
문득 궁금해진게 있다.
public void parseApiCall() {
for (String code : KEPCO_Code) {
Mono<String> apiCallResult = publicService.makeApiCall(
"KEPCO_URL",
"KEPCO_Path",
"KEPCO_Key",
"year=" + LY.getYear(),
"month=" + LY.getMonth(),
"metroCd=" + code,
"apiKey="
);
apiCallResult.subscribe(response -> {이전에 비동기 처리를 했던적이 있다.
처음 해보던 방식이라 참 신기했는데, 요청값이 자기 맘대로 실행되서 처리가 되는게 참 신기했다.
그런데 비동기 처리 방식을 이용하면 성능이 많이 향상된다고들 하지 않는가?
그래서 이게 얼마나 효율적이길레 그런가 궁금해졌다.
@GetMapping("/update_KEPCO")
public void KEPCO_update() {
long startTime = System.currentTimeMillis(); // 시작 시간 측정
kepco.parseApiCall();
long endTime = System.currentTimeMillis(); // 종료 시간 측정
long duration = endTime - startTime;
logger.info("Time taken to process /update_KEPCO: {} ms", duration);
}(딸깍!)
그래서 시간 측정을 해 보았다.
위의 코드를 그대로 썼을때의 시간이다.

441ms가 걸리는걸 확인할 수 있다.
그럼 동기로 바꿔보자.
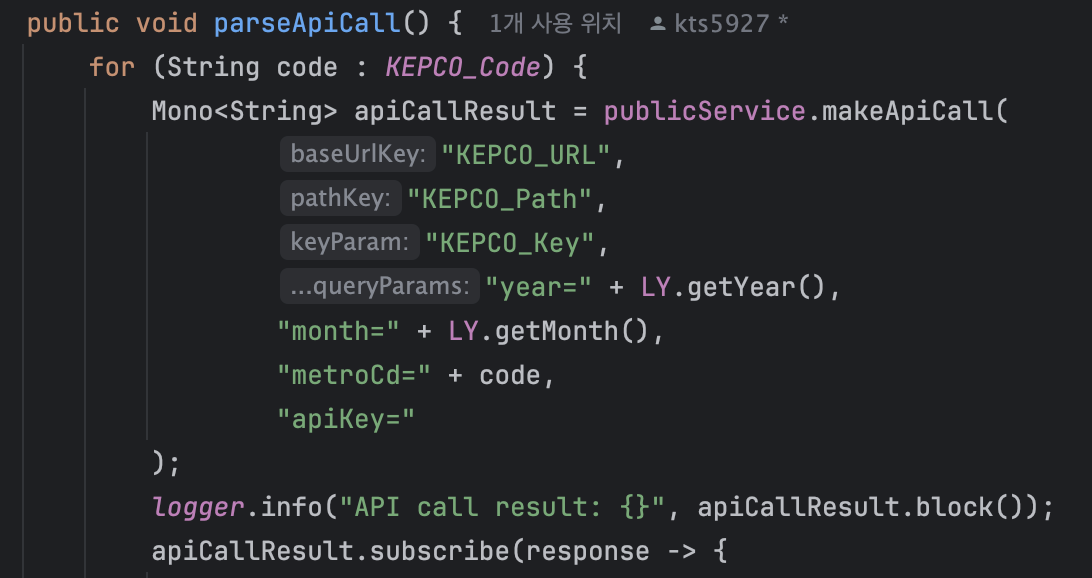
로거를 하나 붙였다.
그냥 .block()를 붙일려니까 Mono는 못한다고 한다.
따라서 API 호출이 끝나면 다음 단계로 넘어가게 했다.
위처럼 바꾸면 어떻게 되냐
기존 방식은
- 1번 요청 처리중
- 2번 요청 처리중
- 3번 요청 처리중
- 4번 요청 처리 요청
- 5번 요청 대기
이런 방식에서
- 1번 요청 처리완료
- 2번 요청 처리완료
- 3번 요청 처리완료
- 4번 요청 처리 요청
- 5번 요청 대기
의 형태로 바뀌는 것이다.
여러개의 요청이 한번에 처리 되는 것이 아니라
하나의 처리가 끝날때까지 기다려야 된다는 것이다.(.block()때문에 다시 못한다)


????????
거의 실행 시간이 6배 차이난다.
private static final String[] KEPCO_Code = {"11", "26", "27", "28", "29", "30", "31", "36", "41", "43", "44", "45", "46", "47", "48", "50", "51"};
legion code는 17개니까 동기 처리가 1개 처리할 동안 비동기는 3개 처리한다는 것이다.
실행 결과가 너무 충격적이라 원래 코드에 logger를 붙여서 다시 실험해 보았다.
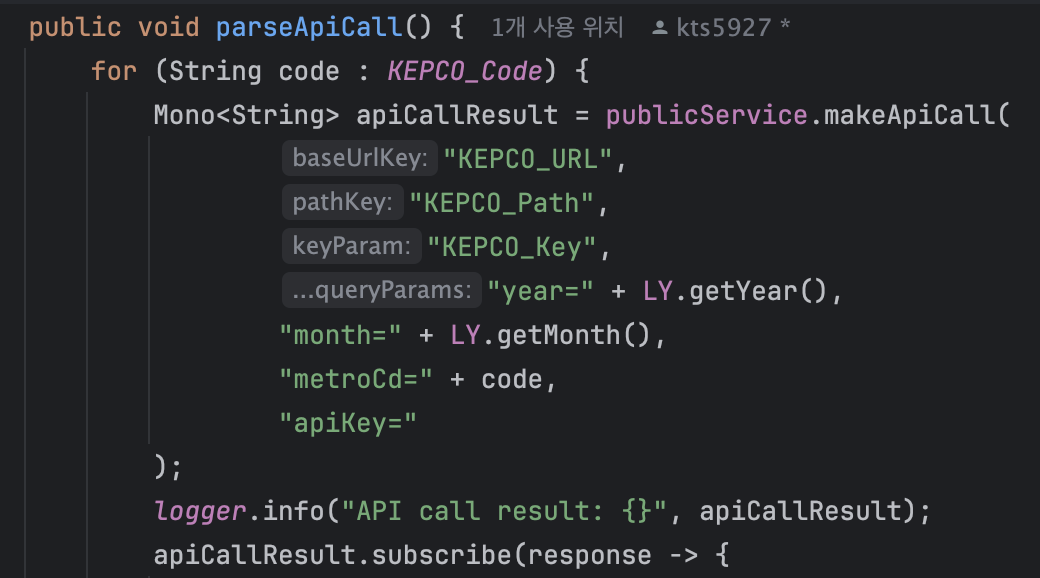
이번에는 .block()을 빼봤다.



