27. Remove Element
문제
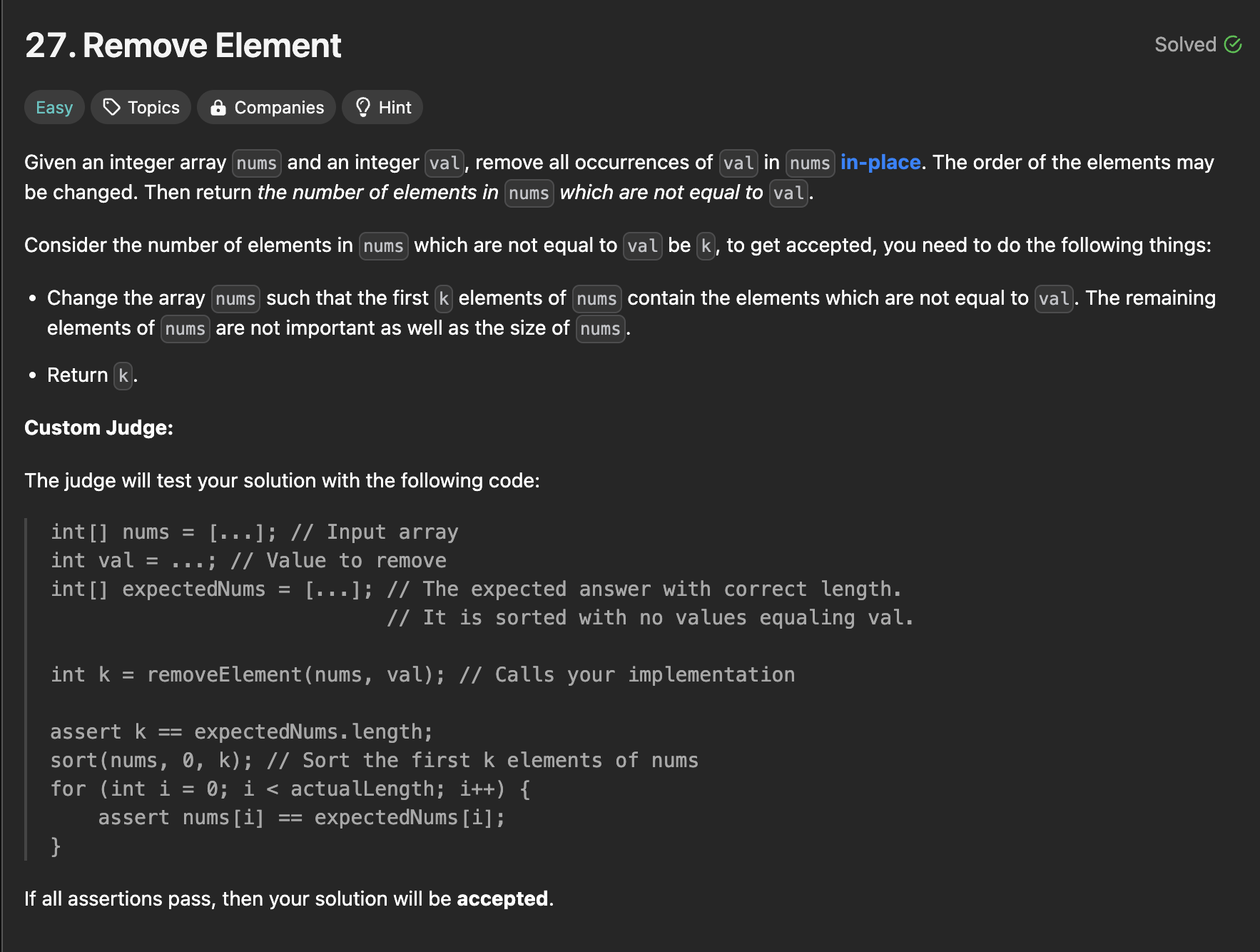
테스트 케이스 & 제약 사항
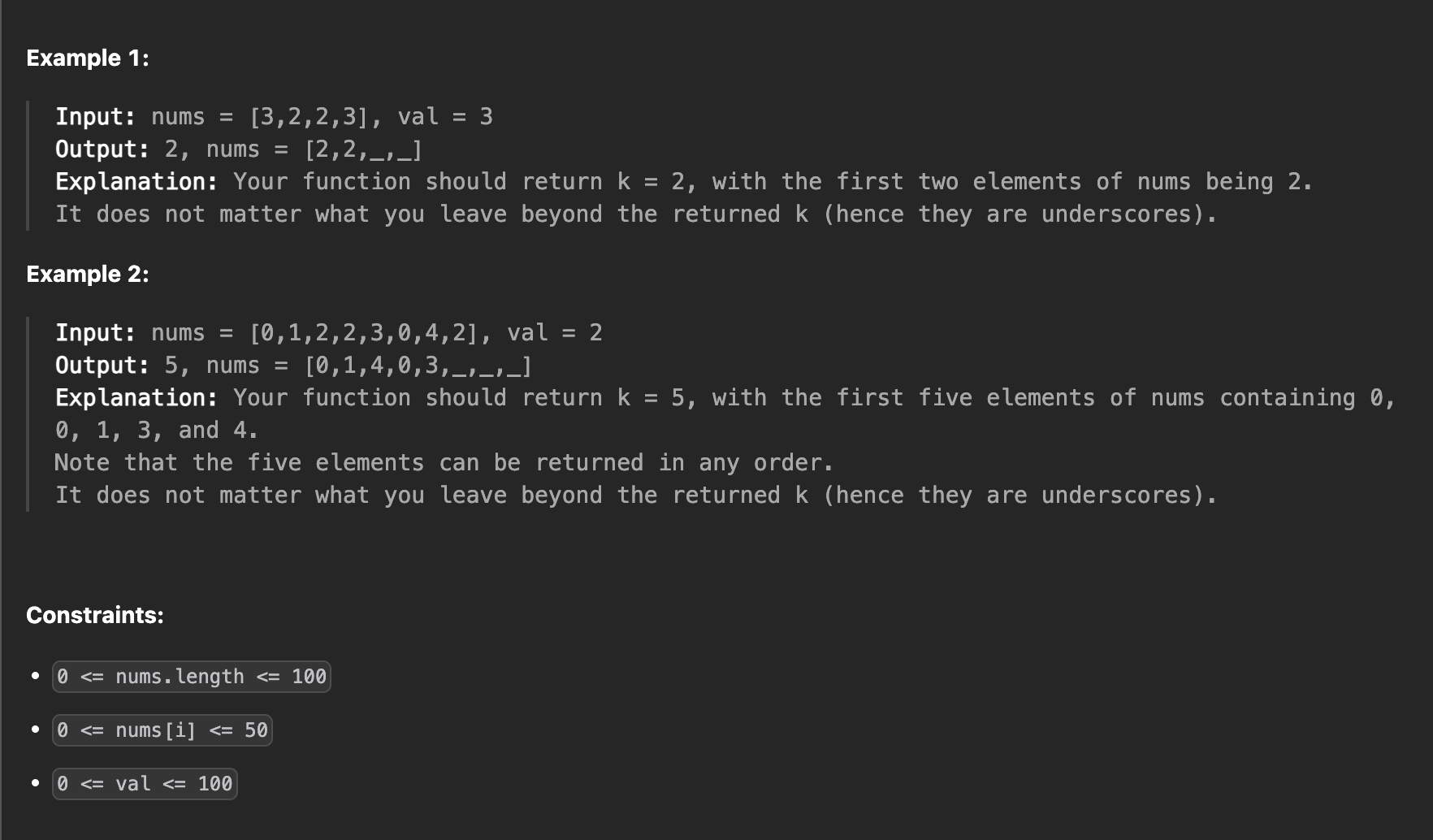
문제 읽고 분석하기
- 정수로 구성된 배열
nums와 정수val이 주어진다. - 배열
nums의 요소 중val의 값을 가진 요소를 전부 '제 자리에서(in-place)' 제거해야 한다. - 제 자리에서(in-place)는 추가적인 배열을 사용하지 않고, 주어진 배열을 '직접 수정'하여
val의 값과 일치하는 요소를 제거해야 한다는 것 k는val과 일치하지 않는 요소들의 개수다.k를 리턴한다.
심사 순서
1. 결과 값 expectedNums가 주어진다.
2. 리턴 받은 k의 값과 expectedNums의 길이가 같은지 확인한다.
3. 배열 nums의 0 번째 요소부터 ~ k 번째 요소까지 정렬한 뒤, expectedNums의 0 번째 요소부터 k 번째 요소와 비교한다.
즉, 배열nums의 0번째 요소부터 k번째 요소까지 val과 일치하지 않는 요소들로 구성되어 있어야한다.
첫 번째 접근
-
배열
nums에서 정수val이 있는 인덱스 번호를 찾아 제거해주는 방식으로 접근하려한다. -
val과 일치하지 않는 요소들은nums의 앞에 위치해야한다는 조건을 충족시키기 위해 -
nums안 (val과 일치하는 요소부터~끝 요소까지) (각 요소의 위치+1)요소로 덮어쓰워주려한다.
