
진행중인 프로젝트에서 중요하게 생각하는것은 대용량 처리를 어떻게 하는가? 이다.
그리고 관련 채용공고나 기업의 기술스택같은걸 찾아보면 많은 정보들이 나온다.
그중 내가 관심있게 봤던것은 Kafka, K8S였다.
K8S는 오케스트레이션이 가능하다는것과 Docker 진영이라서 사용하기 편할것이라 생각했고,
Kafka는 다른 블로그나 글을 읽어보아도 쉽게 찾아볼 수 있기 때문이다.
이전에 기술이 어렵게 느껴져서 간단하게 공부하고 넘어갔었는데, 다시 공부해 보도록 하겠다.
Kubernetes
K8S는 컨테이너 오케스트레이션 툴이다.
Docker 뿐만아니라 다른 Container 엔진도 호환이 가능하다.
K8S의 필요성은 다음과 같다.
- Docker 서버가 다운되었을때 후처리가 매우 번거롭다
- 서버 업데이트 진행시 Docker 이미지를 바꾼후 다시 올리는 과정이 필요하다
- 트래픽 처리가 힘들때 Scale-Out 작업을 해줘야 한다.
K8S는 이러한 작업을 자동화해주는 플랫폼이다.
즉, AWS의 Scale-Out을 사용하지 않아도
K8S는 Scale-Out을 자동으로 관리해준다.
MSA와 함께 설명이 되는 이유도 납득이 간다.
MSA의 특성상 많은 컨테이너를 필연적으로 열어야 하고,
그러한 서버들의 관리를 파이프라인을 통해 자동화를 한다 하더라도 한계가 있을 것이다.
즉, 컨테이너들을 효과적으로 관리하기 위한 툴이라고 생각하면 되겠다.
Kafka

카프카만 검색파면 프란츠 카프카가 나오기 때문에 아파치 카프카라고 검색해야 한다.
어렸을때 프란츠 카프카의 변신을 읽고 한동안 충격을 받았던 기억이 있다.

그리고 충격적이게도 Kafka의 이름이 프란츠 카프카에서 따왔다는 것이다....
레퍼런스1 : https://aws.amazon.com/ko/what-is/apache-kafka/
레퍼런스2 : https://techblog.woowahan.com/17386/
3가지 일을 한다고 한다.
- 레코드 스트림 게시 및 구독
- 레코드가 생성된 순서대로 레코드 스트림을 효과적으로 저장
- 레코드 스트림을 실시간 처리
레코드랑 스트림이 뭔 말인지 모르겠다.
블로그에서 이해를 위한 기본적인 용어와 개념을 알려주고 있다.
- 토픽(Topic): 데이터의 주제를 나타내며, 이름으로 분리된 로그입니다. 메시지를 보낼 때는 특정 토픽을 지정합니다.
- 파티션(Partition): 토픽은 하나 이상의 파티션으로 나누어질 수 있으며, 각 파티션은 순서가 있는 연속된 메시지의 로그입니다. 파티션은 병렬 처리를 지원하고, 데이터의 분산 및 복제를 관리합니다.
- 레코드(Record): 레코드는 데이터의 기본 단위로 키와 값(key-value pair) 구성입니다.
- 오프셋(Offset): 특정 파티션 내의 레코드 위치를 식별하는 값입니다.
- 프로듀서(Producer): 데이터를 토픽에 보내는 역할을 하며, 메시지를 생성하고 특정 토픽으로 보냅니다.
- 컨슈머(Consumer):토픽에서 데이터를 읽는 역할을 하며, 특정 토픽의 메시지를 가져와서(poll) 처리합니다. 컨슈머 그룹은 여러 개의 컨슈머 인스턴스를 그룹화하여 특정 토픽의 파티션을 공유하도록 구성합니다. 이를 통해 데이터를 병렬로 처리하고 처리량을 증가시킬 수 있습니다.
- 카프카 커넥터(Connector): 카프카와 외부 시스템을 연동 시 쉽게 연동 가능하도록 하는 프레임워크로 MySQL, S3 등 다양한 프로토콜과 연동을 지원합니다.
