1. numpy
1. 버전 확인
print(np.__version__)2. 넘파이 배열
1. 파이썬 리스트
arr = [1,2,3,4,5]- 정수형, 문자형, float형 등 동시에 다른 데이터 타입의 요소들이 들어갈 수 있음.
2. 넘파이 배열
- ndarray 객체 형태
a = np.array(arr)-
각 요소가 모두 같은 데이터 타입을 가져야 함.

-
3차원 배열
a = np.array([[[1,2],[2,3],[3,4]],[[3,4],[4,5],[5,6]]])- shape가 (3,1,3)인 array 만들어보기
b = np.array([[[1,2,3],[[4,5,6]],[[7,8,9]])-> 확인: b.shape
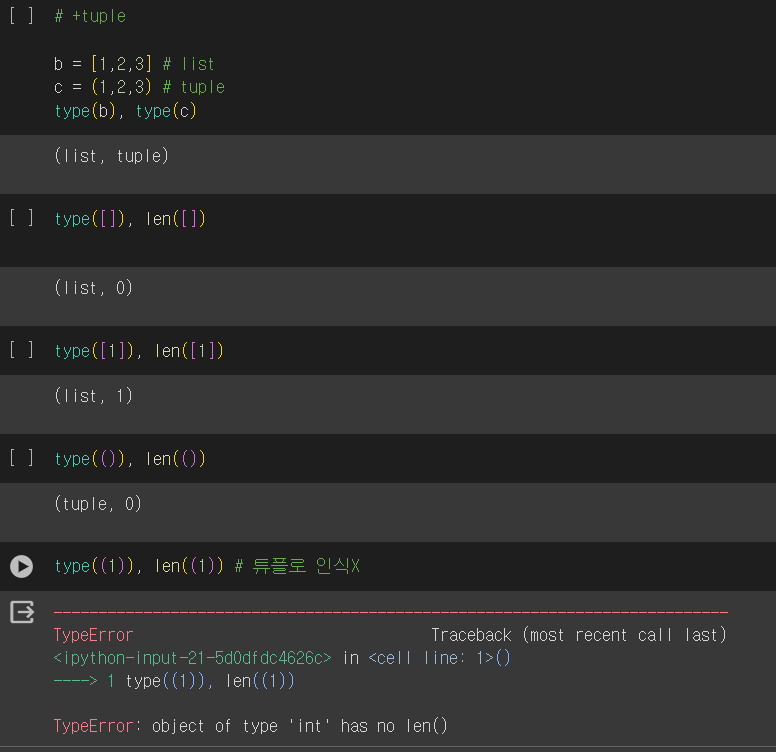
3. 튜플
4. 배열 생성 함수
- arange() 함수
arr = np.arange(12) # 0부터 11까지 출력
arr1 = np.arange(12,2,-1) # 12부터 3까지 -1씩 줄어가면 출력- zeros() 함수: 요소를 0으로
np.zeros(3) # [0,0,0] 출력
np.zeros((3,3)) # 3*3 배열의 모든 요소가 0- ones() 함수: 요소를 1로
3. 차원 변환
- reshape 이용
- 1차원으로 변환: a.reshape(-1)
- a.reshape(3,-1): 행 개수만 입력하면, 열 개수는 알아서 계산
4. 범용 함수
- sum: 요소들의 전체합
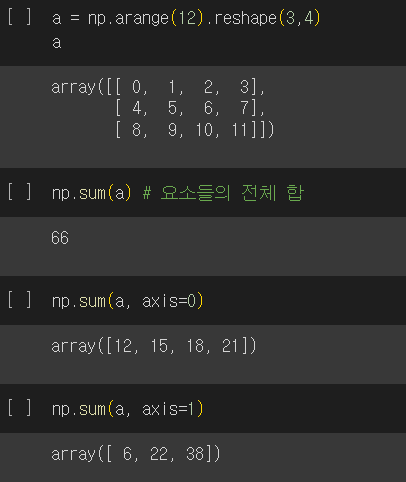
- mean: 요소들의 평균
- argmax: 가장 큰 값이 들어있는 인덱스 반환
5. 인덱싱, 슬라이싱
- 인덱싱: 차원이 줄어든다
- 슬라이싱: 차원 유지
- 인덱스 -1: 제일 뒤를 의미
- 인덱스 -5: 뒤에서 5번째
- Fancy indexing
a = np.arange(12).reshape(3,-1)일 때:

6. 브로드캐스팅(Broad Casting)
- 각 요소에 1 더하기
a = np.array([3,4,5])
a + np.array([1]) # [1,1,1]로 브로드캐스팅- 차원이 다른 배열끼리의 합
y = np.arange(6).reshape(2,3)
