분할 정복 (divide & conquer)

분할정복(divide & conquer)
어떤 문제를 유사한 형태를 가지는 더 작은 크기의서브 문제들로 나눈 후, 이들을 재귀적으로 같은 방식으로 해결한 뒤 각 서브 문제들을 해결한 결과를 활용하여 원래 문제를 해결하는 방식
여기에서 재귀적의 사전적 의미는
어떤 사건이 자신을 포함하고 다시 자기 자신을 사용하여 정의되는 것을 말한다.
쉽게 말해, 함수에서 자신을 다시 호출하여 작업을 수행하는 방식으로 주어진 문제를 푸는 방법을 의미한다.
즉, 분할 정복(divide and conquer)은 문제 해결 전략 중 하나로 총 세가지의 스텝으로 나눌 수 있다.
- divide: 문제를 작은 크기의 서브 문제들로 나눈다.
- conquer: 서브 문제들을 동일하게 재귀적인 방식으로 해결한다. 만약 더 이상 나눌 수 없다면 직접 해결한다.
- combine: 서브 문제들의 솔루션을 합쳐서 원래 문제의 솔루션을 만든다.
위와 같은 방식이 재귀적으로 진행되기 때문에 서브-문제에 대해서 다시 divide-conquer-combine 작업이 반복하여 수행된다는 뜻이다.
분할 정복(divide & conquer) 활용 사례로는 merge-sort, quick-sort, binary-search 등이 있다.
이 중, 오늘은 merge sort를 예시로 공부하며 분할 정복을 정복해보려한다.
merge sort
merge-sort는 배열 또는 리스트의 정렬 알고리즘 중 하나로 큰 문제를 서브 문제들로 나눠 재귀적으로 해결하는 방식을 사용한다.
아래와 같은 순서를 가진 배열을 오름차순으로 정렬한다고 가정해보자.

1. 주어진 배열을 반으로 분할(divide)한다.
2. 서브-문제를 나눠 또 머지 소트를 수행한다.
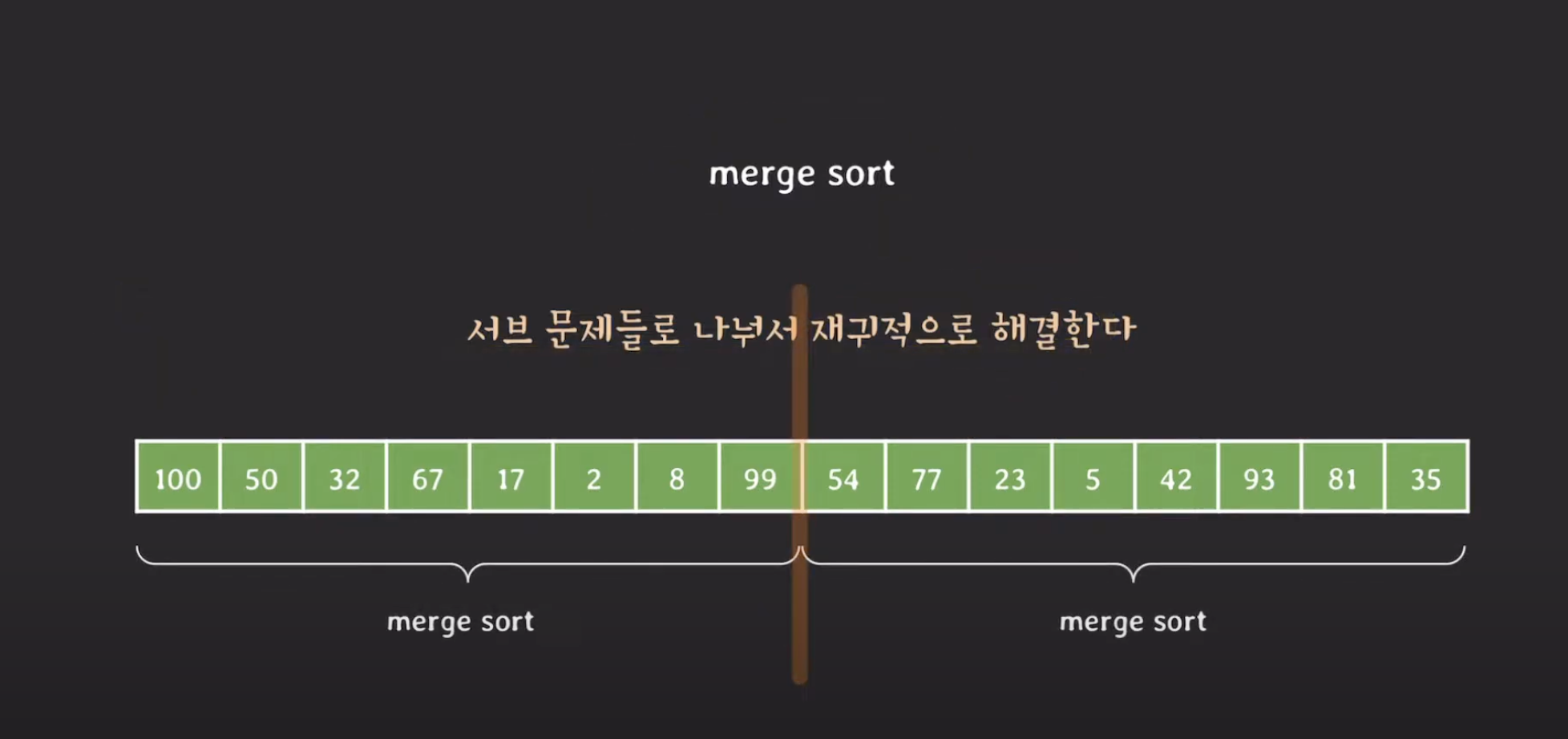
3. 서브 문제들의 솔루션들로 원 문제를 해결해나간다.

