
Spark에 대해 더욱 깊게 알아보기 위해, Spark의 사용방법을 중점으로 알아보자.
사용법
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# 1. SparkSession 생성
spark = SparkSession.builder \
.appName("Spark ETL Example") \
.master("local[*]") \
.getOrCreate()
# 2. CSV 데이터 읽기
df = spark.read.csv("input_data.csv", header=True, inferSchema=True)
# 3. 데이터 변환 (net_salary 계산, 30세 이상 필터링, 컬럼 순서 변경)
df_final = df.withColumn("net_salary", col("salary") * 0.9) \
.filter(col("age") >= 30) \
.select("id", "name", "net_salary", "age")
# 4. 변환된 데이터를 Parquet로 저장
df_final.write.mode("overwrite").parquet("output_data.parquet")
# 5. Spark 종료
spark.stop()
GPT로 뽑은 간단한 ETL 코드이다.
일단 Spark를 처음 사용했다면, 사용법은 위 방법을 숙지하면 끝이다.
Spark의 기본적인 흐름은 다음과 같다.
- Spark Entry Point 생성
- 데이터의 추출(Extract)
- 데이터의 변환(Transform)
- 데이터의 적재(Load)
-> 이를 ETL 이라고 한다.
즉, ETL 파이프라인 이라고 한다면
특정 트리거에 따라서 자연스럽게 ETL 과정이 실행되는 파이프라인을 의미하는것이라 보면 되겠다.
그럼 기본적인 흐름을 알았는데, 어떻게 써야할까?

공식 API문서에 모든 API가 정리되어 있다.
예를 들어서 몇개를 정리해 보자.
Extract
!주의!
ETL 부분은 너무 두서없이 적어서 이후 수정예정입니다.

pyspark.sql.DataFrameReader
- 외부 소스로 부터 DataFrame을 읽어오는 클래스
- SparkSession.read로 데이터를 받아와야 사용할 수 있음.

메서드는 위와 같은것이 있고, 이중 CSV의 예제를 살펴보면
import tempfile
with tempfile.TemporaryDirectory() as d:
# Write a DataFrame into a CSV file
df = spark.createDataFrame([{"age": 100, "name": "Hyukjin Kwon"}])
df.write.mode("overwrite").format("csv").save(d)
# Read the CSV file as a DataFrame with 'nullValue' option set to 'Hyukjin Kwon'.
spark.read.csv(d, schema=df.schema, nullValue="Hyukjin Kwon").show()
+---+----+
|age|name|
+---+----+
|100|NULL|
+---+----+이렇게 되어있다.
분명 DataFrameReader.csv 페이지를 읽었는데도 이런 함수는 없다.
하지만 위에도 살펴봤다시피, spark.read.csv를 사용해서 데이터를 읽어오는 것을 알 수 있다.
즉, DataFrameReader는 read로 대신 써야 읽을 수 있는 것이다..
# 2. CSV 데이터 읽기
df = spark.read.csv("input_data.csv", header=True, inferSchema=True)
글이 난잡해졌지만 제일 처음 나왔던 GPT의 예제를 살펴봤을때
read.csv를 사용하지만
실제로는 DataFrameReader의 csv를 사용한 것을 알 수 있다.
