
그냥 공부하다가 적은 노트입니다.
정리하지 않은 글입니다.
이 글을 읽는 방법은 다음과 같습니다.
- 주제명
ㄴ- 기본 사용법
ㄴ- 예제1 + 설명
ㄴ- 예제2 + 설명
이것에 대한 예제는 다음과 같습니다.
쿼리문 1번
~할때 쓰는거
기본 사용법
SELECT 쿼리1
FROM 쿼리2
GROUP BY 쿼리3
예제1번
~~~
1번의 설명
예제2번
~~~
2번의 설명이러한 흐름으로 읽으시면 좀 더 쉽게 읽으실 수 있습니다.
실행순서
앞으로 배우겠지만 실행 순서는 다음과 같다.
- FROM
- JOIN
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
- LIMIT
즉 SELECT가 먼저 왔다고 해도
FROM/JOIN/WHERE 등에 의해 범위가 좁혀지고 난 후
특정 데이터를 대상으로 연산한다.
SELECT
특정 칼럼을 출력할때 쓰는거
-기본사용법
SELECT [컬럼명, 계산식, 집계함수 등]
FROM [테이블명];
-중복제거
SELECT DISTINCT CATEGORY
FROM PRODUCTS;
-별칭 사용
SELECT ID, NAME AS USER_NAME
FROM USERS;
예제
SELECT ID, IFNULL(CHECK, 0)
FROM CHART
-> CHECK값이 NULL이면 0 출력하라는 소리
SELECT PRICE * 0.9 AS DISCOUNTED_PRICE
FROM PRODUCTS;
- 계산식도 사용 가능
SELECT SUM(BILL) AS INCOME
FROM CHART
-> BILL값을 다 더한걸 INCOME으로 출력하라는거임
*** 이거 GROUP BY에 한번더 나오니까 주의 ***
진짜 중요하니까 무조건 봐야됨
SELECT ID, NAME, DATE_FORMAT(M.DATE_OF_BIRTH, '%Y-%m-%d') AS DATE_OF_BIRTH
FROM CHART
-> DATE_FORMAT 같은 형식을 사용해서 날짜의 형식을 자기가 정할 수 있음.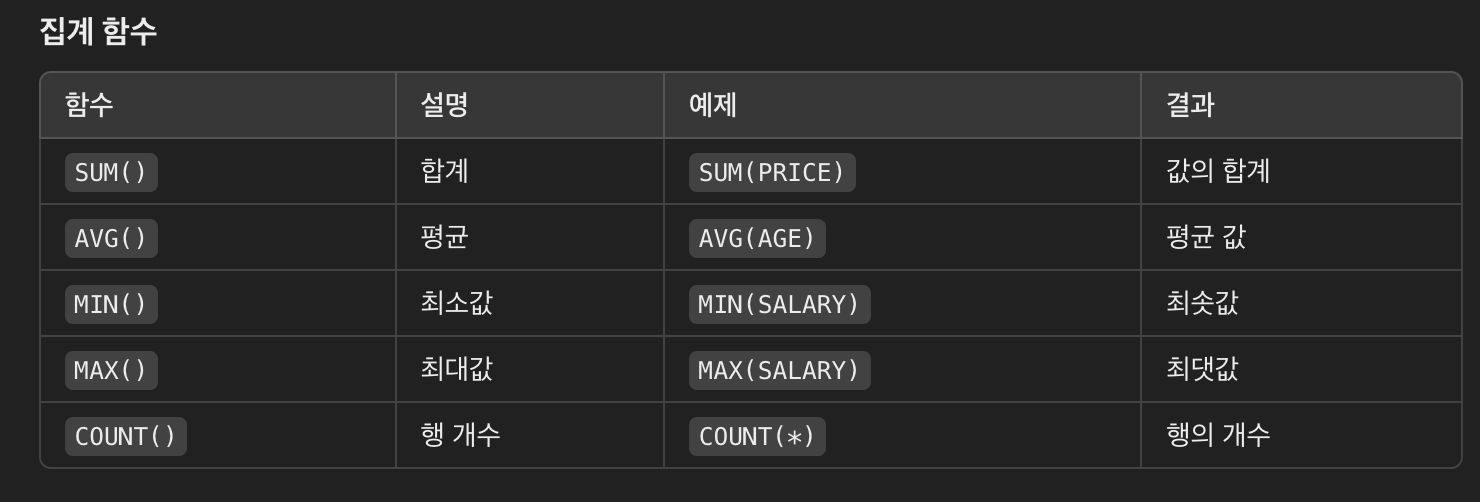
집계함수 참고용
- COUNT(DISTINCT 컬럼) 으로 중복 제거 가능
FROM
무슨 차트에서 데이터를 가져올것인가
기본 사용법
FROM [테이블명] [별칭];
별칭을 사용하지 않을떄
SELECT ID
FROM CHART
별칭을 사용할때
SELECT C.ID
FROM CHART C
WHERE
조건을 거는부분
프로그래밍 문법에서 if를 담당함
'>', '<=', '=' 등의 등호를 사용함
기본 사용법
WHERE [조건식];
SELECT ID, AGE, RECIPE
FROM PILL_CHART
WHERE AGE > 12
-> 나이가 12살보다 많은 사람의 약 처방전을 출력하라
SELECT ID, AGE, RECIPE, DATE
FROM PILL_CHART
WHERE AGE > 12
AND MONTH(DATE) > 3
-> 3월 이후 데이터만 출력
AND 연산을 사용할 수 있다
그리고 DATE 타입의 데이터는 MONTH, YEAR 등을 사용해서 필요한 부분을 비교할 수 있음.
