4.3 SARSA vs Q-learning
Let’s compare two methods with a following example:
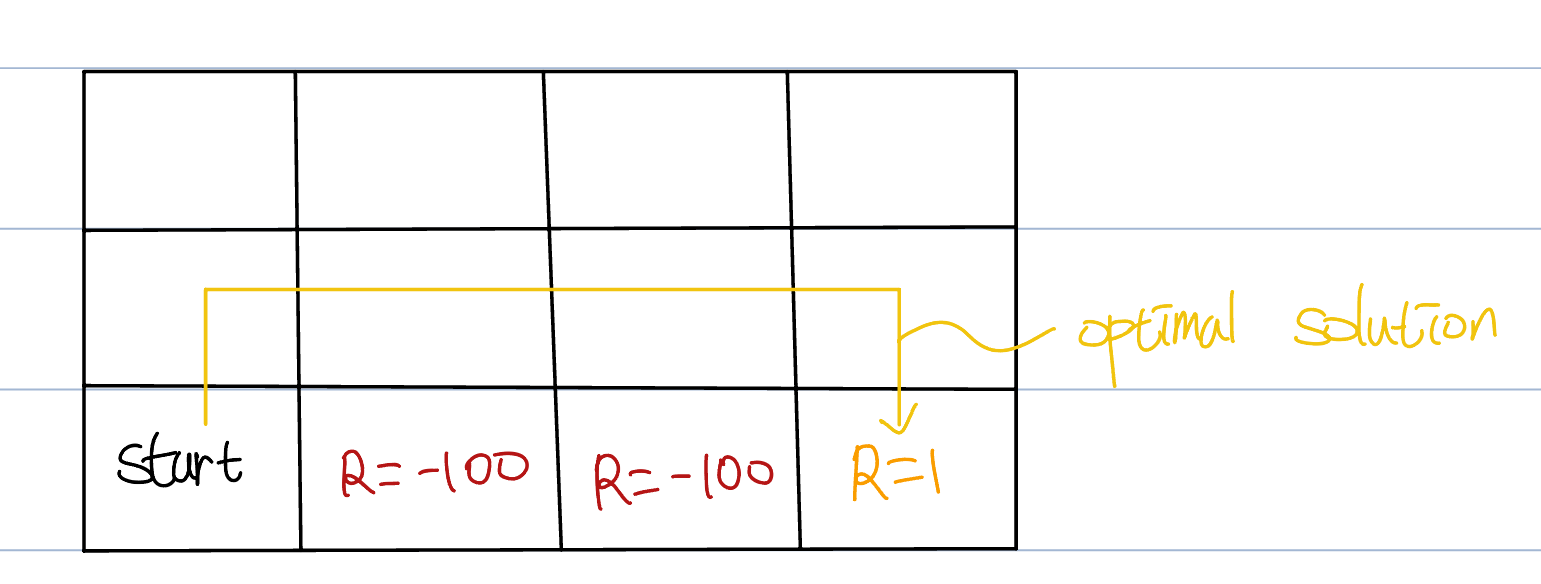
I will denote row 2 column 3 as r2c3(in this figure).
What sarsa do is getting TD-target corresponding to current action and next action. After first episode, r2c3 will be updated.
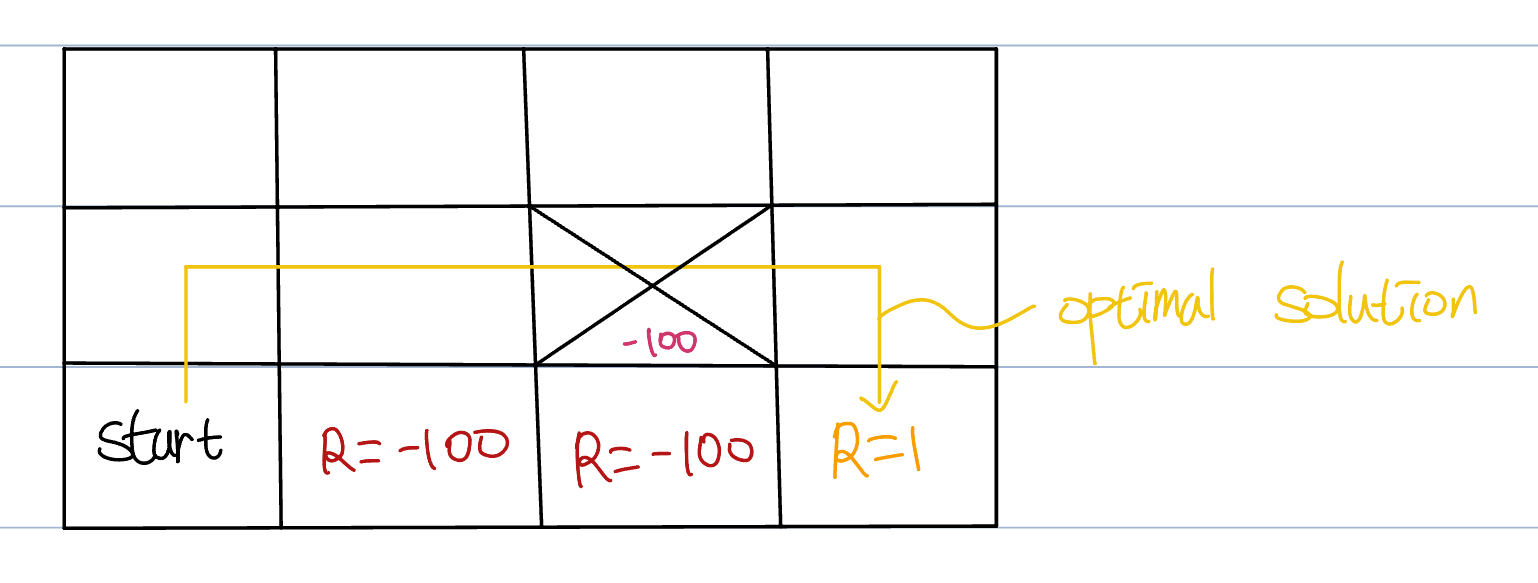
Then, in the second episode, the agent will update r2c2 only negative terms. It will take -100 from lower box, and -100 multiplied