Reinforcement Learning - hyukppenheim youtube
1.1-1. Q-learning
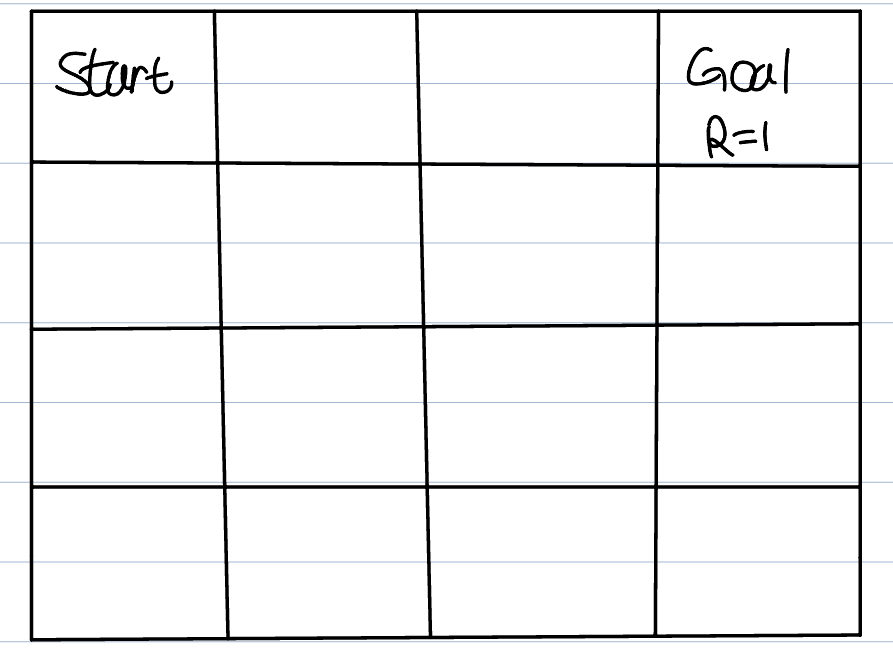
2.2-1. Markov Decision Process(MDP)
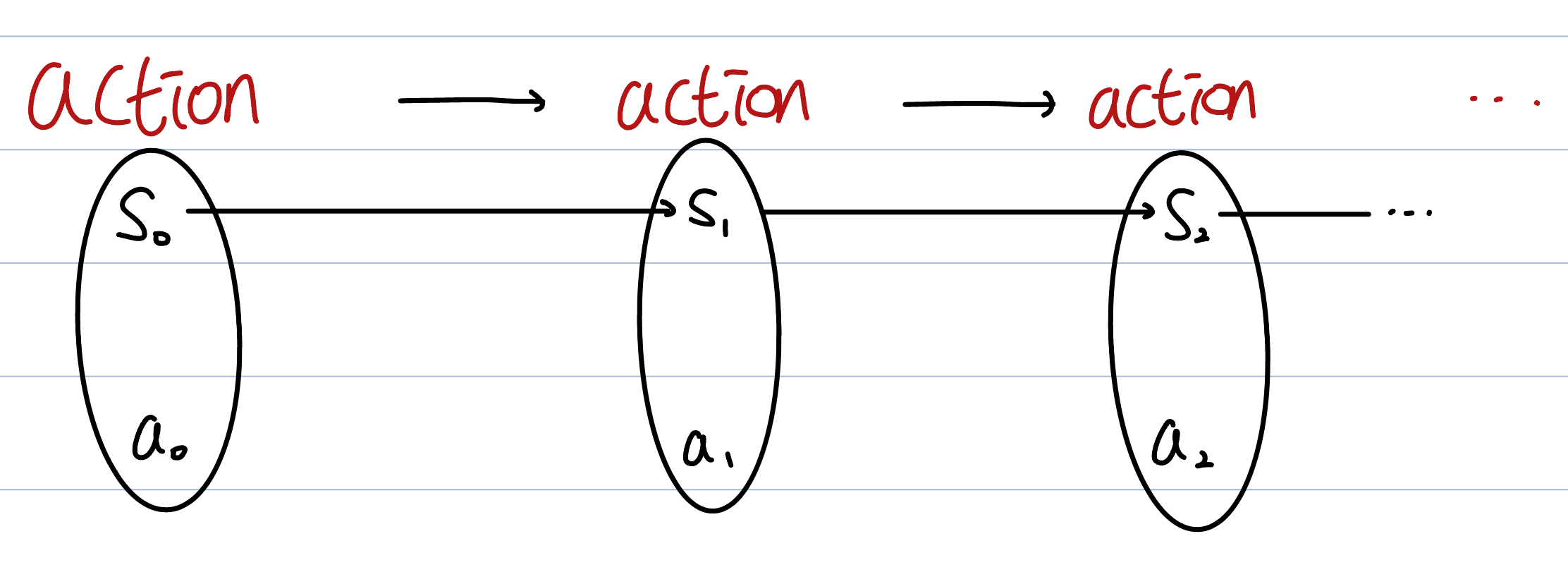
Decision means, the agent decides what action to take in each state.Every action($$a_t$$) leads to next state($$s_t$$).The first important properties
3.2.2 State value function, Action value function & Optimal policy

In this chapter, we will focus more on expected return.State Value Function is a function for the return expected from now on. This function evaluate
4.2.3 Bellman equation

