

설 연휴 첫날이다. 다른 사람들은 집도 가고 약속도 잡고 해서 강의실에 5명도 안남았다. 근데 할게 너무 많이 쌓여있고 기차도 못 잡은 나는 그냥 공부나 해야된다.
집을 짓고 지어도 계속 없어지는 저 비버처럼 공부할게 끊이지 않는다.

하지만 실력도 없는 내가 경력직/뛰어난 신입들과 싸워서 이길려고 하면
남들보다 배 이상은 노력해야된다고 생각한다.
비전공자에 코딩 이제 시작한 나는 쉴 틈이 없다.
팝콘이나 씹기 싫으면 공부나 하자
KMP
kmp는 knuth , morris , pratt 교수에 의해 만들어진 문자열 탐색 알고리즘이다. 하나하나 찾아가는 Naïve String Search 알고리즘은 시간복잡도가 무려 O((N-M)M)이 나온다고 한다. 문자열 10만자만 넘어가도 컴퓨터가 죽을수도 있다.
그렇기 때문에 우리는 시간복잡도를 n 수준으로 끌어내릴 필요가 있는데, 그 방법이 KMP 알고리즘을 쓰는 것이다.KMP의 시간복잡도는 O(M+N)이다.
그런데 앞에서 본 LCP랑 KMP의 차이점이 무엇인가? 라는 고민이 생기긴 하는데, 두 알고리즘은 비슷한 쓰임세를 가졌지만 완전 다른 알고리즘이다.
마치 아일랜드 사람한테 영국인이냐고 묻는거와 비슷하다.
착한 사람이라면 이해하고 넘어가겠지만 흥분한 상태라면 그대로 머리가 깨질 각오를 해야될 수준이다..
lcp와 kmp의 차이점을 설명하자면
-
LCP는 두 문자열의 '가장 긴 공통되는 문자열' 을 찾는 알고리즘이다.
-
KMP는 한 문자열이 다른 문자열의 어느 부분에 속해있는지를 찾는 알고리즘이다.
즉, KMP는 우리가 ctrl+f로 문서의 특정한 단어를 찾는 것이고,
LCP는 논문의 표절 검사 등을 하기 위해 사용되는 알고리즘이라 생각하면 편하다.
KMP 이론
kmp 알고리즘의 기본 아이디어는 문자열을 하나하나 확인 할 필요가 없다는 것이다.

