
이번 포스팅은 k8s Monitoring 과 Logging에 대한 내용이다. 본 포스팅은 PKOS 스터디에서 '24단계 실습으로 정복하는 쿠버네티스' 책과 함께 진행되는 내용임을 밝힌다.
(이전 포스팅들과 마찬가지로, aws configure를 통해 cli에서 administer 권한이 있는 access key가 등록되어 있음을 가정한다.)
1. Preparation
kops 설치 (parameter는 각자의 환경에 맞는 값을 세팅한다.)
1. Preparation
kops 설치 (parameter는 각자의 환경에 맞는 값을 세팅한다.)
# YAML 파일 다운로드
curl -O https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/kops-oneclick-f1.yaml
# CloudFormation 스택 배포 : 노드 인스턴스 타입 변경 - MasterNodeInstanceType=t3.medium WorkerNodeInstanceType=c5d.large
aws cloudformation deploy --template-file kops-oneclick-f1.yaml --stack-name mykops --parameter-overrides KeyName=kp-gasida SgIngressSshCidr=$(curl -s ipinfo.io/ip)/32 MyIamUserAccessKeyID=AKIA5... MyIamUserSecretAccessKey='CVNa2...' ClusterBaseName='gasida.link' S3StateStore='gasida-k8s-s3' MasterNodeInstanceType=c5a.2xlarge WorkerNodeInstanceType=c5a.2xlarge --region ap-northeast-2
# CloudFormation 스택 배포 완료 후 kOps EC2 IP 출력
aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text
# 13분 후 작업 SSH 접속
ssh -i ~/.ssh/kp-gasida.pem ec2-user@$(aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text)
# EC2 instance profiles 에 IAM Policy 추가(attach) : 처음 입력 시 적용이 잘 안될 경우 다시 한번 더 입력 하자! - IAM Role에서 새로고침 먼저 확인!
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name nodes.$KOPS_CLUSTER_NAME
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl top node위 yaml파일로 설치를 하면, docker가 기본적으로 탑재되어 있는 bastion이 설치가 된다. 가시다님에 제공해준 cf의 kops에는 metric-server add-on이 세팅되어 있다.
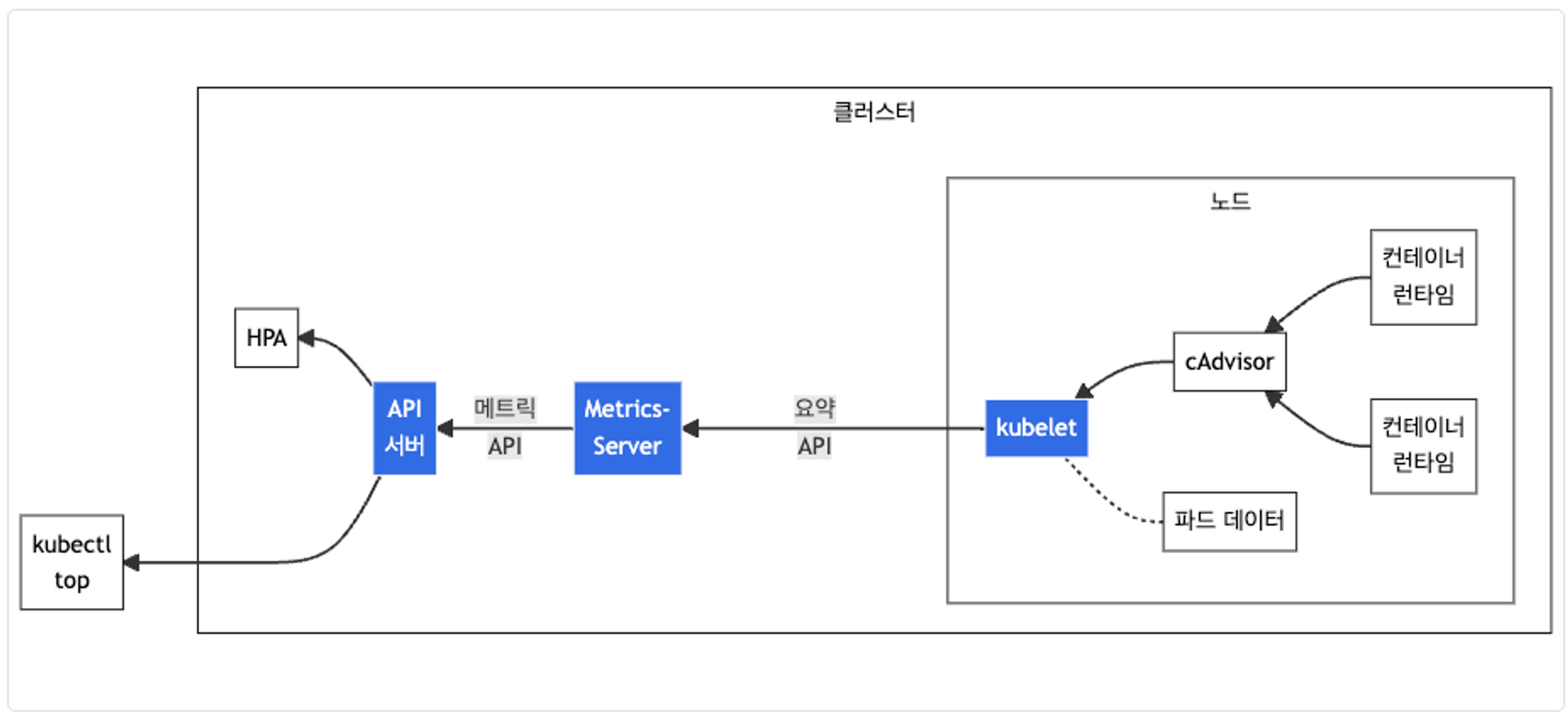 그림출처: https://kubernetes.io/ko/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/
그림출처: https://kubernetes.io/ko/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/
metric-server는 kubelet으로 부터 수집한 리소르 메트릭을 수집 및 집계하는 역할을 한다.
