
A Style-Based Generator Architecture for Generative Adversarial Networks
Introduction
이번에 리뷰할 논문은 GAN의 dicriminator 혹은 loss부분을 건드리는 것이 아닌 오로지 generator의 네트워크 구조를 개선함으로써 기존의 GAN이 가지는 여러 한계점들을 개선한 논문입니다.
1) 여기서 제시한 generator 네트워크 구조는 high-level attribute(사람 얼굴의 pose 혹은 identity)와 stochastic variation(사람 얼굴의 frekles 혹은 hair)을 unsupervised하게 구분하도록 학습이 이루어 집니다. 또한 이렇게 구분하여 학습한 후 이들을 scale-specific하게 적절히 조합하여 이미지를 생성해내는 특징이 있습니다.
2) 그리고 interpolation property와 disentanglement를 개선하였다고 하는데 이는 latent vector를 선형적으로 변화 시켰을 때 생성되는 이미지의 특정 feature들이 변화하는 양상을 개선하였다는 의미입니다. 기존의 GAN들은 이 부분이 상당히 얽혀있어(entangled되어있어) latent vector를 interpolate하는데 있어 어려움이 있습니다.
Style-based generator
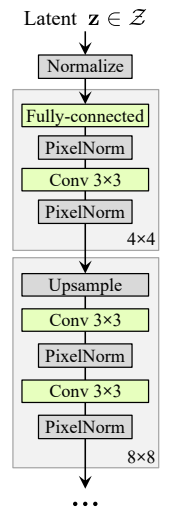
기존의 GAN 구조는 위와같이 latent vector(논문에서는 latent code라는 표현을 씁니다)를 직접 generator 네트워크에 input으로 집어넣어 이미지를 생성합니다.
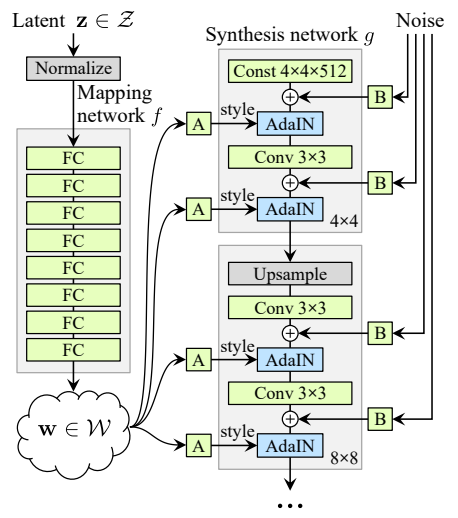
여기에서는 앞에서 말한 기존의 GAN의 generator 구조에서 벗어나 generator 네트워크의 input으로 학습된 특정 고정된 값을 넣어주고 latent vector를 따로 mapping network라는 네트워크를 통해 w를 생성한 후 이를 noise와 함께 네트워크 중간 중간에 넣어주게 됩니다.
generator의 시작부분을 보면 const로 고정된 input이 들어가는 것을 볼 수 있습니다.
다시말해 latent vector로 생성된 w가 이미지의 high-level attribute 즉 style을 결정하게 되고 noise로 들어오는 값이 이미지의 stochastic variation을 조절하게 됩니다.
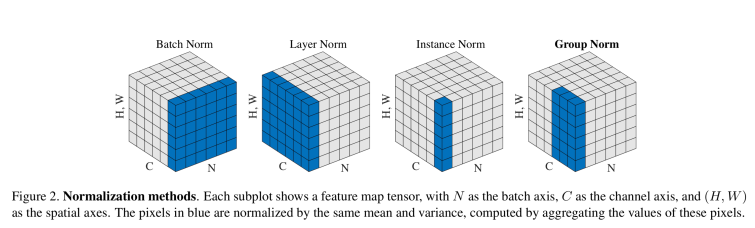
위 그림은 facebook AI의 Group Normalization 논문의 그림입니다.
해당 그림을 보면 각 normalization이 어떻게 이루어지는지 직관적알기 쉽습니다.
