
레퍼런스 : http://www.kocw.net/home/cview.do?cid=6b984f376cfb8f70

저작권 법에 따라 출처 공개, 영리목적 사용금지, 내용을 의도적으로 바꾸지 않습니다.
이전에는 App 계층 관점에서만 봤다면, 이번에는 Transport 계층 관점까지 볼 것이다.
TCP/UDP 까지만 봤지만 네트워크 통신동안 어떤 과정을 통하는지 고려한다는 것이다.
데이터 전송의 예시를 부자.
- App에서 메시지를 보낸다.
- Transport 에서 세그먼트에 담긴다. 데이터 + 헤더로 이루어지는데, 메시지가 데이터에 담긴다.
- Network에서 패킷에 담긴다. 여기서도 데이터 부분에 세그먼트가 담고 추가정보는 헤더에 담긴다.
- Link 에서도 똑같이 반복한다. 여기는 프레임이라고 부른다.
Multiplexing, DeMultiplexing
메시지를 보낼때 정해진 주소에 보내는것을 Multiplexing 이라고 한다.
하나의 Device에서 여러 데이터가 함께 나가서 붙여진 이름이라고 한다.
레퍼런스 : https://en.wikipedia.org/wiki/Multiplexing
위키 설명을 보면
- 다중화(Multiplexing)은 두개 이상의 저수준의 채널들을 하나의 고수준의 채널로 통합하는 과정을 말하며, 역다중화(inverse multipleing, demultiplexing, demuxing) 과정을 통해 원래의 채널 정보들을 추출할 수 있다
진짜 여러 채널들에서 같이 데이터를 보내는것을 의미한다.
TCP/UDP가 모두 이러한 작업을 하는데, 각각이 하는 방식이 완전히 다르다.
UDP 경우
Connection Less Demux
소켓과 소켓 사이에 1:1 매핑 개념이 없다.
그래서 세그먼트 헤더의 필드로 포트번호가 적힌다.
TCP 경우
Connection-Oriented Demux
소켓과 소켓 사이에 1:1 매핑이 되어있음
여기서 하나 중요한 개념이 나온다.
외부에서 들어오는 데이터가 전부 동일한 포트번호를 가지고 있다.
하지만 Source 데이터가 다르기 때문에 DeMultiplexing을 할때 알맞은 소켓으로 연결시켜준다.
즉, 같은 포트라도 여러개의 소켓이 열려있을 수 있고, 각각 식별 가능하다는 것이다.
이후 나오는 추가설명은 소켓을 연결하는 실습에 관한 내용인데 ,
소켓 연결하면 Response 값이 소켓의 ID값을 전송한다.
그래서 이 소켓ID값으로 데이터를 보내면 같은 포트라도 고유 ID가 있기 때문에 올바른 소켓으로 연결이 가능하다는 것이다.
Connectionless Transport : UDP
간단해서 10분안에 설명이 끝난다고 한다.
세그먼트(뿐만아닌 모든 프로토콜)는 데이터/헤더로 이루어져있는데,
헤더를 이해하는것이 프로토콜을 이해하는 것이다.
왜냐하면 상대에게 데이터를 전송해야 하는데, 그 데이터들이 헤더에 담기기 때문이다.
헤더는 전부 오버헤드라고 봐도 무방하다. 따라서 정말 필요한 데이터만을 담기 위해 개발자들이 노력했다.
UDP 구조
UDP 세그먼트 헤더 - 가로 32bits
- Source Port : 보내는 포트번호
- Desp Port : 받는 포트번호
- Length : 전체 길이(끝지점을 알아야하니까)
- CheckSum : 에러를 잡아줌. 만약에 오류가 있다면 반환
총 4개 + Application Data로 이루어져있다.
오류 채크를 하긴 하지만, 데이터에 오류가 있는지는 Host도, Client도 알수 없다.
여기는 UDP에 대해서 말하는 것이지만, UDP의 헤더는 가로 32bits라서 할당 주소가 2^16정도이다.(실제는 더작음)
프로토콜 설계를 할때는 충분했지만, 점점 이것도 부족해지고 새로운 문제가 발생했고, 그런 문제에 대한 해결책을 찾기 위해서 다른 방법을 도입하는 중이다. 관련 내용은 수업 계속 듣다보면 나온다고 한다.
Principles of reliable data transfer
TCP의 중요한 기능중 하나이다.
한가지 예시를 생각해 보자.
한국에 사는 Host가 미국 캘리포니아에 사는 Client에 TCP로 데이터를 보낸다고 가정해 보자.
내가 보내는 순간은 신뢰할 수 있지만, 여러 스위치, 라우터를 통과하는 과정은 믿을수 없다.
따라서,어떤 방법으로 TCP가 수많은 과정을 거치면서도 믿을수 있는 데이터 전송을 할수 있는가?에 대한 이야기다.
믿지 못하는 이유는
- Error
- Loss
2가지 손실을 이유로 잡을 수 있다.
만약 손실이 하나도 없다고 가정한것이 rdt 1.0 버전이다.
rdt 2.0 부터는 bit 에러를 고려하기 시작한다.
교수님의 예시로는, 전화할때 상대방의 말을 지속적으로 알아듣는다는것을 나타내기 위해
응, 어, 그래, 등과 같은 추임새를 말한다.
그러다가 추임새가 오랫동안 return 되지 않으면, 상대방은 전화가 송신되지 않는다고 생각할 수 있다.
이와 마찬가지로, rdt 2.0에서는 상대에게 피드백을 주기 시작한다.
데이터를 수신하다가 에러가 발생한다면 피드백을 통해 데이터 재전송을 요청한다.
