1. ChatGPT
-
챗봇 & 언어모델
-> 언어 모델: 주어진 이전 단어들을 바탕으로 다음에 나올 단어, 문장 예측 -
Generative Pre-trained Transformer
2. ChatGPT API
- ChatGPT Playground 활용
- OpenAI API
ChatGPT API 이용한 번역기 만들기 실습
pip install openai
pip install gradio- app.py
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch() - ChatGPT 이용
import openai
import gradio as gr
openai.api_key = "당신의 API KEY"
def greet(content):
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo", messages=[{"role": "user", "content": content}]
)
return completion.choices[0].message.content
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch(share=True)3. 토크나이징
주어진 문장에서 토큰 단위로 정보를 나누는 작업. (주로 텍스트 전처리 과정에서 사용)
- 토큰: 가장 작은 단위가 되는 단어들
- 한국어 토크나이징을 지원하는 파이썬 라이브러리: KoNLPy
- Kkma: 서울대학교 IDS 연구실에서 자연어 처리를 위해 개발한 한국어 형태소 분석기
- Komoran: Shineware에서 자바로 개발한 한국어 행태소 분석기
- Okt: 트위터에서 개발한 Twitter 한국어 처리기에서 파생된 오픈소스 한국어 처리기
-> normalize() 함수를 지원: 오타가 섞인 문장을 정규화하여 처리하는데 효과적
실습1.
!pip install konlpy
from konlpy.tag import Kkma
# 꼬꼬마 형태소 분석기 객체 생성
kkma = Kkma()
text = "아버지가 방에 들어갑니다."
# 형태소 추출
morphs = kkma.morphs(text)
print(morphs)
# 형태소와 품사 태그 추출
pos = kkma.pos(text)
print(pos)
# 명사만 추출
nouns = kkma.nouns(text)
print(nouns)
# 문장 분리
sentences = "오늘 날씨는 어때요? 내일은 덥다던데."
s = kkma.sentences(sentences)
print(s)
# 다른 분석기도 동일한 방식으로 사용!
4. 임베딩
자연어를 숫자나 벡터 형태로 변환하는 처리 과정
-
문장 임베딩 : 문장 전체를 벡터로 표현하는 방법. 전체 문장의 흐름을 파악해 벡터로 변환하기 때문에 문맥적 의미를 지님. 단어 임베딩에 비해 품질이 좋으며, 상용 시스템에 많이 사용.
-
단어 임베딩: 개별 단어를 벡터로 표현하는 방법. 동음이의어에 대한 구분을 하지 않기 떄문에 의미가 다르더라도 단어의 형태가 같다면 동일한 벡터값으로 표현됨. 문장 임베딩에 비해 학습 방법이 간단해서 실무에서 많이 사용됨.
1) 원-핫 인코딩(one-hot encoding)
- 단어를 숫자 벡터로 변환하는 가장 기본적인 방법
- 하나의 값만 1, 나머지는 0
- 원-핫 인코딩으로 나온 결과: 원-핫 벡터
- 단어 집합이라 불리는 사전 필요
- 동일한 단어에 서로 다른 원-핫 벡터값을 가지면 안되기 때문에 이미 저장된 단어는 다시 사전에 저장 X
- 실습
from konlpy.tag import Komoran
import numpy as np
komoran = Komoran()
text = "오늘 날씨는 구름이 많아요."
# 명사만 추출
nouns = komoran.nouns(text)
print(nouns)
# 단어 사전 구축 및 단어별 인덱스 부여
dics = {}
for word in nouns:
if word not in dics.keys():
dics[word] = len(dics)
print(dics)
# 원-핫 인코딩
nb_classes = len(dics)
targets = list(dics.values())
one_hot_targets = np.eye(nb_classes)[targets]
print(one_hot_targets)2) Word2Vec
-
신경망 기반 단어 임베딩의 대표적인 방법
-
의미상 비슷한 단어들을 비슷한 벡터 공간에 위치시킴.
-
CROW 모델: 맥락이라 표현되는 주변 단어들을 이용해 타깃 단어를 예측하는 신경망 모델.
-> 타깃 단어의손실만 계산하면 되기 때문에 속도가 빠름. -
skip-gram 모델: 하나의 단어를 이용해 주변 단어들을 예측하는 신경망 모델. 입출력이 서로 반대로 되어있어 CBOW 모델에 비해 예측해야 하는 맥락이 많음.
