
레퍼런스 : http://www.kocw.net/home/cview.do?cid=6b984f376cfb8f70

저작권 법에 따라 출처 공개, 영리목적 사용금지, 내용을 의도적으로 바꾸지 않습니다.
이전강의는 APP 계층 + TR 계층 까지 관점을 넓혀보았다.
소켓으로 데이터를 보낸다 -> TCP/UDP 등의 방법을 통해 세그먼트에 데이터를 담아서 보낸다
이제 Network 계층까지 관점을 넓혀보자.
Network Layer
이번 주제에서의 논점은 Segment가 어떻게 전송되는지에 대해 알아보자.
라우터들은 각각 네트워크 계층을 가지고 있고(App, Tr 계층이 없음), 라우팅을 통해 데이터를 전달한다.
Router
2가지 중요한 기능이 있다.
- 포워딩
- 라우팅
포워딩
알맞은 방향으로 데이터를 전달해 주는것.
포워딩 테이블이라는 것이 있고, 목적지와매칭이 되는 엔트리 쪽으로 데이터를 보낸다.
라우팅
포워딩 테이블을 채우는 역할.
Network Layer Service Model
라우터의 서비스 모델 중 하나인 Best Effort는 패킷 로스를 신경쓰지 않는다.
최선을 다해서 라우팅을 할 뿐이다.
그리고 포워딩 테이블은 주소의 Range를 받는다.
A~B 까지는 0번
C~D 까지는 1번..
이런식으로.

이러다가 많이 매칭되는 주소가 여러개 생길 수 있는데, 가장 많이 매칭되는 곳으로 연결된다고 한다.
아래 예를 보자.
11001000 00010111 00010110 10100001
-> 0번과 가장 많이 매칭됨으로 0번으로 라우팅한다.
11001000 00010111 00011000 10101010
-> 1번과 가장 많이 매칭됨으로 1번으로 라우팅한다.
라우터 내부 구조화
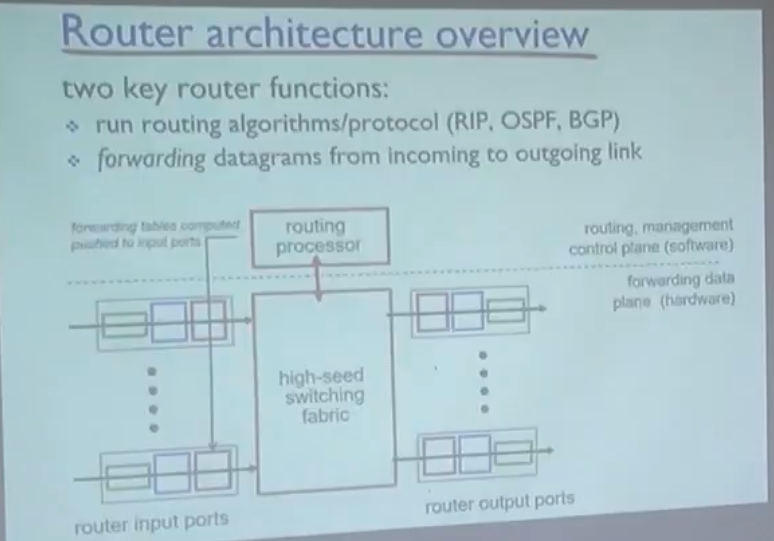
데이터가 들어오고 나가는 것을 프로세스에 맞게 보내는 역할을 한다.

포워딩 테이블은 각 Input Port에 저장된다.
A, B, C.. 등등 에서 들어오는 데이터는 각각 Port에 따라 독립적으로 돌아간다.
처리 속도보다 input 속도가 빠를 수 있음으로 Que를 가진다.
마찬가지로 Output Port에도 Que를 가진다.
IP 프로토콜
현대 인터넷 네트워크는 IP 패킷 형태로 포멧(잘 안들림)이 되어 있어야 목적지까지 도달된다.
왜냐면 라우터들이 IP만 이해할 수 있기 때문이다.
패킷은 세그먼트를 데이터로 받고, 헤더를 추가로 붙여서 사용한다.

