
이제 두려운 하둡에 대해 공부해볼 시간이다.
하둡이 어떤 시스템인지 대략적으로 이해했기에, Hadoop Ecosystem의 각 프레임워크들을 공부해 가며 Hadoop이 어떤 흐름을 가지고 있는지 알아보자.
Hadoop
레퍼런스 : https://www.youtube.com/watch?v=OPodJE1jYbg&list=PL9mhQYIlKEheGLT1V_PEby_I9pOXr1o3r
먼저 알아볼 것은 왜 하둡을 쓰게 되었나? 이다.
2003년에, 구글의 파일 시스템을 릴리즈 하였고(GFS), 이것을 기반으로 너치 파일 시스템을 만들었다.(NDFS) 그리고 GFS, NDFS의 논문을 기반으로 개발을 한 것이 Hadoop이다.
즉, 검색엔진을 만들다 보니 많은 데이터를 분산처리할 시스템이 필요했고, 그래서 Hadoop이 만들어졌다고 보면 되겠다.
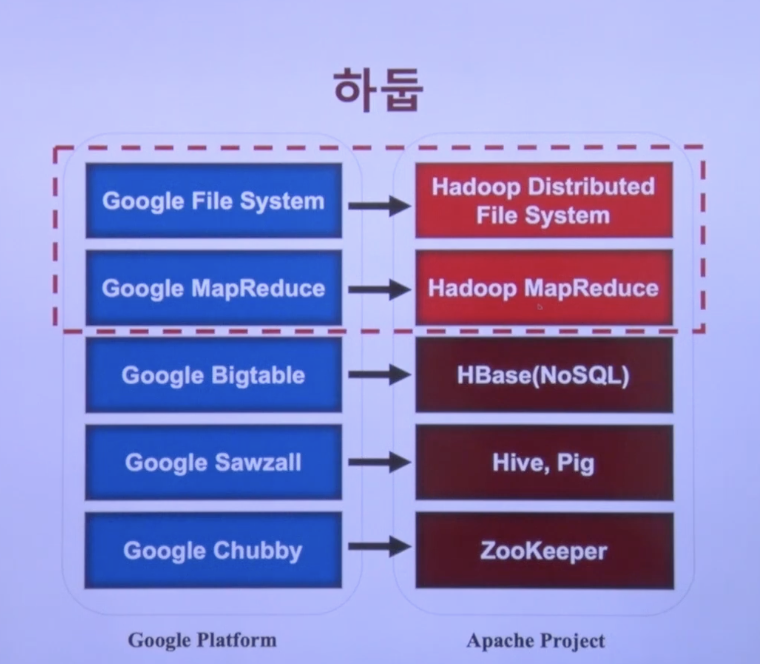
구글과 Hadoop의 상관관계를 보자면
- GFS -> HDFS
- Google MapReduce -> Hadoop MapReduce
- Google Bigtable -> HBase(NoSQL)
- Google Sawzall -> Hive, Pig
- Google Chubby -> ZooKeeper
가 되겠다.
추가 설명을 하자면
- 공유 스토리지에 데이터를 저장할때 일정수준을 넘어서면 병목지점이 발생한다. 따라서 분산데이터베이스를 사용하고 있으며, Hadoop에서 HBase가 담당한다.
- googled에서 시스템을 개발하기 위한 script 언어를 만들었는데, 이를 Sawzall라 하고, 이를 기반으로 만든게 Pig이다. 따라서 Pig를 사용하여 분산시스템의 데이터를 처리할 수 있다.
- Hadoop의 데이터를 SQL로 다루기 위해서 만들어진것이 Hive이다.(SQL과 유사함)
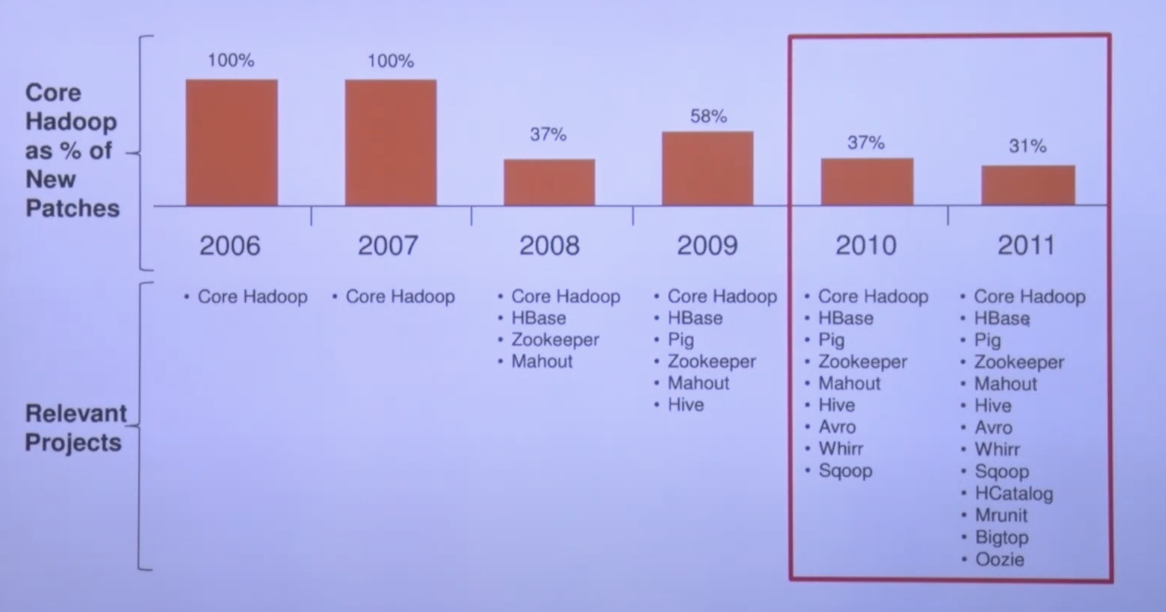
2011년까지의 Hadoop 생태계이다.
이후 많은 프로젝트가 나왔지만, 위의 프로젝트들은 지금도 많이 쓰이고 있다.
- HBase : Hadoop 분산 데이터베이스
- Pig : 스크립트 언어
- Zookeeper : 여러 플랫폼의 분산데이터를 다루기 위한 코디네이터
- Mahout : 머신러닝 알고리즘을 Hadoop 분산 플렛폼의 데이터에서 처리
- Hive : SQL로 Hadoop 데이터를 다룸.
- Scoop : Hadoop - Database 연결을 편하게 만들어줌
- HCatalog : 하나의 카탈로그에서 Hadoop 메타데이터 관리
- Mrunit : Testing 프레임워크
- Oozie : 데이터 처리 Flow를 스케줄링함. 요즘 airflow를 많이 사용함.
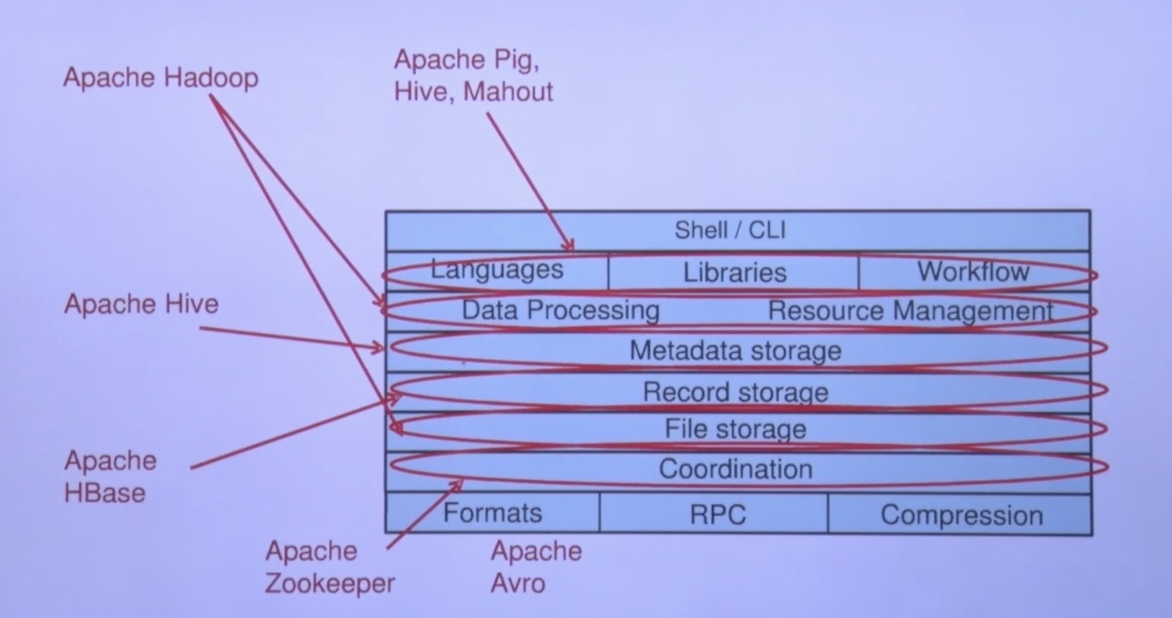
그리고 위의 정보를 정리하게 된다면 이런 모양이 될 것이다.
Hadoop의 영향
- 빅데이터의 저장비용이 줄어듬.
- 빅데이터를 가공하여 insight를 얻으려 시도할수 있게됨.
- 하지만 기존에는 버렸던 데이터를 계속 쌓으려고 하면서 분석할 데이터가 늘어남.
- 데이터가 넘치기 때문에 기계를 활용한 데이터 분석툴이 필요함. 따라서 ML의 중요성 증가
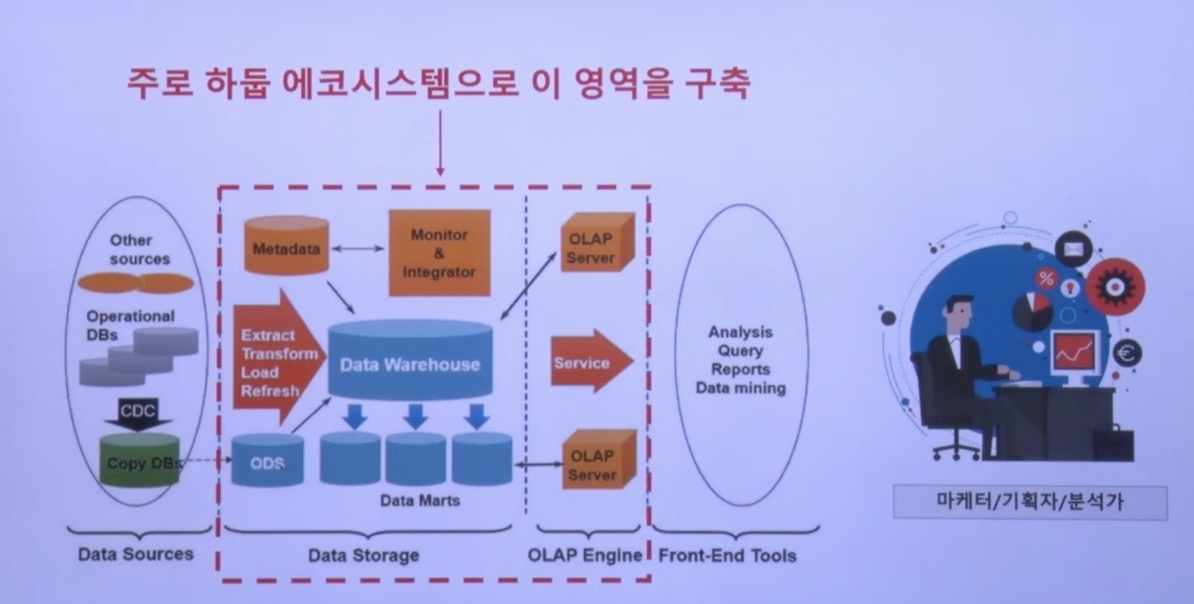
Hadoop은 데이터 처리 시스템을 구축함.
Hadoop 구성요소
레퍼런스 : https://cloud.google.com/learn/what-is-hadoop?hl=ko
크게 4가지로 나뉜다.
- HDFS : 분산 파일 시스템
- YARN : 리소스 관리 플랫폼
- MapReduce : 대규모 데이터 처리를 위한 프로그래밍 모델
- Hadoop Common : 다른 Hadoop 모듈이 사용 및 공유하는 라이브러리와 유틸리티
각각이 무엇을 의미하는지 알아보도록 하자.
HDFS
레퍼런스 : https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html

HDFS는 범용 하드웨어에서 실행되도록 설계된 분산 파일시스템이다.
