
스키마
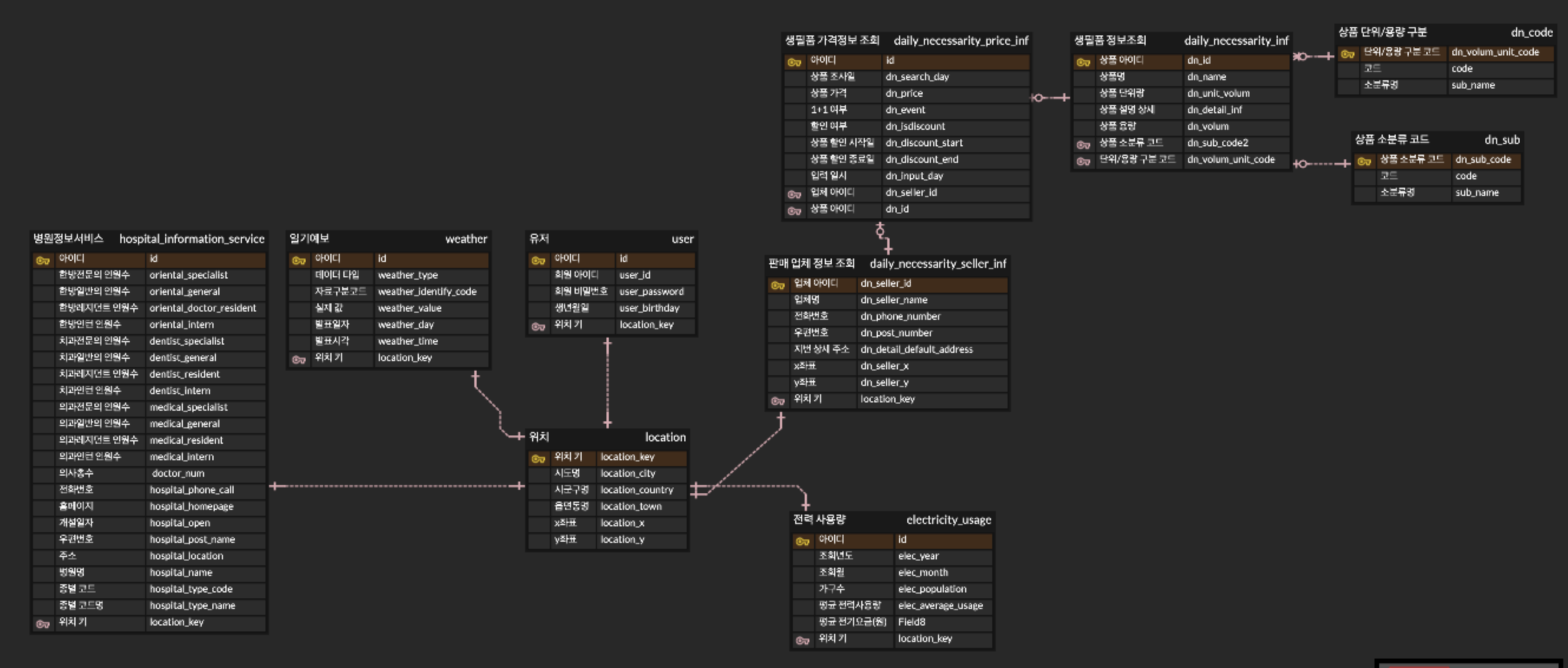
전체적인 설계는 위와 같다.
위치 기반 시스템인 만큼 하나의 위치에 거의 모든 서비스가 묶여있는데, 이를 활용하면 사용자의 위치 하나만 가지고 모든 데이터 서비스를 조회 할 수 있도록 설계하였다.
