OS
데이터의 접근
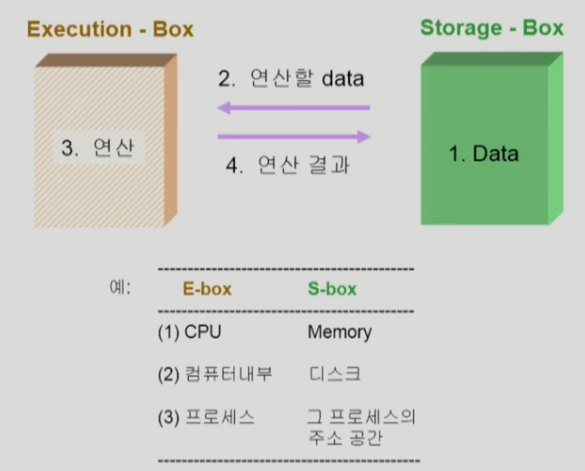
Race Condition
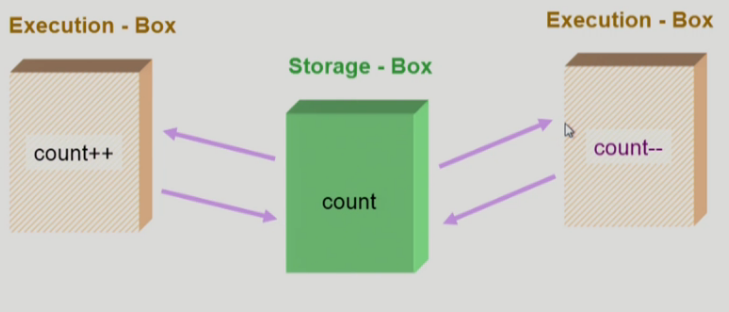
- S-box(Memory Address Space)를 공유하는 E-box(CPU, Process)가 여럿 있는 경우 Race Condition의 가능성이 있다.
OS에서 race condition은 언제 발생하는가?
- kernel 수행 중 인터럽트 발생 시
- Process가 system call을 하여 kernel mode로 수행 중인데 context switch가 일어나는 경우
- Multiprocessor에서 shared memory 내의 kernel data
OS에서의 race condition (1/3)
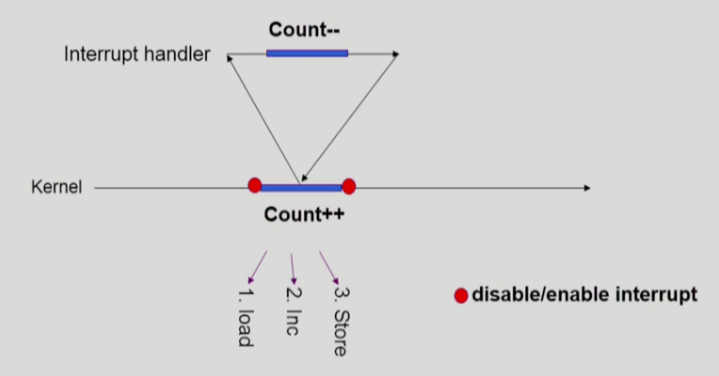
- 커널 모드 running 중 interrupt가 발생하여 인터럽트 처리루틴이 수행
→ 양쪽 다 커널 코드이므로 kernel address space 공유
OS에서의 race condition (2/3)
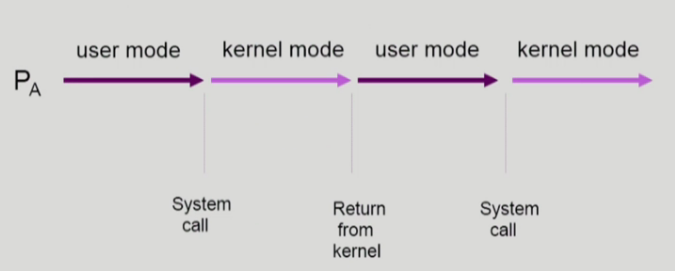
- 두 프로세스의 address space 간에는 data sharing이 없음
- 그러나 system call을 하는 동안에는 kernel address space의 data를 access하게 됨(share)
- 이 작업 중간에 CPU를 PREEMPT 해가면 race condition 발생
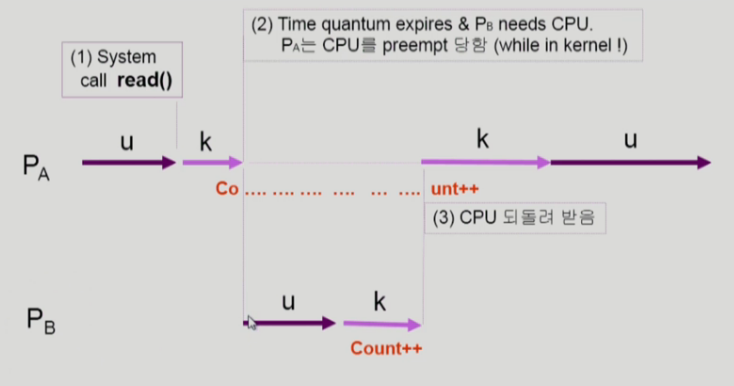
- 해결책 : 프로세스가 커널 모드에서 수행 중일 때는 CPU를 preempt하지 않고 커널 모드에서 사용자 모드로 돌아갈 때 preempt.
