MLFQ(Multi-Level Feedback Queue) Scheduler
과제목표

-
이전까지 구현한 priority scheduler 는 그 실행을 오직 priority 에만 맡기기 때문에 priority 가 낮은 스레드들은 CPU 를 점유하기가 매우 어렵고 이로 인하여 평균반응시간(Average response time) 은 급격히 커질 가능성이 있다. 물론 priority donation 을 통하여 priority 가 높은 스레드들이 실행되는 데 필요한 스레드는 priority 의 보정을 받지만, 이마저도 받지 못하는 스레드가 존재할 가능성도 매우 크다. Advanced Scheduler 는 이러한 문제를 해결하고 average response time 을 줄이기 위해 multi-level feedback queue 스케줄링 방식을 도입한다. 이 스케줄링 방식의 특징은 크게 두 가지가 있다.
-
Priority 에 따라 여러 개의 Ready Queue 가 존재한다. (Multi-level)
-
Priority 는 실시간으로 조절한다. (Feedback)
-
static char **
parse_options (char **argv)
{
...
else if (!strcmp (name, "-mlfqs"))
thread_mlfqs = true;
...
}-
pintos document 에서는 일반 priority scheduler 와 advanced scheduler 중 무엇을 적용할 지 사용자가 선택하도록 요구한다. pintos 를 실행시킬 때 '-mlfqs' 옵션을 넣어주면 advanced scheduler 를 적용하여 kernel 을 작동시키게 된다. 이 값은 <thread.h> 에 정의되어 있다.
-
이제 thread_mlfqs 가 true 일 때는 advanced scheduler 를, false 일 때는 기존 스케줄러를 사용하도록 구현하면 된다.




- 위에 4가지 요구사항에 대해 우선적으로 알아두어야 하는 특징은 niceness, priority, recent_cpu 는 각 스레드별로 존재하는 고유 값이고, load_avg 는 시스템에 하나의 값으로 존재한다는 것과, niceness, priority 는 정수값을 갖고 recent_cpu, load_avg 는 실수값을 갖는다는 것이다.

-
위에서 알 수 있듯이 priority, nice 는 정수 값을, recent_cpu, load_avg 는 실수 값을 가진다. 여기서 문제가 하나 생기는데, 부동 소수점 연산은 복잡한 연산을 다루기 때문에 kernel 을 느리게 만들 가능성이 있다. 이에 따라 pintos kernel 은 부동소수점 연산을 지원하지 않으며 이로 인하여 kernel 에서 위에 나열한 식들의 직접적인 계산은 불가하다. 이를 해결하기 위해 fixed-point 연산을 다루어야 할 필요가 있다.
-
총 32bit 중에서 1 bit(sign), 17 bit(정수부), 14 bit(소수부) 로 적용하여 실수를 int 형식으로 표현할 수 있도록 하는 것이다. 한 가지만 예를 들어보자. 만약 recent_cpu 가 2.75 라는 값을 가진다면 이 값은 fixed-point 로는 아래와 같이 나타낼 수 있다.
-
[0 (sign bit +) 00000000000000010 (정수부 2) 11000000000000 (소수부 0.75)] (소수부의 각 비트는 2^(-1), 2^(-2), ... )
= [0 00000000000000010 11000000000000]
= 45056