유저, 날씨 관련
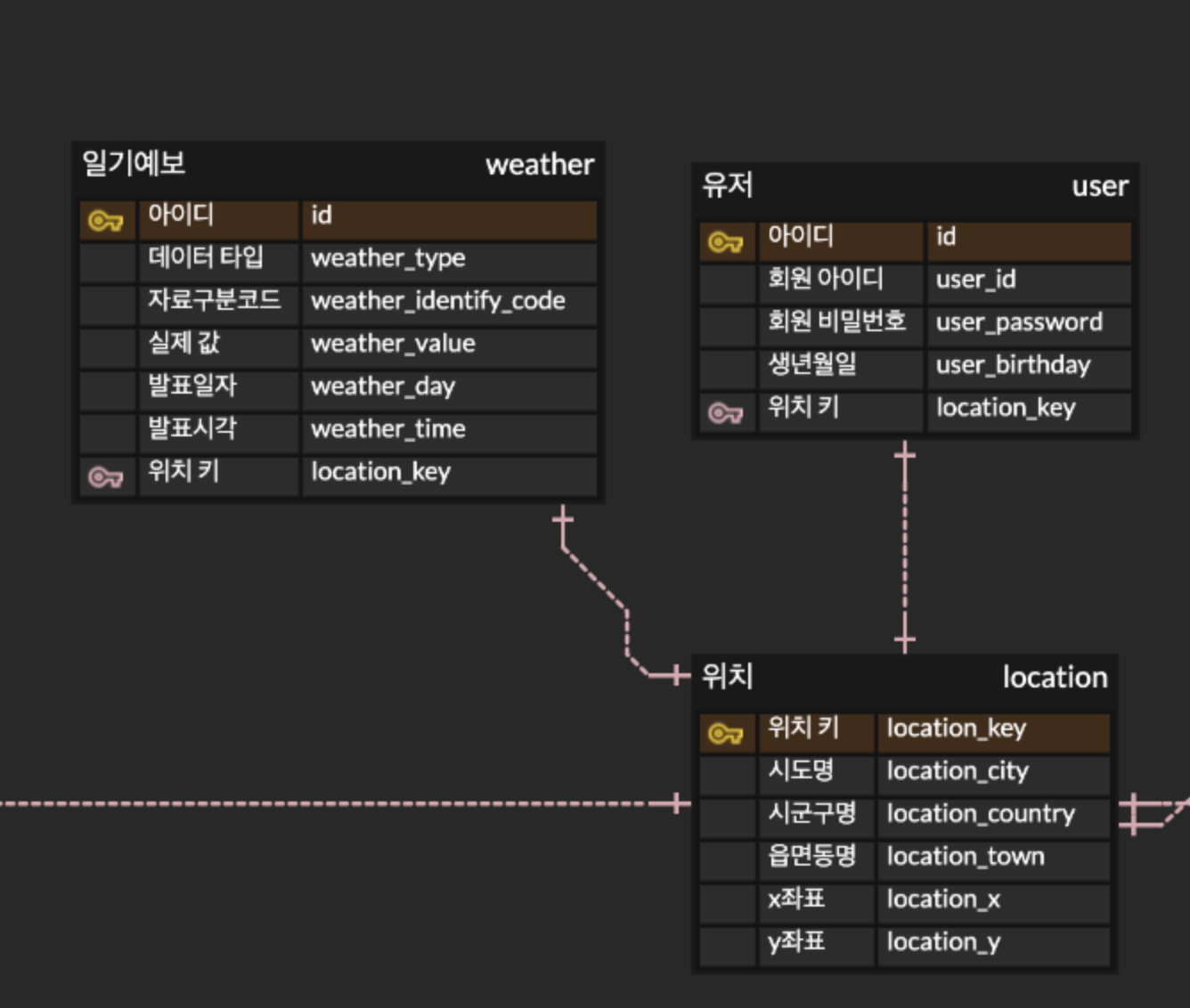
이번에 의도치 않게 일기예보가 큰 도움이 되었다.
그건 바로 날씨 관련 데이터 csv 파일 덕분이다.