Assumptions and Goals
1. 하드웨어의 고장 : 분산시스템이기 때문에 수백~수천대의 서버 머신으로 구성됨. 따라서 고장을 감지하고 빠르게 자동 복구하는것에 목표를 둠.
2. 스트리밍 데이터 접근 : HDFS는 접근의 지연성 보다는 높은 데이터 처리량에 중심을 둠. 따라서 POSIX 표준 요구사항 중 몇가지는 HDFS에서 생략되었다.
3. 대규모 데이터 set : 테라바이트 급의 대형 파일 처리를 위해 설계됨
4. 간단한 일관성 모델 : HDFS는 파일을 한번 작성하고 여러번 읽는 방식을 사용함. 파일이 생성/작성된 후 닫히면 변경할 필요가 없음.
5. 데이터보다 연산을 옮기는게 더 싸다 : 연산이 데이터 운영 위치에서 실행되면 효율이 높아진다. 데이터 전송 오버헤드가 크기 때문에 네트워크 자원을 많이 잡아먹음.
6. HD/SW 범용성 : GNU/Linux(OS), JAVA 기반 프로그램이다. 다양한 플랫폼에 쉽게 이식할수 있도록 설계됨.
NameNode, DataNode
HDFS는 마스터/슬레이브 구조이다.
NameNode
- 마스터 서버에는 하나의 NameNode가 있음.
- 파일 시스템 네임스페이스 관리, Client가 파일에 접근할수 있도록 관리함.
DataNode
- 클러스터의 각 노드는 하나의 DataNode가 존재함.
- 클러스터 내 각 노드에 연결된 스토리지를 관리함.
- 파일시스템 클라이언트로부터의 읽기 및 쓰기 요청을 처리함.
- NameNode의 지시에 따라 블록생성, 삭제, 복제를 수행함
추가설명) 매우 큰 파일을 저장해야 하기에 DataNode는 파일을 파일을 블록으로 저장한다. 그리고 내결함성을 위해 여러개로 복제한다.(개수는 조절가능) 데이터는 한번만 쓰기가 가능하다.
아키텍처
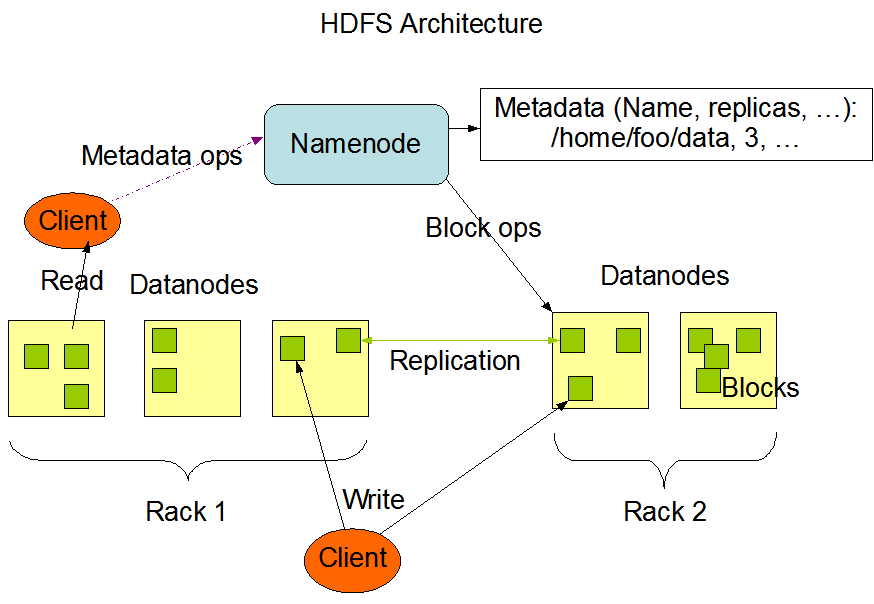
NameNode, DataNode 소프트웨어는 일반 하드웨어에서 실행됨.
GNU/Linux OS를 사용하며, Java로 작성되었기 때문에 java를 지원하는 모든 머신에서 NameNode, DataNode가 실행 가능함(높은 이식성).
클러스터에는 단일 NameNode가 있기 때문에 아키텍처를 크게 단순화한다.
마스터 노드의 부하를 줄여야 하기 때문에, NameNode에는 데이터가 들어가지 않고,
클라이언트와 DataNode가 직접 전송하도록 설계되어 있음.
위의 아키텍처는 이해하기 난해하다.
그래서 읽기/쓰기를 나눠서 설명해보면 다음과 같다.
레퍼런스 : https://wikidocs.net/23582
읽기
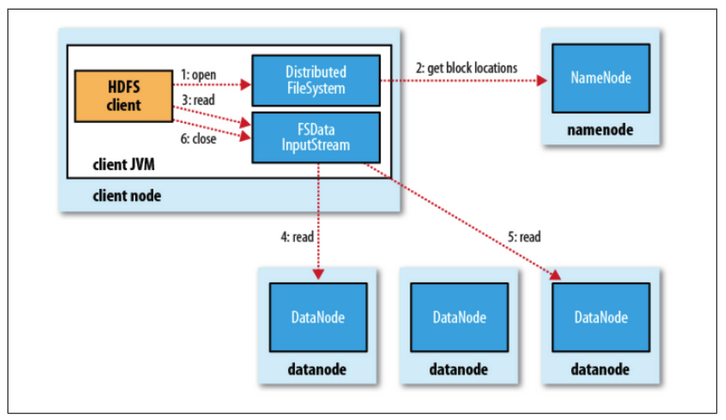
- NameNode에 파일 블록 위치 요청
- 네임노드가 위치 반환
- 각 데이터 노드에 파일 블록 요청
쓰기
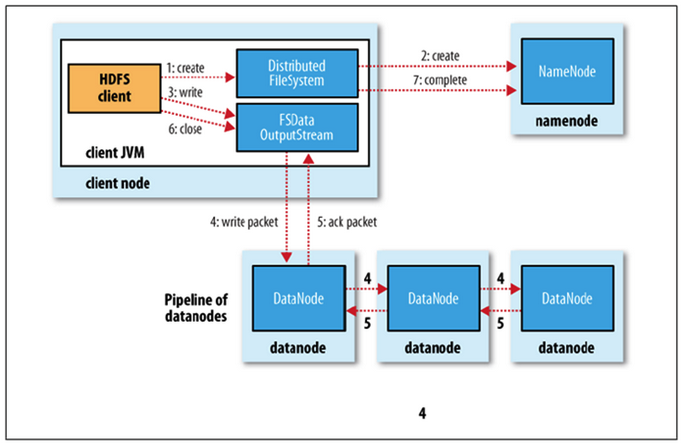
- 네임노드에 파일 정보를 전송하고, 파일의 블록을 써야할 노드 목록 요청
- 네임노드가 파일을 저장할 목록 반환
- 데이터 노드에 파일 쓰기 요청(데이터 노드간 복제 진행)
그러니 NameNode에는 DataNode에서 데이터를 전혀 반환하지 않고,
그저 데이터 위치를 요청하는 작업만 할 뿐이다.
- 그래서 Client가 DataNode에 Write, Read 작업을 하고,
- NameNode는 단순히 MetadataOps를 받아 위치반환/메타데이터 업데이트를 할 뿐이다.
데이터 복제
Data Replication이라고 한다.
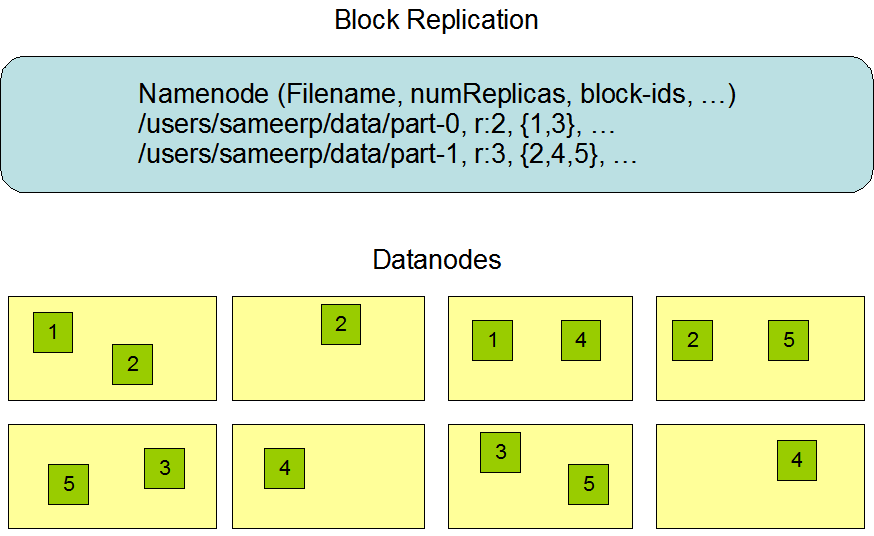
Hadoop은 안정성에도 정말 많은 관심을 보이는데, 그중 하나가 이 데이터 복제이다.
간단하게 말하면, 클러스터중 일부분이 고장나도 데이터를 쓸수는 없을까? 이다.
Hadoop은 여러 컴퓨터가 각각 하나의 기능을 맡고 있다.
어떤 컴퓨터는 NameNode, 다른 컴퓨터는 DataNode 등등..
그래서 특정 컴퓨터 하나가 고장이 나도 다른 컴퓨터는 살아있기 때문에 Hadoop 자체는 굴러간다.
하지만, 특정 DataNode가 고장이 나버리면 그 안에 들어있는 데이터는 사용이 불가능하다.
그래서 DataNode를 특정한 racks라는 그룹으로 묶고, 데이터가 rack 그룹마다 하나씩은 들어가야 한다.
예를 들어서 A라는 데이터는 rack1, rack2, rack3... 각각 한번씩 들어가야 한다.
그래서 Hadoop은 하나의 데이터가 전체 Hadoop 시스템 속에 여러개 들어가있는 구조를 가진다.
이를 다시 적으면
- Data Replication은 Hadoop의 내결함성(Fault Tolerance)을 보장하기 위한 설계다.
- Hadoop은 rack-awareness 정책을 따르며, 데이터 복제본은 서로 다른 랙(rack)에 분산 저장된다.
- 기본 복제 계수는 3이며, 이를 통해 특정 노드나 랙의 장애가 발생해도 데이터를 안정적으로 사용할 수 있습니다.
Hadoop 버전별 차이
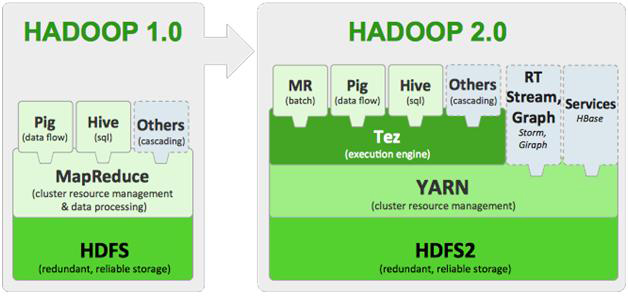
Hadoop은 v1->v2 에서 큰 변화를 가졌다.
우선 YARN이라는 것이 생겼다. 그리고 MapReduce 또한 HDFS에서 자원을 바로 할당받는 것이 아니라 YARN을 통해 배정받는 구조로 바뀌었고, HBase, Tez 등의 프로젝트도 추가되었다.
v2 -> v3는 최적화와 기능개선에 초점을 맞췄다.
그래서 아키텍처 적으로 큰 변화가 없기에, 이 글은 V1, V2를 중심으로 작성된다.
자세한 사항은 다음 링크를 통해 확인 가능하다.
Hadoop 2.x to 3.x Upgrade Efforts : https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+2.x+to+3.x+Upgrade+Efforts
따라서 MapReduce V1, Yarn-MapReduce를 각각 알아보겠다.
이 외의 프로젝트들 또한 다룰 예정이다.
MapReduce
SKplanet Tacademy : https://www.youtube.com/watch?v=Jx9rjPTWYPQ&list=PL9mhQYIlKEheGLT1V_PEby_I9pOXr1o3r&index=5
참 아쉽게도 공식 문서에 Hadoop v1의 문서를 찾을 수가 없다.
따라서 이 글은 SKplanet Tacademy의 Hadoop 맵리듀스 강의를 참고한다.