4. 서브 문제들의 솔루션들로 원래(original) 문제를 해결한다.

merge sort 구체적인 예시
배열을 계속 반으로 분할하다보면 아래 그림처럼 하나의 요소만 남게 된다.(100)

더이상 서브-문제로 분할할 수 없는 경우 합쳐주기 시작한다.(combine)
100과 50을 합치는(combine) 과정에서
1. 각 요소인 100과 50을 복사해준 뒤,
2. 100과 50을 비교한다.
3. 50이 100보다 작기 때문에, 50이 원래 100이 있던 자리로 할당이 되고, 100은 원래 50이 있던 자리로 할당이 된다.

마찬가지로 (32, 67) 서브-문제도 위와 같은 방식으로 정렬한다.

이제 해결된 서브-문제 (50,100)과 (32,67)을 combine해준다.
- 첫 자리인 50과 32를 비교한다.
- 32가 50보다 작기 때문에 32가 원래 50의 자리에 할당한다.
- 다음으로 50과 67을 비교한다.
- 50이 67보다 작기 때문에 50이 원래 100이 있던 자리에 할당한다.
- 다음으로 100과 67을 비교한다.
- 67이 더 작기 때문에 원래 32가 있던 자리에 할당한다.
- 마지막으로 100을 원래 67이 있던 자리에 할당한다.

이제 앞 4개의 서브-문제가 정렬되었는데 이는 앞 8개 서브-문제의 앞 부분이 해결되었다는 뜻이다.

위와 같은 방식으로 원래 문제를 해결할 수 있다. (전체 배열을 정렬할 수 있다.)

위 merge-sort를 코드로 보면 아래와 같다.
merge_sort(nums, start_idx, end_idx):
if start_idx < end_idx:
middle_idx = (start_idx + end_idx) // 2
merge_sort(nums, start_idx, middle_idx)
merge_sort(nums, middle_idx+1, end_idx)
merge(numbs, start_idx, middle_idx, end_idx)배열을 반으로 나누어 middle_idx를 구한 뒤 앞-서브-문제와 뒤-서브-문제를 재귀적으로 함수를 수행하는 것을 볼 수 있다.
if start_idx < end_idx 조건은 더 이상 나눌 수 없을 때까지 재귀를 반복한다는 뜻이다.

merge-sort 시간복잡도
merge-sort의 시간 복잡도는 upper-bound든 lower-bound든 N*logN이 된다. (upper-bound와 lower-bound가 같기 때문에 Θ를 사용한다.)

시간복잡도가 N*logN인 이유
- 배열을 계속 분할(divide)하기 때문에
logN - 분할한 서브 문제를 계속 합치기(combine) 때문에
N
최종적으로 이를 곱해주면 N*logN이 된다.