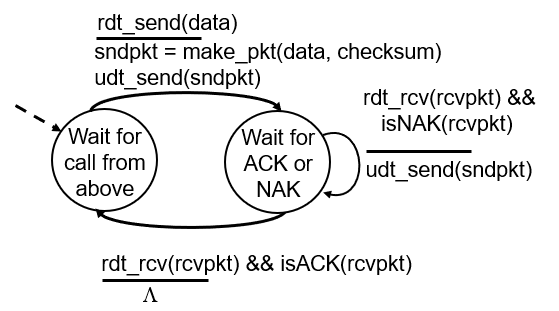
(구글링하니까 그림이 나온다.)
rdt가 checksum을 헤더에 담아서 데이터를 보내고
잘받았다(ACK) or 잘못되었다(NAK) 중 하나를 담아서 재전송 한다.
하지만 여기에도 문제가 발생하는 코너 케이스가 존재한다.
- 메시지를 보냈는데, Error를 발견한다.
- 이후 피드백을 보내는데(NAK) 이 피드백 자체에서 오류가 발생하면 어떻게 행동해야하는가?
- 피드백이 왔는데 보내는게 오류났는지, 피드백이 오류났는지 구분이 안된다.
질문 : 그냥 재전송 요청하면 안됨?
답 : A - Z 까지 데이터를 보낸다고 쳤을때, A의 피드백이 오류가 나서 재전송했다고 쳐보자.
그러면 수신하는사람은 AA가 와야되는건지 뒷 A가 오류에 의한 재전송인지 구분을 못함.
해결책 : Sequence Number를 붙여주자.
즉, 데이터에 순서를 붙여서 AA가 오면 1번 2개니까 뒤의 데이터를 버린다.
질문 : 그럼 Sequence Number를 몇개 붙여주는데?
답 : 어차피 하나 받고 요청보내는거니까 0,1만 있으면됨.
하나 받고 확인하고 다음꺼 요청하는 형식이라 같은거 2번오면 뒤에꺼 버리면된다.
데이터에 넘버 다 붙이면 오버헤드가 너무 크게 발생할것이라 예측가능하다.
를 그대로 그린게 이거다
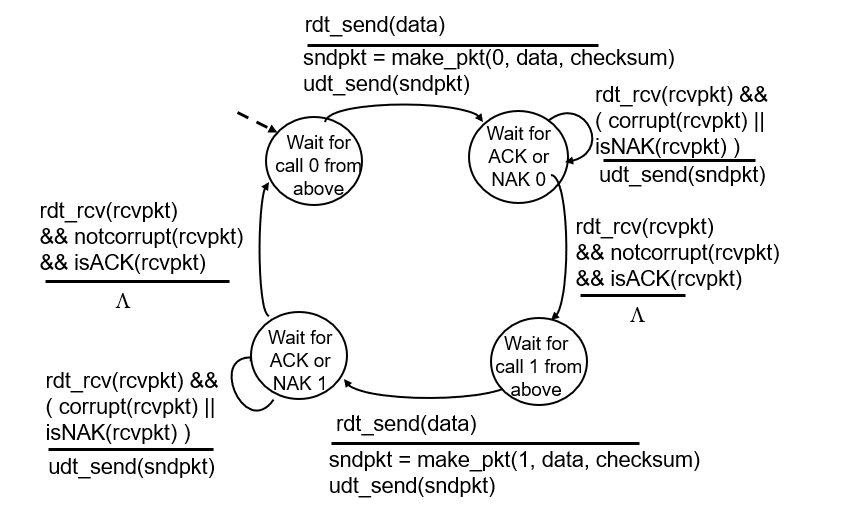
넘버 0,1을 붙이는게 rdt 2.1 버전이다.
- Error detection
- Feed back
- Sequence Number
를 가지고 unreliable을 극복하는 과정이다.
그러다 개발자가 고민을 한다.
NAK 없이 못만드나?
-> 마지막 받은 SequenceNumber를 같이 보낸다.
0을 보내서 return으로 0을 받아야 하는데, 1을 받는다면 데이터 반환에 오류가 있는것이다.
그래서 NAK를 안쓰는게 rdt 2.2이다.
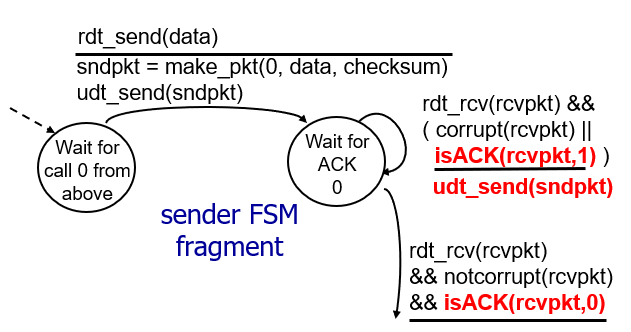
이제 rdt 3.0을 살펴볼 차례이다.
만약 데이터를 보냈는데 중간에 유실되어서 못받는다고 생각해 보자.
그래서 생각한 것이
데이터를 보내놓고 일정시간 데이터가 오지 않으면 액션을 취한다.