MapReduce의 기능
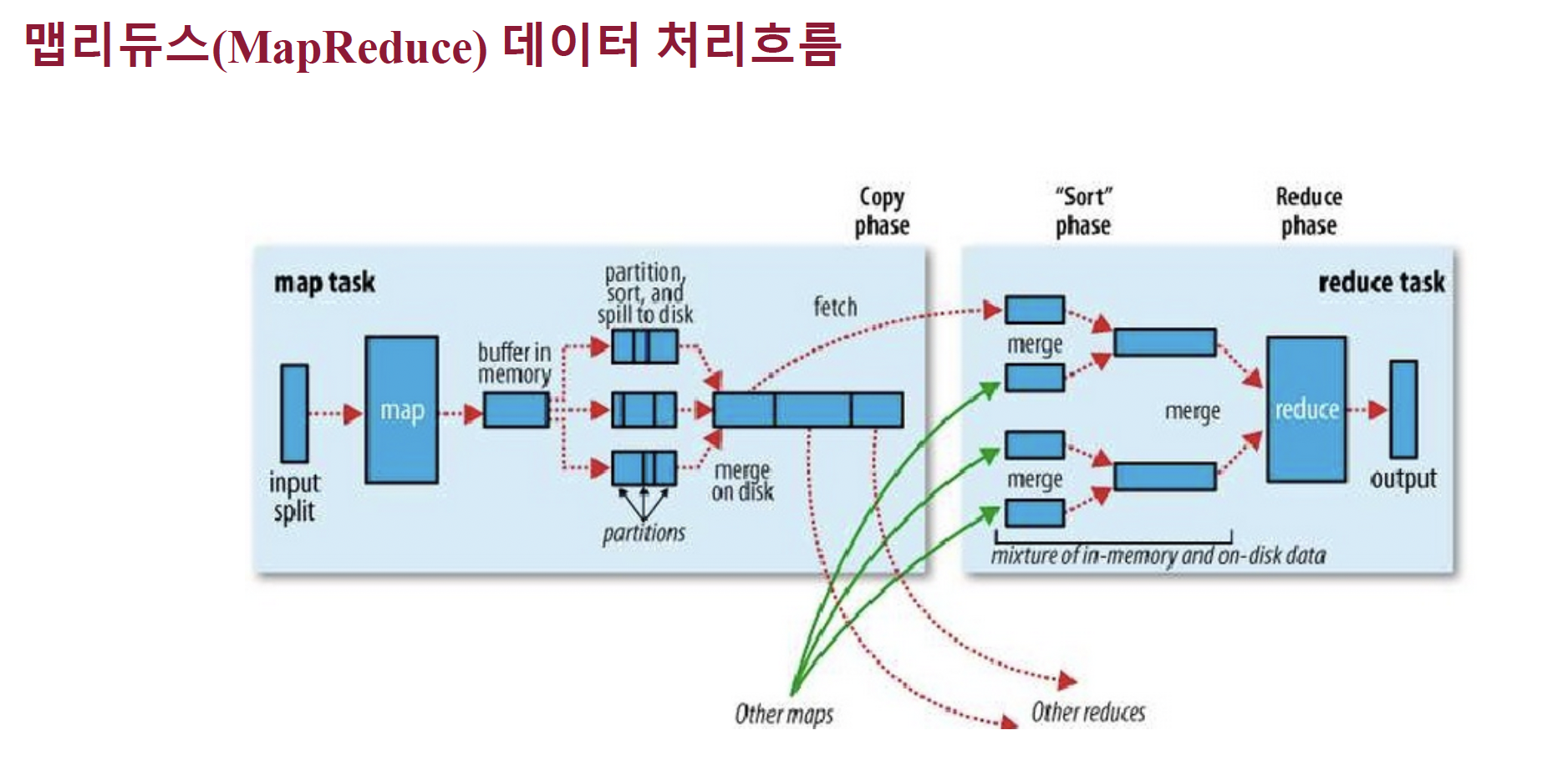
MapReduce의 기능은 한줄로 설명 가능하다.
- 데이터를 사용하고 싶은데 너무 크니까 최대한 작게 만들어 병렬처리후 결과를 모아보자.
(위 사진은 기상청 데이터 이다.)
예를들어서, 위와 같은 128KB짜리 Text 파일이 있다고 가정해 보자.
이 Text는 날씨 데이터인데, 128KB를 사람이 일일이 다 counting하는건 사실상 미련한 짓에 가깝다.
그런데 당신은 이 기상 데이터를 가지고, 날씨가 흐린 지역이 몇개 있을까? 를 알고싶다.
하지만 Text의 데이터가 너무 커서 서칭을 하면 시행마다 O(N)의 시간이 들 것이고, 따라서 효율적인 데이터 저장을 위한 방법이 필요할 것이다.
이럴때 사용하는게 MapReduce이다.
데이터를 최소한의 크기로 자른 후, 특정 작업을 시키는 것이다.
- 데이터의 최대/최소값을 계산하거나
- 특정 데이터가 몇번나왔는지 구하거나
- ML을 위한 전처리 작업을 하거나
원하는 작업은 개발자가 지정할 수 있지만, 핵심은 '데이터를 분할정복한다'라고 생각하면 편하다.
위의 데이터에서 날씨가 흐린 지역의 수를 알아내려면,
지역의 상태칸에 흐림 표시가 된 부분을 counting 하면 됨으로,
흐림 기호의 수가 몇개 있는지 확인하면 구할 수 있다.
MapReduce v1
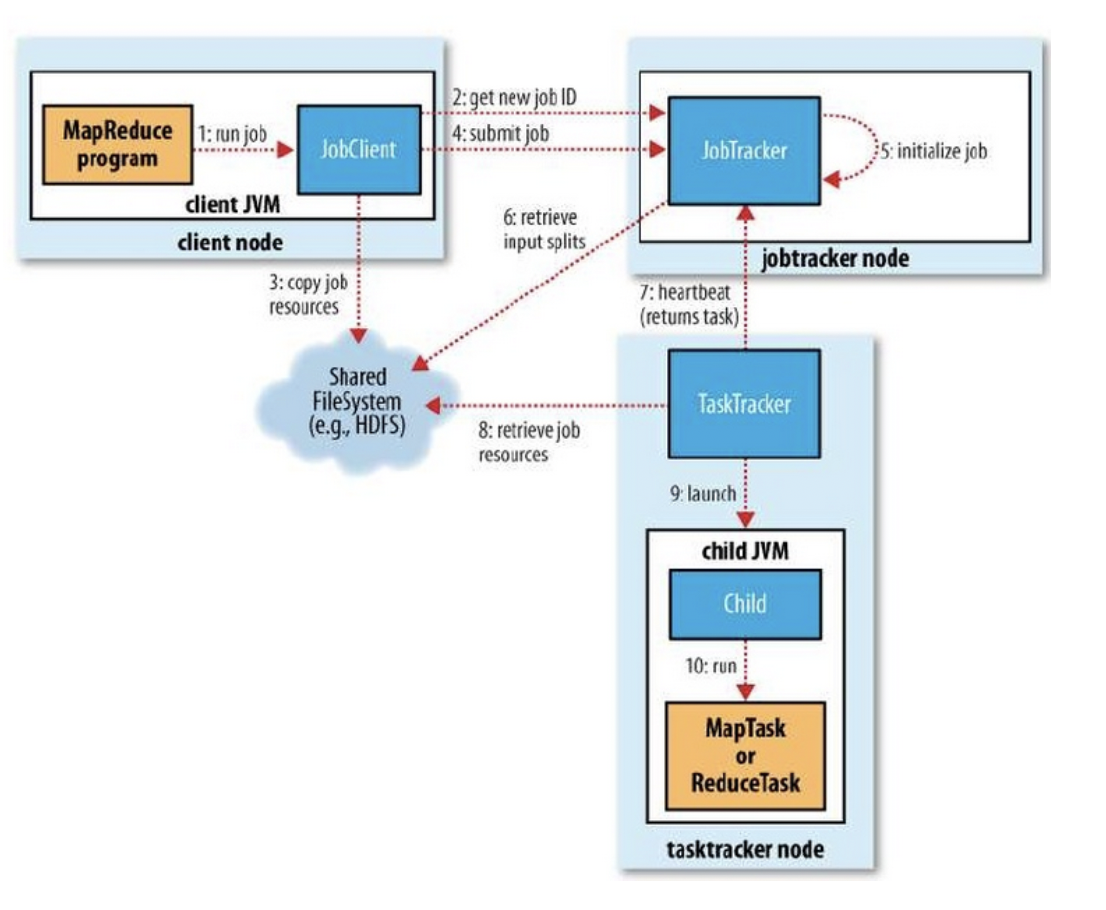
Job Tracker : Job을 조정하는 마스터 역할
Task Tracker : 작업(Task)을 실행할 환경을 제공하고, MapReduce 작업의 실질적 데이터 처리를 담당하는 태스크(Task)를 관리
Client : Job을 제출하는 실행 주체
즉, HDFS와 마찬가지로 Master가 있고, Master가 Task Tracker를 관리하는 형식으로 이루어 진다.
위 그림 또한 Client가 Job Tracker(Master)에게 Job 실행을 제출하고, Job Tracker가 Task Tracker를 관리하며 Job을 처리하는 모습이다.
Yarn-MapReduce
레퍼런스 : https://hadoop.apache.org/docs/r3.4.1/hadoop-yarn/hadoop-yarn-site/YARN.html
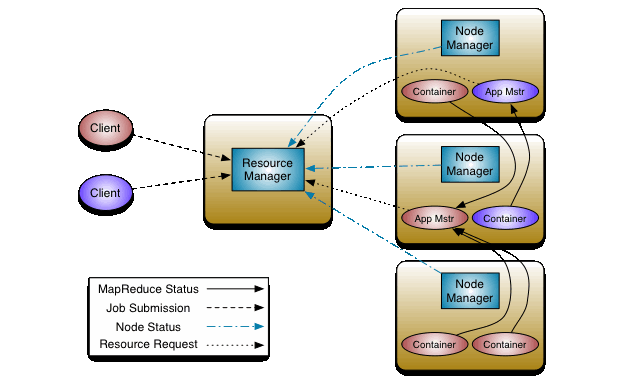
아파치에서 제공하는 Yarn 아키텍처이다.
Resource Manager : 시스템 내 모든 애플리케이션 간 자원을 중재하는 궁극적인 권한을 가진 관리자
2가지 주요 구성요소를 가짐.
-
Scheduler : 용량, 큐 등의 제약 조건에 따라 실행 중인 다양한 애플리케이션에 자원을 할당하는 역할
-
ApplicationsManager : 작업 제출을 수락하고, 애플리케이션별 ApplicationMaster를 실행할 첫 번째 컨테이너를 협상하며, ApplicationMaster 컨테이너가 실패 시 이를 다시 시작하는 서비스를 제공
NodeManager : 각 노드에서 실행되는 프레임워크 에이전트
CPU, 메모리, 디스크, 네트워크 등의 자원 사용량을 모니터링
ResourceManager와 협력해 작업을 수행
-> Slave 서버이지만 YARN에서는 RM/NM으로 부름.
MapReduce V1, V2 참고사항
Hadoop의 특징은 분산 시스템을 활용한 병렬처리가 목적이다.
스케일 업의 한계를 느끼고 스케일 아웃을 중심으로 만든것이 Hadoop이며,
각각의 Node들은 전부 개별 컴퓨터 이다.
즉, TaskTracker, JobTracker, RM, NM 전부 독립된 시스템이다.
하지만 YARN에서는 각 작업이 독립된 컨테이너(Container) 에서 실행되며, 이는 ResourceManager가 스케줄링하고 NodeManager가 관리한다.
컨테이너는 각 노드(개별 컴퓨터)의 자원을 효율적으로 활용하도록 돕는다.
V1 -> V2 개선사항으로는 병목현상에 있다.
Job Tracker에게 일이 몰려있다는 것이 그 이유인데,
RM/AM으로 일이 분산되어서 이러한 병목현상을 줄였다.
Hadoop Ecosystem
레퍼런스 : https://www.analyticsvidhya.com/blog/2020/10/introduction-hadoop-ecosystem/
Core Hadoop을 알아봤으니 주변 프레임워크를 공부할 시간이다.
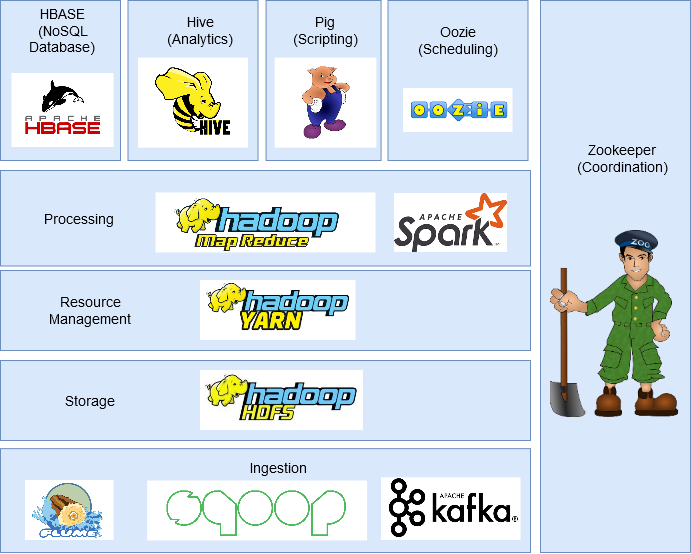
이전글에도 나왔다시피, 많이 쓰이는 프레임워크는 위와 같다.
