시간 복잡도 (time complexity)

시간 복잡도 (time complexity)
시간 복잡도: 함수를 실행했을 때
실행 시간이 어느 정도인지 표현할 수 있는 방식
여기서 실행 시간(running time)이란 함수/알고리즘 수행에 필요한 스텝(step)의 수를 뜻한다.
즉, 우리는 함수의 성능이 궁금할때 시간 복잡도를 이용한다.
아래 이미지와 같은 multiply 함수를 예시로 시간 복잡도를 구하는 법을 단계별로 알아보자.

이 때, 각 스텝(step) 수는 코드 라인마다 고정되어 있는 상수(constants)라고 가정하자.
( 상수: 고정된 값 )
1. 실행 시간을 나타내는 함수 T(N)을 구하기

여기에서 N은 배열 inputs의 크기를 말한다.
- 배열
inputs와 정수multiplier를 받는다.inputs와 길이가 같은 배열nums을 생성한다. (c1)- 배열
inputs를 반복한다. (c2)
이 때,for 반복문의 times가N이 아닌N+1인 이유: N번 반복이 끝난 후 루프를 탈출하기 위해 최종적으로 한번 더 검사하기 때문)- 순회하는 요소의 값에 정수
multiplier를 곱한 값을 배열nums에 할당한다. (c3)nums를 반환한다.
각 라인별로 수행되는 스텝 수(costs)를 c1, c2, c3, c4로 정해놓고, 각 라인이 실행되는 횟수(times)를 곱한 값들을 모두 더하면 전체 실행 시간 T(N)을 구할 수 있다.
T(N) = c1 + c2*(N+1) + c3*N + 1
= (c2 + c3)*N + (c1 + c2 + 1)
= a*N + b마지막 줄의 a는 c2+c3를 치환한 것이고 b는 c1+c2+1를 치환한 것이다.
2. N → ∞ 일 때 T(N)이 어떻게 될지 분석하기
T(N) = a*N + b의 형태에서 더 구체적으로 계산하기는 어렵다.
그리고 입력값 N의 크기가 작다면 실행 시간을 계산하는 것이 큰 의미가 없다. 어차피 빨리 끝나기 때문이다.
즉, 우리는 입력값 N의 값이 무한대처럼 큰 경우에 대해서 계산해봐야한다. (N → ∞)
이를 단순하게 표현하기 위해 몇가지 작업을 더 해줘야한다.
(N → ∞ 인 경우, T(N)에서 덜 중요한 것은 제거해주는 작업)
우선 최고차항을 제외하고 나머지 항들은 모두 제거한다. 왜냐하면 N이 커지면 커질수록 최고차항을 제외한 나머지 항들의 영향력은 상대적으로 미미해지기 때문이다.
위 예에서 최고 차항은 a*N (1차)이기 때문에 상수 b (0차)를 제거해준다.
다음으로 최고차항의 계수도 제거해준다. 마찬가지 이유로 N → ∞인 상황에서 계수도 큰 영향력이 없기 때문이다.
이렇게 했을 때 최종적으로 남는 것은 N이 된다.
그리고 이를 𝚹(big theta)로 표기한다. (theta of N 또는 big theta of N으로 읽는다.)
T(N) = 𝚹(N)
위와 같이 실행 시간 T(N)을 구하면서 최고 차항을 제외한 항을 제거해주고, 최고 차항에서도 계수는 제거하여 임의의 함수가 N → ∞ 인 경우, 어떤 함수 형태에 근접해지는지 분석하였는데, 이와 같은 기법을 점근적 분석이라고 한다.
즉, 점근적 분석(asymptotic analysis)이란 N이 계속 커질 때, 함수 T(N)이 어떤 형태의 함수로 근사하게 되는지를 분석하는 방식이다. 우린 이 방식을 함수 실행 시간을 단순화할 때 사용한다.
그리고 점근적 분석을 통해 근사된 함수를 𝚹(N)로 표기하는 것을 점근적 표기법(asymptotic notation)이라고 한다.