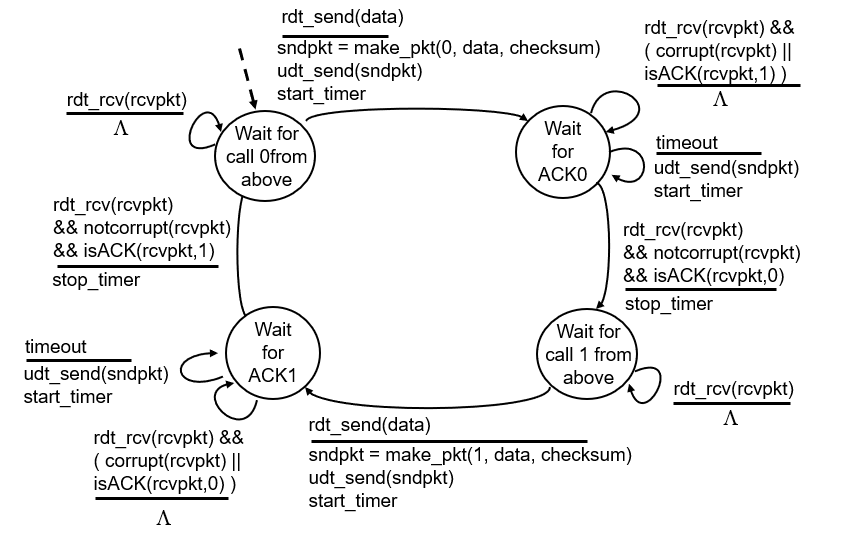
이때 타이머를 설정하는데, 그 시간 수업 진행하면서 설명해주신다고 한다.
2.2버전을 보고 생각한 의문증이었는데 바로 해결이 되었다.
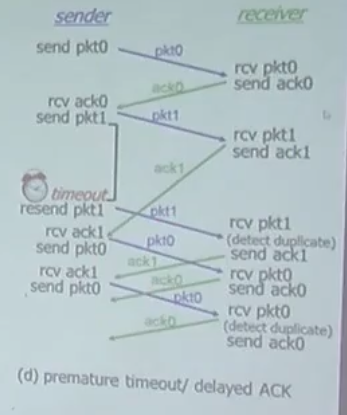
하지만, 이러한 방식은 결국 딜레이가 발생했을때 오버헤드가 발생하고만다..
이제 rdt를 알아봤다.
TCP에서 데이터를 보낼때 rdt를 제공하지만 다른 형식으로 제공할 것이다.
왜냐하면 패킷 하나당 보내고 확인하는 절차를 거치면 너무나도 느릴것이기 때문이다.
그래서 교수님 설명으로는 '데이터를 붓는다' 라고 한다.
Connection Oriented Transport : TCP
중요한 개념을 적어보자.
- point to point : 한쌍의 소켓에 관련되어있다.
- reliable, in-order byte stream : 믿을수 있고, 순차적으로 보낸다
- pipelined : 많이 보낼수 있음
- full duplex data : 양 포인트가 sender, receiver임. 둘다 보낼수있고 받을수있음
- connection-oriented :
- flow controlled : 상대방 machine의 속도에 맞게 데이터를 보냄
이중 flow controlle이 정말 신기했는데 상대 컴퓨터의 처리량에 따라서 데이터를 보내는 양을 다르게 한다는 것이다.
슈퍼컴퓨터면 많이보내고 네트워크가 안좋으면 적게 보내고 등등
TCP 구조

- source port : 보내느사람 포트
- dest port : 받는사람 포트
- Sequence Number : 세그먼트 순서를 나타내는거
- Acknowledgement Number : 수신측이 다음으로 기대하는 바이트 위치
- Flag : 세그먼트 제어 정보
- Window : 송신측이 수신할 수 있는 데이터 크기
- Checksum : 오류
- URG pointer : 긴급 데이터의 끝이라고 함(잘 모르겠음
- Option : 추가정보
- 이후 패딩
Sequence Number vs Acknowledge Number
데이터를 보낼때, 현재 세그먼트 데이터의 번호
- 첫번째 데이터 : 100개 -> 세그먼트 = 0
- 두번째 데이터 : 100개 -> 세그먼트 = 100
- 세번째... -> 200
데이터의 번호를 나타내는것.
하지만 Acknowledge는 받기를 희망하는 데이터 number이다.
- 첫번째 데이터 : 100개 -> 세그먼트 = 100
- 두번째 데이터 : 100개 -> 세그먼트 = 200
- 세번째... -> 300
이 번호의 데이터를 달라고 요청하는 것이다.
TCP timeout value check
샘플 RTT(데이터 보내고 받는게 얼마나 걸리는지 측정)를 측정
만약 피드백을 보낼때(데이터 수신을 못함. 느리던지 오류났던지) 측정이 재대로 안되는데,
이때 재전송한 데이터는 RTT에 포함하지 않음.
실제로 TCP 연결된 소켓의 RTT를 측정했을때 값이 엄청나게 튀는걸 확인할 수 있다.
같은 라우터를 따라가더라도 시간대별로 딜레이가 달라질수 있음.
그래서 공식을 하나 세우고 다음과 같다.
Estimated RTT = (1-a)EstimatedRTT + aSampleRTT
이 식은 가중치에 따라ㅣ서 현제 RTT와 Sample RTT의 반영 비율이 달라진다.
이때 일반적인 가중치(a)는 0.125이다.
Timeout Interval = EsitimatedRTT + 4*DevRTT(safty margin)
그래서 timeout은 margine의 4배를 더한다.
TCP rdt
위의 rdt와는 다르다. 엄밀하게 말하면 데이터를보내고 그에 대한 return값을 기준으로 데이터가 잘 전송되었는지 확인하는건같지만, 그렇게 했다가는 속도가 너무 느리기 때문에 데이터를 왕창 보내는것을 목표로 한다.
아래는 내가 이해한 대로 그림을 그려서 설명해보겠다.