IP 데이터그램 포멧
- Ver = 버전이다. 현재 IPv4
- head len = 헤더 길이
- type of service = 데이터 타입
- time to live = 오류로 인해 루프를 돌지 않도록 몇개의 라우터를 통과할 수 있는지 카운트를 잡음
- upper layer = 상위 레이어(TCP/UDP 등등 데이터가 뭔지)
- length = 전체 길이
- 16-bit-identifier, flag, fragment offset = 설명x(이후 나오는 내용이라고 함)
그리고 데이터 패킷을 뜯어보면 무시할 수 없는 수준의 패킷이 40Byte의 크기를 가지고 있다.
=> 이건 TCP 기반 연결에서 데이터 수신중이라는 반환값을 계속 보내기 때문.(데이터 없이 헤더만)
IP Address(IPv4)
고유의 32비트 숫자이며 인터페이스로서 식별된다.(host, router 등등)
IP 주소 배정
Host를 Grouping 해서 해결한다.

무작위로 배정한다고 해 보자.
그러면 무분별한 숫자 할당으로 인해서 숫자가 겹치더라도 방향이 다 달라진다.(호스팅하는 라우터가 다르다.)
그러면 포워딩 테이블이 어엄청나게 길어지게 된다.

그래서 Network, Host 로 나누게 된다.

이 경우, 위처럼 특정 패턴은 특정한 방향으로 라우팅 해주면 되는 것이다.

그래서 서브넷 마스크라는 것이 나온다.
주소와 mask를 and 연산을 때려버리면 Address의 네트워크 주소값만 나오기 때문에
이를 컴퓨터가 이해하기 쉬운 자료를 가지게 된다.
하지만 이 서브넷 마스크는 고정된 값이 아니다.
예전에는 Class 별로 서브넷 마스크 크기가 고정되었지만,
현재는 각 기관의 요구 host 크기에 맞게 가변해서 쓴다.
Network 16bit, Host 16bit 이런식으로 쓸 수도 있다는 뜻이다.
Subnet

위에서 라우트는 각 포트마다 독립적으로 돌아간다고 했다.
이 말을 더 자세하게 적자면
라우터는 포트마다 개별적인 서브넷을 가진다.
위 그림을 보면 서브넷이 3개가 있고, 각자 각각의 서브넷을 가지게 된다.
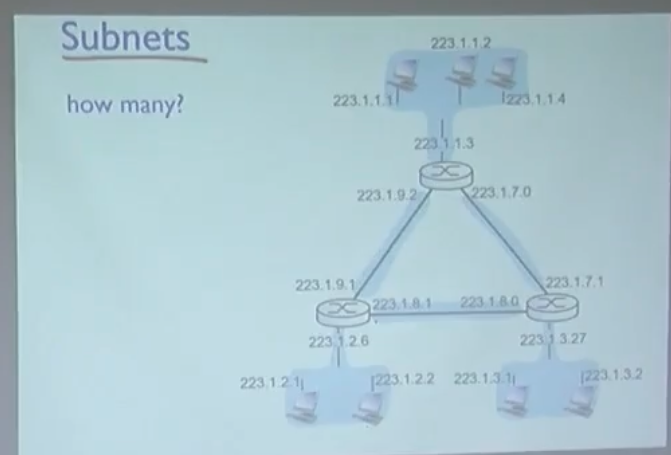
이 그림을 보면 더 자세하게 알 수 있는데,
서브넷이 Client 3개 + 라우터 사이 3개 = 총 6개이다.
IPv6??
IPv4의 용량 한계를 위험하게 바라본 사람들이 IPv6을 만들었다.
IPv6은 2^128개, 바닷가의 모래알 개수보다 많은 IP 주소를 가지게 되었다.
하지만 아직까지도 IPv4를 가지고 있다. 왜그럴까?
- IPv4만을 이해하는 라우터 인프라를 많이 깔아놨기 때문에, 버전을 바꾸는거 자체가
전부다 오버헤드가 되는 것이다.
- 안바꿔도 잘 작동한다. 임시방편 쓰니까 잘 되더라(NAT)
Network Address Translation