z = np.array([1,2,3]) #[[1,2,3], [1,2,3]]으로 브로드캐스팅
y + z7. 배열 합치기
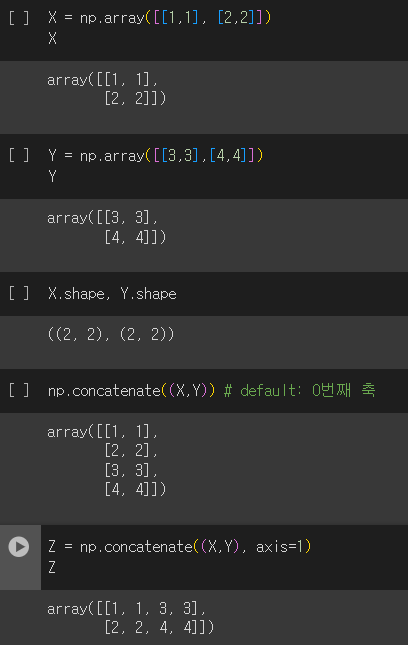
- stack: axis 개수 증가
- concatenate: axis 개수 유지
2.머신러닝(Machine Learning)
1. 정의
명시적으로 규칙을 프로그래밍하지 않고, 데이터로부터 의사결정을 위한 패턴을 기계가 스스로 학습
: "어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때, 경험 E로 인해 성능이 향상됐다면, 이 컴퓨터 프로그램은 작업 T와 성능 측정 P에 대해 경험 E로 학습한 것"
데이터(과거)에 숨겨진 정보와 규칙을 기계 스스로 습득하게 하고, 그 결과를 이용하여 새로운 입력(미래)을 예측하는 기술
- 함수 근사: 입력과 출력의 관계(규칙) 찾기
2. 사용할 수 있는 경우
- 데이터를 구할 수 있어야 함
- 데이터에 관심을 가지는 규칙이 있다고 판단되는 경우
- 기존의 명시적인 프로그래밍 방법으로는 해결 방법이 없는 복잡한 문제
3. 데이터
-
정형 데이터: 표 형식으로 만들어질 수 있는 데이터(DB, 스프레드시트, csv 등)
-
반정형 데이터: XML, HTML
-
비정형 데이터: 이미지, 동영상, 음성, 텍스트 등(빅데이터)
-
수치 데이터(양적 데이터) - 연속형, 이산형
-
범주형 데이터(질적 데이터) - 순위형, 명목형
4. 학습 방법
1. 지도 학습 / 비지도 학습
-
지도 학습: 학습 알고리즘에 주입하는 훈련 데이터에 타깃값(레이블, 정답)이라는 원하는 답이 포함되어 있는 경우
지도학습 예시: 분류, 회귀
- 변수가 연속형: 수치 예측(회귀)
- 변수가 범주형: 범주 예측(분류)
-
비지도 학습: 훈련 데이터에 타깃값(레이블, 정답)이 없는 학습 방법
비지도 학습 예시: 군집
- 타겟 변수가 X
- 특징이 비숫한 변수끼리 묶기
2. 사례 기반 학습 / 모델 기반 학습
-
사례 기반 학습: 기존의 데이터를 기억해두고(학습), 새로운 데이터에 대해서는 기존 데이터와의 유사도를 측정하여 결정
-
모델 기반 학습: 기존 데이터들의 모델을 만들어서 예측
5. 과대/과소 적합
1. 좋은 모델?
- 현재의 데이터(train data)를 잘 예측.