- 소스커넥터(source connector): 메시지 발행과 관련 있는 커넥터
- 싱크커넥터(sink connector): 메시지 소비와 관련 있는 커넥터
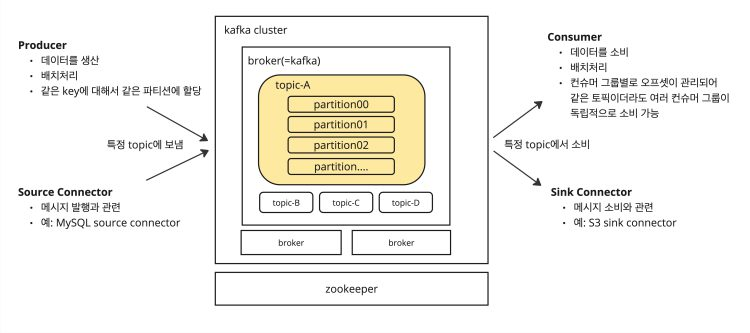
카프카의 흐름을 생각해 보면
1. Producer, Source Connector에서 Kafka의 토픽에 데이터를 보냄
2. Kafka는 여러개의 Topic으로 이루어져있고, 여러 Kafka가 클러스터를 이룸
3. Consumer, Sink Connector에서 데이터를 소비
위에서 스트림 얘기가 나왔는데, 역시나 구독에 관련된 언급이 나온다.
글을 읽어도 Kafka의 구조가 전혀 감이 오지 않아 Kafka를 공부해 보자.
레퍼런스 : https://aws.amazon.com/ko/compare/the-difference-between-kafka-and-redis/
Kafka, Redis 모두 게시/구독 메시징 시스템을 구축할때 사용할 수 있다.
Redis는 Key-Value , Kafka는 스트림 처리 엔진이다.
Kafka, Redis로 각각 메시징 시스템을 구축했다고 가정을 한 후,
각 스택의 차이점을 중심으로 스트림, 구독에 대해 알아보자.
작동방식
Kafka는 클러스터를 통해 생산자와 소비자를 연결함. 각 클러스터는 서로다른 Kafka 브로커로 구성되어 있음. 따라서 생산자가 브로커에게 메시지를 게시했을때, 브로커가 데이터를 분류해 적절한 파티션에 데이터를 저장함. 소비자는 원하는 파티션의 데이터를 추출함.
추가설명) Producer가 파티션 키를 지정하는 등 데이터가 어디로 들어갈지 정해져 있음. 브로커가 데이터를 알아서 넣는건 정확하게는 틀린말
Redis는 NoSQL 기반 Key-Value 방식이기 때문에 생산자와 소비자가 서로 알 필요가 없음(생산자와 소비자가 긴밀하게 연결됨). 생산자가 특정 노드에 메시지를 보냈을때, 연결된 소비자들 전체에게 전달됨.
차이점
- Kafka는 데이터를 분류해서 저장한 후 소비자가 알아서 찾아가는 방식
- Redis는 모든 소비자에게 데이터를 뿌리는 방식
구독이 어떤것인지 알려주는 부분이다.
Kafka에 데이터가 들어왔을때 분류해서 각 파티션에 데이터를 저장한다.
소비자는 자신이 원하는 파티션의 데이터만 들고오면 되기 때문에
데이터가 추가될때 자동으로 특정 파티션의 데이터만 가져온다.
-> 특정 파티션에 업데이트 되는 데이터를 가져오는걸 구독이라고 한다.
처음 봤을때 쓴 글인데 지금보니 완전하게 틀린 말이라는걸 알 수 있다.
Kafka는 메시지 전송의 주체가 아니다.
Kafka는 들어온 데이터를 클러스터링, 파티션 분할을 통해 데이터를 정리하는 저장소이며 소비자들이 저장소의 데이터를 읽어가는 구조를 가지고 있다.
따라서 구독이란 말 그대로 소비자가 원하는 데이터를 가져가는걸 의미한다.
메시지 처리
Kafka와 Redis는 작은 크기의 데이터 패킷을 전송할때 성능이 뛰어나다.
Kafka
- 상당히 큰 메시지도 처리 가능함.
- 파티션에서 어디까지 읽었다를 나타내는 OffSet을 업데이트하며 메시지를 검색함
- 소비자가 메시지를 읽은 후 메시지를 보관함. Client에게 메시지 재전송 가능
Redis
- 데이터가 많아지면 힘들어짐. in-memory의 한계(대신 빠름)
- 메시지가 전송된 후 저장하지 않음. Stream에 연결된 구독자가 없으면 메시지를 삭제함.
Stream에 대한 설명이 되는 부분이다. Stream이란 메시지가 들어오는 흐름이고, 그 데이터를 이용하는 소비자가 구독을 하는 방식으로 이루어진다. 막연하게 Stream이라고 하면 데이터가 막 쏟아져 나오는 것을 상상할 수 있는데, 그러한 데이터의 Stream도 결국 특정한 로직을 걸쳐 절차적으로 예상 가능한 데이터가 들어오는 것이라는걸 알 수 있는 부분이다. 따라서 데이터가 많든 적든 Stream의 소비자가 누구인지 예상할 수 있기 때문에 구독의 관리가 가능하다.