- 이렇게하면 할당 시간이 정확히 지켜지지 않고 편차가 생길 수 있지만 time-sharing은 real-time이 아니기 때문에 이러한 복잡한 문제를 쉽게 해결할 수 있다.
OS에서의 race condition (3/3)
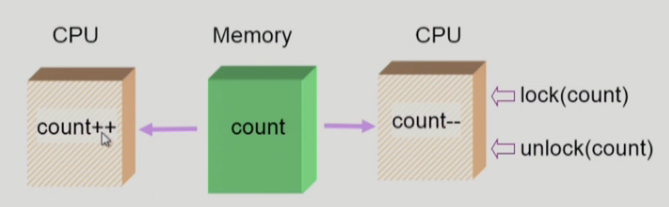
- 어떤 CPU가 마지막으로 count를 store 했는가? → race condition
- (방법 1) 한번에 하나의 CPU만이 커널에 들어갈 수 있게 하는 방법
- (방법 2) 커널 내부에 있는 각 공유 데이터에 접근할 때마다 그 데이터에 대한 lock/unlock을 하는 방법
Process Synchronization 문제
- 공유 데이터(shared data)의 동시 접근(concurrent access)은 데이터의 불일치 문제(inconsistency)를 발생시킬 수 있다.
- Race condition
- 여러 프로세스들이 동시에 공유 데이터를 접근하는 상황
- 데이터의 최종 연산 결과는 마지막에 그 데이터를 다룬 프로세스에 따라 달라짐
- race condition을 막기 위해서는 concurrent process는 동기화(synchronize)되어야 한다.
The Critical-Section(임계 구역) Problem
- n개의 프로세스가 공유 데이터를 동시에 사용하기를 원하는 경우
- 각 프로세스의 code segment에는 공유 데이터를 접근하는 코드인 critical section이 존재
- Problem
- 하나의 프로세스가 critical section에 있을 때 다른 모든 프로세스는 critical section에 들어갈 수 없어야 한다.
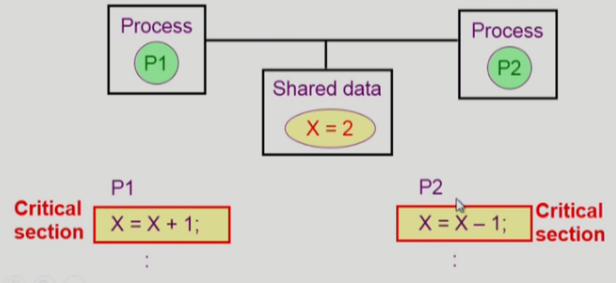
- 하나의 프로세스가 critical section에 있을 때 다른 모든 프로세스는 critical section에 들어갈 수 없어야 한다.
프로그램적 해결법의 충족 조건
- 가정
- 모든 프로세스의 수행 속도는 0보다 크다
- 프로세스들 간의 상대적인 수행 속도는 가정하지 않는다
- Mutual Exclusion(상호 배제)
- 프로세스 Pi가 critical section 부분을 수행 중이면 다른 모든 프로세스들은 그들의 critical section에 들어가면 안된다
- Progress
- 아무도 critical section에 있지 않은 상태에서 critical section에 들어가고자 하는 프로세스가 있으면 critical section에 들어가게 해주어야 한다
- Bounded Waiting(유한 대기)
- 프로세스가 critical section에 들어가려고 요청한 후부터 그 요청이 허용될 때까지 다른 프로세스들이 critical section에 들어가는 횟수에 한게가 있어야 한다.
- critical section에 들어가고자 하는 프로세스가 3개가 있는데 2개가 번갈아가면서 들어가면서 나머지 하나는 못들어가고 기다리는 상태가 될 때 이 조건을 만족하지 못한다.