구현

#define F (1 << 14) /* fixed point 1 */
#define INT_MAX ((1 << 31) - 1)
#define INT_MIN (-(1 << 31))
// x and y denote fixed_point numbers in 17.14 format
// n is an integer
int int_to_fp(int n); /* integer를 fixed point로 전환 */
int fp_to_int_round(int x); /* FP를 int로 전환(반올림) */
int fp_to_int(int x); /* FP를 int로 전환(버림) */
int add_fp(int x, int y); /*FP의덧셈*/
int add_mixed(int x, int n); /* FP와 int의 덧셈 */
int sub_fp(int x, int y); /* FP의 뺄셈(x-y) */
int sub_mixed(int x, int n); /* FP와 int의 뺄셈(x-n) */
int mult_fp(int x, int y); /*FP의곱셈*/
int mult_mixed(int x, int y); /* FP와 int의 곱셈 */
int div_fp(int x, int y); /* FP의 나눗셈(x/y) */
int div_mixed(int x, int n); /* FP와 int 나눗셈(x/n) */
/* 함수 본체 */
/* integer를 fixed point로 전환 */
int int_to_fp(int n)
{
return n * F;
}
/* FP를 int로 전환(버림) */
int fp_to_int(int x)
{
return x / F;
}
/* FP를 int로 전환(반올림) */
int fp_to_int_round(int x)
{
if (x >= 0)
return (x + F / 2) / F;
else
return (x - F / 2) / F;
}
/*FP의덧셈*/
int add_fp(int x, int y)
{
return x + y;
}
/* FP와 int의 덧셈 */
int add_mixed(int x, int n)
{
return x + n * F;
}
/* FP의 뺄셈(x-y) */
int sub_fp(int x, int y)
{
return x - y;
}
/* FP와 int의 뺄셈(x-n) */
int sub_mixed(int x, int n)
{
return x - n * F;
}
/* FP의곱셈 */
int mult_fp(int x, int y)
{
return (int)((((int64_t)x) * y) / F);
}
/* FP와 int의 곱셈 */
int mult_mixed(int x, int n)
{
return x * n;
}
/* FP의 나눗셈(x/y) */
int div_fp(int x, int y)
{
return (int)((((int64_t)x) * F) / y);
}
/* FP와 int 나눗셈(x/n) */
int div_mixed(int x, int n)
{
return x / n;
}- 위의 연산식을 토대로 다음과 같이 함수를 작성해준다.
- F 는 fixed point 1 을 나타낸다.
- 매개변수 x, y 는 fixed-point 형식의 실수이고, n 은 정수를 나타낸다. 모든 mixed 연산에서 n 은 두 번째 파라미터로 들어오게 한다.
- int fp_to_int_round () 에서 F / 2 는 fixed point 0.5 를 뜻한다. 0.5 를 더한 후 버림하면 반올림이 된다.
- int mult_fp () 에서 두 개의 fp 를 곱하면 32bit * 32bit 로 32bit 를 초과하는 값이 발생하기 때문에 x 를 64bit 로 일시적으로 바꿔준 후 곱하기 연산을 하여 오버플로우를 방지하고 계산 결과로 나온 64bit 값을 F 로 나눠서 다시 32bit 값으로 만들어 준다. (div_fp 도 마찬가지)

void mlfqs_priority(struct thread *t)
{
/* 해당 스레드가 idle_thread 가 아닌지 검사 */
/*priority계산식을 구현 (fixed_point.h의 계산함수 이용)*/
if (t != idle_thread) {
int rec_by_4 = div_mixed(t->recent_cpu, 4);
int nice2 = 2 * t->nice;
int to_sub = add_mixed(rec_by_4, nice2);
int tmp = sub_mixed(to_sub, (int)PRI_MAX);
int pri_result = fp_to_int(sub_fp(0, tmp));
if (pri_result < PRI_MIN)
pri_result = PRI_MIN;
if (pri_result > PRI_MAX)
pri_result = PRI_MAX;
t->priority = pri_result;
}
}mlfqs_priority ()함수는 특정 스레드의 priority 를 계산하는 함수이다. idle_thread 의 priority 는 고정이므로 제외하고, fixed_point.h 에서 만든 fp 연산 함수를 사용하여 priority 를 구한다. 계산 결과의 소수부분은 버림하고 정수의 priority 로 설정한다.

void mlfqs_recent_cpu(struct thread *t)
{
/* 해당 스레드가 idle_thread 가 아닌지 검사 */
/* recent_cpu계산식을 구현 (fixed_point.h의 계산함수 이용) */
if (t != idle_thread) {
int load_avg_2 = mult_mixed(load_avg, 2);
int load_avg_2_1 = add_mixed(load_avg_2, 1);
int frac = div_fp(load_avg_2, load_avg_2_1);
int tmp = mult_fp(frac, t->recent_cpu);
int result = add_mixed(tmp, t->nice);
if ((result >> 31) == (-1) >> 31) {
result = 0;
}
t->recent_cpu = result;
}
}mlfqs_recent_cpu ()함수는 스레드의 recent_cpu 값을 계산하는 함수이다.

