- 판다스 공식 사이트: http://pandas.pydata.org
1. 판다스의 주요 기능
• 쉬운 결손 값(missing data) 처리
• 레이블 위치를 자동적/명시적으로 정리한 데이터 작성
• 데이터 집약
• 고도의 레이블 베이스의 슬라이싱, 추출, 큰 데이터세트의 서브세트화
• 직감적인 데이터세트 결합
• 축의 계층적 레이블 붙임
• 여러가지 데이터 형식에 대응한 강력한 I/O
• 시계열 데이터 고유의 처리
2. 판다스 설치(jupyter notebook에서)
!pip install pandas3. Series
-
1차원 데이터를 다루는 데 효과적인 자료구조
-
인덱스(레이블)를 가지는 1차원 데이터 (인덱스는 중복 가능)
-
레이블 또는 데이터의 위치를 지정한 추출 기능, 인덱스에 대한 슬라이스 가능
-
산술 연산 가능, 통계량을 산출하는 메리트 가짐
-
pandas.series 클래스를 사용
1.
import pandas as pd
ser = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
ser
- 키워드 인수 index에 레이블이 되는 값을 넘기는 것으로 데이터를 표시.
2. 인덱스 생략하면?

- 0부터 차례대로 인덱스 할당됨.
3. 레이블 사용하여 데이터 선택
ser.loc['b']-> 2 출력
4. 레이블의 범위 지정
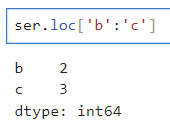
- 레이블의 범위를 지정하여 슬라이싱 가능
5. 복수 요소 지정
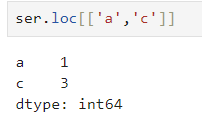
- 복수의 요소를 리스트로 지정 가능
6. 위치 지정하여 데이터 선택
ser.iloc[2]-> 인덱스 2에 대응하는 값 출력(3)
7. 위치를 슬라이스로 지정
ser.iloc[1:3]-> 인덱스 1, 2에 대응하는 값 출력(2,3)
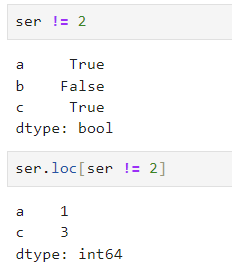
8. 논리값 사용하여 데이터 선택
- loc와 iloc에는 논리값의 리스트를 넘길 수 있음.
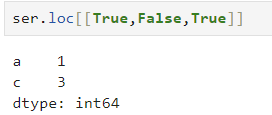
- 비교 연산 이용
4. DataFrame
- 여러 개의 칼럼으로 구성된 2차원 형태의 자료 구조
- DataFrame 객체를 생성하는 가장 쉬운 방법: 파이썬의 딕셔너리를 사용
-> 딕셔너리를 통해 각 칼럼에 대한 데이터를 저장한 후 딕셔너리를
DataFrame 클래스의 생성자 인자로 넘겨주면 DataFrame 객체가 생성됨. - 행과 열에 레이블을 가진 2차원 데이터
- 열마다 다른 형태를 가질 수 있음
- 테이블형 데이터에 대해 불러오기, 데이터 쓰기 가능
- DataFrame끼리 여러 가지 조건을 사용한 결합 처리 가능
- 크로스 집계 가능
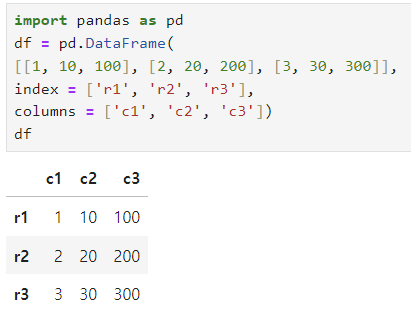
1. DataFrame 작성
- pandas.DataFrame 클래스를 사용
- 첫 인수에는 1차원 또는 2차원 데이터
2. 레이블 사용하여 데이터 선택
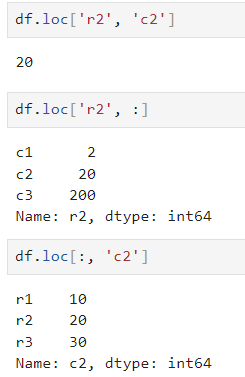
- : 모든 행(열) 선택
- 행의 데이터 수가 1이고 열의 데이터 수가 복수 또는 행의 데이터 수가 복수이고 열의 데이터 수가 1의 경우, 되돌아오는 데이터형은 Series
3. 슬라이스나 리스트를 넘겨주는 방법
- 행 레이블: 리스트로 지정, 열 레이블: 슬라이스로 지정

- iloc 사용

-> 인덱스가 1,2인 행 & 0,2번째 열 - 열 이름 지정

-> loc나 iloc를 지정하지 않고 DataFrame에 대해 지정한 경우, 되돌아 오는 데이터형은 Series
4. 논리값을 사용해서 데이터 선택

5. 다양한 파일 불러오기
1. CSV 파일
- pandas.read_csv() 함수 사용
- 첫번째 인수에 파일 경로를 넘겨주면 DataFrame형 오브젝트 반환
import os
import pandas as pd
csv = os.path.join('./sample/anime.csv')
df = pd.read_csv(csv)
df.head()2. Excel 파일
- openpyxl 패키지를 설치
!pip install openpyxlimport pandas as pd
import openpyxl
import os
xlsx = os.path.join("./sample/anime.xlsx")
df = pd.read_excel(xlsx)
df.head()3. SQL 파일
- pandassql 패키지 설치
!pip install pandasqlfrom pandasql import sqldf
dfsql = lambda q: sqldf(q, globals())
result = dfsql("select name,rating from df where rating > 9.0")
result4. HTML 파일
url = 'https://docs.python.org/3/py-modindex.html'
tables = pd.read_html(url)
tables