내가 알아본 프로젝트는
- Kafka
- HDFS
- MapReduce
- YARN
이 되겠다.
그럼 남은 프로젝트는
- HBase
- Hive
- Pig
- Oozie
- Zookeeper
- Spark
- Flume
이 되겠다.
공부할 순서는 주관적인 기준을 가지는데,
우선은 많이 들어본 ZooKeeper, Spark를 먼저 공부하겠다.
진짜 이유는 별거없고 많이 보였는데 궁금해서 그렇다.
ZooKeeper
레퍼런스 : https://zookeeper.apache.org/doc/r3.5.0-alpha/zookeeperOver.html
주키퍼 교수님 강의 : https://www.youtube.com/watch?v=Avh6AhX_inM&list=PLCsebpDZm0n6HYSDaNxKQYrNrD4Xk9meX&index=32
Zookeeper 부터는 교수님의 강의를 참고한다.
Apache 공식문서만 읽다가 도저히 이해가 안되서 포기했다.
물론 각각의 부분은 무슨 말을 하는지 이해가 갔지만, 전체적인 아키텍처나 실행 흐름 등을 알 수가 없으니 맹인이 코끼리 다리를 만지듯 전체적인 흐름을 이해할 수 없었기 때문이다.
뒤에 나올 프로젝트도 참고한다.
분산시스템에서는 고민거리가 있다.
- 분산 시스템 간의 정보 공유
- 클러스터 서버 상태 채크
- 분산 서버들 간의 동기화를 위한 Lock 처리
그리고 다음은 Apache 공식문서에 나온 내용이다.
It exposes a simple set of primitives
that distributed applications
can build upon to implement higher level services
for synchronization, configuration maintenance, and groups and naming.
Zookeeper는 분산 앱의 다양한 기능을 구현하기 위한 원시적인 simple set을 제공한다는 뜻이다.
따라서, 분산 시스템에는 추가적으로 필요한 여러 요구사항들이 있는데, 그러한 기능들을 Zookeeper가 제공한다는 뜻이다.
Zookeeper의 역할은 다음과 같다.
- 분산 환경에서 노드 간에 조정자 역할을 수행
- 노드간 정보 공유, 잠금, 이벤트 등의 기능
- 여러개의 노드에 작업을 분산시켜주는 부하 분산 기능 제공
- 서버에서 처리된 결과를 다른 서버에 동기화 할때 Lock 처리
- 서버 장애 시 대기 서버가 기존 서버를 대신 처리할 수 있도록 장애상황판단 및 복구
즉, 분산 시스템의 불안정한 부분을 Zookeeper가 보완함으로써 안정적인 시스템 동작을 보장하는 기능을 가졌다고 보면 되겠다.
추가) 부하 분산 기능은 로드밸런싱 기능을 직접 제공한다는 것이 아니다.
Coordination Service의 조건
-
데이터 엑세스가 빨라야 한다 : 관리 데이터를 메모리상에 유지한다. 하지만 이건 캐싱한다는 것이지 in-memory만으로 동작하는것이 아니다.
-
자체적으로 장애에 대한 대응성을 가져야 함. : Zookeeper는 자체적으로 클러스터링을 제공하고, 장애가 발생했을때 데이터 유실 없이 FailOver/FailBack이 가능하다.
Zookeeper 아키텍처
3가지 주요 사항이 있다.
- 디렉토리 구조 기반의 데이터 저장소
- znode라는 데이터 저장 객체 제공(key-value)
- 데이터를 계층화된 구조로 저장하기 용이함.
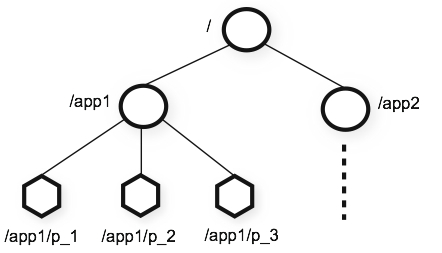
Zookeeper 계층화 구조
루트노드에서 하위 노드로 계층화되어 있는 구조를 가진다.
노드는 3가지 종류가 있다.
- Persistent Node
- 노드에 데이터를 저장하면 삭제하지않는 이상 영구히 저장되는 노드이다.
- 트랜잭션 로그, 스냅샷, 상태 이미지 등을 유지한다.
- Ephemeral Node
- 노드를 생성한 클라이언트의 세션이 연결되어 있을 경우에만 유효하며, 연결이 끊어지는 순간 삭제됨
- 클라이언트의 연결 유무를 판단
- Sequence Node
- 노드를 생성할때 자동으로 일련 번호가 붙는 노드
- 주로 분산Lock을 구현하는데 사용함
Watch 기능
- 주키퍼 클라이언트가 특정 znode에 watch를 걸어놓는다.
- 해당 znode가 변경되었을때 클라이언트로 callback 호출을 날린다.
- 클라이언트에 해당 znode가 변경되었음을 알려준다.
이때 궁금한 것은 위의 3개 노드와 znode는 무엇이 다른가? 이다.
Znode란 데이터를 저장하고 관리하는 기본 요소이다.
그리고 Persistent, Ephemeral, Sequence 모두 Znode의 종류이다.
즉, 다음과 같은 타입이 있다고 보면 되겠다.
- PERSISTENT: 영구 znode.
- EPHEMERAL: 임시 znode.
- PERSISTENT_SEQUENTIAL: 순차 번호가 붙는 영구 znode.
- EPHEMERAL_SEQUENTIAL: 순차 번호가 붙는 임시 znode.
따라서 Znode와 persistent, ephemeral, sequential은 독립된 것이 아니라,
znode의 상태를 의미한다고 보면 된다.
복제 기능
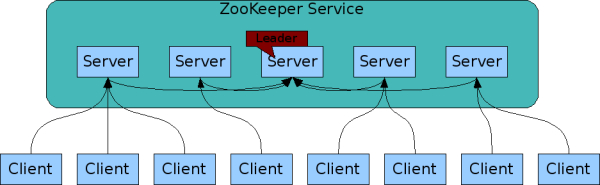
주키퍼는 서비스에 여러 서버와 Client가 존제하고, 그 서버중 하나는 Leader가 된다.
각 서버는 서로의 데이터를 복제해서 공유를 하게 된다.
주키퍼의 흐름을 살펴보면 다음과 같다.
- 클라이언트가 주키퍼 서버에 연결
- 요청, 응답, watch이벤트, heart beats 등을 주고받음
- TCP 연결을 유지하며, 연결이 끊어지면 타 서버에 연결
즉, 어느 서버와 연결해도 같은 데이터를 받을 수 있다는 것이 핵심이다.
활용 분야
- 클러스터의 정보를 확인 : Ephemeral 노드를 만들어서 노드의 유무로 클러스터 상태 확인가능
- 서버의 정보를 확인 : Watch기능을 사용해 서버의 데이터가 변경되면 바로 확인가능
- 글로벌 Lock : HDFS같은 분산FS에서 필요한 Lock 기능을 제공
HDFS은 클러스터와 수 많은 노드를 가지고 있고, 그 노드들이 가지고 있는 시스템, 공유자원, 정보 등을 관리하기 위해서는 Coordinate 소프트웨어가 꼭 필요하다.
Zookeeper는 그러한 기능을 제공해 준다.
Spark
skplanet : https://www.youtube.com/watch?v=rjJ54qtOjW4
spark-yarn : https://spark.apache.org/docs/latest/running-on-yarn.html
spark-cluster : https://spark.apache.org/docs/3.5.3/cluster-overview.html
교수님 강의 : https://www.youtube.com/watch?v=O35dLfyklm0&list=PLCsebpDZm0n6HYSDaNxKQYrNrD4Xk9meX&index=58
Spark를 공부하는데 시간이 좀 많이 걸렸다.
뭔가 정보를 검색해도 정보가 어렵고 양이 너무 방대했으며,
무엇보다도 Yarn의 실행방식을 잘 이해하지 못했던거 같다.
그래서 Spark의 아키텍처를 찾아보아도 어떻게 작동하는지 감이 잘 안왔다.
Yarn 에서의 Spark?
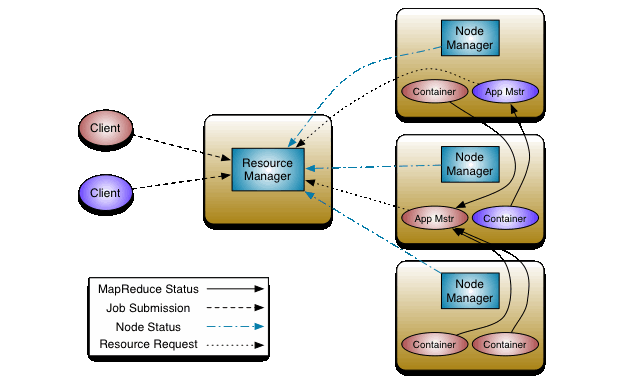
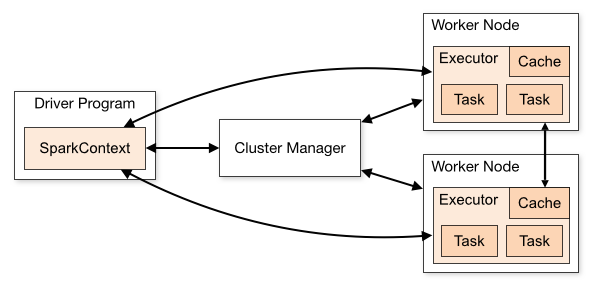
위와 아래는 각각 Yarn / Spark의 아키텍처이다.
Yarn은 Clinet의 요청을 Resource Manager가 Node Manager에 중재하고, Node Manager의 각 요소들은 Status와 Request를 Status를 반환하는 형식이다.
Spark는 ClusterManager가 Driver Program, Worker Node의 리소스를 할당하는 방식을 채택하고 있다.


이때 Spark는 내장 클러스터 관리자나 Mesos, Yarn, K8S의 리소스 메니저를 활용한다고 나와있다.
Cluster Manager는 Spark만의 독립적인것이 아니라, 다양한 방식으로 구현할 수 있다는 것이다.
따라서 Cluster Manager는 말 그대로 리소스를 분배하는 기능을 가진 노드일 뿐, 이 노드를 작동하기 위한 특별한 조취가 필요했던게 아니다.
말 그대로 리소스를 분배하는 노드이기 때문에 특별한 설명도 없었던 것이다.
추가)
Cluster Mode : Driver가 클러스터 내에서 실행
Client Mode : Driver가 클러스터 외부(사용자의 로컬)에서 실행
CLient Mode는 쉽게 말해서 로컬에서 실행하는 테스트 같은 것이다.
다른 프로그램은?
레퍼런스 : https://nightlies.apache.org/flink/flink-docs-release-1.11/ops/deployment/yarn_setup.html

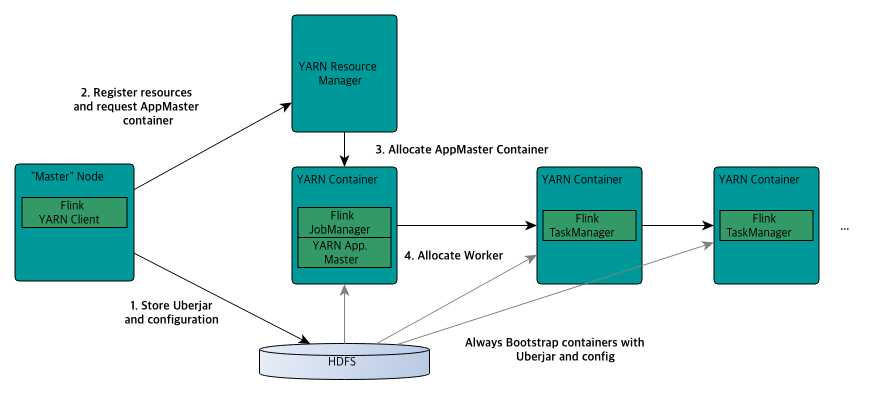
궁금해서 Flink의 아키텍처를 찾아봤다.