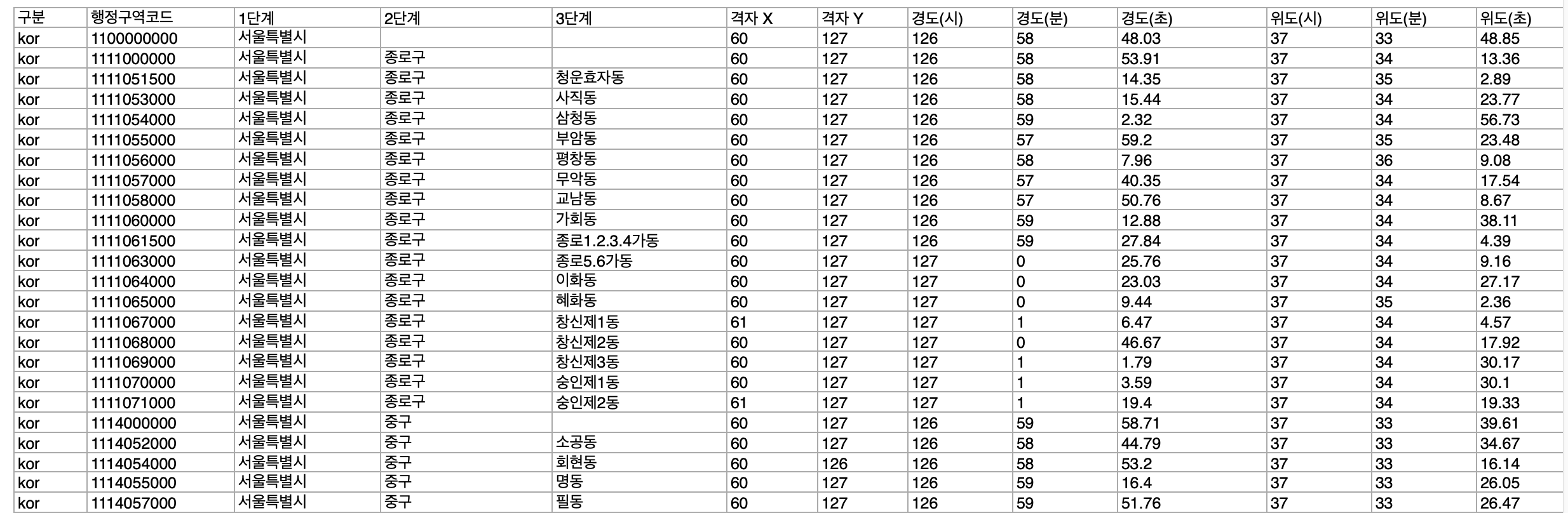
위와 같이 대한민국 전역의 위치 좌표가 다 찍혀있다.
따라서, 위치 데이터는 날씨 위치 데이터를 활용해서 미리 매핑을 시켜놓는것이 가능하다!
우리가 할 일은 각각의 API 주소를 파싱하여 적절한 위치에 연결시키면 되는 것이다.
유저는 회원가입 할 때 3단계(동 주소)까지 입력을 받는것으로 한다.
일기예보는 모든 데이터를 한번에 갱신하게 되면 받아야 하는 데이터의 양이 너무나도 많기 때문에 비어있는 데이터를 요청할때 API를 요청하는 방향으로 설계 할 것 같다.
그 이유는 다음과 같다.

- PostMan으로 API를 요청해본 결과, 하나의 좌표에 해당하는 날씨 데이터를 받아오는데 1000ms가 걸리지 않았다.
- 사이트 이용자들이 일정 숫자 이상 사용할때 특정 지역에 몰릴 것이다.(지방보다는 서울에 몰릴것으로 예상)
- 또한 사이트 실 사용자가 적을 것으로 예상되어 서버에 무리가 가지 않을것으로 보인다.
생필품 관련
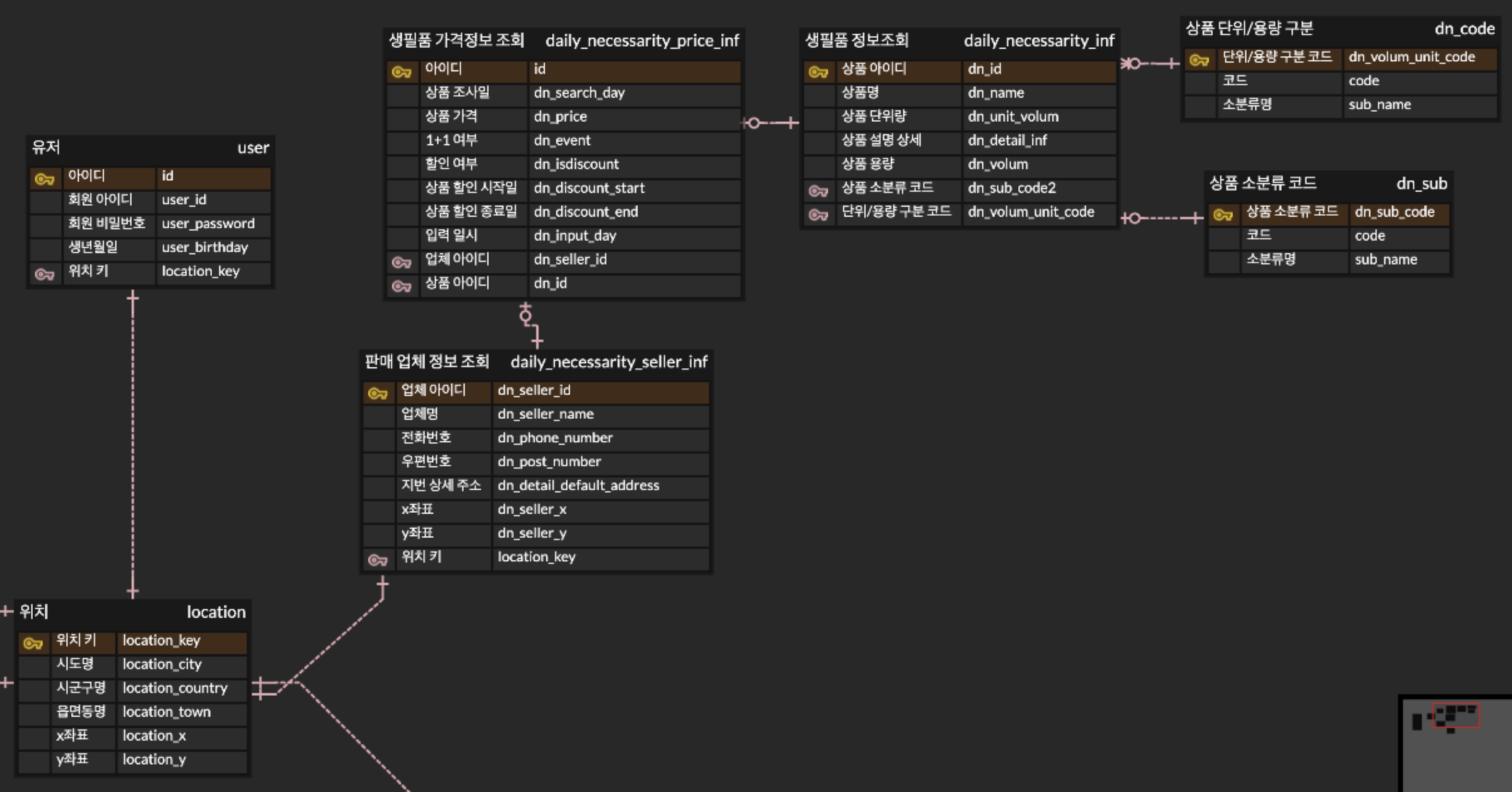