Bellman equation is about method of representing state value function and action value function. By applying Bellman equtaion, we can express state v
5.3.1 Optimal policy - more details

As we have learned, the optimal policy is a function that maximizes the state value function. The state value function focuses on maximizing the rewar
6.3.2 Monte Carlo(MC)
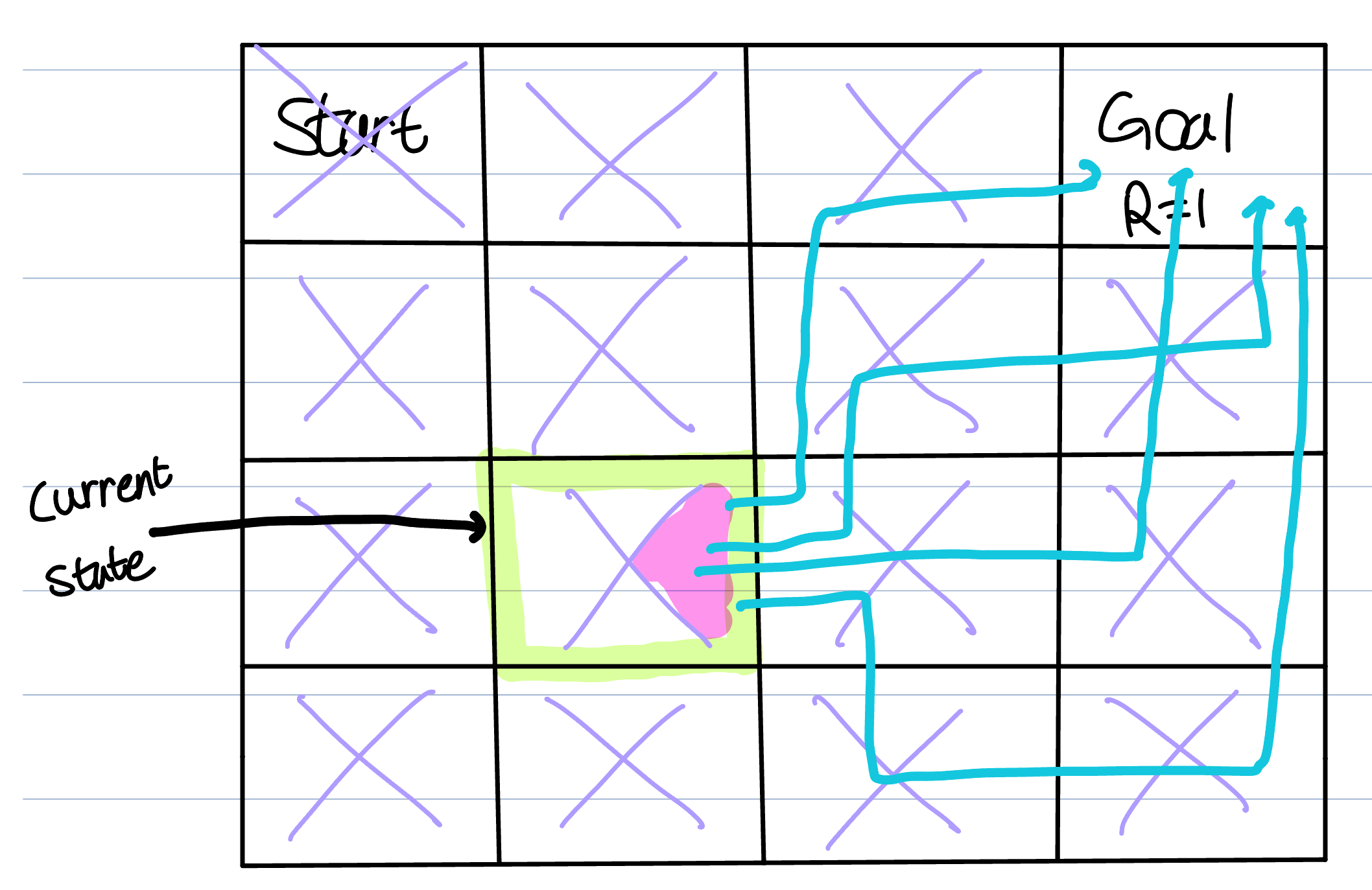
We have learned how to calculate maximum value of state value function by optimal policy. If the $$Q^$$ is given, what we need to do is just find the
7.3.3 Temporal difference(TD) & SARSA
Recall the Bellman equation :
8.3.4 MC vs TD
Temporal difference has a problem.