void mlfqs_load_avg(void)
{
/* load_avg계산식을 구현 (fixed_point.h의 계산함수 이용) */
/* load_avg 는 0 보다 작아질 수 없다.*/
// load_avg = (59/60) * load_avg + (1/60) * ready_threads;
int a = div_fp(int_to_fp(59), int_to_fp(60));
int b = div_fp(int_to_fp(1), int_to_fp(60));
int load_avg2 = mult_fp(a, load_avg);
int ready_thread = (int)list_size(&ready_list);
ready_thread = (thread_current() == idle_thread) ? ready_thread : ready_thread + 1;
int ready_thread2 = mult_mixed(b, ready_thread);
int result = add_fp(load_avg2, ready_thread2);
load_avg = result;
}
-
mlfqs_load_avg ()함수는 load_avg 값을 계산하는 함수이다. load_avg 값을 스레드 고유의 값이 아니라 system wide 값이기 때문에 idle_thread 가 실행되는 경우에도 계산하여 준다. ready_threads 는 현재 시점에서 실행 가능한 스레드의 수를 나타내므로 ready_list 에 들어있는 스레드의 숫자에 현재 running 스레드 1개를 더한다. (idle_thread 는 실행 가능한 스레드에 포함시키지 않음). -
이제 각 값들이 변하는 시점에 수행할 함수들을 만들어보자. 이 값들이 변하는 시점은 3 경우가 있었다.
- 1 tick 마다 running 스레드의 recent_cpu 값 + 1
- 4 tick 마다 모든 스레드의 priority 재계산
- 1 초마다 모든 스레드의 recent_cpu 값과 load_avg 값 재계산

void mlfqs_increment(void) {
if (thread_current() != idle_thread) {
int cur_recent_cpu = thread_current()->recent_cpu;
thread_current()->recent_cpu = add_mixed(cur_recent_cpu, 1);
}
}mlfqs_increment()함수는 현재 스레드의 recent_cpu 의 값을 1 증가시키는 함수이다.

void mlfqs_recalc_recent_cpu(void) {
for (struct list_elem *tmp = list_begin(&all_list); tmp != list_end(&all_list); tmp = list_next(tmp)) {
mlfqs_recent_cpu(list_entry(tmp, struct thread, allelem));
}
}
void mlfqs_recalc_priority(void) {
for (struct list_elem *tmp = list_begin(&all_list); tmp != list_end(&all_list); tmp = list_next(tmp)) {
mlfqs_priority(list_entry(tmp, struct thread, allelem));
}
}mlfqs_recalc_recent_cpu()함수는 모든 스레드의 recent_cpu 를 재계산 하는 함수,mlfqs_recalc_priority()모든 스레드의 priority 를 재계산 하는 함수이다.

void thread_set_priority(int new_priority)
{
/* mlfqs 스케줄러를 활성 하면 thread_mlfqs 변수는 ture로 설정됨
mlfqs 스케줄러 일때 우선순위를 임의로 변경할수 없도록 한다. */
if (thread_mlfqs) return;
thread_current()->priority = new_priority;
thread_current()->init_priority = new_priority;
refresh_priority();
test_max_priority();
}if (thread_mlfqs) return;이 구문을 추가해줌으로써 문제의 요구조건을 충족할 수 있다.