-> 단어 분산 표현력이 우수해 임베딩 품질도 우수. -
실습
from gensim.models import Word2Vec
from konlpy.tag import Komoran
import time
# 네이버 영화 리뷰 데이터 읽어옴
# 리뷰 데이터를 각 라인별로 읽어와 \t를 기준으로 데이터 분리
def read_review_data(filename):
with open(filename, 'r') as f:
data = [line.split('\t') for line in f.read().splitlines()]
data = data[1:] # header 제거
return data
# 측정 시작
start = time.time()
# 리뷰 파일 읽어오기
print('1) 말뭉치 데이터 읽기 시작')
review_data = read_review_data('./ratings.txt')
print(len(review_data)) # 리뷰 데이터 전체 개수
print('1) 말뭉치 데이터 읽기 완료: ', time.time() - start)
# 문장단위로 명사만 추출해 학습 입력 데이터로 만듬
print('2) 형태소에서 명사만 추출 시작')
komoran = Komoran()
docs = [komoran.nouns(sentence[1]) for sentence in review_data]
print('2) 형태소에서 명사만 추출 완료: ', time.time() - start)
# word2vec 모델 학습
print('3) word2vec 모델 학습 시작')
model = Word2Vec(sentences=docs, vector_size=200, window=4, min_count=2, sg=1)
print('3) word2vec 모델 학습 완료: ', time.time() - start)
# 모델 저장
print('4) 학습된 모델 저장 시작')
model.save('nvmc.model')
print('4) 학습된 모델 저장 완료: ', time.time() - start)
# 학습된 말뭉치 개수, 코퍼스 내 전체 단어 개수
print("corpus_count : ", model.corpus_count)
print("corpus_total_words : ", model.corpus_total_words)from gensim.models import Word2Vec
# 모델 로딩
model = Word2Vec.load('nvmc.model')
print("corpus_total_words : ", model.corpus_total_words)
# '사랑'이란 단어로 생성한 단어 임베딩 벡터
print('사랑 : ', model.wv['사랑'])
# 단어 유사도 계산
print("일요일 = 월요일\t", model.wv.similarity(w1='일요일', w2='월요일'))
print("안성기 = 배우\t", model.wv.similarity(w1='안성기', w2='배우'))
print("대기업 = 삼성\t", model.wv.similarity(w1='대기업', w2='삼성'))
print("일요일 != 삼성\t", model.wv.similarity(w1='일요일', w2='삼성'))
print("히어로 != 삼성\t", model.wv.similarity(w1='히어로', w2='삼성'))
# 가장 유사한 단어 추출
print(model.wv.most_similar("안성기", topn=5))
print(model.wv.most_similar("시리즈", topn=5))5. 게임 데이터 임베딩 실습
import json
def open_json(file_path):
with open(file_path, 'r') as file:
data = json.load(file)
return data
from gensim.models import Word2Vec
from konlpy.tag import Komoran
import time
satrt = time.time()
print('1) 말뭉치 데이터 읽기 시작')
train = open_json('/content/drive/MyDrive/SKT_FLY_AI 챗봇/train_game.json')
print(len(train))
print('1) 말뭉치 데이터 읽기 완료: ', time.time()-start)
# 문장 단위로 명사만 추출하여 학습 입력 데이터로 만들기
print('2) 형태소에서 명사만 추출 시작')
korman = Komoran()
docs = [korman.nouns(sentence["sentence"]) for sentence in train]
print('2) 형태소에서 명사만 추출 완료: ', time.time()-start)
# word2vec 모델 학습
print('3) word2vec 모델 학습 시작')
model = Word2Vec(sentences=docs, vector_size=200, min_count=2, sg=1)
print('3) word2vec 모델 학습 완료: ', time.time() - start)
# 모델 저장
print('4) 학습된 모델 저장 시작')
model.save('nvmc.model2')
print('4) 학습된 모델 저장 완료: ', time.time() - start)
# 학습된 말뭉치 개수, 코퍼스 내 전체 단어 개수
print("corpus_count : ", model.corpus_count)
print("corpus_total_words : ", model.corpus_total_words)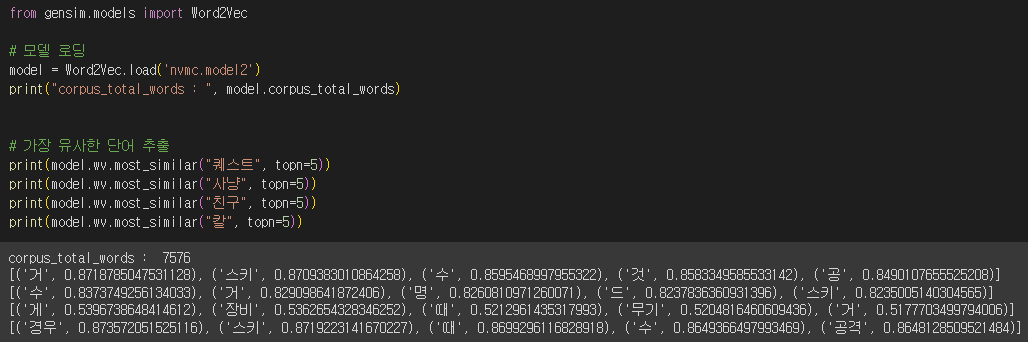
-> 말뭉치가 적어서, 잘못된 결과가 나옴.