WHERE AGE > 12 AND (MONTH(DATE) > 3 OR YEAR(DATE) = 2022);
+ AND가 OR보다 우선적으로 실행되기 때문에
복잡한 쿼리는 묶어서 사용하면 좋음
NULL 관련은 IS를 써야 한다.
WHERE LENGTH IS NULL;
WHERE LENGTH IS NOT NULL;
처럼
JOIN
두 함수의 집합 관계를 의미한다.
기본 사용법
FROM 테이블1
JOIN 테이블2 ON 테이블1.컬럼 = 테이블2.컬럼
정말 간단하게 생각해야 햇깔리지 않는다.
위의 기본 사용법을 예로 들면
테이블1번의 특정 칼럼과 테이블2번의 특정 칼럼이 일치하는 데이터를 추출한다.
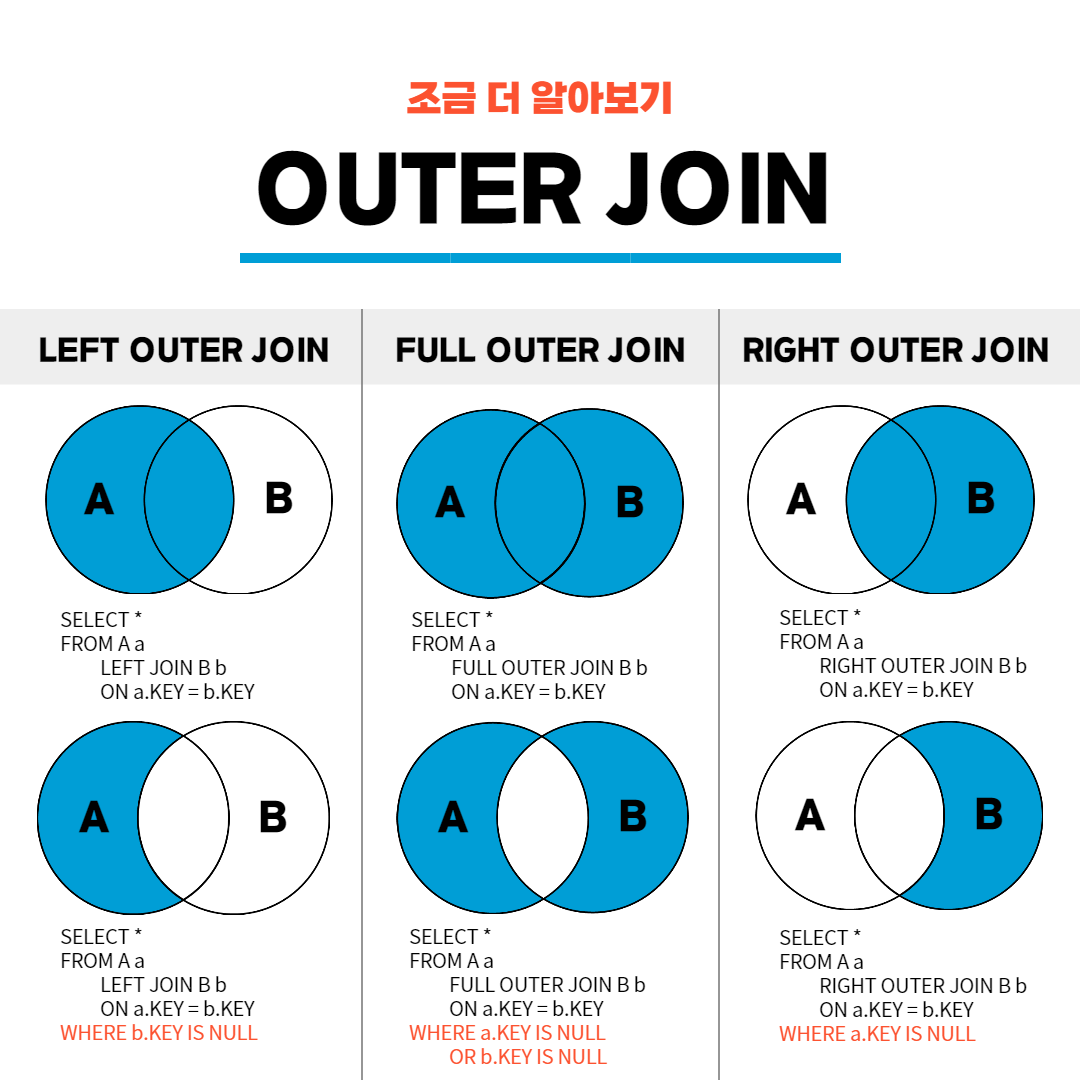
기본적으로 JOIN은 INNER JOIN을 의미한다.