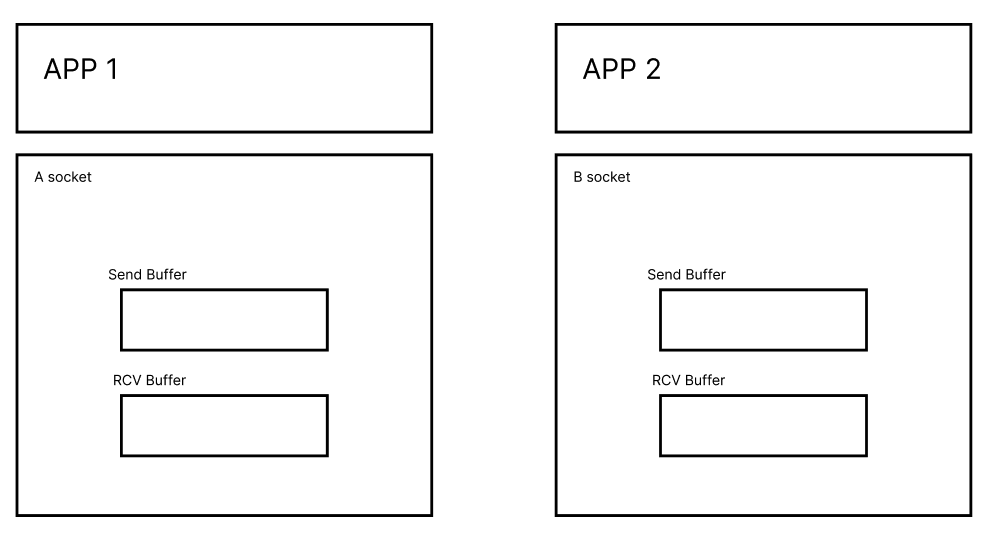
먼저, App 1에서 App2로 데이터를 보내고 싶다고 생각해 보자.
그럼 소켓을 생성하는데, 이때 send, rcv 버퍼가 생긴다.
(그림에는 안그렸지만 Timer도 같이 들어가있다.)
그 이유는 APP -> Socket, Socket -> Socket의 속도가 다르기 때문이다.
한꺼번에 많은양의 데이터를 보낼것이기 때문에 버퍼에 쌓아두면서 처리해야 한다.
그렇지 않다면 App에서 데이터가 나가는 속도와 통신할때의 속도 차이에 의한 병목현상이 발생할 것이다.
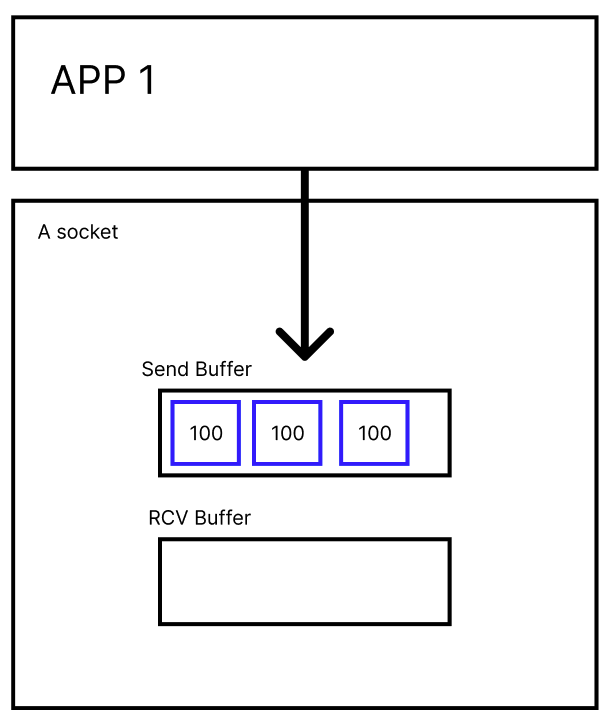
버퍼를 만들고, APP에서 버퍼에 데이터를 내려서 쌓는다.
각 데이터 패킷을 100개라고 설정해 보자.
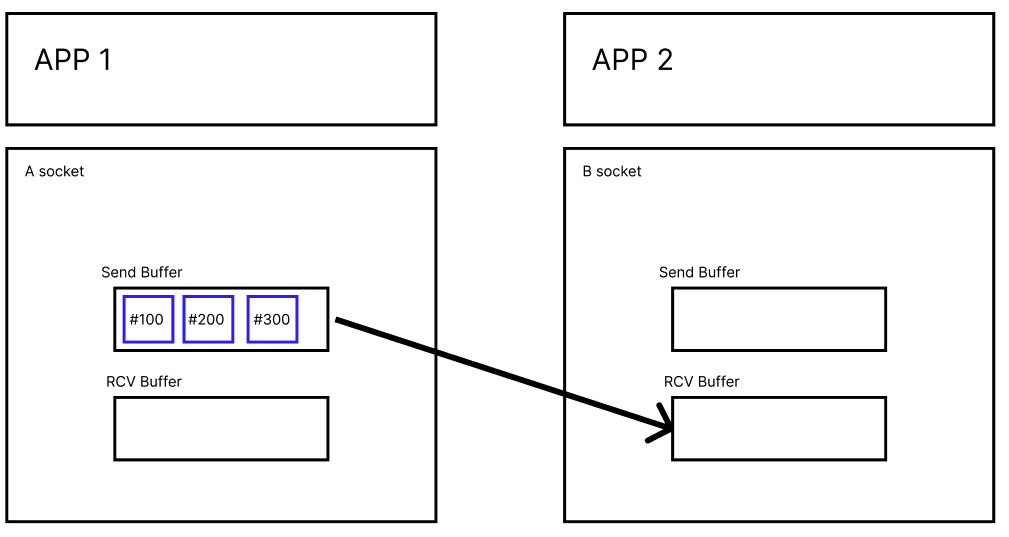
이후 A Socket에서 B Socket으로 데이터를 보낸다.