with from next box(This is because SARSA do not take the maximum value - as we learned).
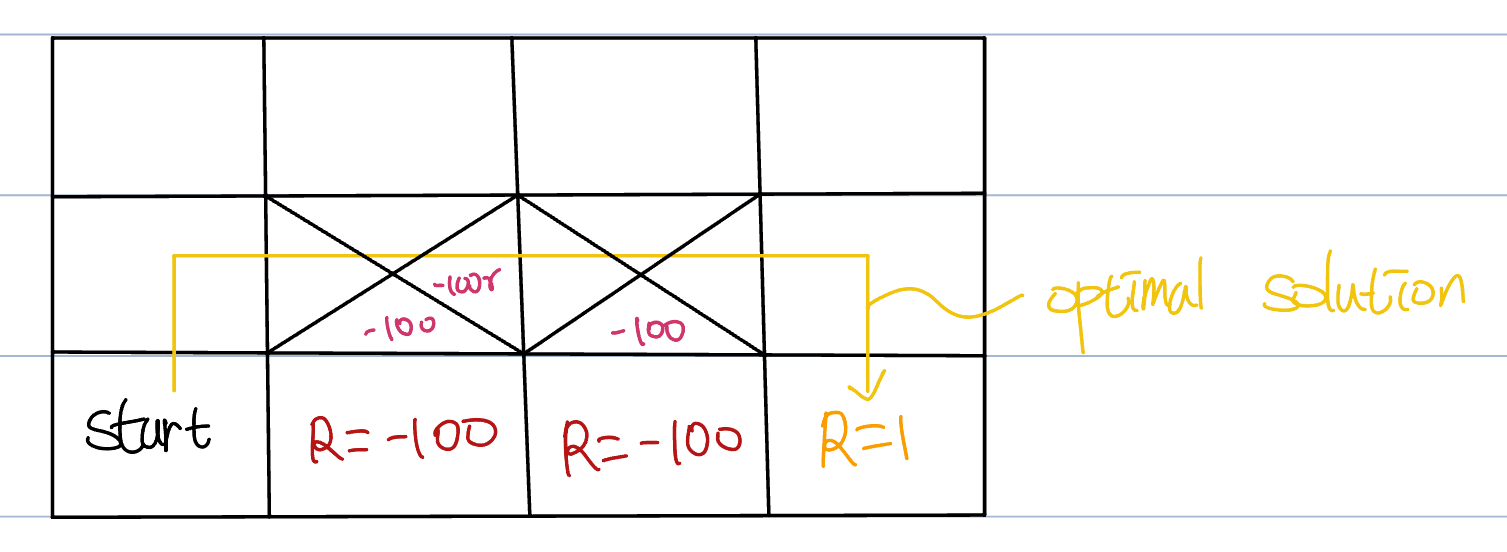
SARSA has the advantage of accounting for negative rewards. However, this advantage can sometimes hinder it from finding the optimal solution.
In contrast, Q-learning takes the optimal policy, so it can find optimal solution.
Both methods find optimal solution eventually. But SARSA takes much time due to its prioritizing safety.