생필품 가격정보를 메인으로 하고, 업체 아이디와 상품 아이디를 외래키로 뒀다.
생필품 정보조회때 상품 소분류와 단위/용량 구분은 코드로 주어지기에 따로 API 요청을 통해 얻을 수 있는 데이터와 연결시켰고, 판매 업체 정보 조회도 위치키를 연결하였다.
왜 업체 정보 조회에 x좌표, y좌표를 중복해서 매핑했는가?
- 공용 엔티티 location의 x,y좌표에는 지역의 x,y좌표가 매핑되어 있다.
- 추후 기업의 지도 서비스를 이용할 계획인데, 이때 x,y좌표를 통해 매핑하여 시각화 시킬 수 있다고 판단하였다.
- 그럼으로 판매 업체의 정확한 x,y좌표가 필요했고, location의 x,y좌표가 아닌 판매업체 정보 조회 API에서 제공하는 정확한 x,y좌표를 따로 저장하였음.
- 하지만 내 주변 생필품 판매목록 서비스를 활용할때, 유저의 위치를 기반으로 데이터를 조회하여야 한다.
- 그럼으로 지번 상세 주소를 파싱하여 location과 연결, 시도/시군구 까지 매핑을 한다.
이렇게 함으로써의 기대 효과는 다음과 같다.