Transform
# 3. 데이터 변환 (net_salary 계산, 30세 이상 필터링, 컬럼 순서 변경)
df_final = df.withColumn("net_salary", col("salary") * 0.9) \
.filter(col("age") >= 30) \
.select("id", "name", "net_salary", "age")
마찬가지로 Doc에서 찾아보면
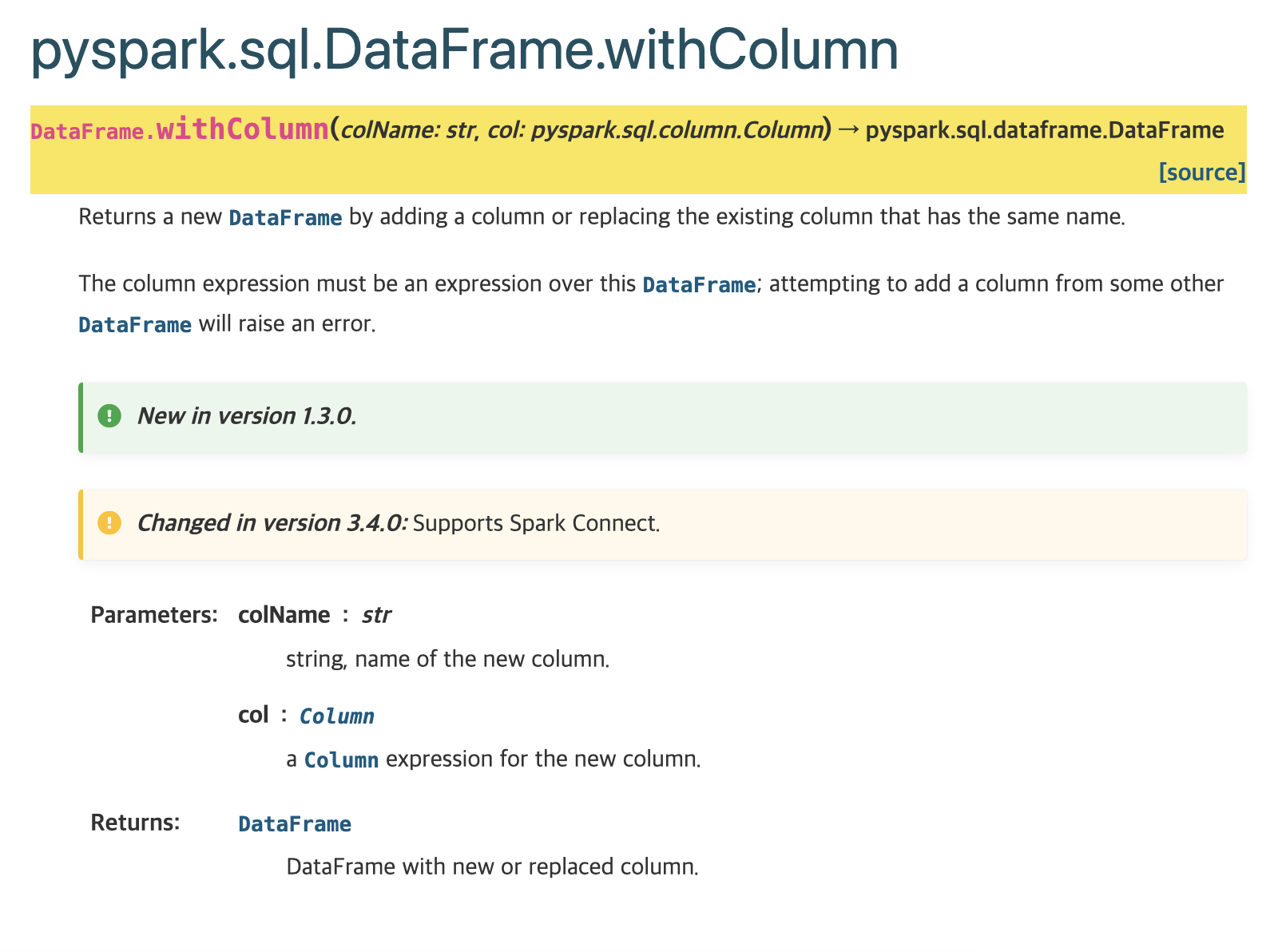
모두 DataFrame에서 찾아볼 수 있다고 나온다.(filter,select 포함)
Load
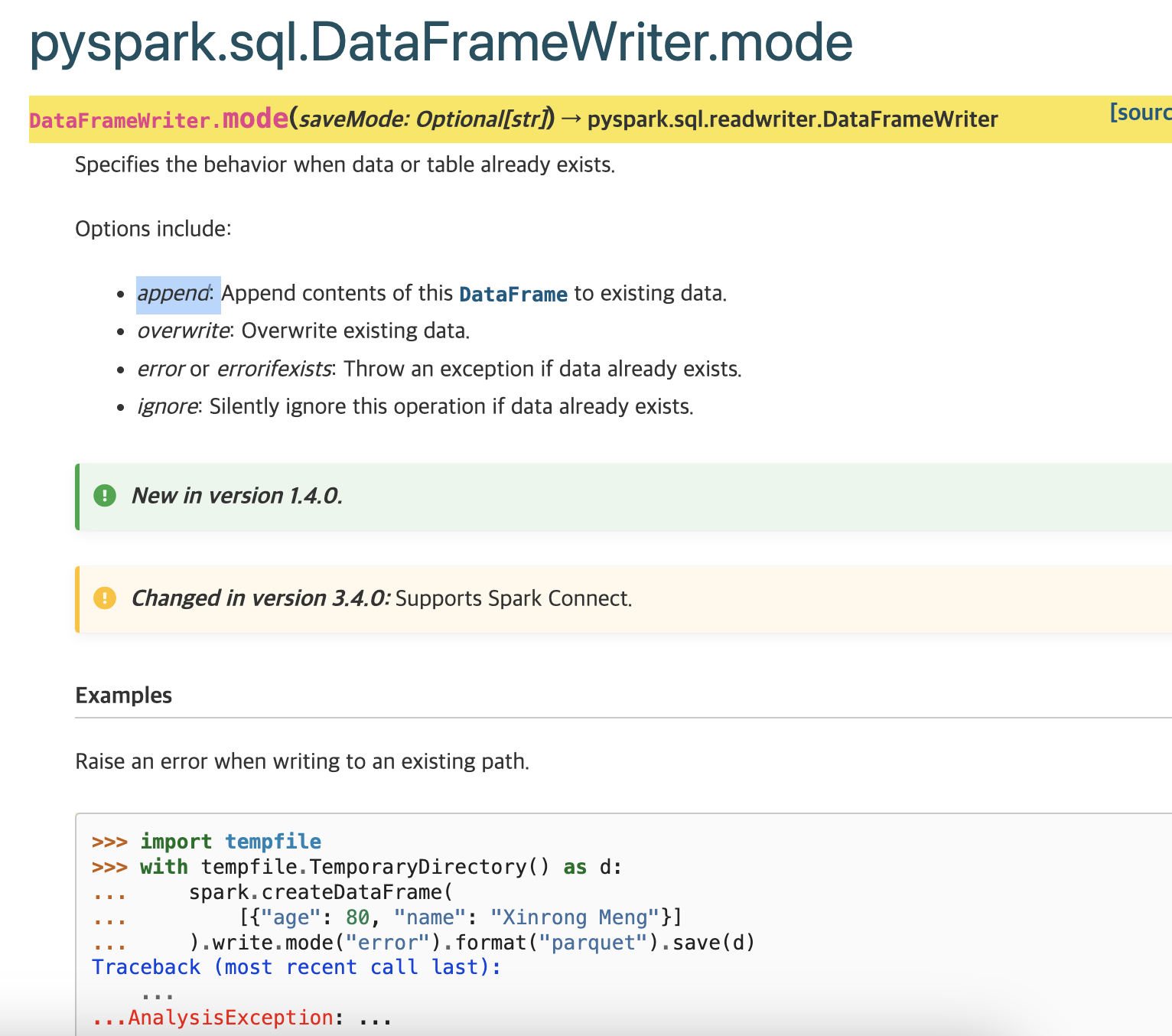
mode와 parquet은 DataFrame의 Write이기 때문에
해당 문서를 찾으면 mode에 대한 정보를 찾을 수 있다.
parquet
- Saves the content of the DataFrame in Parquet format at the specified path.
->지정된 경로의 DataFrame에 저장하는 함수
정리
- 위에서 엔트리 포인트에 대한 언급은 하지 않았는데, 밑에서 다룸.
- 기본적인 ETL 파이프라인은 데이터를 가져와서 변환 및 저장하는것
- 필요한 함수는 API Doc에서 찾아볼 수 있으며, Class 설명을 읽는것이 좋다.
생각보다 Spark의 사용법 자체는 간단하다.
Spring/react 등의 사용법을 공부했을때는 파일 구조부터 이해가 가지 않았지만
Spark는 직관적인 코드의 흐름이 한눈에 보여 이해하기 편했다.
Entry Point
간단한 ETL 코드를 통해 Spark 프로그래밍의 흐름을 알아봤다.
하지만 가장 중요한 부분은 Entry Point이다.
# 1. SparkSession 생성
spark = SparkSession.builder \
.appName("Spark ETL Example") \
.master("local[*]") \
.getOrCreate()위에서 사용했던 Spark Session을 만드는 코드이다.