하지만 햇깔려서는 안되는 것이 Stream은 순차적으로 들어오는 데이터의 흐름이다. 메시징 시스템을 설계할때 보통 시스템 간의 결합도를 낮추기 위해 MSA를 활용한 아키텍처를 구성할것이라 예상되는데, 수많은 Source에서 부터 오는 데이터들은 난잡하게 혼합되어 있을 것이다. 다만 그러한 Stream에서도 같은 로직을 따르는 데이터들이 순서를 따라 들어온다는 말이다.
성능 차이
Redis가 In-Memory를 활용하기에 빅데이터 처리에서는 Kafka의 게시/구독 메시징 성능이 Redis보다 높다.
Kafka
- 병렬처리 지원
- 각 구독자가 다른 구독자로 이동하기 전에 기다릴 필요가 없음
- 소비자가 메시지를 늦게 읽는다면 캐시 데이터가 삭제되어 느려질 수 있음.(memory -> disk)
- 데이터 지속성을 위해 파티션 복제를 하는데, 이때 오버헤드가 발생함
Redis
- 병렬처리를 지원하지 않음
- 소비자의 승인을 기다려야 하기 때문에 노드가 많으면 처리량이 크게 감소함
- 데이터를 백업하지 않고 캐시 메모리 기반이라 전원이 꺼지면 모든 데이터 손실
성능에 관해 알아보는 것이지만 Kafka의 Scale-Out에 대해 알 수 있는 부분이다.
공부를 하면서 궁금했던점은 Kafka는 어떻게 스케일아웃 할 것인가? 였다.
그 이유는 다음과 같다.
- 브로커들 간의 데이터 격차는 어떻게 되는것인가?
- 소비자들은 자신이 구독한 데이터가 어떤 브로커의 어떤 파티션에 있는지 어덯게 아는가?
그런데 이 2가지의 질문은 같은 파티션은 같은 데이터를 갖는다 라는 해답이 나와버렸다.
그냥 생산자가 데이터를 집어넣을때 파티션별로 데이터를 뿌려버리면 되는 것이다.
즉, 브로커별로 가지고 있는 파티션이 다를지라도, 파티션이 동일하다면 같은 데이터를 가지는 것이다.
또한 브로커 간에 데이터 격차도 없기 때문에 배치작업으로 후처리를 할 것도 없다.
단순하지만 강력한 해결방법이고, 대용량 트래픽 처리도 가능한것으로 보인다.
정리
역시 AWS의 문서라고 해야할수 있을 정도로 많은것을 알 수 있는 글이었다.
- 브로커는 파티션을 가지고, 브로커가 모여 클러스터를 만든다.
- 생산자는 브로커의 파티션에 데이터를 넣고, 소비자는 파티션의 데이터를 사용한다.
- 소비자가 Kafka의 데이터를 구독해 가져가는 형식.
- 각 브로커는 개별 서버를 가지고 있으며, 따라서 Scale-Out도 자유롭다.
- 병렬처리, 대용량 메시지, 데이터 지속성이 뛰어나다.
RabbitMQ
레퍼런스 : https://www.cloudamqp.com/blog/part1-rabbitmq-for-beginners-what-is-rabbitmq.html

많이 사용하는 다른 MQ이다.
Kafka와 RabbitMQ 둘다 메시지 지향 미들웨어라는 공통점이 있다.
하지만 차이점은
- Kafka는 생산자 중심의 대용량 스트리밍 데이터 처리
- RabbitMQ는 브로커 중심의 신뢰성 있는 전달
에 중점을 맞췄다고 보면 되겠다.