Apache의 다른 프로젝트 중에서 리소스 메니저를 활용하는 프로그램도 있는데, 그중 Flink를 포함한 많은 프로그램들이 활용한다.

설명을 보면, Yarn resource manager / HDFS에 접속하기 위해 Hadoop에 access해야 한다고 나와있다. 즉, Spark와 같이 Yarn의 리소스 메니저는 말 그대로 Hadoop 프로그램의 리소스를 관리하는 노드였던 것이다.
며칠 골머리앓았는데 드디어 정리되는 느낌이다!
시간이 오래 걸린 이유를 보면
- Spark 실행시 어떻게 프로그램이 동작하는지 알고 싶었는데, 글들이 하나같이 RDD, Streaming에 중점을 맞춰서 어떻게 돌아가는지에 별 관심이 없었음.
- Spark Document의 양이 너무나도 많고 처음보는거라 이해도 안되서 생각이 정리가 안됨.
시간을 넣은만큼 공부가 되지 못했던거 같다.
Spark vs MapReduce
Spark는 MapReduce의 단점을 보완하기 위해서 만들어졌다.
MapReduce의 문제점이라고 한다면 다음 상황에서 비효율적이라는 것이다.
- 실시간 처리
- 비동기적으로 발생하는 데이터 처리
- 반복 작업이 많은 경우
이는 MapReduce는 Disk를 활용해서 I/O 작업시 많은 오버헤드가 발생하기 때문이다.
위의 내용을 다시 한번 정리해 보면
Disk를 활용하는 방식이기 때문에
Batch를 활용한 일괄 처리에 강점을 보이지만
지속적으로 반복작업해야하는 경우에는 I/O의 오버헤드로 인한 비효율이 심각하다.
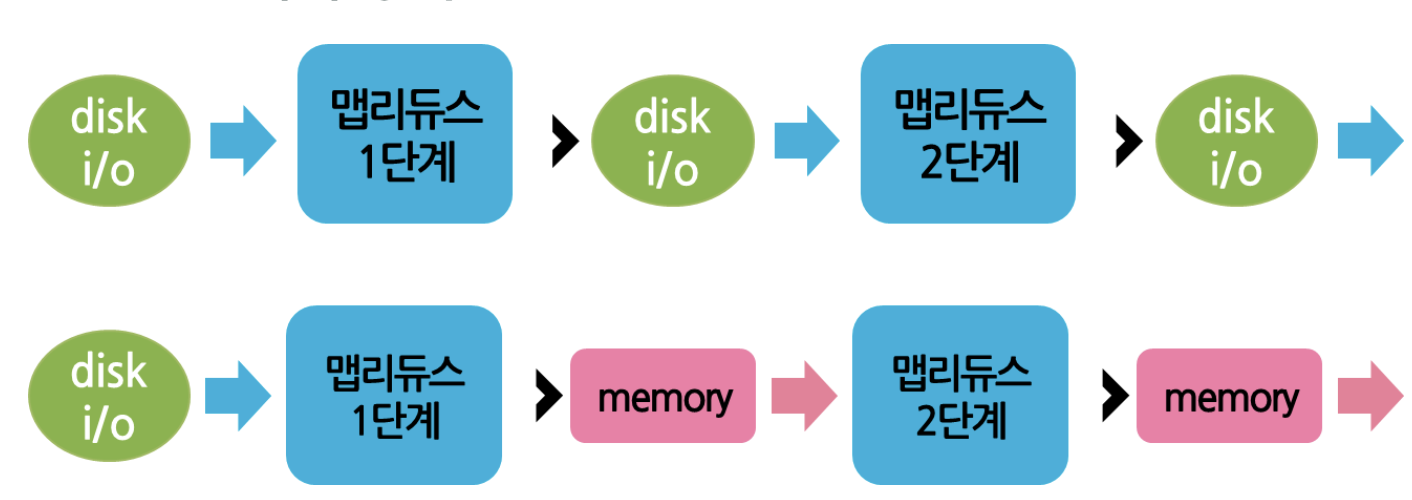
즉, 위와 같이 MapReduce는 Disk I/O가 반복적으로 일어나고,
Spark는 Memory를 활용한다는 것을 알 수 있다.
Spark는 최초 데이터 로드/ 최종 결과 저장 시에만 Disk를 활용하고,
중간 결과를 메모리에 분산저장/병렬 처리 구조로 변경하였다.
이를 통해 10~100배 정도의 속도 향상이 가능했다.
하지만 반대로 생각하면,
MapReduce의 장점 또한 명확해진다.
- Disk 기반의 안정성과 Batch 처리 특화
- 메모리 작아도됨
- 적은 CPU/Memory 자원 소모(사실 Spark는 CPU 사용량 높음)
등이 있겠다.
Spark 요소
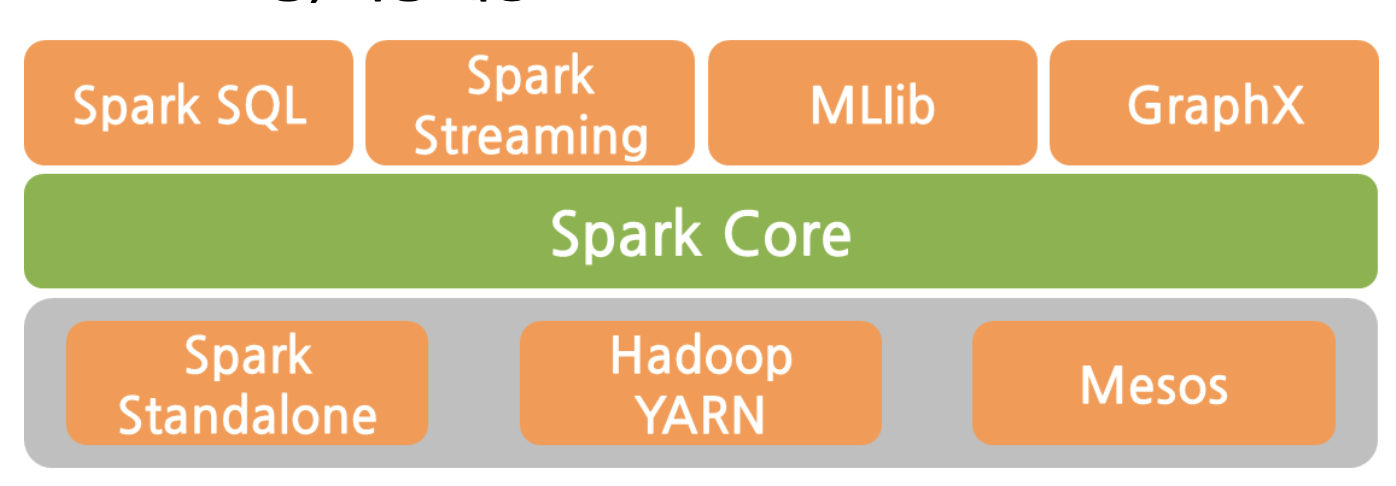
Hadoop 처럼 여러 프로그램이 모여서 Spark를 구성하고 있다.
Yarn/Mesos/Standalone : 자원 관리를 담당하는 부분
Spark Core : 분산작업처리, 스케줄링, I/O, 등의 기능을 제공
Spark SQL : SQL 기반쿼리 수행
Spark Streaming : 스트리밍 데이터 처리
MLlib : ML 라이브러리
GraphX : 그래프 라이브러리
이번 글에서는 Core, Streaming을 중점적으로 다룬다.
아키텍처
Spark Cluster : https://spark.apache.org/docs/latest/cluster-overview.html
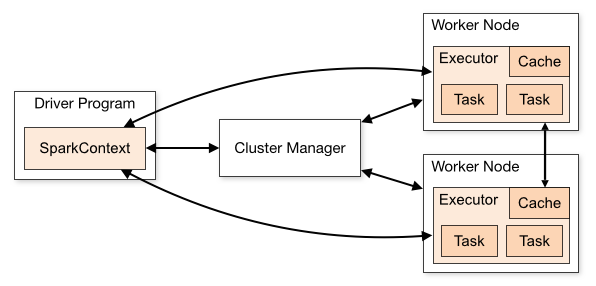
위에서 봤던 아키텍처 그림이다.
구성요소에 대한 설명은 다음과 같다.
- Spark는 클러스터환경에서는 독립적인 프로세스로 실행된다.
- Spark Context 메인 프로그램의 객체에 의해 조정된다.
- Cluster Manager에 연결하여 리소스 할당 가능하며, 연결시 Executor를 얻는다.
- Executor는 계산/데이터 저장 등을 한다.
- Executor, Spark Context는 서로에게 필요한 데이터를 보내며 작업을 수행한다.
- 이때 Executor끼리 데이터를 교환하는 경우도 있다.
그리고 여기서 중요한 것이 Spark Context이다.
Spark Context
레퍼런스 : https://medium.com/@ashwin_kumar_/what-is-sparkcontext-explained-eff53813016c
Spark Context는 쉽게 말해서 Spark의 시작점 중 하나이다.
main()처럼, 진짜 말 그대로 Spark를 실행하는 기능을 한다.
이후 클러스터 매니저에게 Executor 리소스를 요청하고 작업을 수행한다.
작업이라고 하면
- DAG를 생성하고(DAG scheduler)
- Task를 Executor에 분배하고
- 결과값을 반환
이 되겠다.
여러가지 요소가 유기적으로 연결되어 있기에, 바로 DAG, RDD에 대해 알아보자.
DAG
레퍼런스 : https://sparkbyexamples.com/spark/what-is-dag-in-spark/
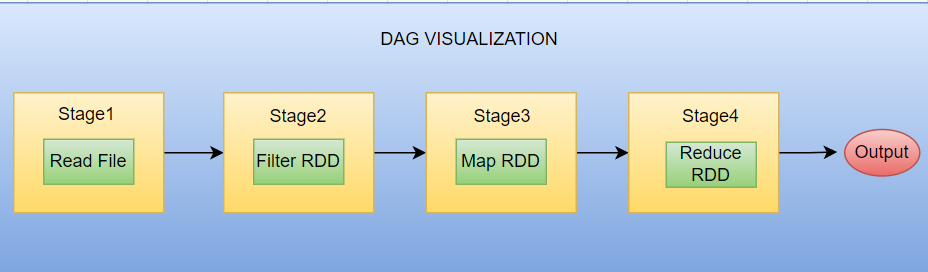
DAG(Directed Acyclic Graph)는 Spark 작업의 논리적 실행 계획을 나타낸다.
RDD의 변환 연산(map, filter)은 DAG의 노드로 추가되며, 액션(count, collect)은 DAG를 실행하는 트리거 역할을 한다.
DAG는 의존 관계를 기반으로 최적화되며, Shuffling과 같은 데이터를 재배치하는 작업 지점에서 스테이지로 나뉘고, 각 스테이지는 병렬로 실행 가능한 태스크로 변환된다.
DAG는 Spark의 DAGScheduler가 최적화하며, 이후 TaskScheduler가 물리적 실행 계획을 Executor에 배치한다.
이때 Shuffling은 Spark에서 비용이 가장 많이 드는 연산인데, DAG가 이러한 Shuffling 단계를 최소화해서 성능을 향상시킨다.
읽다보면 변환/액션이 무엇인지 이해가 안가는데, 이후 나오는 RDD에서 설명이 나온다.
RDD
레퍼런스 : https://www.youtube.com/watch?v=O0N21dTBPy8&list=PLCsebpDZm0n6HYSDaNxKQYrNrD4Xk9meX&index=59
RDD는 한마디로 정의하면 Spark에서 사용하는 기본 데이터 구조이다.
스파크 내부적으로 연산하는 데이터들은 모두 RDD 타입으로 처리된다.
RDD는 Disk에서 데이터를 로딩할때, Spark 연산에서 생성된 데이터를 저장할때 만들어진다.
특징은 다음과 같다.
- 여러 분산노드에 나누어짐
- 다수의 파티션으로 관리
- 변경 불가능한 데이터 set
RDD 연산은 2가지 타입이 존재한다.
Transformation(변환)
RDD에서 새로운 RDD를 생성하는 함수
filter, map ..
Lazy Evaluation을 따르기 때문에 DAG에 계획으로 추가되며, Action을 호출해야 DAG가 실행됨.
또한 2가지 타입이 있는데, Narrow - Wide 타입이 있다.
레퍼런스 : https://medium.com/@priyamjain3377/apache-spark-transformations-narrow-and-wide-d33a772b07dd
Narrow Transformation
Narrow라는 이름이 붙은 이유는 셔플링/파티션간의 데이터 이동을 하지 않아서 그렇다.