Spark는 시작하기에 앞서서 Entry Point를 만들어야 한다.
왜 이것을 뒤에 적었느냐 하면, 매우 중요하기 때문이다.
Spark Context
Spark 1버전에서는 SparkContext라는 것이 EntryPoint였다.

이는 SparkCore에서 제일 상단에 위치한 문서에서도 확인할 수 있다.
Main entry point for Spark functionality.
A SparkContext represents the connection to a Spark cluster,
and can be used to create RDD and broadcast variables on that cluster.해석을 해보자면
- Spark 기능의 주요 진입점이다.
- SparkContext는 Spark 클러스터와의 연결을 나타내며,
- 해당 클러스터에서 RDD 및 브로드캐스트 변수를 생성하는 데 사용할 수 있다.
RDD, Cluster, Broad Cast와 같은 여러가지 말이 나온다.
이것에 대해 자세히 알아야 Spark에 대해서 알 수 있다.
Cluster
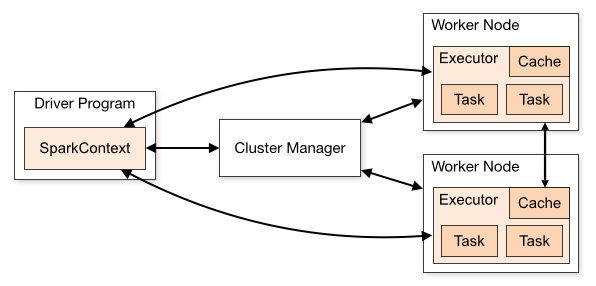
말 그대로 Cluster는 직역하면 '군집'이다. 여러대의 노드(컴퓨터)를 묶는 개념이다.
Spark는 연산을 병렬처리 하기 때문에, 연산에 여러 노드를 사용하고,
이 노드들을 클러스터라고 칭한다.
한마디로 Spark의 연산에 사용되는 노드들의 집합을 Cluster라고 부른다.
Shared Variables (Broadcast,Accumulators)
공유 변수는 Spark에서 정말 중요한 개념 중 하나다.
Spark Overview 중 2번째 문단..
A second abstraction in Spark is shared variables that can be used in parallel operations.
By default, when Spark runs a function in parallel as a set of tasks on different nodes, it ships a copy of each variable used in the function to each task. Sometimes, a variable needs to be shared across tasks, or between tasks and the driver program. Spark supports two types of shared variables: broadcast variables, which can be used to cache a value in memory on all nodes, and accumulators, which are variables that are only “added” to, such as counters and sums.
위의 내용을 정리하자면
- Spark의 두번째 추상화 개념은 병렬 연산에 사용할 수 있는 공유변수이다.
- 기본적으로 Spark가 다른 노드에서 여러 개의 작업(task)으로 함수를 병렬 실행할 때,
해당 함수에서 사용된 각 변수의 복사본을 각 작업에 전송(shipping)한다. - 그러나 일부 변수는 모든 작업에 공유되거나, 작업과 드라이버 프로그램 간에 공유되어야 할 필요가 있다.
여기서 Task란 Spark의 가장 작은 실행단위이다.
이 실행단위가 어떻게 만들어지는지는 다음과 같다.
- Spark에서 어떠한 연산을 수행할때, Spark는 이를 DAG 형태로 변환한다.
- DAG는 여러개의 Stage로 나뉘고, 각 Stage는 여러개의 Task로 구성된다.
- 이때 Stage는 Shuffle 연산을 기준으로 나뉜다.
- Task는 RDD의 각 파티션에 대해 실행되는 작업이다.
- 이 Task는 워커노드에서 실행되고, Driver가 이를 할당하고 관리한다.task의 이야기는 여기까지 하고, 다시 overview로 넘어가자.
Overview의 두번째 문장이 이해가 잘 가지 않을 수 있다.
By default, when Spark runs a function in parallel as a set of tasks on different nodes, it ships a copy of each variable used in the function to each task.
다음 코드를 살펴 보자.
num = 10 # 드라이버에서 정의된 변수
def multiply(x):
return x * num # num을 참조
rdd = sc.parallelize([1, 2, 3, 4])
result = rdd.map(multiply).collect()
print(result) # [10, 20, 30, 40]num이라는 변수는 드라이버에서 정의한 변수이다.