여기서도 놀라운 결과가 나왔다.
처리 완료 시간이 그냥 자기 맘대로 나오는 것이다.
즉, 수십번씩 결과를 내서 통계를 내보면 정확한 값을 알 수는 있겠지만,
비동기 처리가 동기 처리에 비해서 비교할 수 없을만큼 빠르다 라는 것은 확신할 수 있겠다.
하지만
- 비동기 처리가 매우 까다로운점
- WebClient를 사용하기 위해 WebFlux 의존성을 추가해야 한다는점
등을 생각해야 겠다.
9월 12일 추가

진짜 내가 미쳐가지고 논블로킹 - 비동기 차이를 내 맘대로 해석했다.
위에서 설명한거는 싹다 비동기-논블로킹 설명이다.
하나의 함수가 다른 함수의 결과값이 끝날때 까지 기다리냐/기다리지 않냐의 문제이지, 동기/비동기의 차이가 아니다.
만약에
def func1(){
print(1)
}
def func2(){
print(2)
}
def func3(){
print(3)
}
func1()
func2()
func3()
(단순 설명을 위한 것이니 실제 동작방식은 신경쓰지 말자.)
위의 코드를 실행할때, func1 -> func2 -> func3 순으로
앞의 함수가 완료되고 다음 일을 처리한다면 그건 동기
앞의 함수가 완료되는걸 기다리지 않고 일을 처리한다면 비동기다.
그래서 React 작업을 할때 보면 useEffect 훅을 통해서 데이터를 받아올때
수신 데이터 : NULL -> 수신 데이터 : Backend Connected!
몇초 후위와 같은 현상을 자주 목격할 수 있다.
왜냐? 수신 데이터가 들어오건 말건 일단 밀어버리기 때문이다.
그럼 blocking/nonblocking은 어떻게 봐야 할까?
def apple(){
for _ in range(1000):
print('사과냠냠')
}
def banana(){
for _ in range(1000):
print('바나나냠냠')
}
def eat(){
print('먹기 시작함')
apple()
banana()
print('식사 끝')
}
eat()위의 코드를 실행할때를 생각해 보자.
블로킹 일때는 eat의 제어권이 apple, banana에게 넘어간다
따라서 동기 처리와 마찬가지로 먹기시작함 -> apple -> banana -> 식사끝 의
처리결과가 나오지만, 여기서 중요한것은 apple, banana를 실행할때 eat의 실행 스레드가 멈춘다!
따라서 불필요한 자원이 많이 들어가게 되는 것이다.
논블로킹일때는 eat는 제어권을 넘기지 않는다
즉 eat, apple, banana가 동시에 실행되는 것처럼 보이지만
eat 실행 -> print()실행 -> apple 실행 -> apple 콜백 안기다리고 바로 banana실행 -> 콜백 안기다리고 print(apple, banana는 병렬처리중)
이렇게 된다는 것이다.
핵심은 스레드가 일을 안하는 오버헤드를 줄일수 있다는 것이다.
여담
https://velog.io/@kts5927/우아콘-리뷰
이전에 우아콘을 리뷰한 적이 있다.
우아한 형제들 팀에서 마주했던 문제사항은
너무 많은 이벤트에서 데이터를 받아와야 해서 프로그램이 느려진다 였는데,
이 이야기가
하나의 메서드를 실행했을때 여러 종류의 데이터를 받아와야 한다는 것이지 않나 싶다.
예시를 들면
public void RequestEvent() {
request1()
request2()
request3()
request4()
...대략 위와 같은 느낌으로 수십개의 데이터를 요청하는데
하나하나 순차적으로 데이터를 요청하니 반응속도가 느려진다는 것이다.
그도 그럴 것이 배민 같은 거대기업은 장난아닌 DB를 보유해서 데이터 찾는데 한세월
요청 개수도 많아서 처리하는데 한세월
그리고 서비스 요청을 했을때 거쳐가는 메서드 개수도 엄청 많을 것이다.
이러한 상황에서도 2초 이상 넘어가버리면 소비자는 왜이렇게 느리냐 일안하냐 라는 생각을 할 것이고
기업의 매출 하락으로도 이어질 수 있는 문제이기 때문이다.
아 그렇구나 하면서 봤는데 실제로 체감되니까
이런 구조 갈아치우기 위해서 신기술 도입하고 코드 다 뜯어고치는 과정이
정말 대단하고 존경스럽게 느껴진다.
과연 난 이런 일을 할 수 있을까...?