정리해보면, 시간 복잡도란 함수의 실행 시간을 표현하는 것이다.
주로 점근적 분석을 통해 실행 시간을 단순하게 표현하는데 이 때 점근적 표기법을 사용한다.
예제로 알아보는 점근적 표기법
boolean exists(int[] inputs, int target) {
for (int i = 0 ; i < inputs.length ; i++) {
if (inputs[i] == target) {
return true;
}
}
return false;
}위 코드는 배열 inputs의 요소에 정수 target과 일치하는 요소가 있으면 true를 반환해주고, 그렇지 않으면 false를 반환해주는 함수다.
그렇다면 위 함수의 시간 복잡도는?
때에 따라 다르다.
함수의 파라미터 데이터에 따라 실행 시간이 달라지는 이유는 찾으려는 숫자 target이 배열의 앞부분에 있으면 금방 찾을 것이고, 반대로 찾으려는 숫자가 배열 뒷부분에 있으면 더 오래 걸릴 것이다.
1. best-case와 worst-case로 나눈다.
위와 같은 경우는 best 케이스와 worst 케이스를 나눠 접근해야한다.
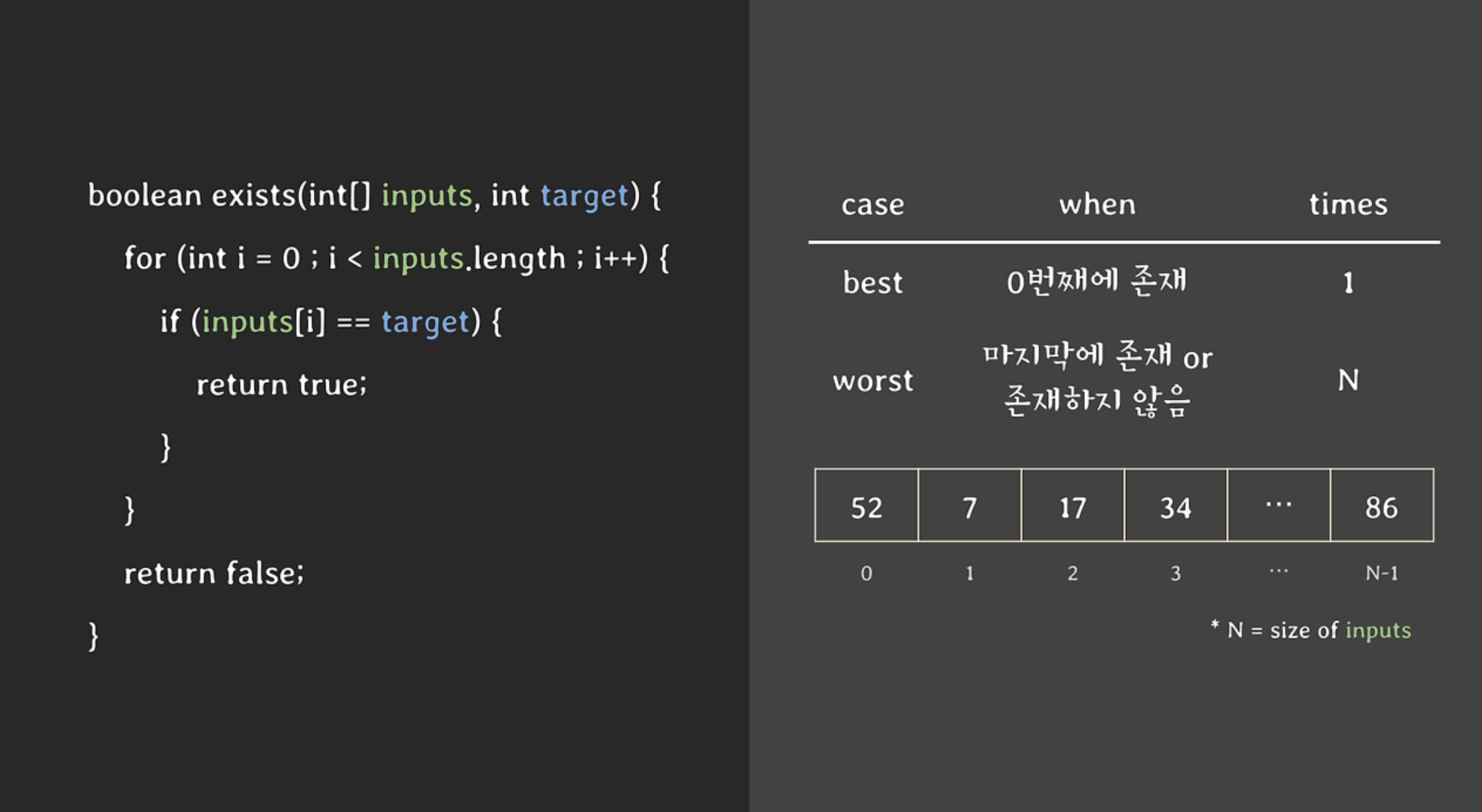
best-case
위 예제에서 best-case는 맨 처음에 찾는 타겟이 있는 경우다. 함수는 한 번만에 true를 반환하고 종료되기 때문에 배열 inputs의 크기 N과 상관없이 상수(constant)의 시간으로 종료된다.
worst-case
worst-case는 타겟이 가장 마지막에 있거나 없는 경우다. 이 때는 모든 배열을 순회하기 때문에 총 N번을 확인해야하며, 실행 시간이 배열 inputs 의 크기 N에 비례한다.
2. 시간 복잡도를 서술하는 두가지 방법
위 두가지 case별로 시간 복잡도를 표현해보자.
- 하한선(lower-bound)을 기준으로 표현했을 때: 아무리 빨라도 상수 시간 이상이다.
- 상한선(upper-bound)을 기준으로 표현했을 때: 아무리 느려도 input-size N에 비례하는 이하다.
3. 상한선과 하한선 기준으로 시간 복잡도를 구하기
위 두가지 표현을 기호로 표기하면 아래와 같다.
하한선 기준으로 표현했을 때: 𝝮(1)
상한선 기준으로 표현했을 때: O(N)
여기서 𝝮(big omega)는 lower-bound를 의미하고, O(big O)는 upper-bound를 의미한다.
𝝮(1)의 1이 의미하는 것은 상수(constant)를 뜻하는데, 이는 input-size N과 상관 없이 N이 크던 작던 상수라는 의미다
O(N)에서 N은 input-size N에 비례하는 형태를 뜻한다.
보통 일반적으로 O(N)을 사용한다.
4. case별로 시간 복잡도 구하기
best-case
best-case는 배열 맨 앞에 위치한 정수가 찾고자 하는 target과 같은 경우다. 이 경우에는 실행 시간의 lower-bound와 upper-bound가 모두 상수 시간이 된다.
이는 𝝮(1)과 O(1)로 표현할 수 있다.
즉, best-case에서 실행시간은 항상 상수 시간이다. 이와 같이 상한선과 하한선이 같은 함수 형태를 띠게 되면, 상한선과 하한선이 아주 가까이 있다 (tight하다) 라고 표현해서 tight-bound라고 한다.
그리고 위의 경우는 𝚹(1)로 표현할 수 있다.
𝚹(theta)는 tight-bound를 의미하며, lower-bound와 upper-bound가 같은 함수 형태를 나타낸다면 한번에 tight-bound인 𝚹로 표기할 수 있다.