WAN에서 LAN으로 데이터가 들어올때, NAT에서 주소 변환을 시킨다.
이때, 모든 LAN은 네트워크 주소가 같지만, 포트번호만 다르다.
NAT는 이 포트번호로 내부 Device의 IP를 할당해 준다.
이때, LAN의 IP주소는 외부에 겹칠수 있겠지만, 내부에서만 사용하기 때문에 사용이 가능한 것이다.
하지만 여기에는 문제가 발생한다.
서버를 LAN에 연다고 생각해 보자.
그럼 서버는 NAT에서 할당받은 IP를 가지고 있을것인데, 외부 접속망에서 이 IP주소를 입력한다고 해도
절대 접속할 수 없다.
그래서 NAT 관리하는 전산실에 매핑되는 WAN IP주소를 찾아서 불러달라고 하거나,
홀펀칭(Hole Punching)이라는 기법을 써야 한다. 설명은 안하심.
홀펀칭은 중간 서버를 만들어서 자동으로 IP를 변환해야 하는것을 의미한다.
그리고 이러한 NAT 기법은 네트워크 구조를 좋지 못하게 망치는 방법이다.
왜냐? 기껏 계층화 시켜놓은걸 NAT가 도입됨에 따라 헤더를 고쳐야 한다.
End - to - End 방식에서 중간에 다른 존재가 패킷을 뜯어본다는게 말이 안되기 때문이다.
Dynamic Host Configuration Protocol
간단히 말해서, 동적으로 IP를 할당해주는 DHCP 서버가 관리하는 시스템이다.
동적 할당은 4단계로 이루어진다.
- Client가 IP 주소가 필요하다고 LAN에 브로드캐스트 한다. 이때 src IP주손,ㄴ 0.0.0.0으로 보낸다.(할당 못받음)
- DHCP 서버는 특정 IP주소를 할당해서 IP주소와 Limit 시간값을 return 한다.
- 이때 여러 DHCP 서버에서 Return 할 수 있기 때문에, 사용하고자 하는 DHCP 서버에 Request를 보낸다.
- DHCP가 ACK를 보내고, 수신하면 통신이 시작된다.
IP Fragment Offset
헤더에서 설명안한 그 부분이다.
라우터는 고유의 MTU(Max Transfer Size)가 있다.
그런데 Host에서 MTU를 초과하는 데이터를 보내게 되면 전송이 불가능하다.
따라서 이 데이터를 여러개로 나눠서 전송하게 된다.

데이터를 나눠서 보내고, Offset은 데이터 크기를 8로 나눠서 넣어준다.(최적화)
Dijsktra's Algorithm
알고리즘은 공부하지 않습니다!
이전에 한번 알아본 알고리즘이기도 하고, 지금은 네트워크 강의에 집중하기 위해서
알고리즘에 대한 정리는 하지 않습니다.

(잡음이 너무 심해서 강의를 들을수가 없다..)
라우터에서 경로를 찾는데 쓰는 다익스트라 알고리즘의 수도코드이다.
Distance Vector Algorithm
Bellman-Ford 알고리즘이다.
이전에 공부했을때의 기억을 떠올려보면, 벨만-포드는 가중치가 음의 수가 있어도 구할 수 있는 알고리즘이다.
여기에서 내가 공부할때 생겼던 의문이 한번에 해결 된다.
왜 벨만포드는 2차원으로 만들어서 모든 간선을 다 확인할까?
그 이유는 다익스트라/벨만포드를 사용하기 위한 상황의 차이에서 발생한다.
다익스트라를 사용할때는 모든 라우터가 서로 얼마의 비용이 발생하는지 알고 있다.
하지만 벨만포드를 사용할때는 자신과 연결된 라우터 까지의 비용밖에 알지 못하고,
이 정보를 주변 라우터를 통해 '전파'하는 상황이 발생한다.
따라서, A개의 노드가 A번 전파하니 각각의 데이터가 모이게 되면
A * A 2차원 테이블이 만들어지는 것이다.