작동방식
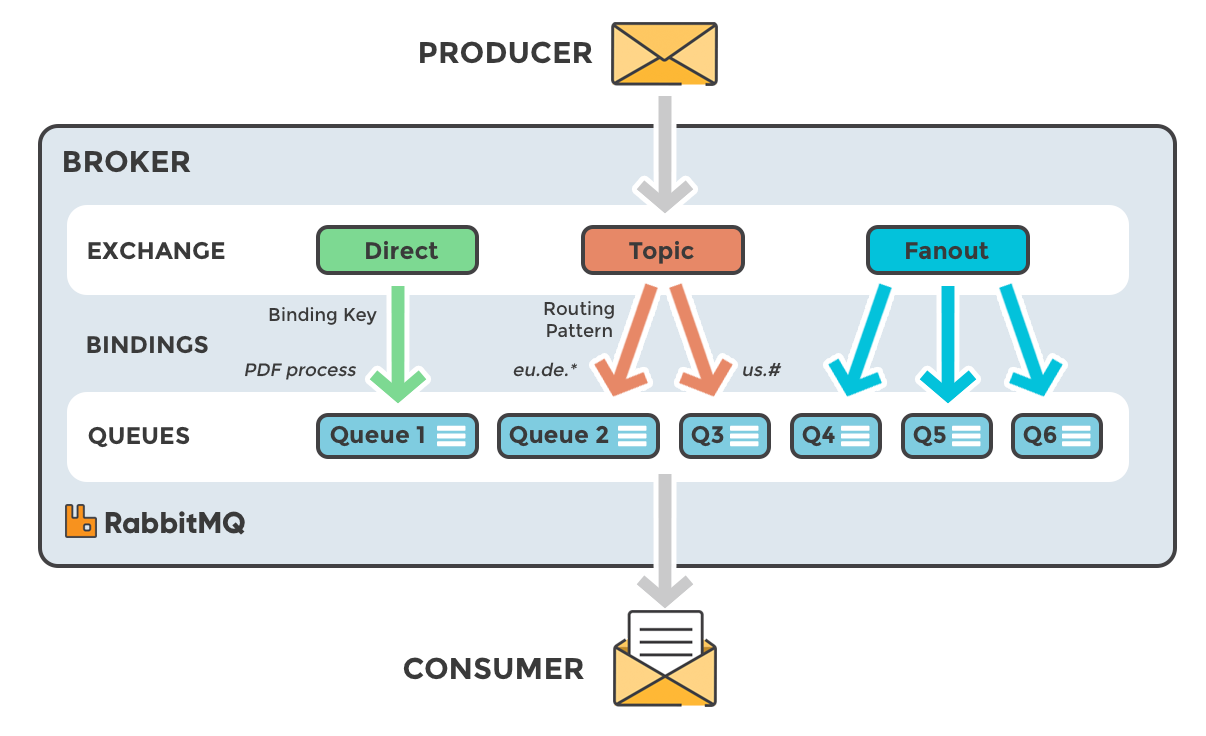
카프카와 마찬가지로 생산자 - 소비자의 흐름을 위해 브로커가 활동하는 방식이다.
하지만 Kafka와의 차이점이라고 한다면 Kafka에는 없는 Exchange 과정이 포함되어 있다.
Exchange는 생산자의 메시지를 Que에 담기 위해 분류하는 작업이다.
- Direct : 바인딩 키가 메시지의 라우팅 키와 정확히 일치하는 큐로 라우팅
- Topic : 바인딩에 지정된 라우팅 패턴과 라우팅 키 사이에서 와일드카드 매칭을 수행
- Fanout : 메시지를 해당 교환에 바인딩된 모든 큐로 라우팅
Direct는 특정한 큐에, Topic은 조건에 맞는 큐에, Fanout은 모든 큐에 메시지를 넣는다고 보면 되겠다.
RabbitMQ vs Kafka
레퍼런스 : https://www.rabbitmq.com/docs/consumers#message-properties
RabbitMQ와 Kafka의 결정적인 차이점은 무엇일까?
그것은 메시지를 움직이는 주체가 다르다.
다시 설명하자면
- Kafka는 소비자가 파티션에서 메시지를 가져가는 방식이고,
- RabbitMQ는 브로커가 소비자에게 메시지를 전송하는 방식이다.
따라서, Kafka는 데이터를 적절하게 분류하는 것을, RabbitMQ는 메시지를 정확하게 전달하고 모니터링하는것을 중요하게 여기고 있다.
오해의 소지가 하나 있는데, RabbitMQ 또한 소비자가 구독요청을 해야 한다.
- Kafka는 소비자가 토픽의 데이터를 Pull, RabbitMQ는 구독 요청이 된 소비자에게 Push 방식으로 작동한다.
라고 적는것이 정확한 표현이긴 하다.
그리고 Kafka와 RabbitMQ는 위에서 적었듯이
- Kafka는 생산자 중심의 대용량 스트리밍 데이터 처리
- RabbitMQ는 브로커 중심의 신뢰성 있는 전달
라고 보면 된다.
신뢰성 이라는 말은 여러가지를 채크하고, 확실한 전달을 보장하겠다는 뜻이기에 오버헤드가 필연적으로 발생할 수 밖에 없고, 대용량 데이터 처리에는 적절하지 못하다는것을 알 수 있다.
Hadoop
레퍼런스1 : https://en.wikipedia.org/wiki/Apache_Hadoop
레퍼런스2 : 네이버 클라우드 하둡 강의영상
레퍼런스3 : https://tech.kakao.com/posts/556
레퍼런스4 : https://www.youtube.com/watch?v=4-W-PSMshgA
레퍼런스5 : https://aws.amazon.com/ko/what-is/hadoop/
레퍼런스6 : https://www.upgrad.com/blog/hadoop-ecosystem-components/
위 레퍼런스들은 Hadoop을 이해하기 위해 참고했던 글/영상으로, 이번 글에는 위의 내용이 들어가지 않은 부분이 상당히 많음.