9.4.1 On-policy vs Off-policy
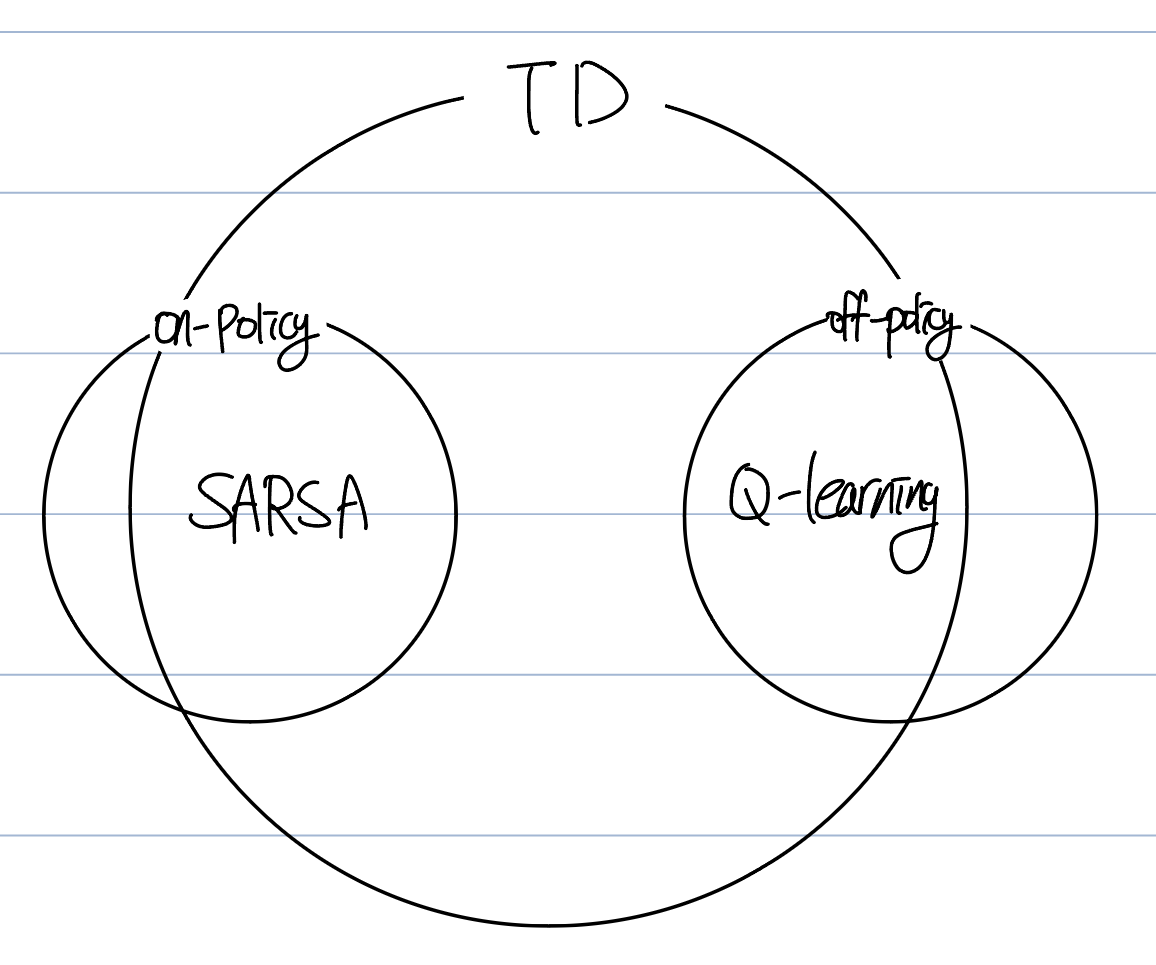
Relationship between on-policy & off-policy
10.4.2 Q-learning(advanced)
We use off-policy in the Q-learning. We apply greedy action for target policy, and $$\\epsilon$$-greedy action for behavior policy.Since we use greedy
11.4.3 SARSA vs Q-learning
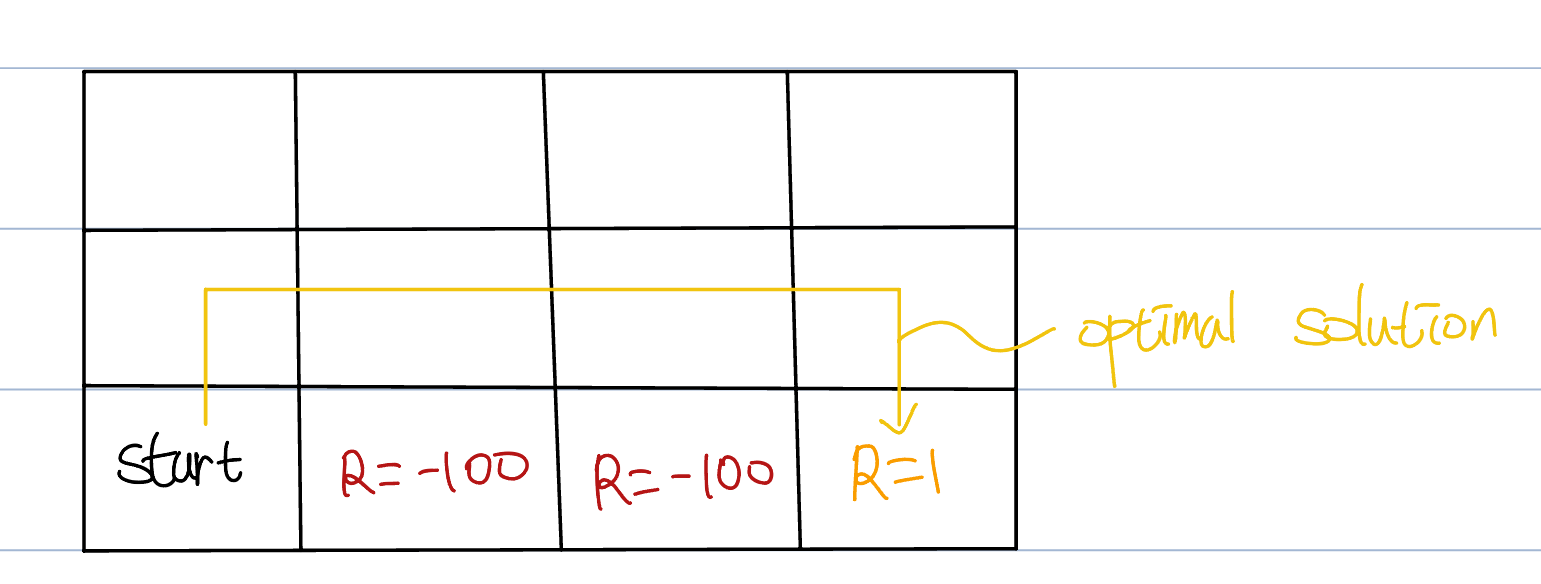
Let’s compare two methods with following example:
12.4.4 n-step TD vs n-step Q-learning
recall equation for $$Gt$$(expected reward)$$\\begin{aligned}G_t &= R_t + \\gamma R{t+1} + \\gamma^2 R{t+2}…\\&= R_t + \\gamma R{t+1} + \\gamma^2 G\_{
13.5.1 2013 DQN paper review
Let’s review Q-learning in the previous lecture.The action value function has target policy and transition pdf.