주의점
이 알고리즘을 사용할때 전파가 느려서 정보 불균형으로 인한 예외 케이스가 발생할 수 있다.
따라서 데이터를 전달할때, 자신에게 직접 연결되어있는 노드를 제외하면 '무한'으로 전파하면 된다.
역류를 방지한다고 보면 된다.
그 이유는 뭘까?
각 라우터마다 자신만의 테이블이 있기 때문에 그렇다.
상대방이 알지 못하는 정보가 있을 수 있기 때문에
아예 모른다고 가정하고 전파하는 것이다.
Autonomous Systems
자치(자율) 시스템이라고 한다.
이런 이름이 붙은 이유는 시스템의 운영자가 자율적으로 정책을 설정하기 때문이다.
말 그대로 하나의 독립적인 시스템인 것이다.
모든 AS는 같은 체급을 가지고 있는게 아니다.
개인이 독자적인 AS를 설정할 수도 있고(어렵겠지만), 대기업에서 제공하는 AS도 있다.
대표적인 예가 통신사, 기관의 독자적 시스템 등이 있다.
그래서 AS의 사용은 돈이 관련되어 있을 수 있다.
서비스를 제공하는 AS는 돈을 대가로 서비스를 제공한다.
클라이언트는 서비스를 대가로 돈을 지불한다.
집에서 인터넷 연결할때 통신사에 전화해서 연결하는것과 같은 현상이다.
Peering
하지만 같은 통신사 급 되는, 체급이 비슷한 관계에서 서비스를 서로 제공받고자 한다면
돈을 지불하는것이 서로에게 부담이 될 수 있다.
지금은 내가 돈을 더 많이 달라고 해도, 언제 상황이 변할지 모른다.
그래서 Peering이라는 관계를 맺게 되는데, 이는 두 AS가 동등한 관계일때
서로 요금을 지불받지 않고 서비스를 제공하는 관계이다.
하지만 이 모든건 추측만 할 뿐, 비공개 이다.
BGP
AS의 끝단 게이트웨이에서만 적용된다.
AS의 Prefix가 ~~입니다 하고 다른 AS에 전파하는 것이다.
왜냐하면 그래야 다른 AS도 상대의 Prefix를 알게 되고, 주소를 알아야 라우팅이 가능하기 때문이다.
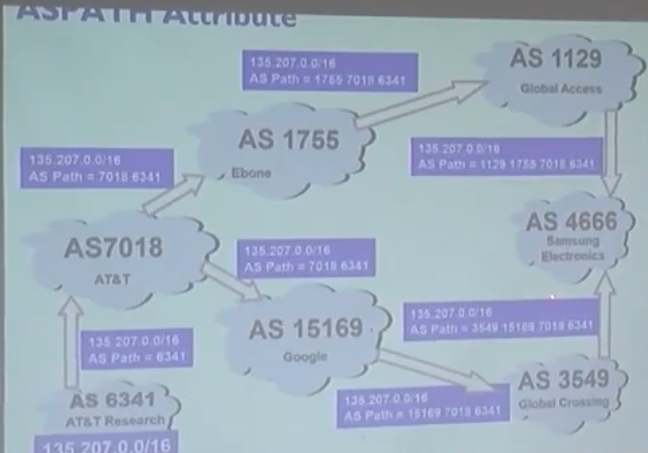
전파되는 도중 경로도 같이 전파되기 때문에, 특정 경로를 거치기 싫다면
제외하는것도 가능하다.
교수님도 설명은 개념만 이해하고, 그 이상은 설명해주지 않으신다.
preference?
선호도에 관한 이야기인데..
데이터 패킷을 전송할때 꼭 최단경로만을 선택하는건 아니라고 한다.
어디까지나 인터넷 통신사의 손을 거치기 때문에 느리더라도 이득이 나는 방향으로 라우팅이 가능하다고..