이중 style gan에서는 instance normalization을 응용한 AdaIN이라는 adaptive instance normalization 방법을 사용합니다.
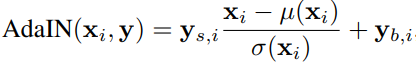
AdaIN의 원리로는 위의 그림과 같으며 mapping network에서 w라는 style feature 정보를 다시 fully connected layer를 통해 y라는 값으로 style 정보 feature값을 도출합니다.
여기서 i는 각 layer의 channel 개수가 됩니다.
이때 y는 와 가 존재하므로 각 layer의 channel수의 2배만큼의 size를 가지게 됩니다.
해당 논문에서는 w에서 이렇게 y라는 지역적인 style을 추출해낸다고 언급하고 있습니다.
그리고 마지막으로 noise input을 얘기하고 있는데 이 noise input은 1 channel의 각 feature가 uncorrelated한 gaussian noise이며 기존의 feature map에 더해집니다.
여기서 이러한 방법이 entangled 문제를 해결하는 이유는 각 style 값이 이미지를 generate하는데 있어 일부 feature map에만 영향을 주기 때문이라고 생각됩니다.
Quatlity of generated images
해당 논문에서는 이러한 새로운 generator 구조가 image의 quality를 항상 보장하는 건 아니지만 보편적으로 상당히 개선하는 것을 볼 수 있다고 합니다.
지표로는 FID(frechet inception distance)를 사용하였으면 celeba-HQ와 FFHQ데이터에서 각 generator를 추가했을 때 값이 다음의 표와 같다고 제시하고 있습니다.
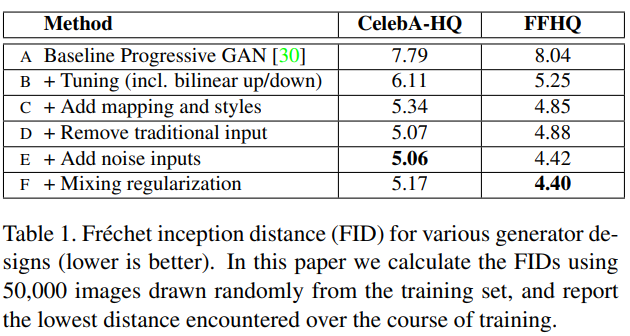
이때의 결과는 아래의 그림과 같으며 선별한 결과들이 아닌 보편적인 결과들이라고 한다. 이때 확실히 1024x1024 이미지 임에도 불구하고 악세서리같은 것들을 포함하여 높은 quality의 이미지가 생성됨을 볼 수 있습니다.
이때 w가 너무 extreme한 값 즉 너무 치우쳐진 값이 나오지 않도록 truncated trick을 사용했다고 하네요.

Prior art
이전 GAN architecture들은 discriminator를 변형하거나 multi-discriminator를 사용해서 이러한 문제들을 해결하였는데 해당 논문의 architecture는 그런거 일절 없이 generator의 구조만 바꾸어도 좋은 결과를 얻었다는 내용입니다.
Properties of the style-based generator
지금까지 generator의 구조가 어떻게 이루어졌는지 살펴보았으니 이제 어떠한 특징을 갖는지 소개합니다.
먼저 w에서 나온 y가 각 style의 정보를 담게되는 이유로는 각 channel단위로 AdaIN이 적용되므로 이전의 통계량 값(normalize 했으니까 mean과 variance를 말하는 것 같습니다.)에 의존적이지 않으면서 각 feature들의 relative importance를 조절할 수 있기 때문이라고 합니다.
즉 각 AdaIN은 하나의 convolution에서 style을 control하는 영향력을 가지며 다른 AdaIN을 만나면 그 영향력이 덮어씌워져 희미해집니다.