예시)
# double each number
input_data = [1, 2, 3, 4, 5]
result_rdd = input_rdd.map (lambda x: x * 2)
# 출력: [2, 4, 6, 8, 10]Wide Transformation
계산을 하기 위해 셔플링/파티션간의 데이터를 교환해야 한다.
예시)
# group data
data = [(“apple”, 3), (“orange”, 2), (“apple”, 5), (“orange”, 4)]
rdd = sc.parallelize(data)
result_rdd = rdd.groupByKey()
# 출력: [(“apple”, [3, 5]), (“orange”, [2, 4])]Action(액션)
RDD에서 RDD가 아닌 다른 타입의 데이터로 변환하는 함수
count(),collect()..
위에서 연산에서 생성된 데이터를 저장할때 RDD가 만들어진다 라고 했는데,
이것은 Transformation의 경우이다.
Action의 반환값은 결과값으로 반환되기 때문에 list, int 등등으로 반환된다.
이는 Spark의 특성과도 연결되는데, RDD가 Memory에 저장되는 것은,
Map-Reduce의 I/O의 문제를 해결하기 위해 Memory에 계산결과를 저장하는 작업이 필요했고,
따라서 RDD라는 형식으로 중간 계산값을 Memory에 저장하는 것이다.
Spark Streaming/Structured Streaming
Event-Driven 아키텍처로 구현된 Spark 프레임워크이다.
Low Latency/일정한 응답속도/예측가능한 성공을 보장한다.
왜 보장한다는 말을 사용할 수 있을까?
그것은 Spark Streaming의 특징에 있다.
Spark Streaming에서 사용하는 데이터 크기는 마이크로 배치나 개별 레코드 정도이다.
따라서 처리하는 데이터의 크기가 매우 작다는 것이다.
그렇기에 간단한 응답이나 데이터 수집 등의 작업을 담당한다.
Spark Streaming은 RDD/Dstream을 사용한다.
DStream은 일정 시간 동안 들어온 데이터를 RDD로 변환한 후, RDD의 연속된 흐름으로 표현되며, 이를 마이크로 배치 처리라고 한다.
Structured Streaming은 Spark Streaming과 유사하지만, DataFrame/Dataset 기반의 스트리밍 처리로 더 높은 수준의 API와 실시간 데이터 처리를 지원한다.
Spark Session / Data Frame
위에서 나왔던 키워드 들이다.
Spark2 버전부터 나온 기능들이고, Spark Session은 Spark Context와,
Data Frame은 RDD와 비교된다.
Spark Session?
- Spark Context, SQL Context, Hive Context를 하나로 통합
- DataFrame/SQL 쿼리, Spark 설정 관리, 데이터 소스 통합 등의 기능을 함.
Spark Context의 업그레이드 버전이라고 생각하면 되겠다
Spark Context는 RDD 기반의 작업을 하는데, 이를 확장시킨 것이다.
Data Frame?
- 스키마 구조(RDD는 Key-Value)
- SQL같은 형식의 데이터를 처리
Spark에서도 SQL 데이터를 활용하기 위해서 만들어진 것이 Data Frame이다.
GPT에게 물어보니 친절하게 코드를 비교해 줬다.
from pyspark.sql import SparkSession
# Spark Session 생성
spark = SparkSession.builder \
.appName("Example") \
.master("local") \
.getOrCreate()
# 데이터프레임 생성
data = [("Alice", 25), ("Bob", 30), ("Cathy", 45)]
columns = ["Name", "Age"]
df = spark.createDataFrame(data, columns)
# 데이터프레임 조회
df.show()
# SQL 쿼리 실행
df.createOrReplaceTempView("people")
result = spark.sql("SELECT * FROM people WHERE Age > 30")
result.show()
# RDD 생성
rdd = spark.sparkContext.parallelize([("Alice", 25), ("Bob", 30), ("Cathy", 45)])
# RDD에서 데이터프레임 변환
df = rdd.toDF(["Name", "Age"])
df.show()
Spark Session에 createDataFrame으로 데이터 프레임을 만드는걸 볼 수있고,
이를 활용해 SQL 쿼리 또한 실행하는게 확인 가능하다.
하지만 SparkContext는 단순히 RDD를 생성하는것에서 끝이 난다.
HBase
레퍼런스 : https://hbase.apache.org/book.html

HBase는 Hadoop 기반 No-SQL DB이다.
이번 파트는 시작전에 GPT와 대화하면서 정리한 생각을 먼저 적어놓고 시작할 것이다.
대화 이전 알고있는 지식은 다음과 같다.
아키텍처 가이드 : https://www.devkuma.com/docs/hbase/architecture/
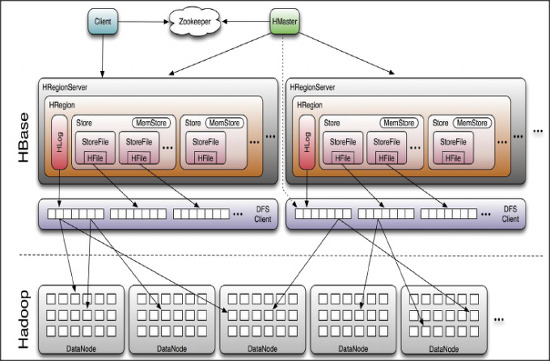
- HRegionServer - HRegion 구조로 되어있다.
- Region은 Key-Value구조로 되어있다.
- ZooKeeper가 메타데이터 제공을 해준다.
그러니까 많은 데이터를 저장하기 위해서 Region을 나눠서 저장한다는 것이다.
그런데 여기서 도저히 이해가지 않는 부분이 발생했다.
Region으로 나눴다고 한들 PB수준의 데이터가 들어오면
각 Region의 데이터가 몇백GB ~ TB 수준의 데이터가 생길것인데, O(n)으로 Get을 한다고 한들 속도가 감당이 될까?
LSM Tree
레퍼런스 : https://suewoon-ryu.medium.com/hbase-%EC%95%8C%EC%95%84%EB%B3%B4%EA%B8%B0-part-1-2fcc7a2413b1
LSM : https://youtube.com/watch?v=i_vmkaR1x-I
Memstore : https://tsaiprabhanj.medium.com/hbase-memstore-a9b730c19e57
HBase가 데이터를 어떻게 저장하는지부터 알아야 한다.
결론부터 말하면 LSM Tree를 사용한다.(No-SQL)
따라서 LSM Tree를 알면 HBase가 어떻게 작동하는지 알 수 있다.
데이터 쓰기

Key - Value 값을 가진 테이블이다.
그리고 이 데이터는 고유 번호를 가지고 있다.
고유번호는 RowKey라고 하며, 데이터를 찾는데 중요한 역할을 하게 된다.
## 데이터 예시
1453,{"name":"kim"}
3322,{"name":"park"}
4678,{"name":"lee"}
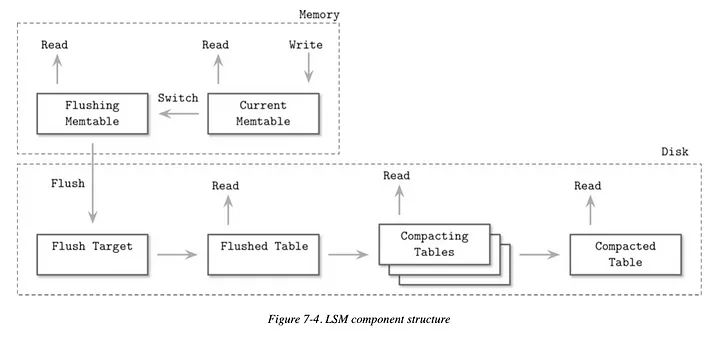
데이터를 쓸때, Memory(Memstore)의 HBase는 Skip List에 추가하게 된다.
각 데이터의 고유번호(이번 예시의 1453, 3322, 4678)만 알면 데이터를 O(logn)으로 찾을 수 있다.
그러다 데이터가 많아져서 메모리가 넘치면 Disk에 SSTable을 만들면 되는 것이다.
이때 SSTable은 Sort 되어있기 때문에 역시나 매우 빠르게 찾을 수 있다.
또한 Immutable(불변) 구조이기 때문에 수정되지 않아 파일의 위치를 빠르게 파악할 수 있다.
그럼 캐시된 메모리가 날아가면 어떻하는가?
Log만 따로 저장한 Disk를 만들면 된다. Log를 기반으로 다시 캐싱하면 되기 때문.
HBase에서는 이것을 WAL이라고 하고, MemStore에 저장되기 전에 먼저 기록된다.
그리고 SSTable의 개수가 많아지게 되면 데이터를 읽을때 여러 SSTable을 찾아야 하기 때문에 느려진다.
따라서 SSTable의 개수가 많아지면 SSTable을 합치는 작업(Compaction)을 하게 된다.
Compaction은 읽기 성능을 향상시키지만, Disk I/O를 많이 사용한다.
Compaction은 Minor/Major 2가지 분류로 나뉜다.
- Minor Compaction : 작은 SSTable 여러개를 병합
- Major Compaction : 모든 SSTable을 병합
데이터 읽기
MemStore에 일단 먼저 찾아본뒤 없으면 SSTable을 찾게 된다.
하지만 Disk에 접근하는것은 시간이 정말 오래 걸리기 때문에 Indexing을 하게 된다.
따라서 자주 사용하는 데이터를 캐싱하는 Block Cache를 확인하고,
어떤 SSTable에 있는지 BloomFilter를(존재 가능성 확인) 통해 SSTable을 필터링하고,
이후 Block Index를 활용하여 SSTable에 데이터의 위치를 확인한다.
아키텍처
레퍼런스 : https://data-flair.training/blogs/hbase-architecture/
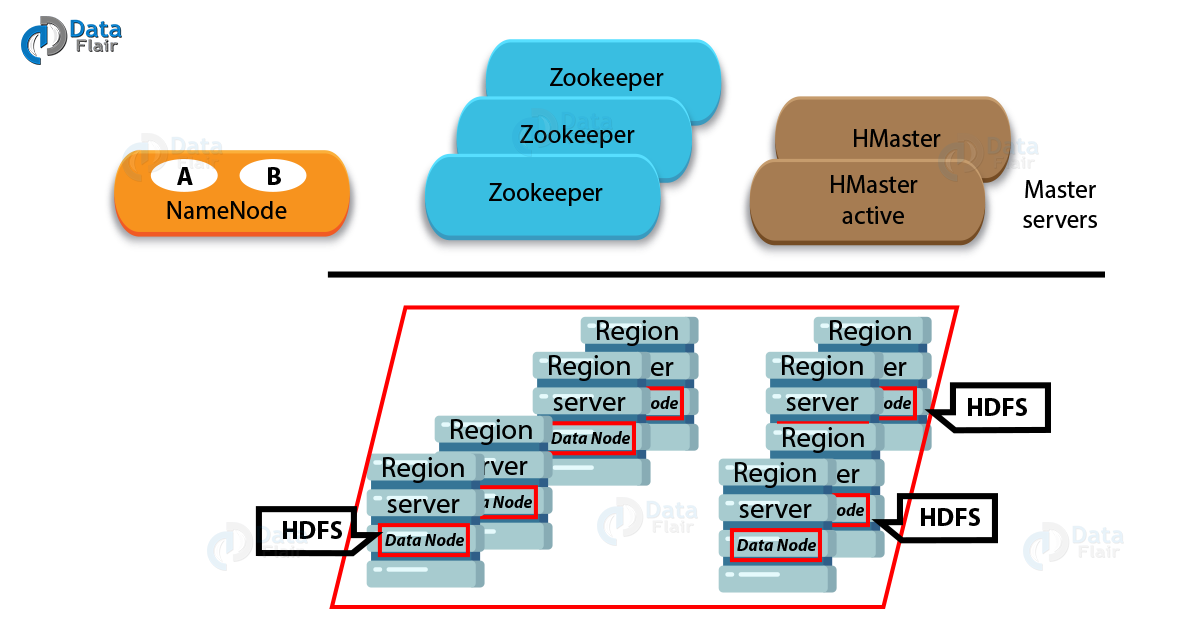
HBase는 3가지 종류의 서버를 가지고 있다.