6. 챗봇 문답 데이터 감정 분류 모델 구현
1) CNN
- 문장을 감정 클래스별로 분류하는 CNN 모델 구현
- 수치(벡터)로 표현 가능한 대상이면, 특징을 뽑아내도록 CNN 모델을 학습 가능
2) 모델 만들기
# 필요한 모듈 임포트
import pandas as pd
import tensorflow as tf
from tensorflow.keras import preprocessing
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Dense, Dropout, Conv1D, GlobalMaxPool1D, concatenate
# 데이터 읽어오기
train_file = "/content/drive/MyDrive/SKT_FLY_AI 챗봇/chatbot_data.csv"
data = pd.read_csv(train_file, delimiter=',')
features = data['Q'].tolist()
labels = data['label'].tolist()
# 단어 인덱스 시퀀스 벡터
corpus = [preprocessing.text.text_to_word_sequence(text) for text in features]
tokenizer = preprocessing.text.Tokenizer()
tokenizer.fit_on_texts(corpus)
sequences = tokenizer.texts_to_sequences(corpus)
word_index = tokenizer.word_index
MAX_SEQ_LEN = 15 # 단어 시퀀스 벡터 크기
padded_seqs = preprocessing.sequence.pad_sequences(sequences, maxlen=MAX_SEQ_LEN, padding='post')
# 학습용, 검증용, 테스트용 데이터셋 생성 ➌
# 학습셋:검증셋:테스트셋 = 7:2:1
ds = tf.data.Dataset.from_tensor_slices((padded_seqs, labels))
ds = ds.shuffle(len(features))
train_size = int(len(padded_seqs) * 0.7)
val_size = int(len(padded_seqs) * 0.2)
test_size = int(len(padded_seqs) * 0.1)
train_ds = ds.take(train_size).batch(20)
val_ds = ds.skip(train_size).take(val_size).batch(20)
test_ds = ds.skip(train_size + val_size).take(test_size).batch(20)
# 하이퍼파라미터 설정
dropout_prob = 0.5
EMB_SIZE = 128
EPOCH = 5
VOCAB_SIZE = len(word_index) + 1 # 전체 단어 수
# CNN 모델 정의
input_layer = Input(shape=(MAX_SEQ_LEN,))
embedding_layer = Embedding(VOCAB_SIZE, EMB_SIZE, input_length=MAX_SEQ_LEN)(input_layer)
dropout_emb = Dropout(rate=dropout_prob)(embedding_layer)
conv1 = Conv1D(filters=128, kernel_size=3, padding='valid', activation=tf.nn.relu)(dropout_emb)
pool1 = GlobalMaxPool1D()(conv1)
conv2 = Conv1D(filters=128, kernel_size=4, padding='valid', activation=tf.nn.relu)(dropout_emb)
pool2 = GlobalMaxPool1D()(conv2)
conv3 = Conv1D(filters=128, kernel_size=5, padding='valid', activation=tf.nn.relu)(dropout_emb)
pool3 = GlobalMaxPool1D()(conv3)
# 3, 4, 5- gram 이후 합치기
concat = concatenate([pool1, pool2, pool3])
