
머리가 빙글빙글 돈다...!
엄청난 데이터 속에서 내가 사용할 데이터를 선별해야 한다.
많은 양이지만 하나씩 해나가도록 하자.
찾는 과정
데이터 출처 : https://www.data.go.kr/index.do
대한민국 공식 전자정부 누리집에 공공데이터포털 이라는 사이트가 있다.
이곳에는 대한민국의 공공기관/공기업/사기업 등이 공공 데이터 제공 API를 배포하고 있다.
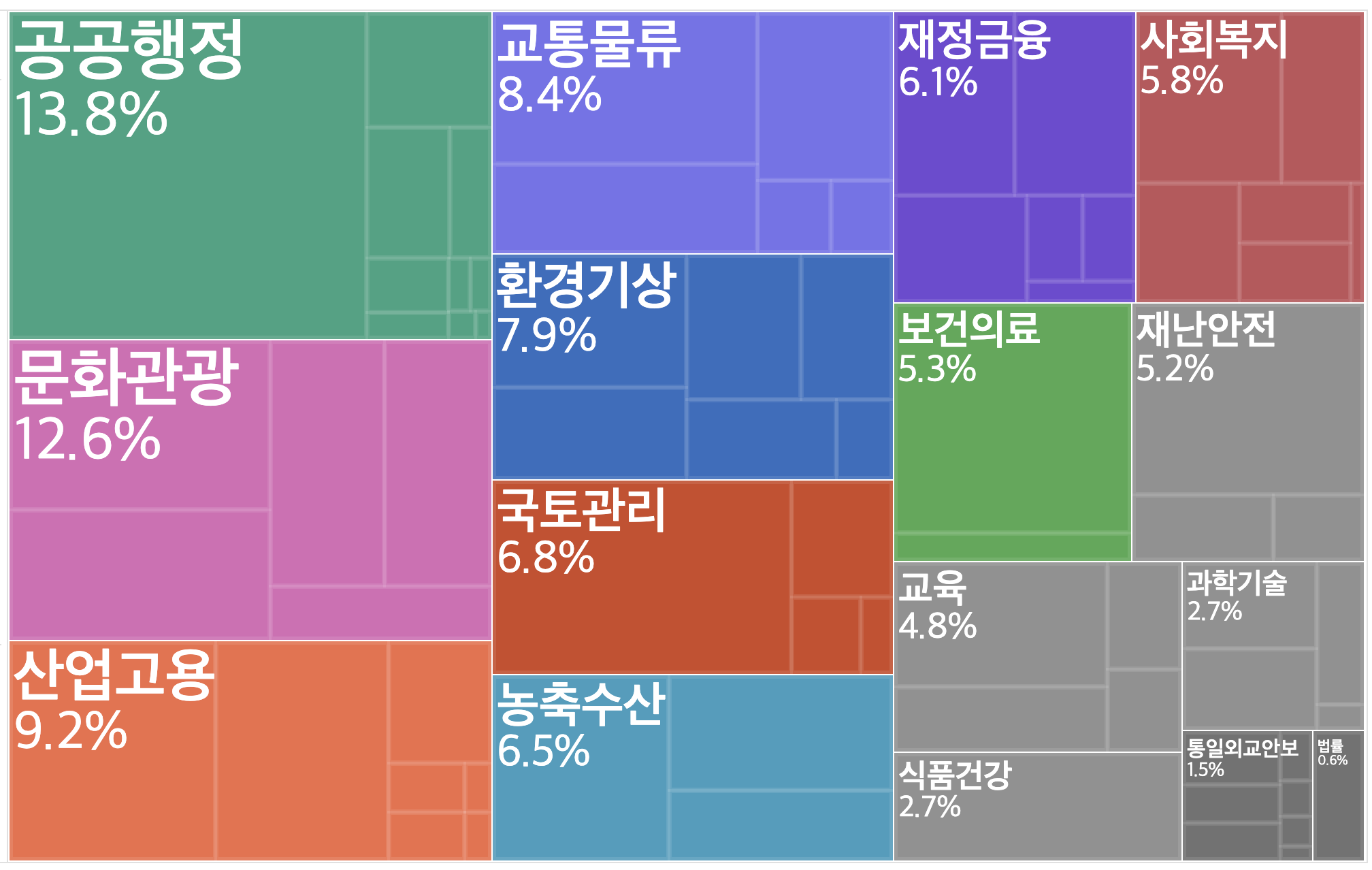

위와 같은 데이터들이 포함되어 있으며, 전체 약 9만건, API만해도 1.1만건 이상의 방대한 데이터를 제공한다.
이러한 거대한 데이터들을 계속 확인하고 어떻게 쓸지 고민하다보니 시간이 훌쩍 지나가버렸다...
마치 코딩을 처음 배울때 정보의 바다에 빠진거같은 느낌을 받게 되었다.