worst-case
worst-case는 찾고자 하는 타겟이 맨 마지막에 있거나 아예 없는 경우인데, 이 case의 실행 시간은 lower-bound와 upper-bound 모두 input-size N에 비례한다. 이는 각각 𝝮(N)과 O(N) 표기할 수 있으며 마찬가지로 상한선과 하한선이 동일한 함수 형태이기 때문에 즉, tight하기 때문에 𝚹(N)으로 표기할 수 있다.

average-case
average-case는best-case도 worst-case도 아닌 일반적인 경우다. 예를 들어, 찾고자 하는 타겟을 배열의 중간 정도에서 찾았을 때, 실행 시간은 O(1/2*N)이 된다. 하지만 앞서 이야기 한것처럼 계수 1/2는 큰 영향력이 없기 때문에 O(N)으로 표현할 수 있다.

점근적 표기법과 case정리

즉, 가장 처음 등장 했던 예제에서 실행 시간을 𝚹(N)으로 표기하였는데, 이는 upper-bound와 lower-bound 모두 동일하게 input-size N에 비례하기 때문이다.
Binary Search
Binary Search는 이미 정렬이 된 배열을 파라미터로 받고 그 배열에서 내가 원하는 타겟을 찾아서 반환하는 검색을 말한다.
이미 정렬이 되어있기 때문에, 가운데부터 검색을 시작하여 찾고자 하는 값과 비교를 해나가는 방식이다.

위 예시에서 정렬이 된 배열 sortedInputs과 찾고자 하는 정수 target을 파라미터로 받는 경우, 최종적으로 target 값 105와 배열 요소 100을 비교하게 된다.
binary-searh는 위처럼 매번 탐색을 실행할 때마다 N의 사이즈가 1/2씩 줄어들기 때문에, 최종적으로 N의 사이즈가 1이 될 때까지 탐색을 k번 했다고 가정하면 N*(1/2)^k = 1텍스트 이라는 수식이 나온다.
이 수식은 k=log(2)N 으로 변경 할 수 있다.
결론적으로, 위 예제는 찾고자 하는 값이 없는 worst-case에서 시간 복잡도가 𝚹(logN)이 된다.

주요 시간 복잡도
주요 시간 복잡도 예시


실행 속도를 비교하면 아래와 같다.

왜 big O 표기법을 많이 사용할까?
키보드에 오메가와 셉타가 없기 때문이 아닐까 라는 말에 많은 공감을 한다.