hidden = Dense(128, activation=tf.nn.relu)(concat)
dropout_hidden = Dropout(rate=dropout_prob)(hidden)
logits = Dense(3, name='logits')(dropout_hidden)
predictions = Dense(3, activation=tf.nn.softmax)(logits)
# 모델 생성
model = Model(inputs=input_layer, outputs=predictions)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 모델 학습
model.fit(train_ds, validation_data=val_ds, epochs=EPOCH, verbose=1)
# 모델 평가(테스트 데이터셋 이용)
loss, accuracy = model.evaluate(test_ds, verbose=1)
print('Accuracy: %f' % (accuracy * 100))
print('loss: %f' % (loss))
# 모델 저장
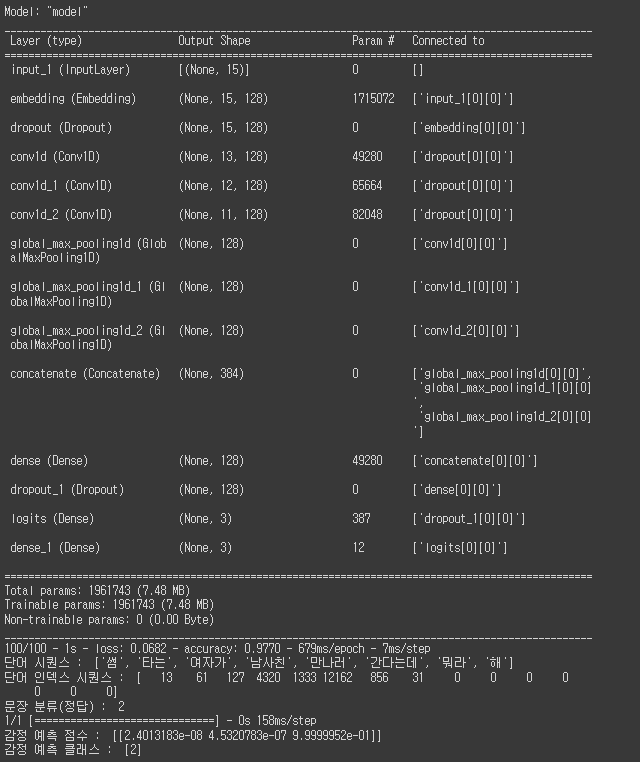
model.save('cnn_model.h5')- 전처리된 입력 데이터를 단어 임베딩 처리
- 합성곱 필터와 엽산을 통해 문장의 특징 정보(특징맵)를 추출하고 평탄화(Flatten)
- 완전 연결 계층(fully connected layer)을 통해 감정별로 클래스를 분류
3) 모델 사용
import tensorflow as tf
import pandas as pd
from tensorflow.keras.models import Model, load_model
from tensorflow.keras import preprocessing
# 데이터 읽어오기
train_file = "/content/drive/MyDrive/SKT_FLY_AI 챗봇/chatbot_data.csv"
data = pd.read_csv(train_file, delimiter=',')
features = data['Q'].tolist()
labels = data['label'].tolist()
# 단어 인덱스 시퀀스 벡터
corpus = [preprocessing.text.text_to_word_sequence(text) for text in features]
tokenizer = preprocessing.text.Tokenizer()
tokenizer.fit_on_texts(corpus)
sequences = tokenizer.texts_to_sequences(corpus)
MAX_SEQ_LEN = 15 # 단어 시퀀스 벡터 크기
padded_seqs = preprocessing.sequence.pad_sequences(sequences, maxlen=MAX_SEQ_LEN, padding='post')
# 테스트용 데이터셋 생성
ds = tf.data.Dataset.from_tensor_slices((padded_seqs, labels))
ds = ds.shuffle(len(features))
test_ds = ds.take(2000).batch(20) # 테스트 데이터셋
# 감정 분류 CNN 모델 불러오기
model = load_model('cnn_model.h5')
model.summary()
model.evaluate(test_ds, verbose=2)
# 테스트용 데이터셋의 10212번째 데이터 출력
print("단어 시퀀스 : ", corpus[10212])
print("단어 인덱스 시퀀스 : ", padded_seqs[10212])
print("문장 분류(정답) : ", labels[10212])
# 테스트용 데이터셋의 10212번째 데이터 감정 예측
picks = [10212]
predict = model.predict(padded_seqs[picks])
predict_class = tf.math.argmax(predict, axis=1)
print("감정 예측 점수 : ", predict)
print("감정 예측 클래스 : ", predict_class.numpy())- 결과