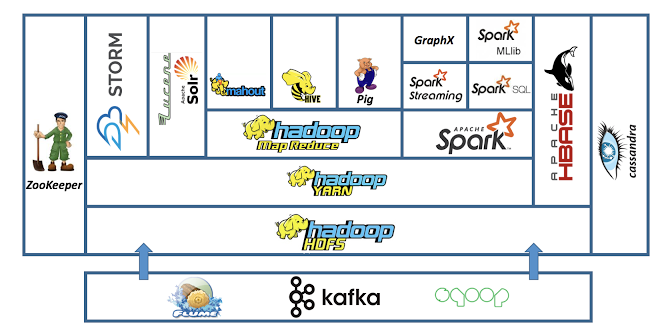
하둡은 빅데이터 처리를 위한 여러 프로젝트를 의미한다.

하둡은 위의 코어 프로젝트를 가지고 있는데, 하둡 에코시스템이라는 개념이 있다.
하둡 에코시스템은 Apache Hadoop을 기반으로 애플리케이션을 구축하는 데 도움이 되는 도구, 라이브러리, 프레임워크의 모음이다.

하둡 관련 글과 영상을 찾고 보는데 감당이 안된다.
어떤 기업이 쓰고있나 신입/경력 공채를 살펴봐도 네카라쿠베 뿐만 아니라 ML 관련 기업은 싹다 쓰고있는듯하고, 사용하는 기술 스택도 저마다 다르다.
특히나 Hadoop Ecosystem쪽은 프로젝트의 수가 장난아니라 이걸 어떤 순서로, 어떤 방법으로 공부해야 하는지도 잘 모르겠다.
일단 이번 글에서는 하둡 에코시스템의 프로젝트는 어떤것이 있고, 그 기능과 구조에 대해서 간략하게 내용을 정리해보려고 한다.
양이 너무나도 방대하고, 처음 접하는 내용들이긴 하지만, 하나씩 살펴보도록 하자.
하둡 에코시스템 개요
레퍼런스 : https://www.analyticsvidhya.com/blog/2020/10/introduction-hadoop-ecosystem/
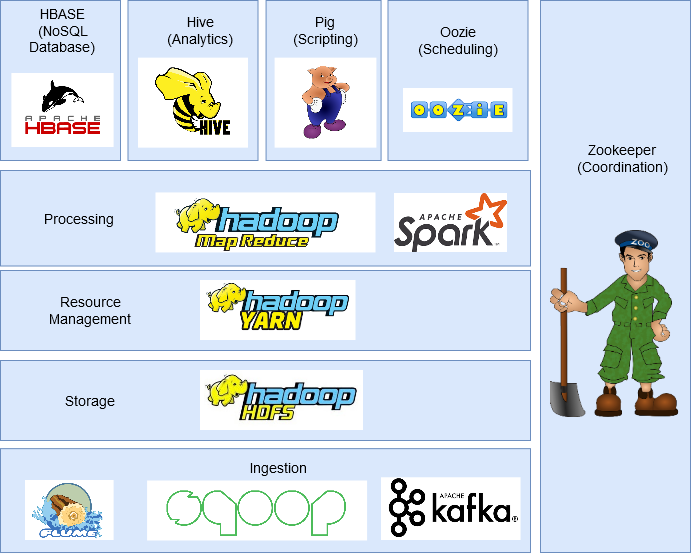
2024년 Hadoop 의 Top component를 정리해 놓은 자료이다.