이전 글에서도 봤다시피, 대략적인 데이터 분야는 정해졌기 때문에 이를 바탕으로 최대한 엄선해서 분류했다.
그리고 공공 데이터 포털은 사용하기 위해 활용신청을 해 개인 Key를 받아야 한다.
방법은 간단하다. 특정 API 제공 글에 들어가면 활용신청 버튼이 떡하니 보인다.
저걸 누르고 절차대로 하면 Key가 발급될 것이다.
그리 어렵지는 않으니 따로 서술하진 않겠다.
데이터 정리
지금 내가 받아올 수 있는 데이터를 정리해 볼 것이다.
다음 글에 스키마로 정리해볼 것이다.
한전) 가구평균 전력사용량
요청
- 조회년도
- 조회월
- 시도코드
응답
- 가구평균 전력사용량 내역(List, 아래의 내용을 저장)
- 조회년도
- 조회월
- 시도명(광역자치단체 명 ex: 서울특별시, 경기도, 부산광역시)
- 시군구명(기초자치단체명, ex:청주시, 양평군, 강남구 등등)
- 가구수(호)
- 평균 전력사용량(kWh)
- 평균 전기요금(원)
한국소비자원) 생필품 정보 조회
요청
- 상품 아이디(전체 조회시 미사용)
응답
- 결과코드
- 결과 메시지
- 상품 아이디
- 상품명
- 상품 단위 구분 코드
- 상품 단위량
- 상품 소분류 코드
- 상품 설명 상세
- 상품 용량
- 상품 용량 구분 코드
한국소비자원) 판매 업체 정보 조회
요청
- 업체 아이디 (전체 조회시 미사용)
응답
- 결과코드
- 결과메시지
- 업체 아이디
- 업체명
- 업체 업태 코드
- 업체 지역 코드
- 업체 지역 코드
- 지역 상세 코드
- 전화번호
- 우편번호
- 지번 기본 주소명
- 지번 상세 주소
- 도로 기본 주소명
- 도로 상세 주소명
- x 좌표 (GCS / 그리니치 기준)
- y 좌표
한국 소비자원)생필품 가격정보 조회
요청
- 상품 조사일(매주 금요일 날짜)
- 업체 아이디(전체 조회시 미사용)
- 상품 아이디(전체 조회시 미사용)
응답
- 결과코드
- 결과 메시지
- 상품 조사일
- 업체 아이디
- 상품 아이디
- 상품 가격
- 원플러스원 여부
- 상품 할인 여부
- 상품 할인 시작일
- 상품 할인 종료일
- 입력 일시
한국 소비자원) 기준 데이터 조회
요청
- 코드(위의 상품 분류코드 기입)
응답
- 결과코드
- 결과 메시지
- 코드
- 코드 이름
건강보험심사평가원) 병원정보서비스
요청
- 페이지번호(페이징 가능)
- 한 페이지 결과수
- 시도 코드
- 시군구 코드
- 읍면동명
- 병원명
- 분류코드
- 종별코드
- 진료과목코드
- x좌표(소수점 15)
- y좌표(소수점 15)
응답
- 결과 메세지
- 결과코드
- 한방레지던트 인원수
- 한방전문의 인원수
- 조산사 인원수
- x좌표
- y좌표
- 거리
- 치과일반의 인원수
- 치과인턴 인원수
- 치과레지던트 인원수
- 치과전문의 인원수
- 한방일반의 인원수
- 한방인턴 인원수
- 의과레지던트 인원수
- 의사총수
- 의과일반의 인원수
- 의과인턴 인원수
- 전화번호
- 홈페이지
- 개설일자
- 시군구명
- 읍면동명
- 우편번호
- 주소
- 시도명
- 시군구코드
- 암호화된 요양기호
- 병원명
- 종별 코드(코드는 따로 기술)
- 종별 코드명
- 시도코드
- 의과전문의 인원수
- 한 페이지 결과 수
- 페이지 수
- 데이터 총 개수
특이사항 - header, body, footer로 나눠져 있음
HIRA 빅데이터 개방포털) 종별 코드 정보
상위 몇개만 기술
코드구분 코드 명칭
서식구분코드 $ 해당사항없음
서식구분코드 021 의과입원
서식구분코드 031 의과외래
서식구분코드 041 치과입원
서식구분코드 051 치과외래
서식구분코드 061 조산원입원
서식구분코드 071 보건기관입원의과
기상청) 일기예보
요청
- 서비스키
- 페이지 번호
- 한 페이지 결과 수
- 응답 자료 형식
- 발표 일자
- 발표 시각
- 예보지점 X 좌표
- 예보지점 Y 좌표
응답
- 결과코드
- 결과 메시지
- 한 페이지 결과 수
- 페이지 번호
- 전체 결과 수
- 데이터 타입
- 발표 일자
- 발표 시각
- 예보지점 X 좌표(요청 보냈던 값)
- 예보지점 Y 좌표(요청 보냈던 값)
- 자료 구분 코드
- 실황 값
여기서 예보지점 x,y좌표를 따로 입력해줘야 하는데...