이때 보내는 양은 RCV Buffer의 Window 크기(버퍼 크기)에 맞게 보낸다.
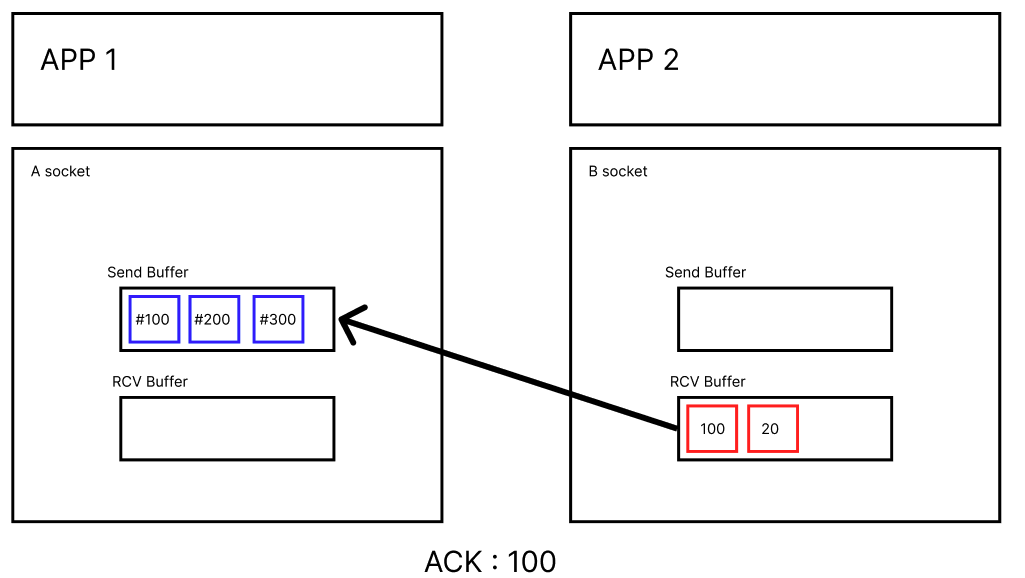
APP2가 데이터를 100까지 잘 받았다고 하면, ACK를 100이라고 보내준다.
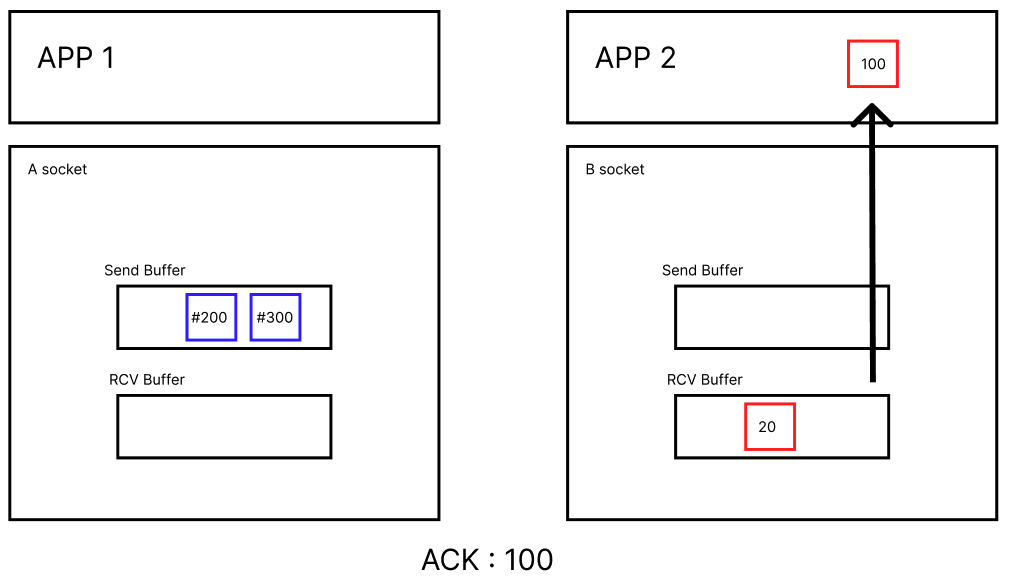
A 소켓은 100까지 잘 받았으니 버퍼에서 #100을 지우고, B Socket은 잘 받은 데이터를 APP으로 올린다.
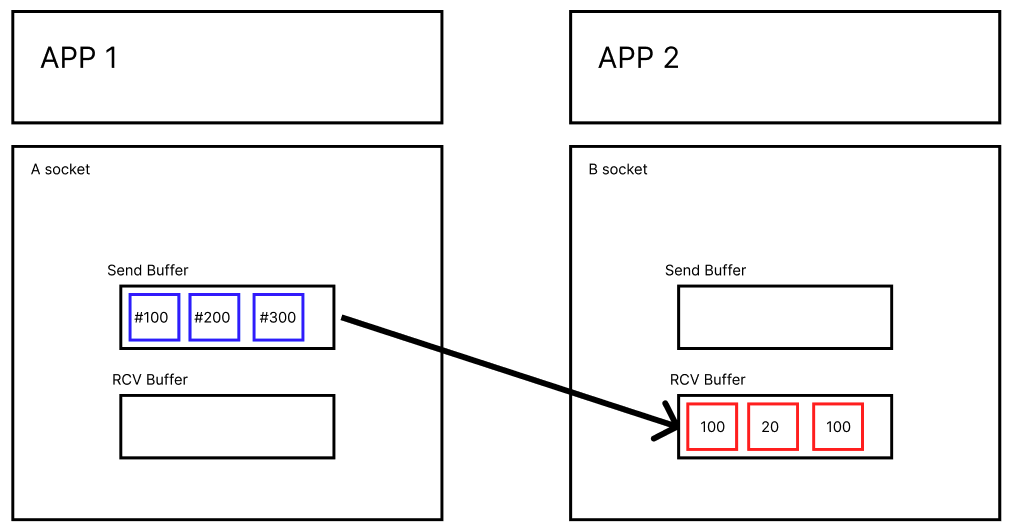
하지만 이때, #100, #300 데이터는 잘 들어왔는데 # 200 데이터가 덜 들어오면 어떻게 될까?