- HBase HMaster
- Region Server
- ZooKeeper
Region
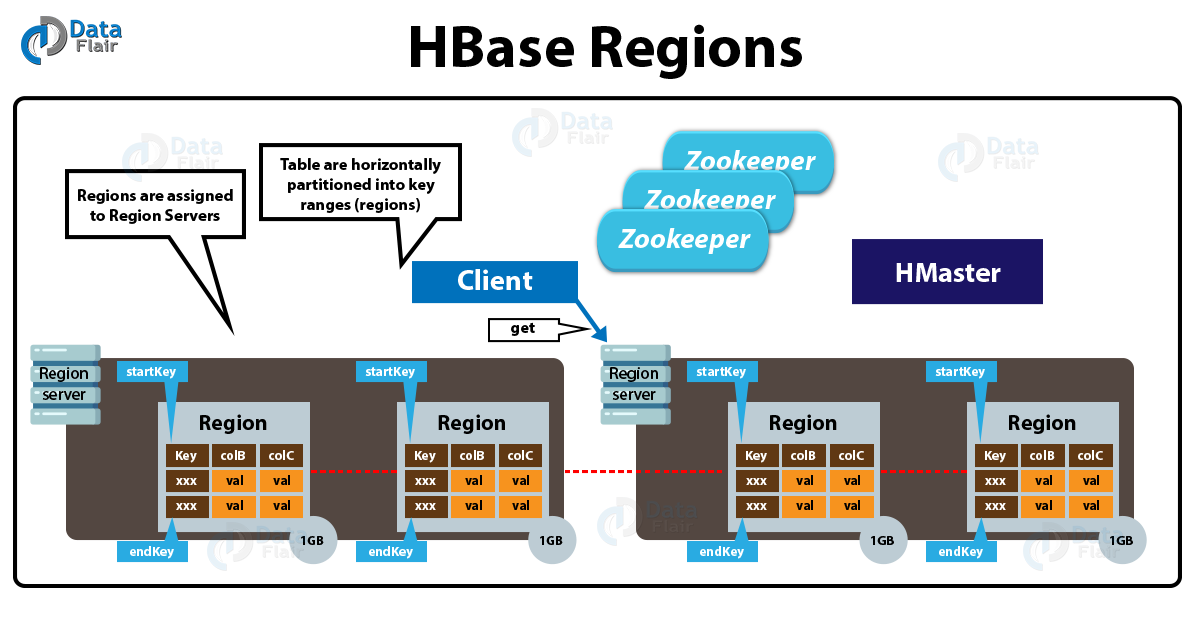
- 각 Region은 특정 Row Key 범위를 관리한다.
- Region은 Region Server에 분산 저장돈다.
- 10GB가 넘어가면 자동으로 2개로 나눠진다.
- 데이터가 추가될때마다 Region에 자동으로 추가가 된다.
위에서 말했던 SSTable과 Region은 다른것이다.
Region은 HBase의 노드에서 관리되고,
SSTable은 Disk(HDFS) 등에 저장된다.
HMaster
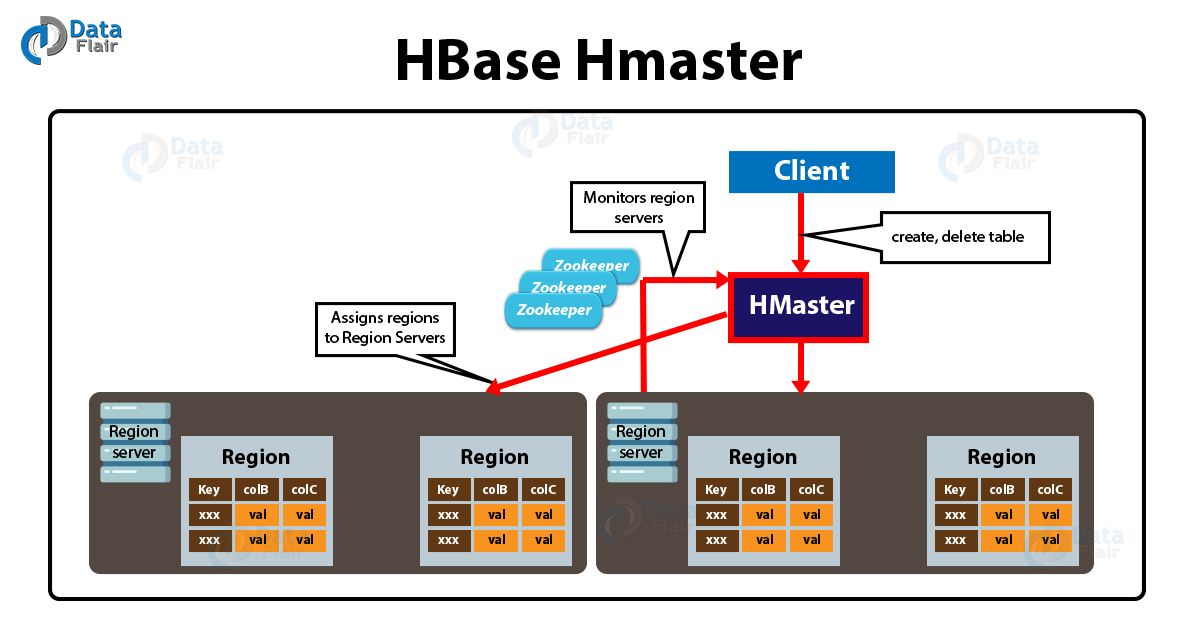
- HMaster는 Region 할당
- Load Balancing, Recovery 목적으로 Region 재할당을 함.
- DDL(테이블 생성, 삭제)작업을 담당
- 클러스터의 모든 Region Server인스턴스의 모니터링
로드 밸런싱이 무슨말이냐면
특정 Cluster의 Region Server가 과부화 되지 않도록 Region을 재분배 한다는 것이다.
- ex)Region Server에 Region이 너무 많을때
ZooKeeper
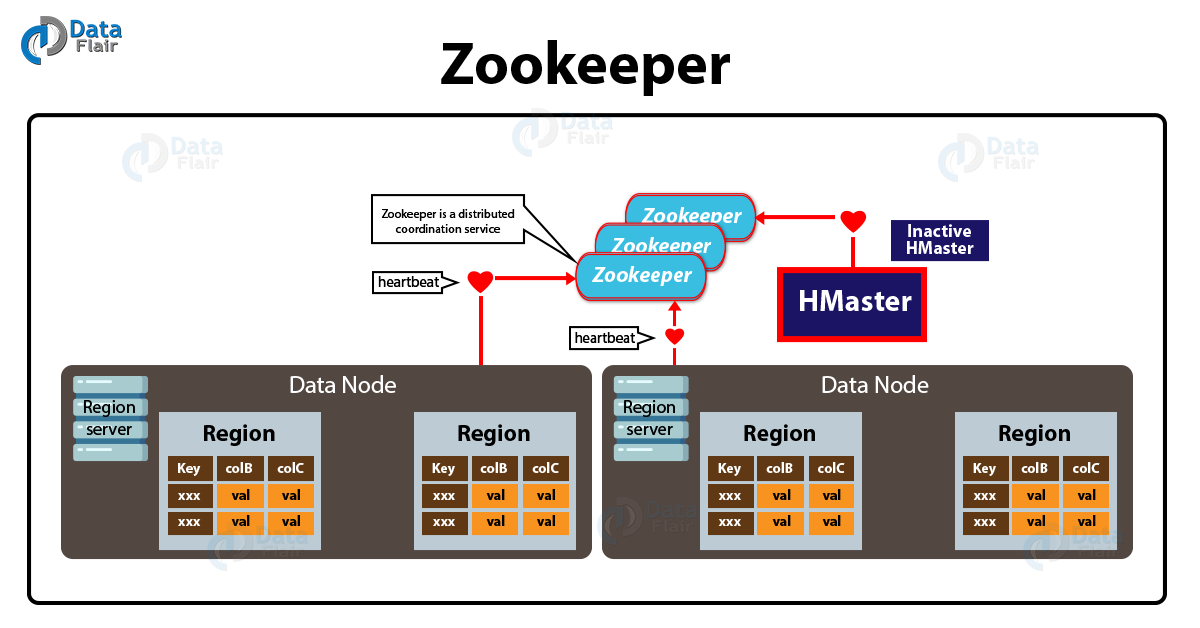
HBase에도 ZooKeeper의 도움을 받는다.
ZooKeeper는 클러스터의 메타데이터 관리, Region Server의 상태를 모니터링 한다.
Hive

많이 징그럽게 생긴 Apache Hive의 로고이다.
Hive는 데이터 웨어하우스 시스템이다.
데이터 웨어하우스라는것은 처음 들어보기 때문에 Hive를 알아보기전에 먼저 공부해보도록 하자.
데이터 웨어하우스?
레퍼런스 : https://en.wikipedia.org/wiki/Data_warehouse
강의 : https://www.youtube.com/watch?v=G2A_CzwVM64
데이터 웨어하우스(data warehouse)란 사용자의 의사 결정에 도움을 주기 위하여 기간시스템의 데이터베이스에 축적된 데이터를 공통의 형식으로 변환해서 관리하는 데이터베이스를 말한다. 줄여서 DW로도 불린다.위키의 설명이다. 축적된 데이터를 공통의 형식으로 변환해서 관리하는 DB라고 하는데, 이게 무슨 뜻일까?
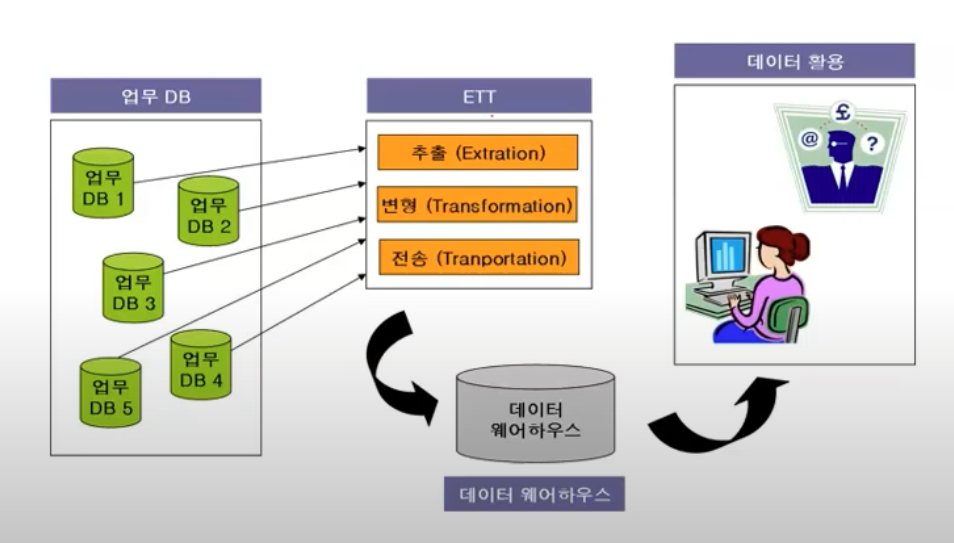
말 그대로 창고다.
일반적인 DB가 업무에 사용하는 데이터 중심의 저장이라고 한다면
사용하지 않는 데이터(예/계시글 지운거) 등등은 모두 데이터 웨어하우스에 적재한 후,
나중에 이 데이터를 분석해서 의사결정 등을 할때 활용한다는 것이다.
특징은 다음과 같다.
- 버전이 하나다. 데이터들은 전사적 관점에서 계속 통합된다.
- 시간성/역사성을 가진다. 특정 시점을 기준으로 정확한 데이터를 가진다.(몇월 몇일에 어떤 데이터가 있었나?)
- 주제를 중심으로 데이터를 조직한다.
- 데이터가 웨어하우스로 들어갈때 재구조화 되어야 한다.