- 유저 위치정보를 기반으로 주변 생필품 판매목록 조회 가능
- 판매 업체의 정확한 위치를 파악 가능하고, 네비게이션 기능까지 사용가능
전력 사용량 관련
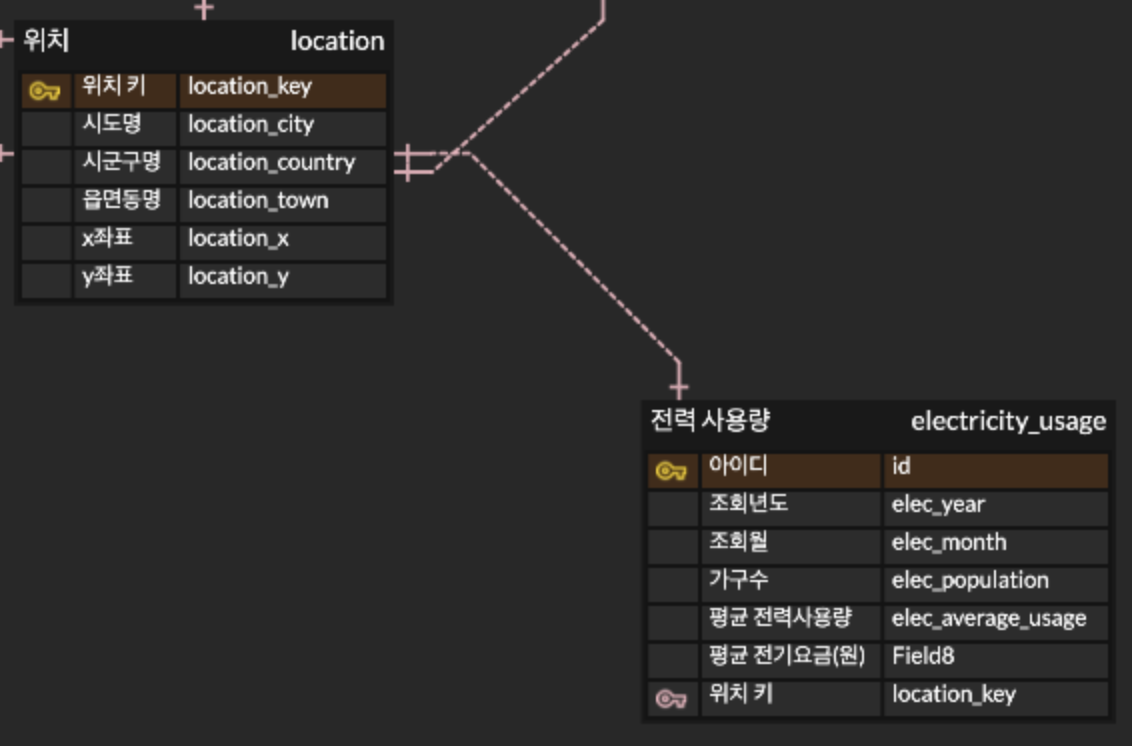
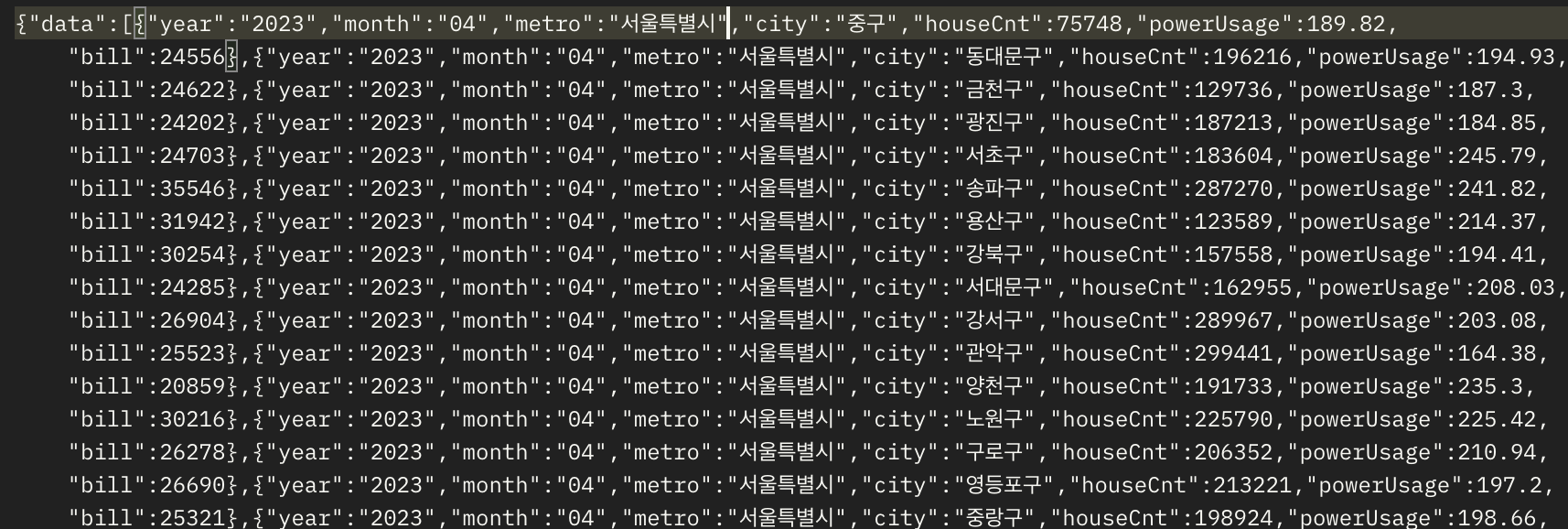
이건 간단했다.