- 새로운 데이터(unobserved data)가 들어왔을 때에도 잘 예측. (일반화)
2. 과대적합
-
모델을 지나치게 복잡하게 학습하여, 학습 데이터 세트에서는 성능이 높게 나타나지만, 새 데이터가 주어지면 정확한 예측/분류 수행X
-
테스트 데이터는 학습에 사용 X (전체 데이터 -> Train + Validation + Test)
-
과적합을 막는다 = 일반화
3. 교차검증
- 가장 적합한 모델을 선택하기 위한 방법
- 학습 세트를 여러 서브 세트로 나누고, 모델을 각 세트의 조합으로 훈련 & 검증
- 학습이 끝나면, 최종 모델을 전체 학습 세트로 학습시키기
6. 인코딩
-
Label Encoding: 문자로 표현된 범주형 데이터(타겟값)를 숫자로 변환
-
One-Hot Encoding:
1) 알고리즘이 가까이 있는 두 값이 떨어져 있는 두 값보다 비슷하다고 판단하는 오류를 막기 위함2) 큰 숫자를 더 중요하다고 판단할 수 있는 알고리즘의 동작을 막기 위함
7. 특성 스케일링
-
Min-Max 스케일링(최대 최소 정규화)
1) 최대값이 1, 최소값이 0, 나머지는 0 ~1 사이의 값
2) 이상치의 영향 큰 편
3) X_norm = (X-X_min) / (X_max-X_min)
4) 가장 많이 사용 -
표준화(Z-Score Normalization)
1) 평균이 0, 분산이 1이 되도록 변환
2) 이상치 영향 덜함
3) 입력 데이터가 정규분포를 따르도록 함
4) z = (x-mean) / Standard Deviation -
Robust Scaler
1) 평균과 분산 대신에 중간값과 사분위값 사용
2) 이상치 영향 최소화 -
결측치 처리
1) 삭제
2) 0, 평균, 중간값, 최대, 최소 등의 값으로 채우기
3) scikit-learn의 Imputer 객체 사용
8. 데이터 불균형
- 샘플링 기법
- 오버 샘플링: 소수 클래스의 샘플 늘리기
- 언더 샘플링: 다수 클래스의 샘플 줄이기
- 하이퍼파라미터:
모델링할 때, 사용자가 직접 세팅하는 값(튜닝 필요)
9. 모델의 성능 평가
1.오차 행렬(혼동 행렬)
- TP: 양성으로 예측, 정답도 양성
- FP: 양성으로 예측, 정답은 음성
- TN: 음성으로 예측, 정답도 음성
- FN: 음성으로 예측, 정답은 양성
2. 정확도(Accuracy)
: 전체 중 정답으로 맞춘 비율(TP+TN / TP+TN+FP+FN)
3. 정밀도(Precision)
: 양성이라고 판정한 것 중에서 실제로 양성(TP / TP + FP)
4. 재현율(Recall)
: 실제 양성 중 양성이라고 예측한 비율(TP / TP+FN)
5. 특이도(Specificity)
: 음성인 것 중에서 음성이라고 맞춘 비율(TN / TN+FP)
6. F1 점수
: 정밀도와 재현율을 하나의 숫자로 표현(조화평균, 2(정밀도재현율)/(정밀도+재현율))
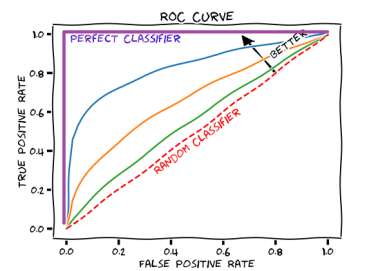
7. ROC
: Threshold 값을 변화시키면서, True Positive Ratio와 False Positive Ratio를 그래프로 나타낸 것.
-> 커브가 왼쪽 상단에 붙어 있을수록 좋은 분류기
10. 회귀 모델의 평가
1. 회귀 알고리즘
- 오차: 실젯값과 예측값의 차이
- 오차가 최소가 되도록 모델을 최적화하는 것
2. MSE(평균 제곱 오차)

3. 결정계수(R^2)
- 독립변수가 종속변수를 어느 정도 설명하고 있는지 나타내는 지표
- ex) R^2 = 0.3 -> 독립변수가 종속변수의 30% 설명
- 1에 가까울수록 잘 설명
- R^2 = SSE/SST = 1 - SSR/SST
- 회귀 알고리즘 적용 전, y값의 평균과 전체 데이터 사이의 오차 계산
4. 조정된 결정계수(Adjusted R Square)
- 독립변수의 개수가 증가하면, 일방적으로 결정계수가 증가하는 단점 수정
- Adjusted R^2 = 1 - ((SSR / (n-k-1)) / (SST / (n-1)))