그리고 각 노드들은 rdd.map 연산을 실행한다.
이때, Task들은 각각 1,2,3,4의 숫자중 하나를 가져가서 num과 곱하는 연산을 한다.
모든 Task들은 num이 필요한데, 이 때문에 드라이버에서 Task로 변수를 옮긴다는 말이 나온다.
Task에서 연산할때 사용하는 변수는 참조를 할때(위의 경우는 map이 실행될때) 드라이버에서 변수를 복사하여 가져오게 되는데, 변수의 크기가 엄청나게 커져버린다면 Spark는 각 Task마다 이 데이터를 복사해서 전달해야 됨으로 네트워크/메모리 용량이 커진다.
어차피 모든 Task마다 전송을 해야해서 보내야 하는 데이터의 양은 같지않은가?
라는 의문이 있겠지만..
하나의 노드에 여러 Task를 처리하고, 전달된 데이터는 노드에 캐싱되기 때문에
각 노드당 한번씩만 보내주면 그 노드의 모든 Task들은 캐싱된 데이터를 쓰면되서
유의미한 속도의 향상과 네트워크의 절약을 기대할 수 있다.
이러한 데이터의 전파를 Broadcast라고 한다.
하나의 Task가 드라이버에서 받아온 변수는 다음 Task가 쓸지 안쓸지 모르기 때문에
다음 Task에서 또 받아오는 비효율적인 일을 한다는 것이고,
Broadcast는 이러한 비효율적인 오버헤드를 방지하는 것이다.
그리고 변수를 여러 Task에 공유하면서 값을 계속 누적해야 한다면
Accumulators가 필요하다.
accum = sc.accumulator(0) # 드라이버에서 누적 변수 생성
def add_value(x):
global accum
accum += x # 모든 Task에서 누적 연산
rdd = sc.parallelize([1, 2, 3, 4])
rdd.foreach(add_value) # 각 요소를 처리하면서 accumulator 값 증가
print(accum.value) # 10 (1+2+3+4)
Accumulator는 Broadcast와 마찬가지로 모든 Task에 공통으로 사용되지만,
값을 계속 누적한다는 특성이 있다.
일반적인 변수들과는 다르게 각 Task의 연산 결과를 드라이버가 수집할 수 있다.
그리고 Accumulator는 합계/카운팅 연산만 가능하다.
빼기/곱하기/나누기 등은 불가능.
하지만 AccumulatorParam을 사용하면 다양한 커스텀 연산을 이용할 수 있으며,
Task가 실패 등에 의해 재연산하게 되면 중복으로 더해질 가능성이 존재함.
그래서 정확한 연산 보다는 로그수집, 통계 등에 활용하는것이 바람직하다.
Spark Session
레퍼런스 : https://www.npntraining.com/blog/various-entry-points-for-apache-spark/
레퍼런스 : https://spark.apache.org/docs/3.5.2/sql-migration-guide.html?utm_source=chatgpt.com
Spark Session은 쉽게 말하면 Spark Context가 발전한 것이라 보면 된다.
Spark Session이 나오기 이전, Spark의 엔트리 포인트는 3가지가 있었다.

위는 Spark 1.x버전의 엔트리 포인트를 나타내며, 종류는 다음과 같다.
- SparkContext
- SQLContext
- HiveContext
그리고 위의 Context들은 Spark 2.x버전으로 되면서 SparkSession으로 통합되었다.

위는 Spark 공식문서의 1.6->2.0 migration guide이다.
1버전에서 2버전으로 바꿀때 어떠한 변화가 있었는지 설명해주는 문서이다.
위의 글을 직역해 보자면
- SQLContext와 HiveContext가 SparkSession으로 통합되었다.
- 기존의 DB 및 테이블 엑세스API 또한 모두 SparkSession으로 이동하였다.
그럼으로 SQLContext와 HiveContext는 현 상황에서는 따로 접근할 필요가 없다.
SParkSession으로 대체가 가능하기 때문이다.
그럼 궁금한게, 왜 SparkContext에 대해서는 언급을 하지 않는가?

(SparkCore - SpaekContext 문서)
그 이유는 SparkContext가 여전히 사용되기 때문이다.
SparkContext는 RDD에서 사용이 된다.