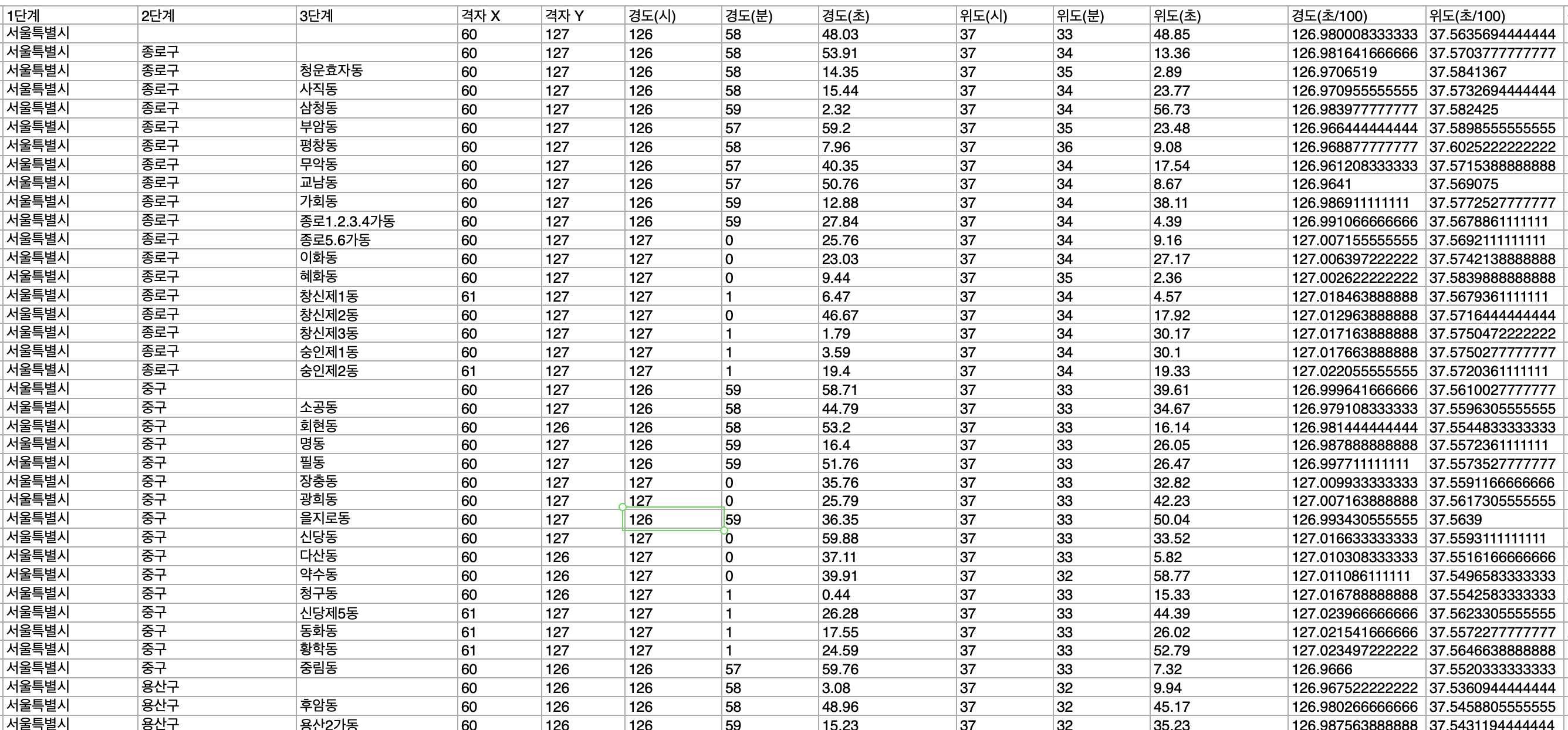
이렇게 따로 XML 파일로 제공이 된다.
따로따로 매핑을 해줘야 한다...
이 데이터를 가공하는데 큰 어려움이 있을것으로 보인다.
단순히 데이터를 받아서 보내는 것이 아니라, 일정 시간마다 데이터를 한번에 호출해 데이터베이스에 쌓아놓을 생각이기 때문이다.
정리
우리는 4가지 타입의 API를 요청/응답 받을 수 있다.
- 한전) 가구평균 전기 사용량
- 한국 소비자원) 생필품 가격 및 판매정보
- 건강보험 심사 평가원) 병원 세부정보
- 기상청) 단기 예보
이것을 바탕으로 스키마를 짜고, 프로젝트를 진행할 예정이다.
