
오늘 문제를 풀다가 실버문제에 막혀서 레퍼런스를 봤다.
https://www.acmicpc.net/problem/12761
12761번 돌다리 실버1
레퍼런스 : https://young1403.tistory.com/29
왜 못풀었나
BFS를 돌리는데 각 케이스마다 리스트가 10배씩 늘어났다.
정답 코드중 일부
def cal(l):
arr = [l+1,l-1,l*a,-l*a,l*b,-l*b,l+a,l-a,l+b,l-b]
return arr내 생각에는.. 시간제한 1초에 케이스가 10배씩 뻥튀기되는걸 감당할 수 없다고 생각했다.
간단하게만 봐도 케이스 10번돌면 list 구성요소가 10억개에 달한다...
O(10^logN)이라는 말이 된다.
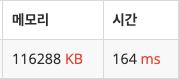
하지만 실제로 코딩해보니 164ms만에 문제가 풀려버렸다.
이에 대해 곰곰히 생각을 해 보았다.
시간이 줄어든 이유
첫번째로, BFS를 돌린다고 해도 최대 계산량이 정해져 있다.
시작이 1, 끝이 100000, A가 2라고 했을때

무슨짓을 해도 17번 안에 끝난다.
그러면
- 아니 17번이면 10^17번인데 그게 적은건 아닐껀데
라고 분명히 말이 나올 것이다.
하지만, 우리는 정해진 숫자에 어떻게 가야하는지를 파악해야 하기 때문에
v = [0 for _ in range(100001)]
1차원 visited 리스트를 사용할 것이다.
이 list를 체우는데는 N이면 끝날 것이고, 아무리 많이 계산해봐야
100000번 안에 끝날 것이다.
또한, A의 값이 작다는 것은 계산을 많이 한다는 것이고,
Visited 리스트에 값이 많이 체워진다는 것이니 중복이 많이 발생할 것이고,
불필요한 오버헤드가 많이 줄어든다는 것을 알 수 있다.
따라서
우리는 10배씩 증가하는 이 문제의 경우에도
많아봤자 10만번의 연산 안에 계산이 왠만하면 끝난다는 것을 알 수 있고,
잘못된 계산량 추측으로 인해 실제로는 빠르게 끝날 계산 방법을 사용하지 못할 수 있다.
결론
계산량을 추측할때는 왜 그런지 정확한 이유를 찾아야 된다.
단순히 list가 10배씩 늘어나서 라는 생각은
Big O 에 매몰되어 재대로된 계산과정을 무시하는 결과를 낳게 될 것이다.
Big O 는 거짓말을 하진 않지만, 잘못된 사용으로 인한 오버헤드가 발생할 수 있다는것을 명심하자.