반면, SparkSession은 DataFrame, DataSet에 사용된다.
그렇다면, 우리는 RDD와 DataFrame/DataSet의 차이를 알게되면
SparkSession, SparkContext의 차이에 대해 알 수 있게 되는 것이다.
RDD
RDD는 분산된 데이터셋을 관리하는 구조로, 대규모 데이터를 처리하기 위한 핵심 요소이다.
Spark에서 데이터를 효율적으로 처리할 수 있도록 설계되었으며,
Hadoop과 같은 분산 저장소(HDFS, S3)와 연동하여 사용할 수도 있다.
기본적으로 RDD는 분산 환경에서 동작하며, 데이터의 파티션 단위 저장 및 병렬 처리를 지원한다.
RDD의 특징은 다음과 같다.
- RDD는 파티션 단위로 데이터를 저장한다.
- RDD는 메모리 혹은 디스크(HDFS, S3) 등에 분산 저장된다.
- 요소는 Java객체 형태로 저장되며, 스키마가 없다.
- Key-Value 형태로 저장이 가능하다.
- HDFS, Disk, Ram 등 여러 저장소에 저장될 수 있다.
하지만 여기서 Java 객체 형태로 저장되는것에서 문제가 발생한다.
Java 객체는 Heap에 저장되고 Stack에 참조값이 저장이 된다.
이때 참조값 해당 JVM 내에서만 유효하며 다른 JVM에서는 이 주소에 데이터를 찾을 수 없으며, GC에 의해 객체 위치가 변경될 수도 있다.
따라서 데이터를 사용하기 위해서는 객체 데이터를 바이트 스트림으로 변환해야 하는데,
이를 직렬화라고 한다.
예시를 보면서 다시 한번 생각해 보자.
Row 1: (Alice, 25) → <00101010 01101101>
Row 2: (Bob, 30) → <11010110 10010110>
객체 만들기
case class Person(name: String, age: Int)
val person = Person("Alice", 25)
Stack과 Heap의 객체 저장 방식
Stack:
person (변수) → 0x7ffc10
Heap:
0x7ffc10 (Person 객체)
├── name → 0x5a3d20 (String "Alice")
├── age → 25 (기본 데이터 타입, Heap 내부에 저장)
0x5a3d20 (String 객체)
├── "Alice"
├── length → 5
├── hashCode → 12345678 (캐싱된 해시 값)
자료구조를 잘 생각해 보자.
Spark는 Java 기반 프레임워크이기 때문에, 위의 person과 같은 변수들이 객체로써 저장된다.
그래서 name이라는 컬럼에 해당하는 데이터를 나타내기 위해서는
- "Alice"
- length
- hashCode
등과 같은 String 객체의 참조값을 가리킨다.(String값이기 때문에)
이 데이터를 직렬화 하지 않고 그냥 내보낸다면
name 필드에는 문자열 "Alice"가 아닌
Heap의 참조값(예: 0x5a3d20)만 전달되므로, 다른 JVM에서는 해당 데이터를 해석할 수 없다.
따라서, 데이터를 직렬화하여 포인터가 아닌 실제 값을 전송해야 한다.
이처럼 객체의 저장 방식은 다른 프로그램에서 이해할 수 없기 때문에
JVM이 통신을 하려면 직렬화를 통해 데이터를 바꿔줘야 하는 것이다.
자바 자료형 : http://www.ktword.co.kr/test/view/view.php?m_temp1=3119&id=1426
자바 객체의 저장 방식에 대해서는 처음 알게 되었다.
그리고 디스크에 저장될때는 Block 단위 저장이 기본이다.
(Row/Object/Column 단위 저장도 가능하다)
HDFS / 디스크 저장 구조 (Block 단위 저장)
├── Block 1 (노드 1에 저장됨)
│ ├── [ 직렬화된 데이터 블록 ]
│
├── Block 2 (노드 2에 저장됨)
│ ├── [ 직렬화된 데이터 블록 ]
DataFrame
DataFrame에 대해서 먼저 알아보자.
DataFrame : https://www.linkedin.com/pulse/rdd-vs-dataframe-dataset-sanyam-jain-iwsfe/
공식 Doc
A DataFrame is a Dataset organized into named columns.