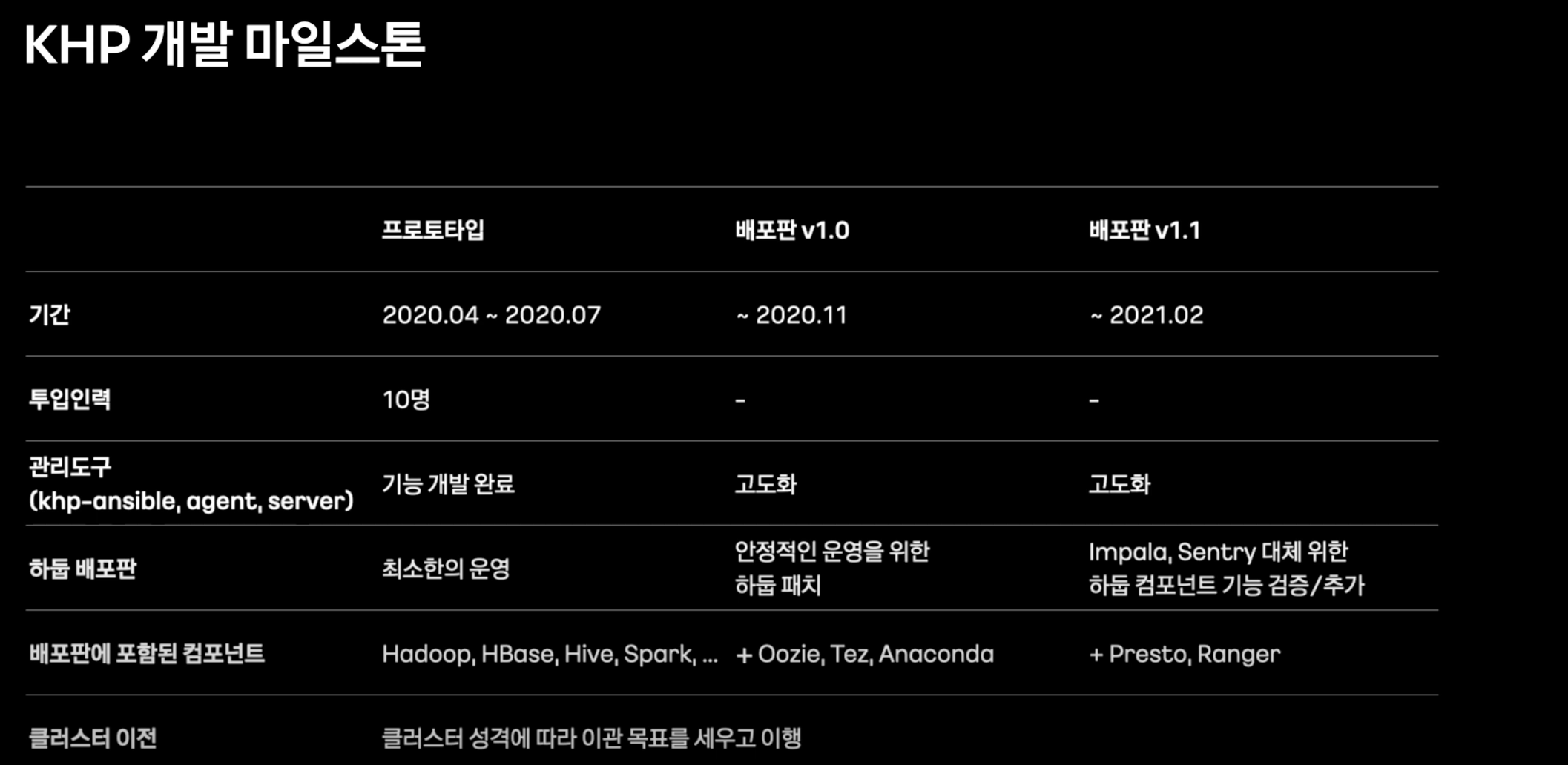
실제 사례 중 카카오 자체 개발 하둡 플랫폼을 활용하겠다.
카카오 자체 개발 Hadoop Platform의 마일스톤에서도 위의 스택이 잘 나타난다.
겹치는 프로젝트를 보면
- Hadoop, HBase, Hive, Spark, Oozie
을 TopCompoenets에서 볼 수 있다. Hadoop은 HDFS가 들어간것으로 보아 포함된다고 판단했다.
Tez 레퍼런스 : https://www.dremio.com/wiki/apache-tez/
이 외에도 아나콘다를 사용한것으로 보아 파이썬을 통한 ML을 활용할 것이라 예측하였으며, Tez를 사용하여 데이터 분석 성능을 향상시키려 했음을 알 수 있다.
이처럼 하둡 또한 Spring과 같은 프레임워크 처럼 주요한 코어기능을 바탕으로, 필요한 기능들을 붙여서 사용하는 자체 개발이 가능한 시스템이라는 것을 알 수 있다.
그러니 Hadoop을 Spring, Nest와 같은 하나의 단일 프레임워크로 생각한 것 때문에 Hadoop이 무엇인지 파악하는데 오래 걸렸던거 같다.