아키텍처
레퍼런스 : https://cwiki.apache.org/confluence/display/Hive/Design
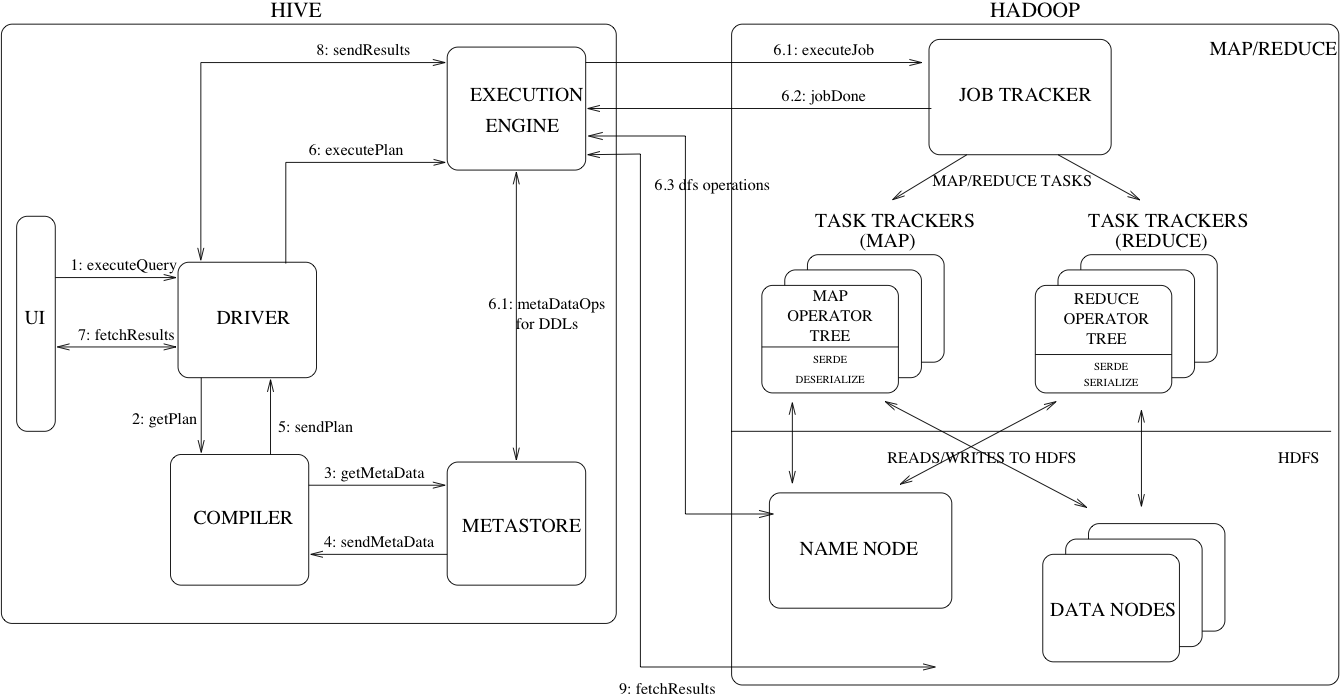
왼쪽은 Hive, 오른쪽은 Hadoop / Map Reduce이다.
위의 그림은 Hive에 데이터 분석을 명령해 Hive가 Map Reduce에 작업을 시키고,
작업의 결과를 반환하는 과정을 나타낸 것이다.
Hive 아키텍처의 각 부분에 대해서 알아보자.
UI
쿼리나 여러 Operation 등을 시스템에 제공하는 인터페이스 이다.
예저네는 Command Line으로 했지만 요즘은 GUI로 제공한다.
Driver
쿼리를 받는 부분이다. Session Handles의 개념을 구현하고, JDBC/ODBC 인터페이스를 모델로한 Execute/Fetch API를 제공
Compiler
쿼리 구문을 분석하며 실행 계획을 생성하는 요소.
MetasStore에서 메타데이터를 받아온다.
MetaStore
다양한 테이블의 Structure information을 전부 저장한다.
column, column type, serializer/deserializer 데이터와 데이터가 저장된HDFS 파일에 대한 정보가 담긴다.
Execution Engine
Compiler의 실행계획을 실행하는 요소이다.
실행 계획은 여러 단계로 구성된 DAG이다.
Execution Engine은 단계간의 종속성 관리하며 단계를 실행한다.
여기서 중요한건 이 Execution Engine에 DAG가 들어갔다는 것인데,
위에서 봤듯이 Spark에서도 DAG를 사용하는것을 알 수 있다.
그리고 Spark를 Hive Execution Engine으로 활용하는것 역시 가능하다.
Hive가 Disk 기반의 처리라 메모리를 사용하는 Spark를 사용하게 되면 속도가 월등히 빨라진다.
위의 아키텍처에서 Execution Engine을 개별적인 요소처럼 그려놨는데,
Execution Engine은 Hive쿼리를 실행하기 위해 선택할 수 있는 실행 도구이다.
따라서 MapReduce -> Spark/Tez로 마이그레이션 가능하다는 뜻이다.
Pig

레퍼런스 : https://en.wikipedia.org/wiki/Apache_Pig
Apache Pig는 Hadoop을 이욯아여 MapReduce를 사용하기 위한 높은 수준의 스크립터 언어와 이를 위한 인프라로 구성되어 있다.
MapReduce는 Low - Level 수준의 언어로 구동되기 때문에 스크립트의 길이가 무지막지하게 길어지게 되는데, Pig의 High-Level 언어로 스크립트 양이 획기적으로 줄어든다는 장점이 있다.
Pig vs MapReduce
레퍼런스 : https://www.geeksforgeeks.org/introduction-to-apache-pig/
서강대학교 SW중심대학사업단 pig 강의 : https://www.youtube.com/watch?v=N4C86u4hTfM
Pig를 왜 써야할까? 그것은 MapReduce의 낮은 생산성에 있다.
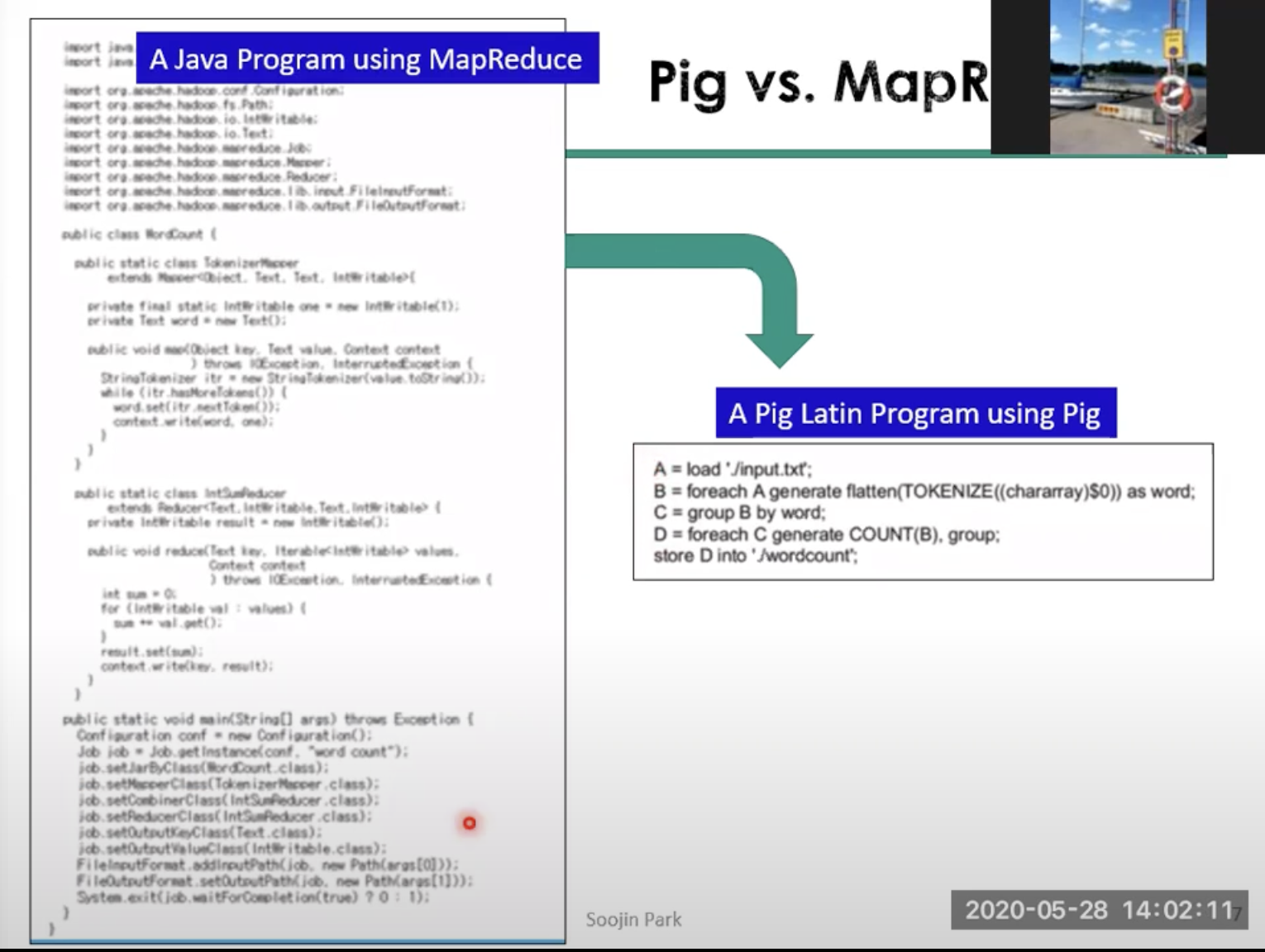
위는 서강대학교 sw 중심대학사업단의 Pig 강의에서 가져온 자료이다.
한눈에 봐도 엄청난 양의 스크립트가 Pig에서는 간단하게 작성되는것을 확인할 수 있다.
Java의 여러 부분들(문법적 길어짐, import 등)이 모두 생략되었다.
이 외에도 스크립트를 작성하는데 많은 도움을 주는 함수를 제공하는 등, 유저의 편의성을 크게 증가시키는 것을 확인할 수 있다.
아키텍처
레퍼런스 : https://www.tutorialspoint.com/apache_pig/apache_pig_architecture.htm
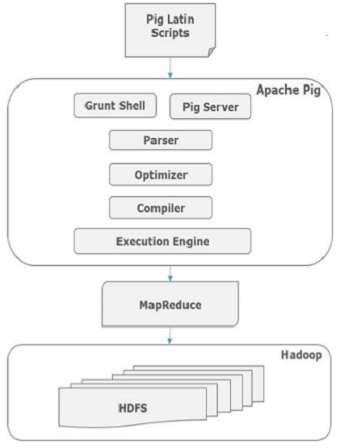
각 구성요소에 살펴보면 다음과 같다.
Parser
Pig Script를 처리하는 부분이다. 여러 검사를 진행 후 Pig Latin은 DAG가 된다.
Optimizer
DAG를 전달받으며, 최적화와 Projection, Pushdown 등의 일을 한다.
Compiler
최적화된 DAG를 MapReduce 작업으로 컴파일한다.
Execution Engine
MaprReduce 작업을 Hadoop에 제출한다.
pig tez mode : https://pig.apache.org/docs/latest/perf.html#tez-mode
pig on spark : https://cwiki.apache.org/confluence/display/pig/pig+on+spark
Pig는 또한 MapReduce 말고도 Tez로 작동할 수 있다.
그리고 spark로 작동하는것을 찾아봤지만 2015년에 작성된 문서 말고는 공식문서를 찾지 못했다..
MapRedcue가 아무레도 Disk I/O로 인한 오버헤드가 많이 발생하다 보니 이런 Engine들과의 결합은 필연적인거 같다.
Pig는 정말 짧게 끝이 났는데, MapRedcue를 대체하는 고급언어라는 간단한 목적 때문에 내부적으로는 정교한 작업이 많지만, 구조적으로 살펴볼때는 내용이 적을수 밖에 없을것 같다.
정리
거의 1달간 Hadoop에 대해서 알아봤다..
물론 Hadoop 뿐만 아니라 Data Engineer에 대한 관심도 생겨서 이것저것 알아보다보니 생각보다 진도가 더디게 나아갔던것 같다.
마지막으로 정리를 하며, 글을 마치도록 하자.
Hadoop Core
- HDFS : 분산 파일 시스템
- YARN : 리소스 관리 플랫폼
- MapReduce : 대규모 데이터 처리를 위한 프로그래밍 모델
- Hadoop Common : 다른 Hadoop 모듈이 사용 및 공유하는 라이브러리와 유틸리티
HBase
Hadoop 기반 No-SQL DB
대용량 데이터를 처리하는데 획기적이며, HDFS/MapRedcue와 함께 사용하는데 최적화되어있음
많은 데이터를 쉽게 저장할 수 있고, 쉽게 찾아서 쓸수있는 장점이 있다.
Hive
Hadoop 기반 웨어하우스 시스템
이전의 데이터까지 모두 저장하기 때문에 데이터 분석을 할때 용이하다.
Pig
MapReduce를 위한 고급언어
Java 기반의 긴 스크립트들을 PigLatin으로 짧게 코딩이 가능하다.
Zookeeper
분산 시스템을 위한 분산 시스템 코디네이션 서비스.
분산 시스템에 추가적으로 필요한 여러 요구사항들을 제공하는 시스템이다.
시스템의 불안정한 부분을 보완하여 안정적인 시스템 동작을 보장한다.
Spark
느린 MapRedcue의 Disk I/O를 해결하기 위한 In-memory 분산처리 시스템
Dag를 활용하며, 다양한 Hadoop 프로젝트와 연동 가능하다.
Oozie??
우지는 워크플로우 관리 시스템이다.
채용공고를 살펴보니 한국의 대부분 기업들은 AirFlow를 사용하는것으로 보이며, 추후 다룰 예정이다.