2. Prometheus
What is Prometheus?
Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud.
프로메테우스는 사운드클라우드에서 만든 모니터링 시스템이다. 가끔 사운드클라우드에서 음악을 듣긴하는데, 여기서 이걸 만든건 정말 신기하다.
프로메테우스는 k8s에 최적화된 모니터링 툴이라고 생각한다. 실습을 통해서 대체 뭘 하는 녀석인지 알아보도록 하자.
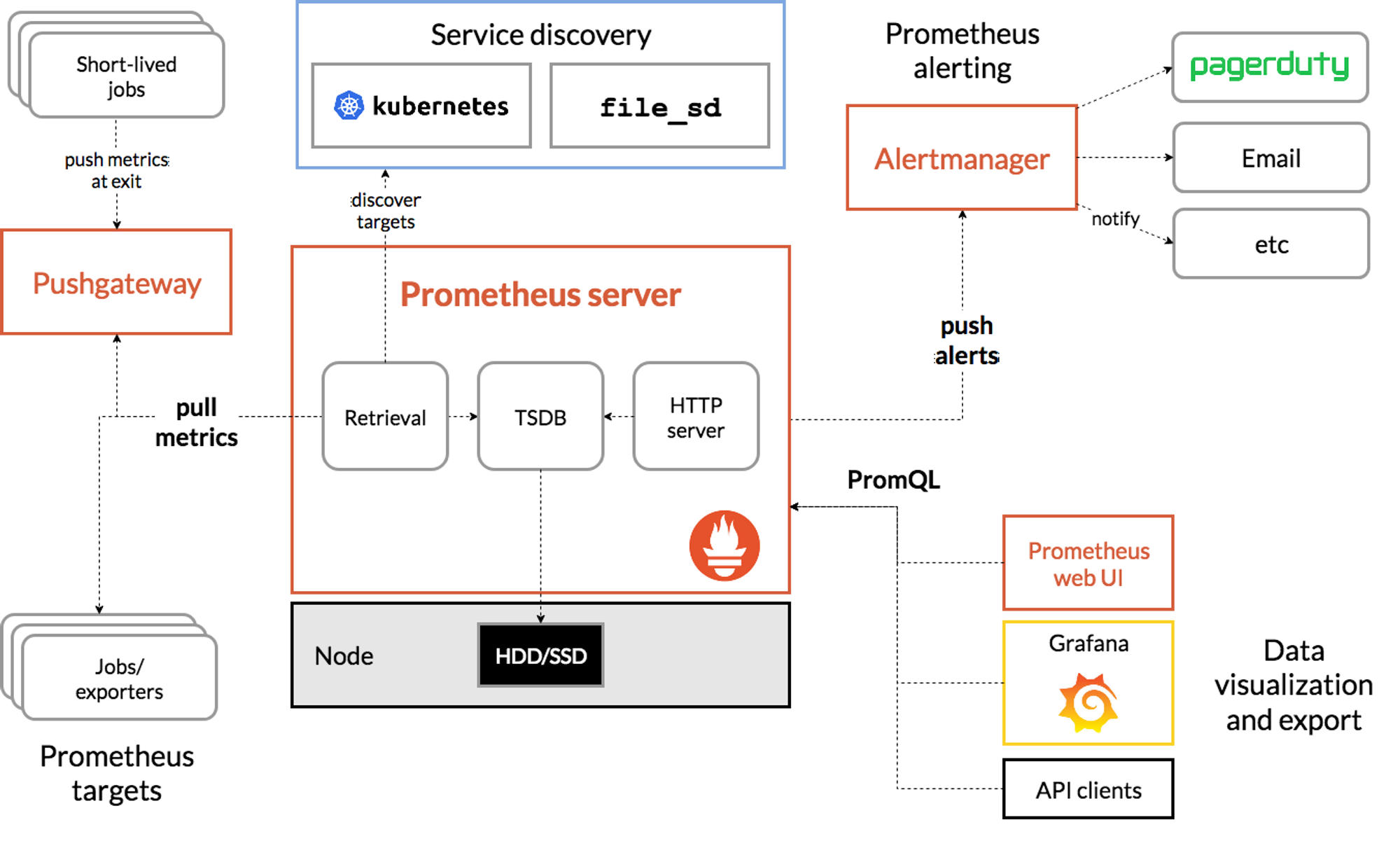 그림출처: https://prometheus.io/docs/introduction/overview/
그림출처: https://prometheus.io/docs/introduction/overview/
Features
- a multi-dimensional data model with time series data identified by metric name and key/value pairs
- PromQL, a flexible query language to leverage this dimensionality
- no reliance on distributed storage; single server nodes are autonomous
- time series collection happens via a pull model over HTTP
- pushing time series is supported via an intermediary gateway
- targets are discovered via service discovery or static configuration
- multiple modes of graphing and dashboarding support
2-1. Prometheus stack
Prometheus에서는 k8s에 설치를 쉽게하기 위해 kube-prometheus-stack을 제공한다. 몇가지 설정만 바꿔주면 helm chart로 바르게 설치가 가능하다.