카카오 하둡 플랫폼 설명
설명 : https://tech.kakao.com/posts/541
KHP 아키텍처/개발/운영 : https://www.youtube.com/watch?v=4-W-PSMshgA
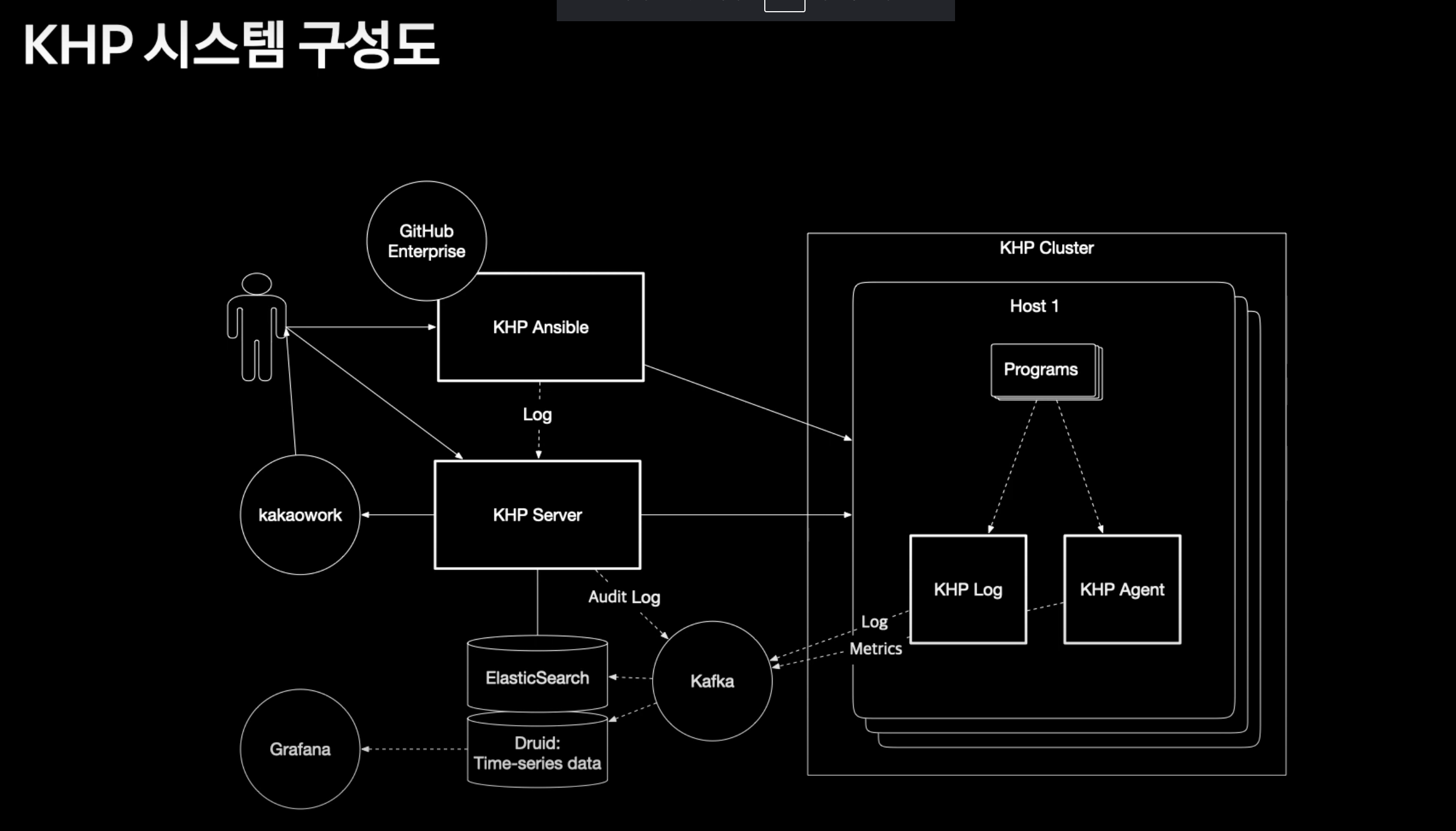
KHP의 구성도는 위와 같다.
크게 4가지로 구성이 된다.
- KHP Ansible
- KHP Server
- Agent
- Data
KHP Ansible
Hadoop 에코시스템에서 필요한 프로젝트들을 카카오에서 쓰기 위해 패키징한다.
Ansible은 Hadoop 배포판을 클러스터로 구축, 기능 업그레이드, 설정 변경, 컴포넌트 제어 등을 하는 부분을 담당한다.
영속성 유지하며 제어를 하는 기능을 한다.