예를 들어, nums = [3,2,2,3], val = 3 이 주어진 경우,
val과 일치하는 요소의 첫 인덱스는 0이다.0번 인덱스에첫 번째 요소를 할당한다.[2,2,2,3]1번 인덱스에두 번째 요소를 할당한다.[2,2,2,3]2번 인덱스에세 번째 요소를 할당한다.[2,2,3,3]마지막 요소를 제거한다.[2,2,3]
위 과정을 한번 더 반복하면
val과 일치하는 요소의 첫 인덱스는 2다.[2,2,3]2번 인덱스에세 번째 요소를 할당하려 했지만세 번째 요소가 존재하지 않는다.마지막 요소를 제거한다.[2,2]
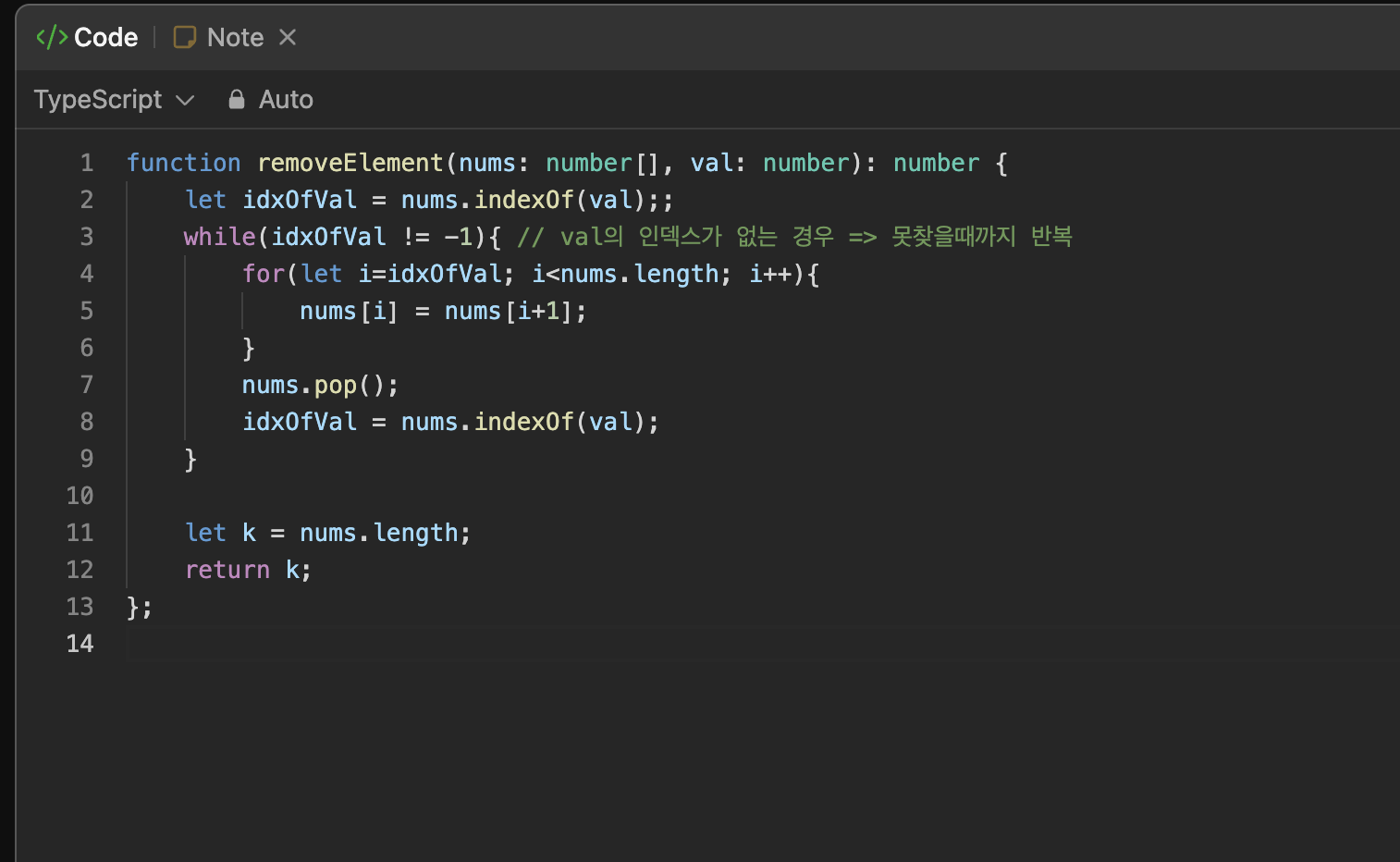
위와 같이 코드를 짜니 테스트 케이스와 submit했을 때 모든 케이스에 통과하였다.