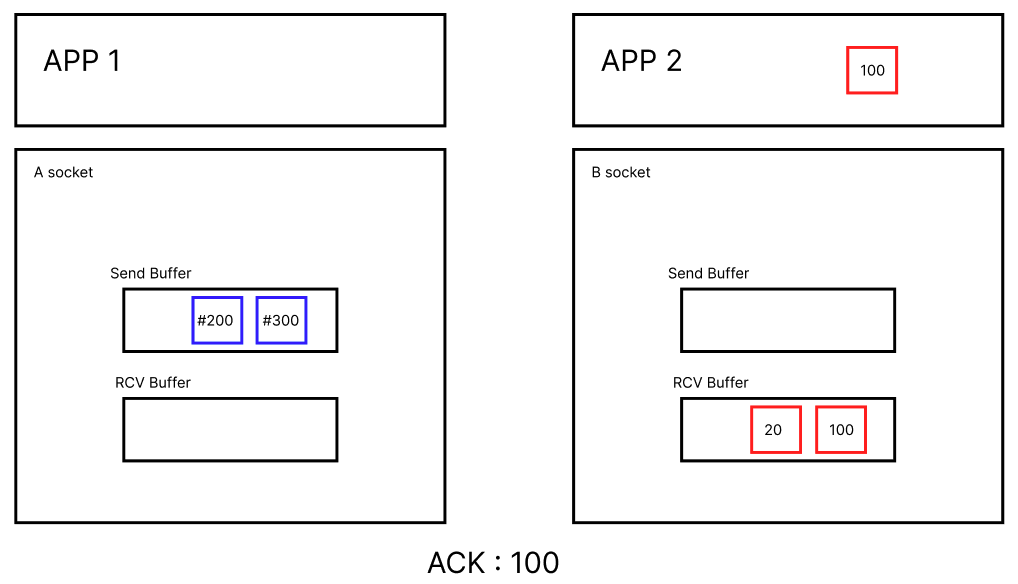
ACK는 100이 리턴되기 때문에 뒤의 데이터는 버퍼에 그대로 남아있다.
왜냐? TCP는 순차적인 데이터 return을 하기 때문이다.
이 설명을 들었다면 위의 Sequence number, acknowledge number의 설명이 이해가 될 것이다.
- Sequence Number는 데이터의 번호이고
- Acknowledge Number는 어디까지 받았다고 리턴하는 번호이다.
- 두개가 같이 있는 이유는 하나의 헤더에 데이터를 담아서 send, return 하기 때문이다.
그럼 들어오지 못한 데이터는 어떻게 하나?
-> timer 안에 return이 되지 않기 때문에 loss라고 판단, 재전송한다.
그런데 데이터의 손실을 좀 빠르게 판단할 수는 없나?
-> 같은 ACK Number를 3번 받으면 데이터 Loss라고 판단을 한다.
이거 꽤 중요하다.
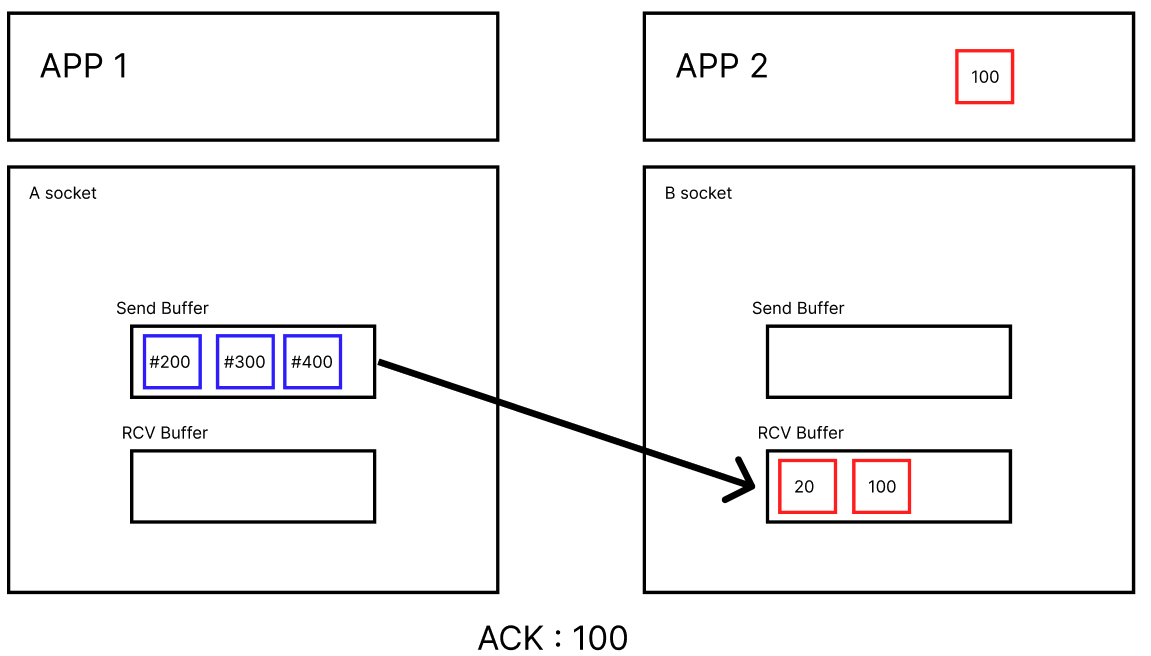
그리고 데이터의 수신이 파악되면, Window가 비어있기 때문에(RCV 버퍼에 여유가 있음)
남는 Window의 크기에 맞는 데이터를 추가로 보내준다.