KHP Server
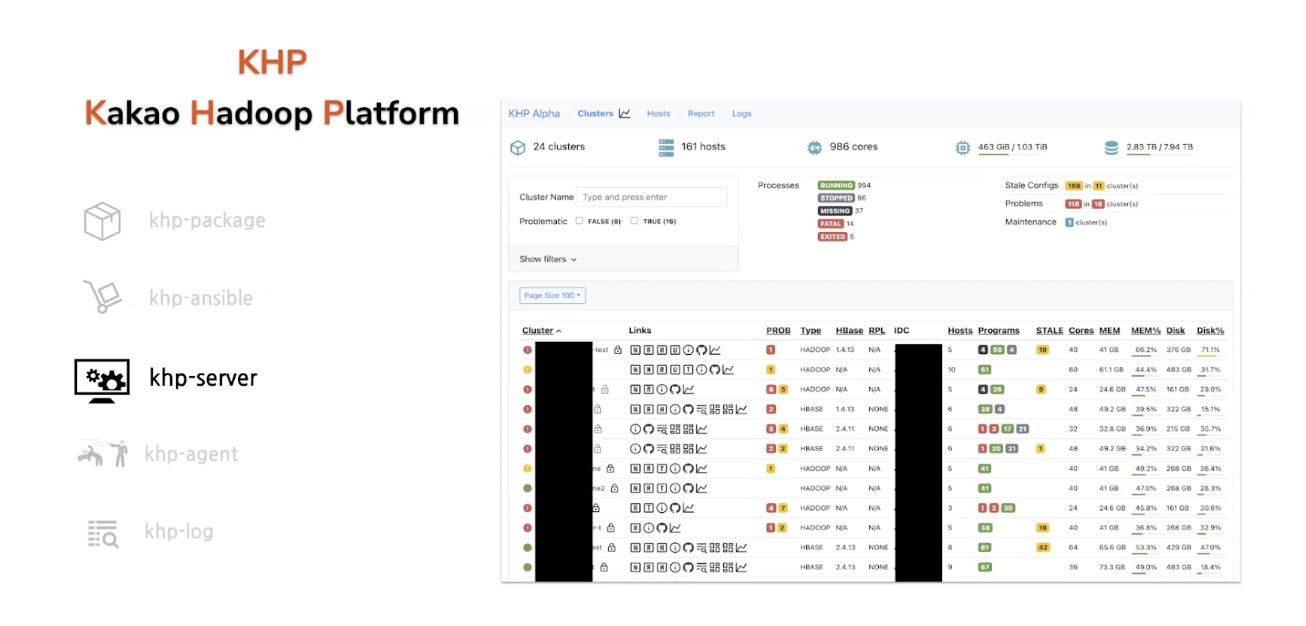
서버는 다음과 같은 일을 한다.
- GUI를 만들어 리소스를 관찰
- 매트릭 수집을 통한 클러스터 상태 확인
- 로그 검색
- 에러 발생 시 자동알림
KHP Agent

서버의 기능을 수행하기 위해 에이전트를 시스템에 침투시킨다.
카카오에서 하둡 관련 처리량이 엄청난데, 이러한 데이터를 견딜 수 있는 구조로 되어잇다.
Hadoop의 기능?
Hadoop 레퍼런스 : https://cloud.google.com/learn/what-is-hadoop?hl=ko
여기서 이해가 잘 안되는 부분이 있었다. 분명 Kakao에서 Hadoop을 이용한 플랫폼을 설명하는데 Hadoop에 관한 설명은 하나도 없다.
Spring으로 설명하면 Spring을 사용해서 서버를 구성했다는데 ~했다, ~했다 말만하지 Spring과 관련 프레임워크에 대해서 언급 자체를 안한다는 것이다.
그래서 곰곰히 생각을 해보았을때, 다음과 같은 결론을 낼 수 있었다.
- 쓸 이유가 없어서
- 각 프레임워크의 기능이 명확해서
아마 둘 다라고 생각이 드는데, Hadoop에 관해 깊게 설명하는 글/영상이 아니기도 하였고, 레퍼런스에서 나오는 설명 또한 각 프레임워크의 기능이 명확하게 설명되어 있다.
따라서 이번 글에서 내릴 수 있는 결론은
빅데이터 처리에 필요한 여러 프레임워크를 개발했고, 그중 코어를 Hadoop, 추가 프레임워크를 합쳐서 Hadoop Ecosystem이라고 한다.
즉, 빅데이터라고 해서 무언가 복잡한 기능을 쓰고 연산처리를 하는것이 아니다.
Hadoop의 분산처리, 분산저장을 바탕으로 Hadoop Ecosystem의 데이터 분석, 처리 등을 활용하는 빅데이터 처리 시스템이다.
나는 왜 하둡을 어려워했나?
Hadoop은 ML(Machine Learning)과 긴밀하게 연관되어있다. 왜냐하면 ML을 하기 위해서는 방대한 양의 데이터가 필요한데, 빅데이터를 처리하기 위해서는 Hadoop과 같은 빅데이터 처리 시스템이 필요하기 때문이다.
예전에 Tensorflow, Keras, 인공신경망 등을 찍먹해본적이 있었는데 그때는 CS, 컴퓨터 언어에 대해 하나도 모르던 시절이라 막연하게 너무 어려웠던 기억이 있다. 그래서 접근에 어려움을 느꼈고 ML과 연관지어 생각하다 보니 Hadoop이 어떤것인지 정확하게 파악하지 못했던거 같다.
이후
Hadoop이 어떤것인지 알게 되었으니 이제 세세한 부분을 파악해보려고 한다.
Hadoop Ecosystem의 프레임워크들이 어떠한 기능을하는지, 어떻게 작동하는지 대표적인 프레임워크부터 알아볼 예정이다.