위 그림을 보면 한번에 이해가 된다.
문자열을 비교하다, 일치하지 않는 문자열이 나왔을때, 비교 문자열의 위치를 단순히 오른쪽으로 한 칸 움직이는 것이 아닌, 비교할 필요가 없는 부분은 뛰어넘어 버린다는 것이다.
이러한 사소한 차이 덕분에, 위 그림에서는 3번의 연산을 아낄 수 있었다.
9번 연산 해야 할 걸 6번으로 줄었으니, 거의 33퍼센트에 가까운 이득을 보았다는 것이다.
물론 저 방식이 kmp 이론은 아니고, 이해를 돕기 위한 자료이다.
다음과 같은 상황을 생각 해 보자.
긴 문자열 1번이 주어지고,
그 문자열과 비교하는 문자열 2번이 주어진다.
문자열 2번은 ABCDABD인데, AB가 반복이 된다.
- A B C D A B D
감이 오는가?
만약에 비교할 문자가
ABCABCD... 라고 생각해보자.
- ABCABCD....
- ABCDABD
ABC까지는 맞는데 다시 A가 나오니 맞지 않는 문자열이다.
하지만 틀렸다고 해서 비교문자를 오른쪽으로 한칸 미는 것이 아닌,
AB에 맞춰서 밀게 되는 것이다.
- ABCABCD...
- _ _ _ABCDABD
이렇게 한번에 3칸을 밀어 AB가 일치하게 만들어 버리게 되면
연산량이 확 줄어드는 효과를 만들 수 있다!
이렇게 연산량을 줄여버린 것이 KMP 알고리즘이다.
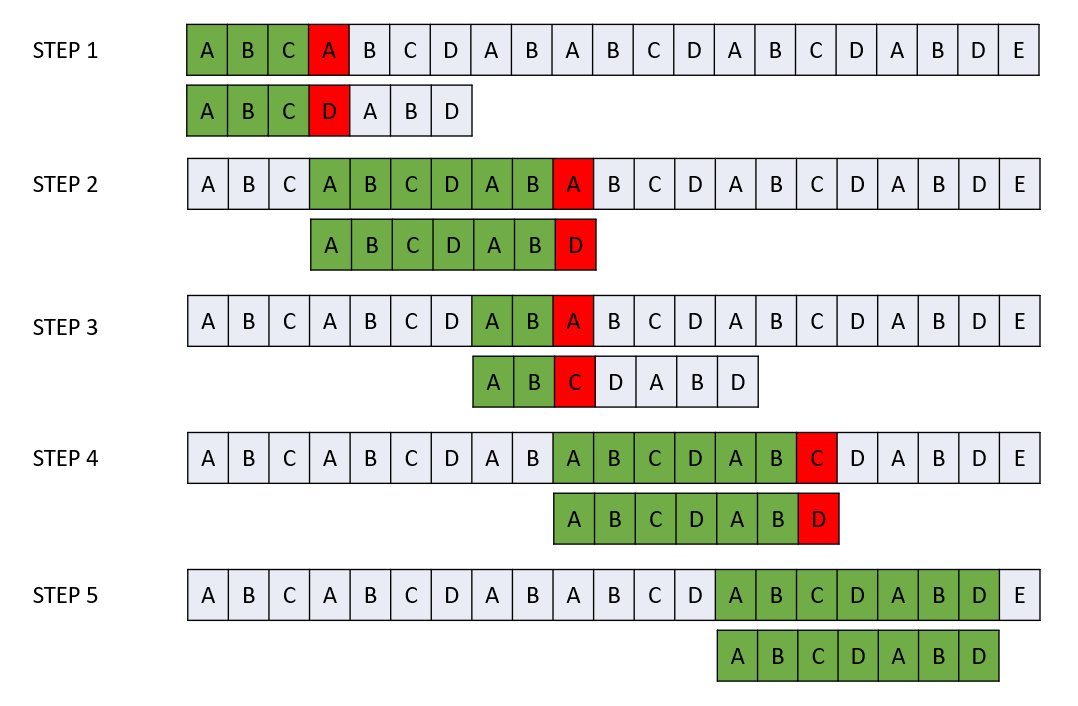
더욱 자세하게 설명이 되어 있는 그림이니 한번씩 보고 이해하도록 하자.
배열 만들기
KMP 알고리즘을 구현하기 위해서는 2단계를 거쳐야 한다.
그 첫번째 단계가 파이 배열 만들기 이다.
table = [0 for _ in range(len(compare))]
i = 0
for j in range(1,len(compare)):
while i>0 and compare[i] != compare[j]:
i = table[i-1]
if compare[i] == compare[j]:
i += 1
table[j] = i
배열을 만들기 위한 코드이다.
여기서 중요한 코드는 for-while 구문이다.
-
j는 문자열의 처음부터 끝까지 돌며 비교를 하기 시작한다.
-
while구문을 통해 만약 앞의 글자와 뒤의 글자가 다르다면
i = table[i-1]을 한다. -
만약에 같다면, i의 값을 하나 올리고, table[j] = i 를 한다.
이렇게 되면 table[j]이 같은문자열을 몇번째로 가지는지를 나타내게 된다. 말이 참 기묘한데 다음 예시를 보자.
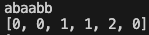
여기서 보면 001120이라고 나와있다.
하나하나씩 보자.
-
a는 자기 자신 밖에 없기 때문에 0의 결과가 나온다.
-
ab는 b가 첫번째 부터 비교했을때 같은 문자열이 없기 때문에 0 이 나온다.
-
aba는 마지막 글자인 a가 첫번째 글자와 같음으로 1이 나온다.
-
abaa도 마찬가지로 1이 나온다.
-
abaab는 처음 ab와 마지막의 ab가 같은 글자임으로, 2개의 글자가 겹침으로 2가 나온다.
-
abaabb는 b와 첫글자 a가 다름으로 0이 나온다.
이거 그냥 보면 뭔소리인지도 이해 안가고
내가 뭔말하는지도 이해가 안 갈 것이다.
그럼으로 코드를 여러번 돌려가면서 이해를 하도록 하자.
KMP알고리즘 실행
result = []
i = 0
for j in range(len(arr)):
while i>0 and compare[i] != arr[j]:
i = table[i-1]
if compare[i] == arr[j]:
i += 1
if i == len(compare):
result.append(j-i+2)
i = table[i-1]
return result
알고리즘 자체가 엄청 짧고 간단해서 이해도 빠르다.
이해가 안된다고 자책하지 않아도 된다.
어디까지나 플래티넘 수준에서 간단하다는거지 골드 이하의 알고리즘과는 수준차이가 상당히 난다.
먼저, 설명하기 전에 용어를 정하고 가자.
문서에서 단어를 찾는 상황이라고 가정을 해야 된다.
코드에서 compare는 찾을려는 단어, arr은 문서라고 생각을 해야 된다.
이거 생각보다 이해하는데 중요하니 확실히 해야된다.
다시 코드로 돌아와서,
코드를 읽다보면 뭔 개소리지? 싶을거다. 좀 더 자세히 설명을 하자면
처음에 i = 0 이기 때문에 while 구문을 전혀 돌지 않는다.
이게 진짜 중요하다. 저거는 같은 글자를 만났을때, 어느정도를 '점프'해야되는지 결정하는 코드이기 때문이다.
그래서 if 구문부터 먼저 봐야한다.
if compare[i] == arr[j]:
i += 1
if i == len(compare):
result.append(j-i+2)
i = table[i-1]이 코드를 보면, 단어[i] == 문서[j]가 되었을때 실행이 된다.
같은 코드를 만났으니, i+=1을 한다.
이후 다음 루프를 돌때 i와 j가 같이 +=1 이 되니,
같은 문자열이 계속 된다면 같이 커질 것이다.
이후 i == len(단어) 라는 뜻은 일치하는 단어를 찾았다는 뜻이다!
그러니까 result.append(j-i+2)로 이 문자열의 위치를 매핑한다.
이후 i = table[i-1]을 해서 i를 초기화 시킨다.
왜 초기화가 되냐고?
위의 실험 결과에서 알 수 있듯이, 겹치지 않는다면 0이 되기 때문에
i = 0이 될 것이고, 그렇다는 것은 단어[i]와 문서[j]가 같지 않다면, O(N)의 속도로 계속 문자를 비교해 갈 것이다.
이렇게 해서 KMP 알고리즘에 대한 공부가 끝이 났다.
전에 LCP 알고리즘을 해서 한번 머리 터질때까지 공부해서 그런건지
알고리즘 공부에 감을 잡아서 그런건진 몰라도 생각보다 할만했다.