Style mixing
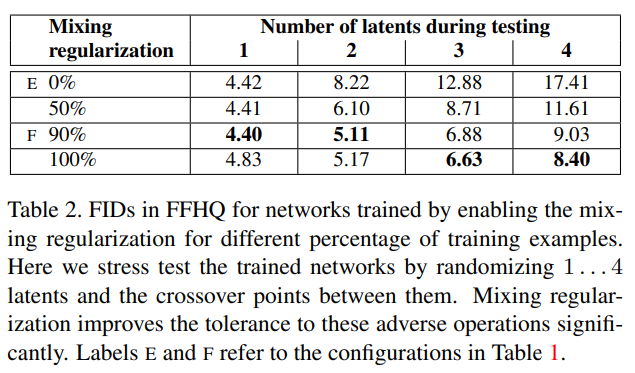
해당 논문에서는 이 style의 localization 즉 특정 layer의 AdaIN이 특정 style 정보를 담고있다는 성질을 더 개선하기 위하여 mixing regularization이라는 방법을 사용합니다.
해당 방법은 2개의 latent vector에서 각각 ,을 만든 후 특정 비율만큼의 AdaIN의 style y값을 섞어서 이미지를 generate하는 방법입니다.
섞으니까 FID가 더 줄어드는 것을 볼 수 있으며 해당 E와F는 table 1에서의 E와F 모델을 말합니다.
그리고 다음 그림은 두개의 latent vector에서 생성된 y값을 중간 feature map의 사이즈에 따라 A를 기준으로 B의 값으로 바꿔넣은 결과이다.
위의 그림일수록 앞단 layer에서 값을 바꾼거고 뒤로갈수록 뒷단 layer에서 값을 바꾼 결과이다.

Stochastic variation
우리가 사람 얼굴을 판단할 때 얼굴의 주근깨나 혹은 머리 스타일, 피부색등은 크게 영향을 미치지 않습니다.
눈이 하나면 사람이 아니지만 피부색이 좀 달라도 그건 상관이 없는것과 같은데 기존의 GAN은 이러한 특징 마저 high-level attribute랑 같이 학습되는 문제가 있어 함수의 capacity를 잡아먹는 문제와 랜덤성을 반영하는데 어려움이 있다고 합니다.
즉 피부색은 좀 달라도 되는데 이러한 피부색도 어느정도 특정하도록 학습이 되어버리는 것으로 굳이 학습하지 않아도 되는데 학습하는 문제로 이해됩니다.
그러나 논문에서 제시하는 generator는 각 layer마다 per-pixel noise를 줌으로써 stochastic aspect에만 영향을 주도록 학습이 이루어진다고 합니다.

위의 그림을 보면 noise값을 변화시켰을때 머리카락 부분만 바뀌는 것을 보아 stochastic variation만 발생하는 것을 볼 수 있습니다.

또한 위의 그림을 보면 윗부분은 앞단의 layer의 noise를 바꾼 것이고 아랫부분은 뒷단의 layer의 noise를 바꾼 부분인데 확실히 뒷단으로 갈 수록 finer한 stochastic variation이 발생하는 것을 볼 수 있습니다.
즉 noise에서도 layer에서 localization이 일어나는 것을 볼 수 있습니다.
Seperation of global effects from stochasticity
style정보 y의 경우 전반적으로 영향을 미치는 값이지만 마구잡이 random하게 주는 noise의 경우 규칙성이 없으므로 high-level attribute는 y로 학습되고 stochastic variation은 noise로 학습된다고 합니다.
Disentanglement studies
disentanglement란 linear subspace 즉 각 원소값이 하나의 variation 요소를 control하는 latent space를 말합니다.
이때 z의 분포에서 mapping network를 통해 w의 sampling density는 기존의 z의 분포에 영향을 받기보다 학습이 되므로 기존의 entanglement를 해결이 가능합니다.
이때 이렇게 mapping된 w가 linear subspace에 가까워지는 이유로는 w가 entangled 된것보다 disentangled한 상태가 더욱 realistic한 이미지를 generate하기 좋기 때문이라고 설명하고 있습니다.
그래서 variation의 요소들을 알지는 못하지만 기존의 GAN에 비해 상대적으로 disentangled되어 unsupervised setting이라고 표현하고 있습니다.