void thread_set_nice(int nice UNUSED)
{
/* 현재 스레드의 nice 값을 변경한다.
nice 값 변경 후에 현재 스레드의 우선순위를
재계산하고 우선순위에 의해 스케줄링 한다.
해당 작업중에 인터럽트는 비활성화 해야 한다. */
struct thread *t = thread_current();
enum intr_level old_level;
old_level = intr_disable();
t->nice = nice;
mlfqs_priority(t);
test_max_priority();
intr_set_level(old_level);
}
int thread_get_nice(void)
{
/* 현재 스레드의 nice 값을 반환한다.
해당 작업중에 인터럽트는 비활성되어야 한다. */
struct thread *t = thread_current();
enum intr_level old_level;
old_level = intr_disable();
int nice_val = t->nice;
intr_set_level(old_level);
return nice_val;
}
int thread_get_load_avg(void)
{
/* load_avg에 100을 곱해서 반환 한다.
해당 과정중에 인터럽트는 비활성되어야 한다. */
/* timer_ticks() % TIMER_FREQ == 0 */
enum intr_level old_level;
old_level = intr_disable();
int new_load_avg = fp_to_int(mult_mixed(load_avg, 100));
intr_set_level(old_level);
return new_load_avg;
}
int thread_get_recent_cpu(void)
{
/* recent_cpu에 100을 곱해서 반환 한다.
해당 과정중에 인터럽트는 비활성되어야 한다. */
enum intr_level old_level;
old_level = intr_disable();
int new_recent_cpu = fp_to_int(mult_mixed(thread_current()->recent_cpu, 100));
intr_set_level(old_level);
return new_recent_cpu;
}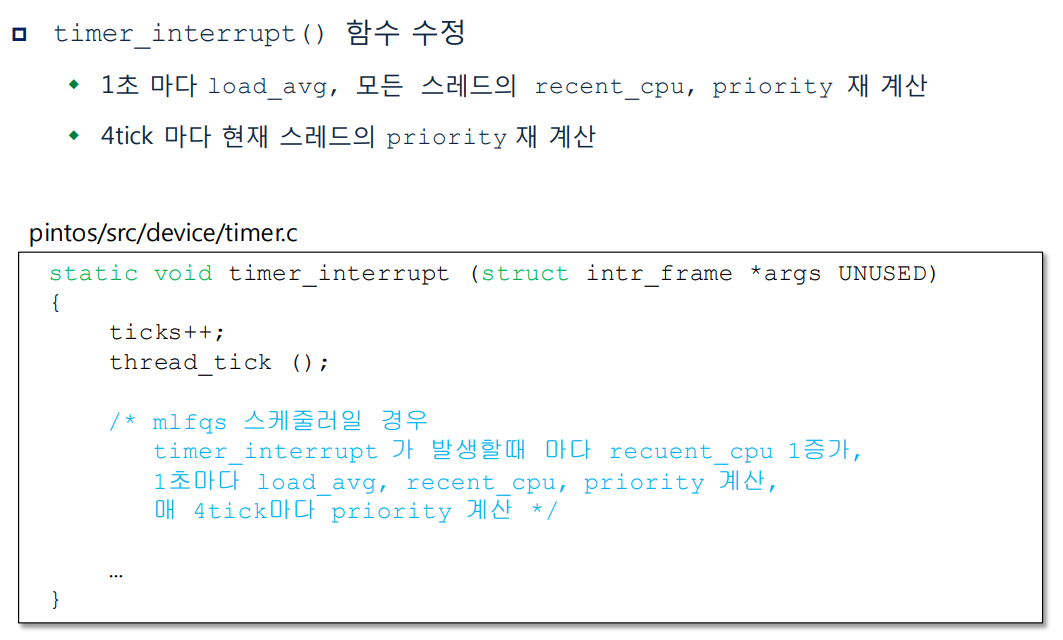
static void
timer_interrupt(struct intr_frame *args UNUSED)
{
ticks++;
thread_tick();
/* mlfqs 스케줄러일 경우
timer_interrupt 가 발생할때 마다 recuent_cpu 1증가,
1초마다 load_avg, recent_cpu, priority 재계산,
매 4tick마다 priority 재계산 */
if (thread_mlfqs) {
mlfqs_increment();
if (timer_ticks() % 4 == 0)
mlfqs_recalc_priority();
if (timer_ticks() % 100 == 0) {
mlfqs_load_avg();
mlfqs_recalc_recent_cpu();
}
}
if (MIN_alarm_time <= ticks)
{
thread_awake(ticks);
}
}- mlfqs 옵션이 들어왔을 때에만 advanced scheduler 가 작동할 수 있도록 if 문으로 묶고 각 시간에 맞게 priority, recent_cpu, load_avg 값의 조정이 실행되게 하였다. TIMER_FREQ 값은 1초에 몇 개의 ticks 이 실행되는지를 나타내는 값으로 thread.h 에 100 으로 정의되어 있다. 이에 따라 pintos kernel 은 1 초에 100 ticks 가 실행되고 1 ticks = 1 ms 를 의미한다.