요약을 하자면
- TCP Socket마다 Send/RCV버퍼가 생긴다
- Window Size 만큼 데이터를 한번에 보낸다.
- 데이터를 보내면서도 RCV를 통해 데이터 받는다.
- ACK를 통해 데이터 전송을 추적한다.
- timeout, 같은 sequence number 3회 중복일때 에러라 판단하고 재전송한다.
- 다 보낸것이 확실한 데이터는 Send Buffer에서 지운다.
- 다 받았다고 확실한 데이터는 RCV에서 APP으로 데이터를 올린다.
- 순서대로 데이터를 RCV에서 APP으로 올려야 한다. 뒷 데이터가 먼저 들어와도 버퍼에 남아있는다.
Flow Control
모든 데이터 권한은 APP에서 관리한다. TCP는 단순히 프로토콜일 뿐이다.
만약 데이터를 받는 APP에서 RCV 데이터를 받아들이는게 너무 느리다면?
그런데도 데이터를 계속 보낸다면?
RCV 버퍼가 넘쳐서 데이터 유실이 발생할 것이다.
하지만 RCV에 얼마나 남아있는지 데이터를 받는 APP이 알고 있기 때문에,
Receive Window 헤더에 데이터를 담아서 보낸다.
즉, Send 버퍼는 Receive Window에 의존적이다.
정말 중요한 내용이지만, 짧게 끝이 난다.
왜냐하면 Receive Window로 확실하게 컨트롤 할 수 있어
추가적인 설명이 필요없기 때문이다.
코너 케이스
만약 RCV가 꽉 찼음에도 불구하고 APP 영역에서 데이터를 가져가지 않는다면?
Window Size가 0이라고 return 되어버리면?
데이터를 보낼수도 없고(Window가 없음), RCV가 비었는지 확인할 수도 없다.
데드락 상태에 빠져버린 것이다.
그래서 세그먼트에 데이터 단 하나(1byte)만을 담아서 일정 시간마다 보낸다.
그러면 RCV에 공간이 비었을때 Send 버퍼에서 데이터를 보낼 수 있고,
이를 통해 데드락을 해결할 수 있다.
Segment Size
2줄로 설명하자면
- App에서 데이터 내려보내는 속도가 빠르다면 Segment 크기를 늘리고
- 인터넷 속도가 빠르면 Segment 크기를 줄인다.
세그먼트 크기를 줄이면 헤더가 많이 발생하기 때문에 오버헤드가 발생하게 된다.
하지만 그럼에도 불구하고 인터넷이 빠르기 때문에 어느정도의 오버헤드를 감수한다는 것이고,
인터넷의 속도가 느리다면 한번에 많은 데이터를 보내서 오버헤드를 줄이고자 하는 것이다.
RCV Window Return
만약 RCV에서 아주 작은 메모리가 남았다면(예를 들어서 10byte) 그냥 남는 window를 0으로 return한다는 것이다.
너무 작은 Segment를 계속 보내기 위해서 Send쪽에서 오버헤드를 감수하지 않아도 된다는 것이다.
그리고 RCV가 데이터를 받았을때 약간의 딜레이를 준다.
그러면 여러번 return을 보내는 것이 아닌, 데이터가 들어온걸 확인하고
훨씬 적은 return을 보내도 같은 기능을 할 수 있다.
Handshake
3-way handshake
TCP 연결을 하기위한 handshake이다.
-
Client가 Server에 TCP-Connection을 만들자고 보내는것이 TCP SYN 메시지이다. 이때 헤더만 전송한다. 그리고 Flag에 SYN 플래그가 1로 설정된다.
-
서버는 SYN - ACK을 Client로 전송한다. 이때 ACK Field를 +1 해서 보내준다.
SYN 보내고 ACK 따로 보내는게 아니다! -
Client는 서버로 SYNACK를 return하는데, 받은 ACK에 +1을 해서 보낸다.
그리고 마지막 ACK에 HTTP 리퀘스트를 보낼 수 있다 라고 교수님께서 설명을 해주시는데
이것은 TCP Fast Open 이라는 기술이다.
레퍼런스 : https://en.wikipedia.org/wiki/TCP_Fast_Open
하지만 보안상 폐기가 되었다고..
4-way handshake
TCP 연결을 종료하기 위한 handshake이다.
-
Socket Close를 하면, Client가 서버로 FIN을 보낸다.
-
서버는 ACK를 반환하고 Socket Close를 할때 자신이 보낼 데이터가 다 보내졌으면, FIN을 보낸다.
-
이후 Client는 서버로 ACK를 반환한다.
하지만 여기서 ACK가 소실된다면 어떻게 되는가?
Send 측은 데이터를 보내도 return이 안들어오고, RCV 측은 여유시간을 남기기 위해 Max*2 시간만큼 기다린다.
3-way, 4-way의 차이점
그건 중간에 Request + ACK를 같이 보내냐, 따로 보내냐의 차이이다.