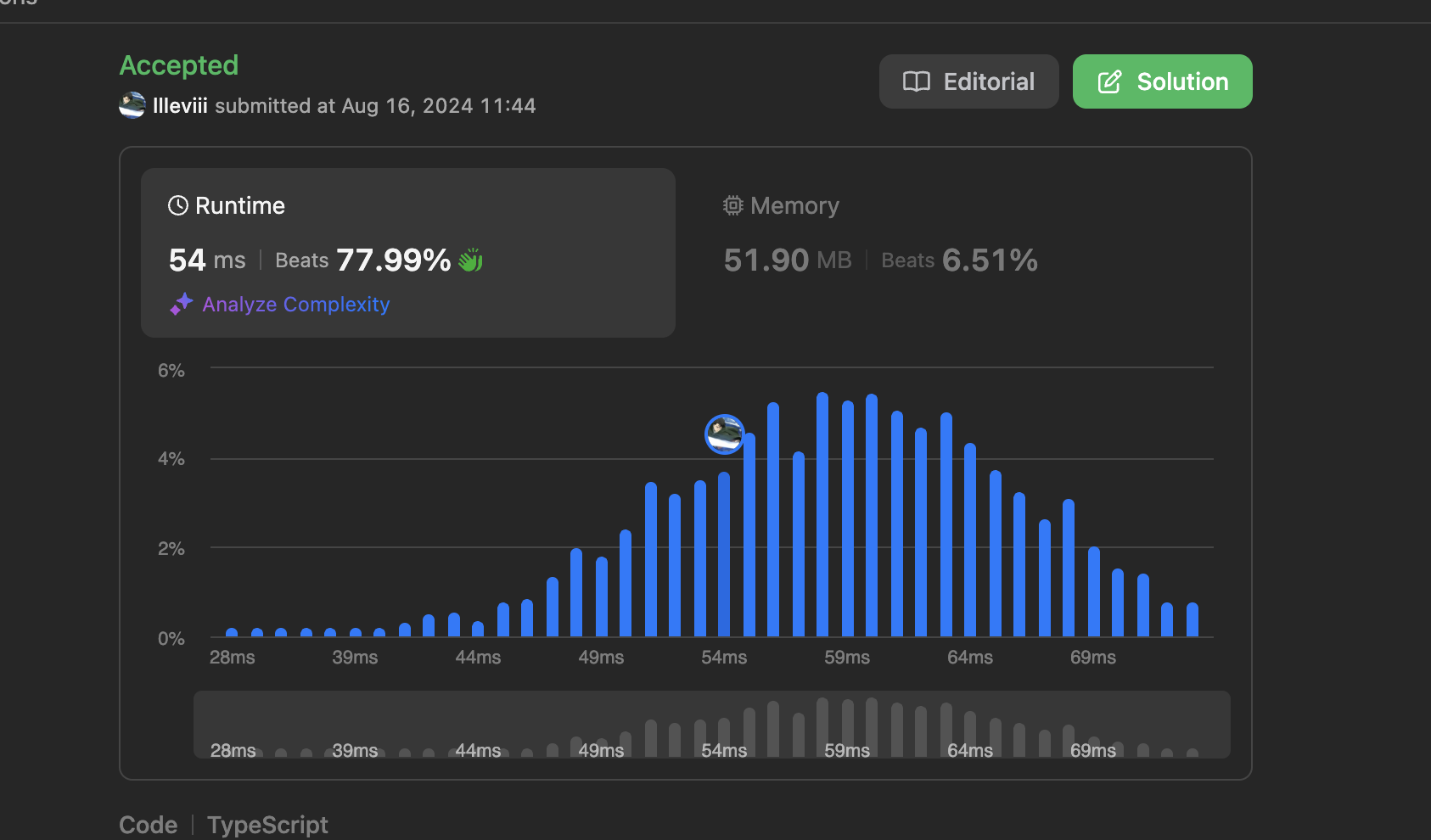
첩 번째 접근에 대한 문제
제출한 코드의 시간 복잡도를 계산해보자.
- 길이가
n인 배열nums에서 요소를 찾는데 걸리는 시간은 최대 O(n) nums의 요소들을 한 칸씩 앞으로 당기는 작업은 최대 O(n)
결과적으로 시간 복잡도는
O(n^2)
시간 복잡도를 더 개선 할 수 있도록 코드를 다시 변경해보자.
두 번째 접근
더 심플하게 생각해보자.