void lock_acquire(struct lock *lock)
{
ASSERT(lock != NULL);
ASSERT(!intr_context());
ASSERT(!lock_held_by_current_thread(lock));
struct thread *curr = thread_current();
/* mlfqs 스케줄러 활성화시 priority donation 관련 코드 비활성화
!thread_mlfqs -> RR */
/* 해당 lock의 holder가 존재 한다면 */
/* 통과하면 수정해보기 */
if (lock->holder != NULL)
{
/* 현재 스레드의 wait_on_lock 변수에 획득 하기를 기다리는 lock의 주소를 저장 */
curr->wait_on_lock = lock;
/* multiple donation 을 고려하기 위해 이전상태의 우선순위를 기억,
donation 을 받은 스레드의 thread 구조체를 list로 관리한다. */
list_insert_ordered(&lock->holder->donations, &curr->donation_elem, cmp_donation_priority, NULL);
/* priority donation 수행하기 위해 donate_priority() 함수 호출 */
if (!thread_mlfqs)
donate_priority();
}
sema_down(&lock->semaphore);
curr->wait_on_lock = NULL;
/* lock을 획득 한 후 lock holder 를 갱신한다. */
lock->holder = thread_current();
}
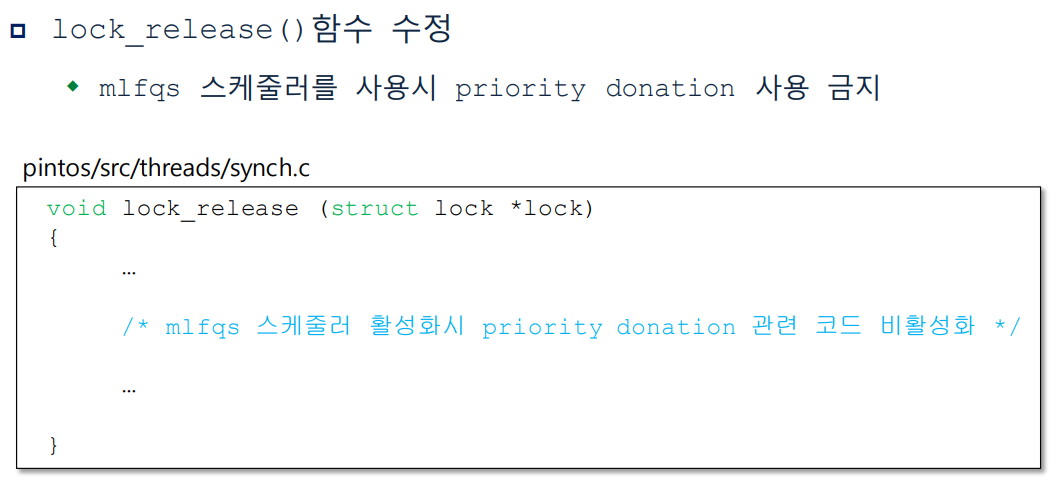
void lock_release(struct lock *lock)
{
ASSERT(lock != NULL);
ASSERT(lock_held_by_current_thread(lock));
lock->holder = NULL;
/* mlfqs 스케줄러 활성화시 priority donation 관련 코드 비활성화
!thread_mlfqs -> RR */
if (!thread_mlfqs){
remove_with_lock(lock);
refresh_priority();
}
sema_up(&lock->semaphore);
}lock_acquire (),lock_release ()함수에서 구현해주었던 priority donation 을 mlfqs 에서는 비활성화시켜주어야 한다. mlfqs 스케줄러는 시간에 따라 priority 가 재조정되므로 priority donation 을 사용하지 않는다.
결과
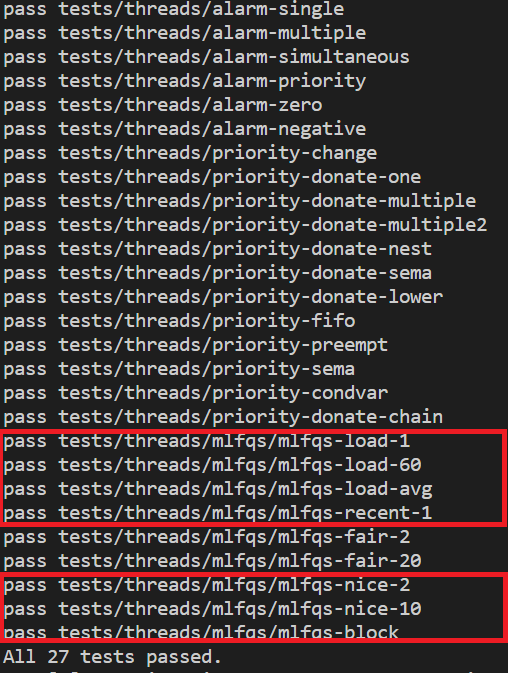
요약
- 추가 함수

- 수정 함수

PintOS Project1 GIthub 주소 PintOS