Algorithm 1
- Synchronization variable
- int turn;
- initially turn = 0; → P can enter its critical section if (turn == i)
- Process P
do {
while (turn != 0);
critical section
turn = 1;
remainder section
} while (1);- Satisfies mutual exclusion, but not progress
- 즉, 과잉양보 : 반드시 한번씩 교대로 들어가야만 함(swap-turn) 그가 turn을 내값으로 바꿔줘야만 내가 들어 갈 수 있음, 특정 프로세스가 더 빈번히 critical section을 들어가야 한다면?
Algorithm 2
- Synchronization variable
- boolean flag[2];
- initially flag [모두] = false; // no one is in CS
- "P ready to enter its critical section" if (flag[i] == true)
- Process P
do {
flag[i] = true;
while (flag[i]);
critical section
flag[i] = false;
remainder section
} while (1);- Satisfies mutual exclusion, but not progress requirement.
- 둘 다 2행까지 수행 후 끊임 없이 양보하는 상황 발생 가능
Algorithm 3(Peterson's Algorithm)
- Combined Synchronization variables of algorithms 1 and 2.
- Process P
do {
flag[i] = true;
turn = j;
while (flag[i] && turn == j);
critical section
flag[i] = false;
remainder section
} while (1);- Meets all three requirements; solves the critical section problem for two processes.
- Busy Waiting(=spin lock)!(계속 CPU와 memory를 쓰면서 wait)
Synchronization Hardware
- 하드웨어적으로 Test & modify를 atomic하게 수행할 수 있도록 지원하는 경우 앞의 문제는 간단히 해결
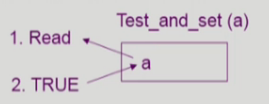
- Mutual Exclusion with Test & Set
Synchronization variable:
boolean lock = false;Process P
do {
while (Test_and_Set(lock));
critical section
lock = false;
remainder section
}Semaphores
- 앞의 방식들을 추상화시킴
- Semaphore S
- integer variable
- 아래의 두 가지 atomic 연산에 의해서만 접근 가능

Critical Section of n Processes
Synchronization variable:
semaphore mutex; /* initially 1: 1개가 CS에 들어갈 수 있다 */Process P
do {
P(mutex); /* If positive, dex-&-enter, Otherwise, wait. */
critical section
V(mutex); /* Increment semaphore */
remainder section
} while (1);- busy-wait는 효율적이지 못함(=spin lock)
- Block & Wakeup 방식의 구현(=sleep lock)
Block / Wakeup Implementation
- Semaphore를 다음과 같이 정의
typedef struct
{
int value; /* semaphore */
struct process *L; /* process wait queue */
}semaphore;- block과 wakeup을 다음과 같이 가정
- block : 커널은 block을 호출한 프로세스를 suspend 시킴, 이 프로세스의 PCB를 semaphore에 대한 wait queue에 넣음
- wakeup(P) : block된 프로스세 P를 wakeup 시킴, 이 프로세스의 PCB를 ready queue로 옮김
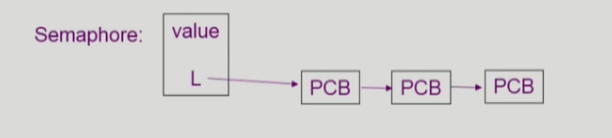
Implementation
- Semaphore 연산이 이제 다음과 같이 정의됨
P(S):
S.value--; /* prepare to enter */
if (S.value < 0) /* Oops. negative, I cannot enter */
{
add this process to S.L;
block();
}V(S):
S.value++;
if (S.value <= 0)
{
remove a process P from S.L;
wakeup(P);
}Which is better?
-
Busy-wait v.s. Block/wakeup
-
Block/wakeup overhead v.s. Critical section 길이
- Critical section의 길이가 긴 경우 Block/Wakeup이 적당
- Critical section의 길이가 매우 짧은 경우 Block/Wakeup 오버 헤드가 busy-wait 오버헤드보다 더 커질 수 있음
- 일반적으로는 Block/wakeup이 좋음
Two Types of Semaphores
- Counting semaphore
- 도메인이 0 이상인 임의의 정수값
- 주로 resource counting에 사용
- Binary semaphore(=mutex)
- 0 또는 1 값만 가질 수 있는 semaphore
- 주로 mutual exclusion (lock/unlock)에 사용
Deadlock and Starvation
- Deadlock : 둘 이상의 프로세스가 서로 상대방에 의해 충족될 수 있는 event를 무한히 기다리는 현상
- Starvation : indefinite blocking. 프로세스가 suspend된 이유에 해당하는 세마포어 큐에서 빠져나갈 수 없는 현상
본문 출처 : 운영체제 - 이화여자대학교 반효경

: )