3-way는 서로 보낼 데이터가 없으니 빨리 연결을 해야 함으로 같이 보내고
4-way는 한쪽에 잔여 데이터가 있을 수 있음으로 Request, ACk를 따로 보낸다.
TCP Congestion Control
어렸을적 게임을 다운받을때 처음 속도가 너무 느리고, 잘 다운받다가 갑자기 속도가 낮아져서 짜증이 났던 기억이 있다. 이번 강의도 이러한 TCP 통신의 속도에 관련된 내용이 나온다.
하나의 예시를 들어보자.
아파트에 통신망을 설치했다. 이 통신망에는 30층짜리 아파트 15동이 들어간다.
각 동에 4호수가 있다고 하면 단순계산으로 1800가구가 사는 아파트 단지가 완성된다.
이때, 이 모든 가구가 1GB의 데이터를 한번에 보낸다면 어떻게 될까?
잘 알지는 못하지만 1800대의 디바이스가 각각 1GB씩 데이터 송신을 오쳥하게 되면 엄청난 병목현상이 발생할것으로 예상된다.
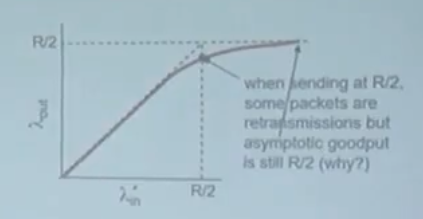
이 그림에서 R은 라우터가 감당가능한 통신의 양이다.
여기서 TCP의 특징을 리마인드 해 보자.
TCP는 안전한 데이터 통신을 목적으로 하기에 데이터가 들어오지 않으면 재요청을 보낸다.
이것은 RCV쪽이 데이터를 반환했는지에 관계가 없다.
따라서, 병목이 발생해서 통신이 막혔는데, 병목이 됐기 때문에 통신양이 늘어난다는 것이다.
그래서 통신에서 데이터를 송신하는 크기는 민감하고, 예민하게 접근할 수 밖에 없다.
네트워크는 공공제이다. 내가 빨리 쓰고싶다고 데이터를 막 쏴버린다면
나 뿐만 아니라 네트워크 전체에 큰 문제가 발생한다는 것이다.

그래서 데이터 전송은 위의 그래프와 같은 변동이 발생한다.
데이터를 계속 쏘다가 병목이 생기면 데이터 전송을 반으로 줄여버린다.(Loss가 발생했다)
이를 multiplicative decrease라고 한다.
그럼 처음 송신하는 데이터의 크기는 얼마나 될까?
-> 1MSS(세그먼트 한개)이다.
처음은 천천히 시작한다고 해서 Slow Start라고 한다.
그리고 RTT 마다 2배로 증가한다.
하지만 계속 2배로 증가할 수 없기 때문에, 일정 이상 넘어가게 되면 Linear하게 증가한다.
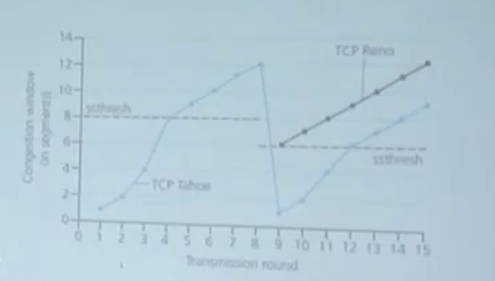
가로선이 슬로우 스타트가 끝나는 지점이고, 그 뒤로는 Linear 하게 진행된다.(Congestion Avoidance)
여기서 하나 짚고 넘어갈 부분이 있다.
위에서 데이터를 계속 쏘다가 병목이 생기면 데이터 전송을 반으로 줄여버린다라고 했는데
거기에 조금 더 설명을 붙여야 한다.
레퍼런스 : https://en.wikipedia.org/wiki/TCP_congestion_control

(강의에서 설명하였지만 부연설명을 위한 레퍼런스)
데이터 로스가 발생했을때 처리하는 2가지 알고리즘이다.
첫번째인 타호는
그냥 얄짤없이 1부터 다시 시작한다. 대신 ssthresh를 병목이 발생한 지점의 절반으로 설정한다.
두번째인 르노는
1부터 시작하는 것이 아닌, ssthresh에서 부터 선형적으로 증가한다.
슬로우 스타트를 다시 하는것이 불필요한 오버헤드라고 판단했기 때문이다.
UDP?
TCP는 속도를 인터넷 환경이 결정한다.
즉, 사람들이 얼마나 네트워크를 사용하고 있는지가 중요하다는 것이다.
그렇다면 UDP는 어떻게 될까?
UDP는 최대한 빨리 전송하는것을 목적으로 하고 있기 때문에
위와 같은 데이터 전송 속도 조절 메커니즘이 없다.
그 이유는 TCP는 네트워크 환경에 영향을 받지만, UDP는 APP에서 조절하기 때문이다.
따라서, UDP로 많은 사람들이 많은 데이터를 보낸다면 문제가 심각해질 것이다..
교수님의 말씀으로는 무법자 라고 한다.
TCP Fairness
하나 궁금증이 생긴다.
모든 사용자가 공평하게 속도를 가질 수 있을까?
결론만 말하자면 그렇다.
어떤 수 A, B를 생각해 보자.
이 수들에 1씩 더하면서, 한 수가 C에 도달하면 *0.5를 한다고 가정해 보자.
그렇게 계속 진행 하였을때, A, B는 C/2 ~ C 사이를 맴돌게 되는데, 한없이 비슷한 수가 될 것이다.
간단하게 사고실험을 통해 알 수 있다.
개념적인 부분을 듣고 정리한 것이다.