0번째 부터 ~k번째 까지 요소는val과 겹치지 않는 요소로 채워야한다.- 즉,
k번째 이후의 요소는 무엇이 와도 상관이 없다.
nums의 요소들은 두 가지 케이스로 나뉜다.
1. 정수
val과 일치한다.
2. 정수val과 일치하지 않는다.
정수 val과 일치 하지 않는 요소는 0번째 부터 채워 넣는 방식이다.
예를 들어, nums = [3,2,2,3], val = 3 이 주어진 경우,
0번째 요소3은 val과 일치한다.
=>[2,2,2,3]1번째 요소2은 val과 일치하지 않는다.
=>1번째 요소2를0번째에 할당한다.[2,2,2,3]
=> k = k+12번째 요소2은 val과 일치하지 않는다.
=>2번째 요소2를1번째에 할당한다.[2,2,2,3]
=> k = k+13번째 요소3은 val과 일치하지 않는다.
=>[2,2,2,3]- k를 리턴한다.
리턴할 때 중요한건 k의 값이 무엇인지와 0번째 부터 ~ k번째 까지 요소가 무엇인가이다. 즉, 배열 nums가 [2,2,2,3]건 [2,2]건 [2,2,10000000 ...]건 전혀 상관이 없다.
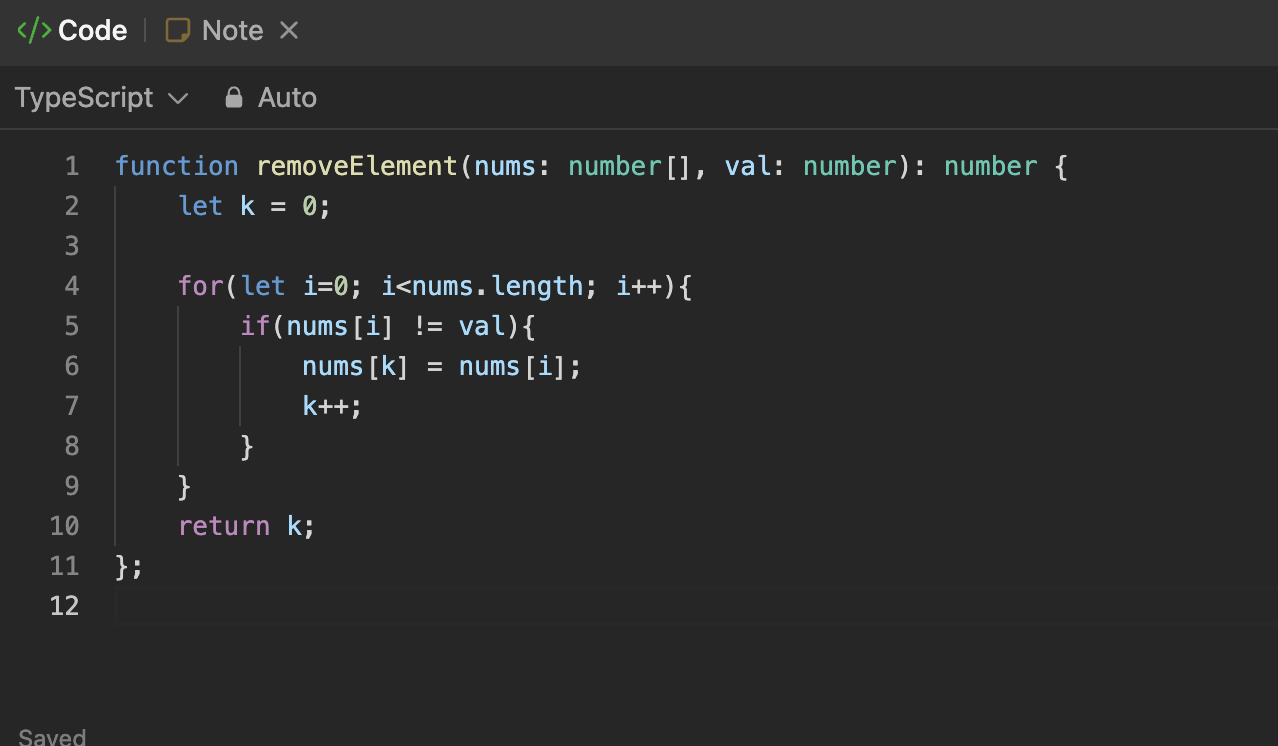
위와 같이 코드를 변경하면 시간 복잡도는 O(n)으로 줄어 들어 더 나은 성능을 기대할 수 있다.
마무리
단순히 문제를 풀어서 통과한걸로 넘어가지말고, 시간 복잡도를 고려하여 더 효율적인 방법이 없을지에 대해 고민해보기