이때 disentanglement의 정도를 나타내는 지표로는 기존의 지표가 encoder의 latent vector생성을 필요로 하는데 해당 논문의 network에는 encoder가 없으므로 다른 2가지 방안을 제시하게됩니다.
Perceptual path length
만약 2개의 end point가 있을 때 이 둘 사이의 특정 interpolation 영역에서 두 end point에서 없던 feature가 갑자기 생긴다면 해당 latent vector는 entangled되어있다고 생각해도 좋을 것입니다.
그래서 서로다른 latent vector 와 로 이미지를 각각 generate한 후 VGG16의 embedding값으로 distance를 구하는 방법을 쓰게 됩니다. (정확한 거리구하는 수식은 모르겠습니다 ㅠㅠ)
이때 interpolation은 z의 경우 spherical interpolation이 해당 논문의 architecture에서는 적합하기 때문에 그렇게 했다는데 왜 인지는 마찮가지로 모르겠습니다.
아마 gaussian distribution시 같은 분포의 vector들이 원형으로 나오기 때문이지 않을까 추측해봅니다.
z의 경우는 spherical interpolation, w의 경우 linear interpolation을 하여 sample들의 distance 평균을 구하게 되며 수식은 다음과 같습니다.
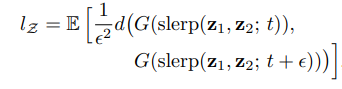

아래의 표를 보면 확실히 perceptual path length값이 줄어드는 것을 볼 수 있습니다.
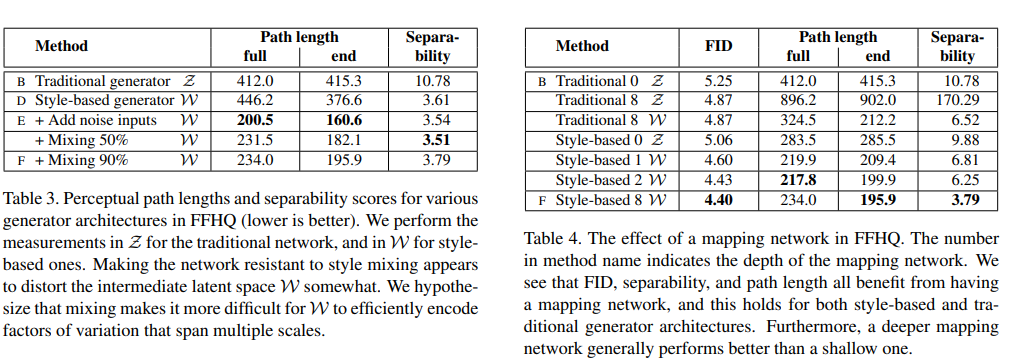
Linear separability
2번째 방법으로는 dataset의 binary attribute들을 40여개정도 뽑아서 discriminator와 구조가 같으나 이들을 classification하는 모델들을 다 학습후 20000장의 이미지들을 generate하여 이중 각 attribute에서 probability순으로 10000장씩 2그룹으로 나눈후 SVM을 하여 entropy 즉 를 구하여 다 더한후 exp취한 값을 지표로 사용하였다고 한다.
concept은 이해가 되나 너무 복잡하다...
식은 다음과 같다.
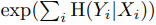
뭐 결과적으로는 mapping network의 depth를 깊게 할 수록 더 좋아지더라는 거 같다.
Conclusion
해당 논문에서 제시하는 generator 구조는 기존의 GAN이 가지는 style-based design 즉 높은 quality의 이미지와 entanglement를 개선하는데 효과적입니다.
future work로는 intermediate latent space를 직접적으로 shaping하면 좋을 것 같다고 합니다.
이거 학습하는데 tesla v100 8대로 학습했다고 합니다... ㄷㄷ
pretrain된 weight아닌 바닥부터의 학습은 일반인이 따라하기는 힘들것 같아요 ㅠㅠ
20.11.03
paper link - https://arxiv.org/abs/1812.04948
video link - https://www.youtube.com/watch?v=kSLJriaOumA&feature=youtu.be
code link - https://github.com/NVlabs/stylegan