It is conceptually equivalent to a table in a relational
database or a data frame in R/Python, but with richer
optimizations under the hood. DataFrames can be constructed
from a wide array of sources such as: structured data files,
tables in Hive, external databases, or existing RDDs. The
DataFrame API is available in Scala, Java, Python, and R. In
Scala and Java, a DataFrame is represented by a Dataset of
Rows. In the Scala API, DataFrame is simply a type alias of
Dataset[Row]. While, in Java API, users need to use
Dataset<Row> to represent a DataFrame.
이를 요약하면..
1. DataFrame은 Dataset(뒤에 나오는 Dataset이 아님)으로 구성되어 있다.
2. R/Python의 데이터프레임과 동등하고, 최적화 기능을 강화하였다
3. Scala, Java, Python, R에서 사용 가능하다
정도로 해석할 수 있다.
즉 여러 Dataset이 RDB 데이터처럼 행/열을 이루고 있다는 것이다.
이를 통해서 DataFrame은 여러 Dataset이 행과 열을 이루는 구조를 가지며, 관계형 데이터베이스의 테이블과 유사한 형태로 데이터를 다룰 수 있다.
또한, 내부적으로 최적화된 연산을 제공하여 대용량 데이터를 효율적으로 처리할 수 있다.
그런데 왜 DataFrame이 나오게 된 것일까?
- RDD는 OOP스타일을 지원하는데, 어려움
- 단일 노트북에서 몇 KB의 데이터 처리부터 대규모 클러스터에서 페타바이트(PB) 단위의 데이터 처리까지 확장 가능
- 직렬화 강제
- 스키마 없음
- 최적화 엔진 없음
- SQL 쿼리 사용불가
이를 포함한 성능적 이슈가 정말 많았기에, DataFrame을 만들게 되었다.
또한 여기에 중요한게 있는데, python, pandas 등의 DataFrame, DataSet과 spark의 DataFrame, DataSet은 다르기 때문에 혼동하면 안된다.
DataSet
결론만 말하면 PySpark에는 DataSet이 없다.
앞서 Spark의 EntryPoint는 SparkContext, SQLContext, HiveContext에서
SparkSession으로 통합되었다고 했었다.
이중 HiveContext가 DataSet을 사용했고, 다른 SparkAPI에서 사용한다.
Spark Datasets: Advantages and Limitations : https://www.mungingdata.com/apache-spark/dataset-tods-createdataset-advantages/
Python and R infer types during runtime, so these APIs cannot support the Datasets.
위의 글이 무슨 말인고 하니
Python과 R은 런타임 동안 타입을 추론하니, Datasets에 관한 API가 지원되지 않습니다.
다들 알다시피 Python은 타입을 지정하지 않는다.
아래는 모두 python에서 지원하는 문법들이다.
A = 1
A = 'A'
A = [1]
A = ['A']
A = {1}A라는것이 int형 일수도, Float일수도, String일수도, List일수도 있는데,
이를 '동적 타입 언어'라고 한다.
즉, python 등의 언어가 변수의 자동으로 타입을 맞춰주는 것이다.
R 또한 동적 타입 언어이다.(Rust인줄 알았는데 따로 있는 언어였다..)
이와 반대로 Scala, Java는 정적 타입 언어 이다.
따라서 Python, R과 반대로 Datasets를 사용할 수 있다.
그렇다면 왜 동적 타입 언어는 DataSets를 사용할 수 없는 것일까?
레퍼런스 : https://medium.com/geekculture/introduction-to-datasets-in-spark-79a7d94d9158

위 글에서 힌트를 찾을 수 있었다.
Overview를 읽어보고 요약을 하자면
- Dataset은 Scala에서는 강한 정적 타입을 가진 JVM 객체의 컬렉션이다.
- Encoders를 사용하여 구조화된 쿼리를 표현한다.
- TypeSafety와 객체 지향 프로그래밍 인터페이스를 제공한다.
- Python과 R은 동적 타입이기 때문에 지원하지 않는다.
Q. 그럼 Python에서 정적 타입을 명시하면 가능한가?
A. JVM 내부 Encoders와 직접 호환되지 않음.
Pyspark는 다음과 같은 방식으로 데이터를 직렬화함.