정말 친절히 시도/시군구 까지 나타내주기 때문에 부담없이 바로 매핑이 가능하다.
위와 마찬가지로 위치 기반 데이터 제공을 할때 같이 나온다.
병원 관련
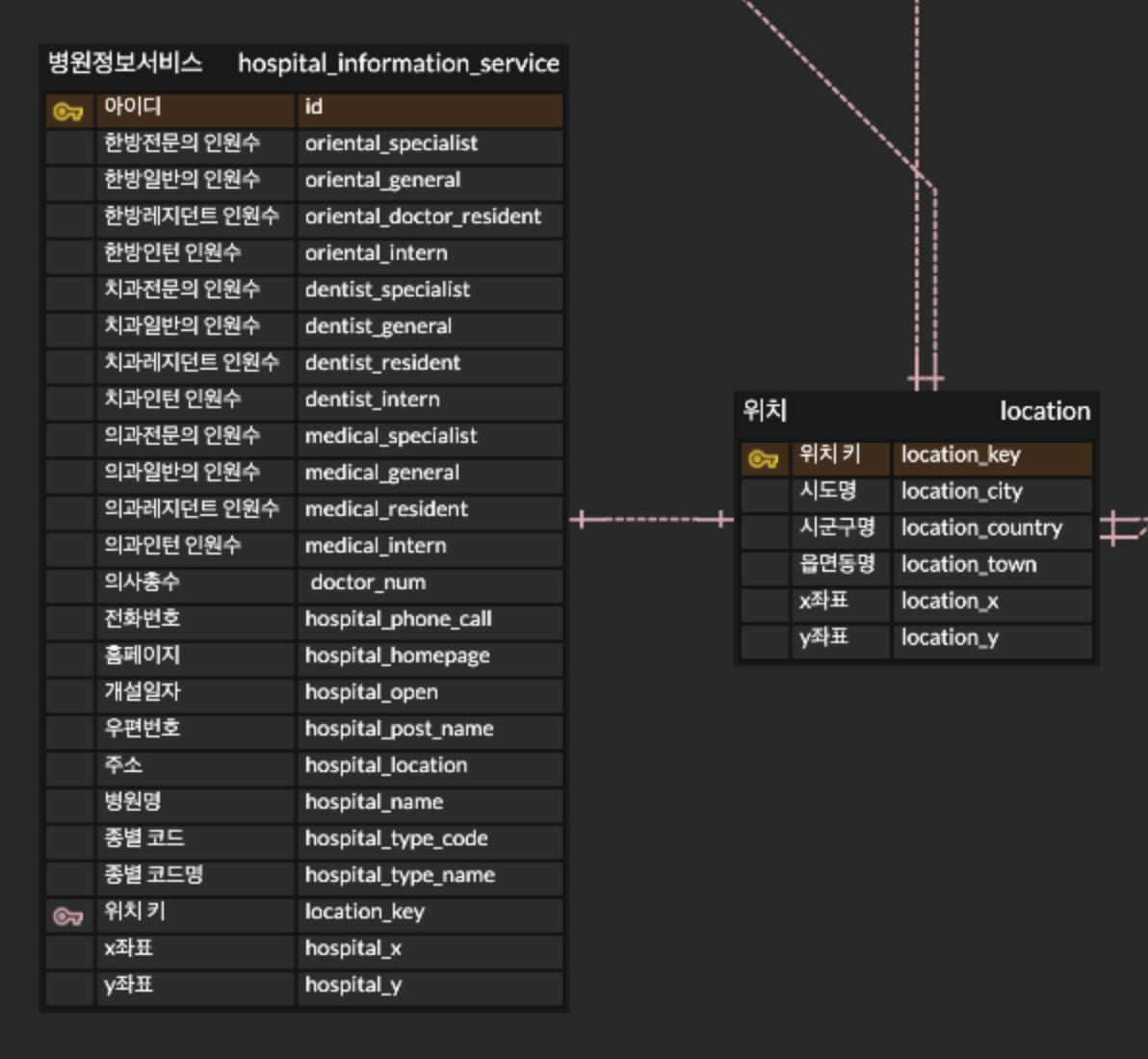
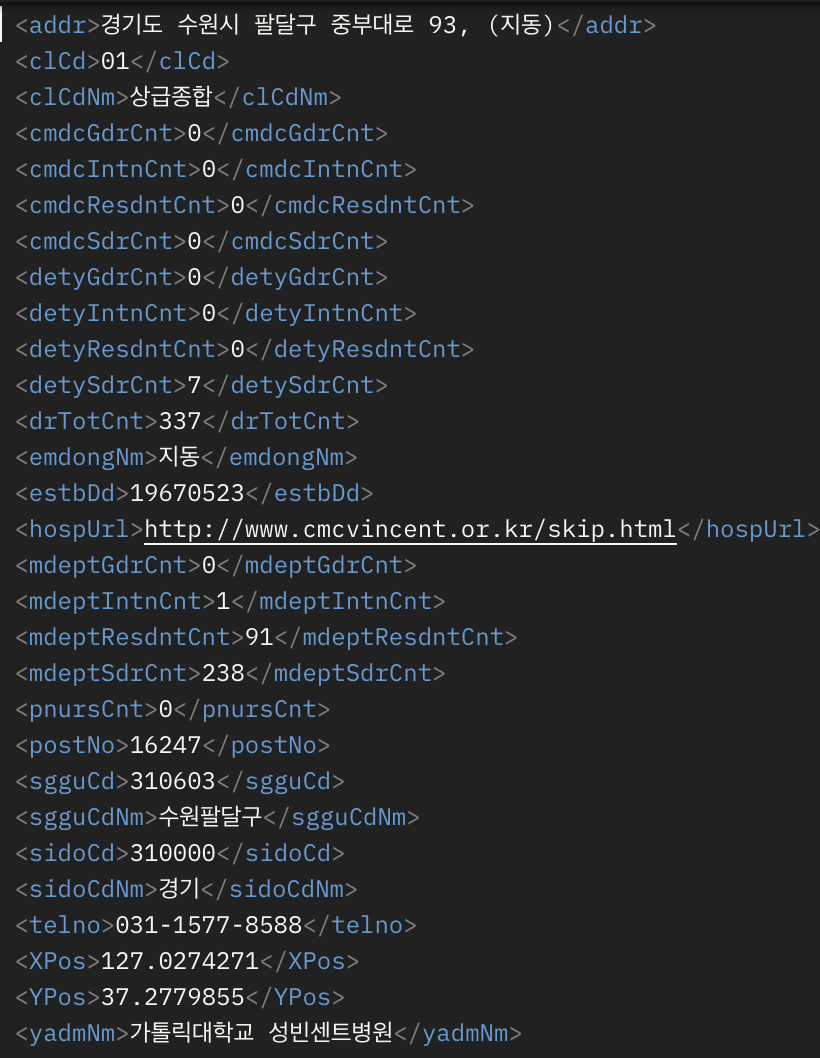
위치 기반 데이터가 주어지지만, 정확한 주소가 아닌 약식으로 데이터가 제공되기 때문에 주소를 파싱해서 매핑해야 한다.
생필품 판매 업체와 마찬가지로 X,Y 좌표를 따로 매핑해야 한다.
병원도 내 위치를 기반으로 주변에 있는 병원찾기/ 특정 병원 찾기 등으로 호출할 예정이다.