그리고 사용하는 JOIN은 다음과 같다.
- INNER JOIN
- LEFT JOIN
- RIGHT JOIN
- FULL OUTER JOIN
그리고 INNER JOIN은 교집합을 의미한다고 보면 된다.
왜 필요한가?
-> JOIN을 공부하기 위해서 반드시 알아야 한다고 생각함.
데이터는 처음에 FULL OUTER JOIN의 전부를 가져온다.
즉, AUB의 꼴을 가진다는 것이다.
여기서 우리가 A에만 포함되는 데이터를 가지고 싶다면?
아니면 B에만 포함되는 데이터를 가지고 싶다면?
그것도 아니라면 A와 B가 겹치는 데이터를 제외하고 싶다면?
등등의 니즈를 충족시켜주는 쿼리문이다.
헷갈리기 쉬운 점
JOIN을 쓰지 않고 FROM A만 썼을때는 데이터가 위처럼 교집합이 나오지 않는다!
교집합은 어디까지나 '추상적'인 데이터의 표현일 뿐이지
JOIN을 씀으로써 관계가 생겨난다고 판단해야 한다.
SELECT A.ID, A.NAME
FROM A;
SELECT A.ID, A.NAME
FROM A
LEFT JOIN B ON A.ID = B.ID;위 두 쿼리의 출력값은 같다.
왜냐하면 A의 데이터를 모두 출력하기 때문이다.
하지만 아래의 쿼리는 B테이블을 추가적으로 출력하는것도 가능하다.
SELECT A.ID, A.NAME, B.VALUE
FROM A
LEFT JOIN B ON A.ID = B.ID;혹은 이를 이용해서 중복되는 값을 제거할 수도 있다.
SELECT A.ID, A.NAME
FROM A
LEFT JOIN B ON A.ID = B.ID
WHERE B.ID IS NULL;이렇게 되면 B 테이블의 값이 NULL인, A와 B의 교집합을 뺀 A의 데이터만을 출력한다.
GROUP BY
말 그대로 그룹을 묶는것
기본 사용법
SELECT 컬럼1, 집계함수(컬럼2)
FROM 테이블명
GROUP BY 컬럼1;
SELECT ID, SUM(BILL) AS INCOME
FROM CHART
GROUP BY ID;
-> ID별로 INCOME을 구하라는 소리
GROUP BY가 있고 없고에 따라서 SUM 함수의 작동방식이 달라진다
SELECT USER_ID, PRODUCT_ID
FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID
HAVING COUNT(*) > 1
USER_ID, PRODUCT_ID를 기준으로 묶고
그 갯수가 몇개인지 COUNT 하는 SQL문임
이처럼 GROUP BY는 특정 컬럼의 묶음을 기준으로 데이터를 나타냄
틀린 예제
SELECT USER_ID, PRODUCT_ID, CUSTOMER
FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID
-> CUSTOMER가 (USER_ID, PRODUCT_ID) 묶음당 여러개가 발생할 수 있음으로 처리 불가
올바른 예제
SELECT USER_ID, PRODUCT_ID, SUM(SELLING) AS INCOME
FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID
-> (USER_ID, PRODUCT_ID) 묶음당 얼마나 팔렸는지 판단하는 집계함수를 사용
SUM, MAX, MIN 등을 사용하면 계산이 가능함으로 처리 가능
HAVING
GROUP BY 전용 if문
WHERE의 GROUP BY버전이라고 보면 된다.
SELECT 컬럼1, 집계함수(컬럼2)
FROM 테이블명
GROUP BY 컬럼1
HAVING 집계함수(컬럼2) 조건;
이렇게 쓰임
SELECT USER_ID, SUM(SALES_AMOUNT) AS TOTAL_SALES
FROM SALES
GROUP BY USER_ID
HAVING SUM(SALES_AMOUNT) >= 700;
-> 총판매량 700 이상인 USER의 ID와 판매량을 출력해라
ORDER BY
정렬할때 쓰는 기능
기본 사용법
ORDER BY [컬럼명] [ASC|DESC];
SELECT ID, AGE, RECIPE
FROM PILL_CHART
WHERE AGE > 12
ORDER BY ID ASC, AGE DESC;
내림차순은 ASC, 오름차순은 DESC로 정렬가능함
왼쪽부터 오른쪽 순으로 정렬하며, ','로 구분, ';'로 마무리함