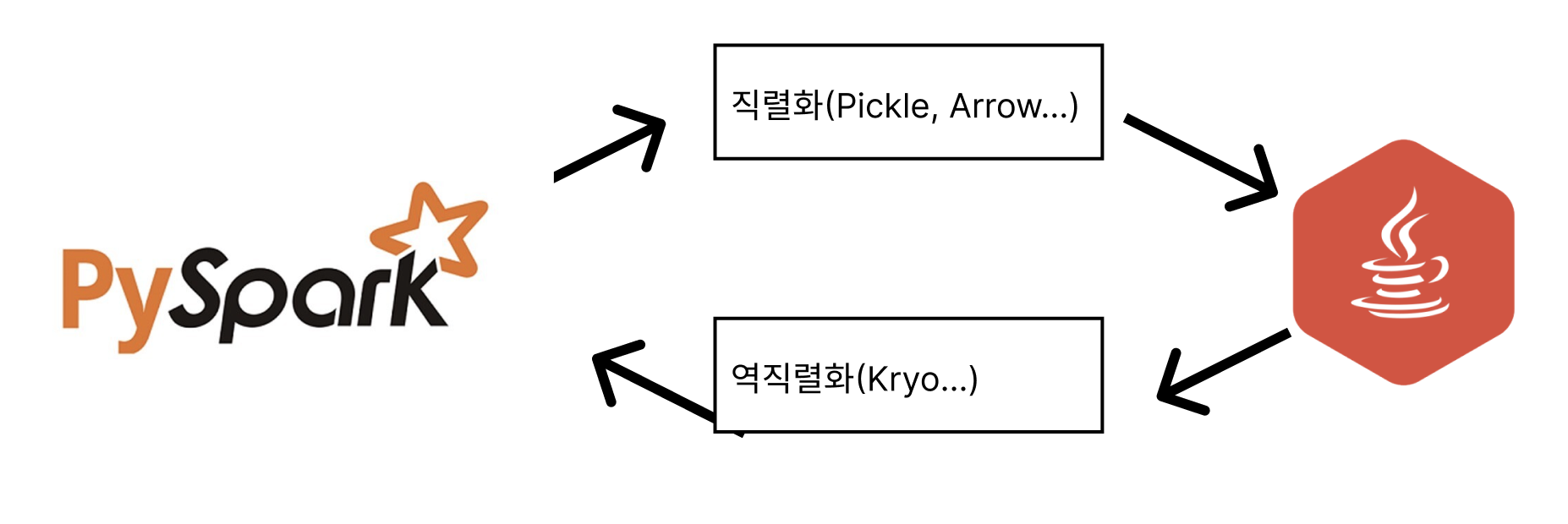
다음은 Pyspark와 JVM이 데이터를 통신하는 방식을 나타낸 것이다.
- Python 객체 (list, dict) → Pickle/Arrow 직렬화(pyspark는 kryo로 직접 직렬화 불가)
- Pickle/Arrow 데이터를 JVM으로 전송
- JVM에서 Spark 내부 포맷(Row)으로 변환 (Thungsten으로 역직렬화)
- Spark 실행 후, 결과를 Kryo등을 통해 Python으로 직렬화하여 반환
위처럼 Pyspark는 JVM에 데이터를 보낼때 직렬화를 한 후 보낸다.
그럼 역직렬화 한 데이터일지라도 Pyspark측에서 Encoder를 활용할 수 없음으로(JVM에있음)
Pyspark는 DataSets를 활용할 수 없게 되는 것이다.
이거 찾느라 시간 많이 소비했지만
다른 타입의 언어 간에 데이터를 통신하기 위해서
거쳐야 할 중간과정이 정말 많고 복잡하다는것을 배웠다..
정리
Spark의 개념과 Entry Point에 대해 공부해봤다.
RDD/DataFrame/DataSet에 대해 알아보았고
Python에서 DataSet이 쓰이지 않는이유,
RDD에 직렬화가 필요한 이유에 대해 알게 되었다.
아마 이 다음글은 다시 Spring으로 돌아가야 할거같다는 생각이 든다.
서류/면접 준비하고 대용량처리에 정신이 팔려버리니 3달이 지나가버렸는데
본 프로젝트를 완성하지도 못했는데 이러는건 아니라는 생각이 들었기 때문이다..
시간이 무한하다면 좋겠지만
일단 여기까지 하는게 좋아보인다.