추가) 위치 데이터
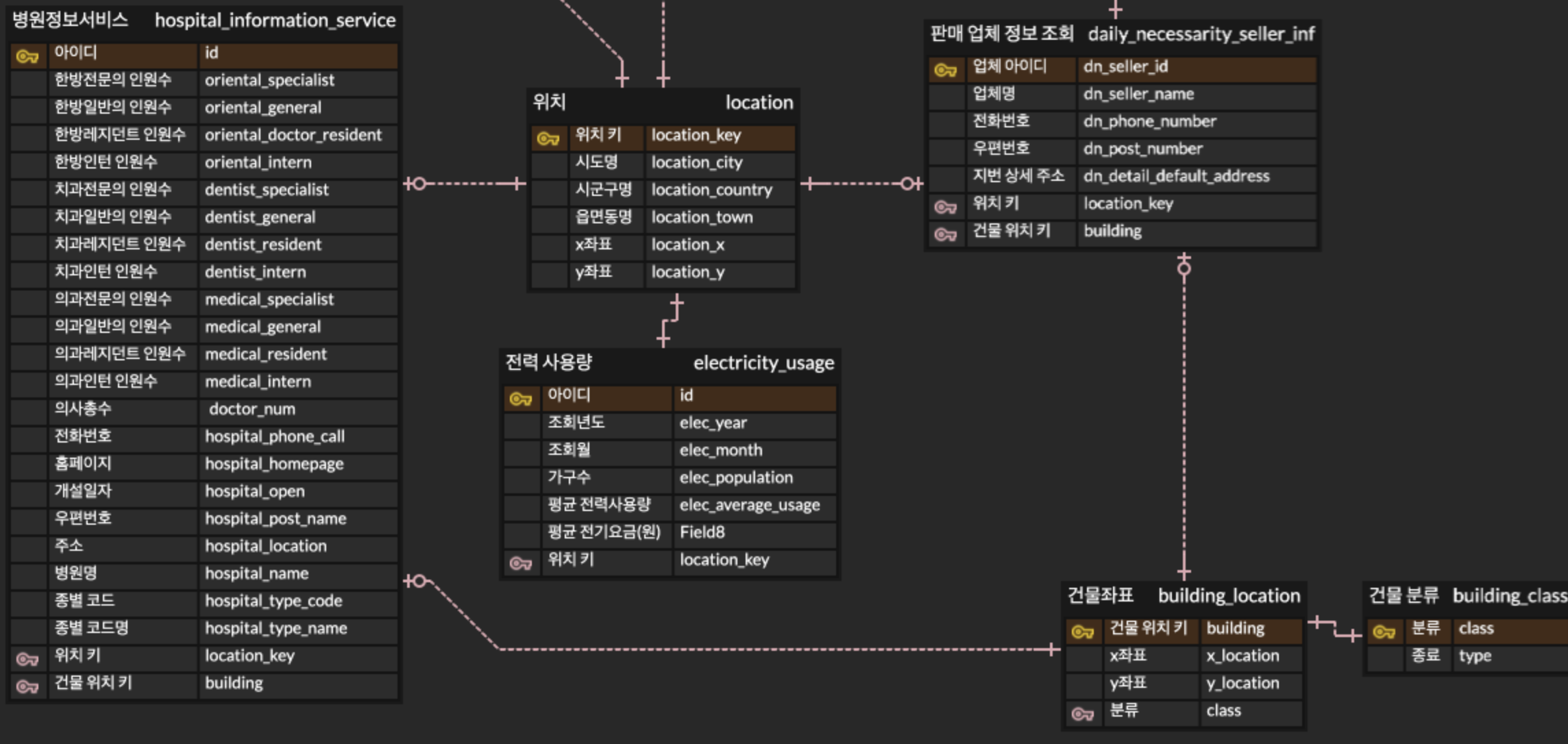
병원/판매 업체는 고유한 주소를 가지기에 따로 빼버렸다.
데이터의 종류가 증가했을때, 건물 좌표만을 가져오기 편하게 하기 위해서 빼뒀다.
건물 분류도 좌표마다 매핑해주는 것이 아닌, 분류 코드에 연결하는 것으로 효율을 올렸다.(데이터 중복 매핑 방지)
데이터 업데이트
이제 데이터가 3가지 분류로 나뉘게 된다.
- 처음 1번만 업데이트 : 위치, 상품 단위/용량구분 코드, 상품 소분류 코드
- 일정 주기마다 업데이트 : 생필품 가격정보, 판매업체정보, 생필품 정보,전력사용량, 병원정보서비스
- 요청마다 업데이트 : 일기예보
이로서 드디어 데이터베이스 정리가 끝이 났다.