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo "alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN"
# 설치
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.7.1 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get pod,svc,ingress -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,alertmanager -n monitoring
kubectl get prometheusrule -n monitoring
kubectl get servicemonitors -n monitoring
kubectl get crd | grep monitoring설치확인
(kimchigood:default) [root@kops-ec2 ~]# kubectl get pod,svc,ingress -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 1 (2m36s ago) 2m40s
pod/kube-prometheus-stack-grafana-5dc647679-nk6rf 3/3 Running 0 2m52s
pod/kube-prometheus-stack-kube-state-metrics-7c44b8c9c4-d89z9 1/1 Running 0 2m52s
pod/kube-prometheus-stack-operator-75b7b9747d-tgmlp 1/1 Running 0 2m52s
pod/kube-prometheus-stack-prometheus-node-exporter-472ph 1/1 Running 0 2m52s
pod/kube-prometheus-stack-prometheus-node-exporter-sbcc6 1/1 Running 0 2m52s
pod/kube-prometheus-stack-prometheus-node-exporter-w86nr 1/1 Running 0 2m52s
pod/prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 2m40s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 2m40s
service/kube-prometheus-stack-alertmanager ClusterIP 100.65.182.35 <none> 9093/TCP 2m52s
service/kube-prometheus-stack-grafana ClusterIP 100.69.114.115 <none> 80/TCP 2m52s
service/kube-prometheus-stack-kube-state-metrics ClusterIP 100.71.228.8 <none> 8080/TCP 2m52s
service/kube-prometheus-stack-operator ClusterIP 100.66.46.33 <none> 443/TCP 2m52s
service/kube-prometheus-stack-prometheus ClusterIP 100.71.186.24 <none> 9090/TCP 2m52s
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 100.65.249.133 <none> 9100/TCP 2m52s
service/prometheus-operated ClusterIP None <none> 9090/TCP 2m40s
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/kube-prometheus-stack-alertmanager alb alertmanager.kimchigood.link k8s-monitoring-b4ff94b1ba-586092015.ap-northeast-2.elb.amazonaws.com 80 2m52s
ingress.networking.k8s.io/kube-prometheus-stack-grafana alb grafana.kimchigood.link k8s-monitoring-b4ff94b1ba-586092015.ap-northeast-2.elb.amazonaws.com 80 2m52s
ingress.networking.k8s.io/kube-prometheus-stack-prometheus alb prometheus.kimchigood.link k8s-monitoring-b4ff94b1ba-586092015.ap-northeast-2.elb.amazonaws.com 80 2m52shelm chart 설치 후 pod, svc, ingress만 확인하면 위와 같은 리소스들이 생성된다. Prometheus stack를 사용하면, Visualizing을 해주는 Grafana와 Alert을 담당하는 alermanager도 함께 설치 할 수 있다.
그럼 Prometheus는 어디서 metric정보를 가져오는 것일까?
(kimchigood:default) [root@kops-ec2 ~]# kubectl get node -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
i-02932457f9845ecf6 Ready node 37m v1.24.12 172.30.78.225 54.180.109.140 Ubuntu 20.04.5 LTS 5.15.0-1031-aws containerd://1.6.18
i-0b4fe9bb506cb39d9 Ready node 37m v1.24.12 172.30.37.211 13.125.78.92 Ubuntu 20.04.5 LTS 5.15.0-1031-aws containerd://1.6.18
i-0d3f0b674dc34b6b6 Ready control-plane 40m v1.24.12 172.30.63.30 3.35.13.37 Ubuntu 20.04.5 LTS 5.15.0-1031-aws containerd://1.6.18
(kimchigood:default) [root@kops-ec2 ~]# kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 100.65.249.133 <none> 9100/TCP 9m54s
NAME ENDPOINTS AGE
endpoints/kube-prometheus-stack-prometheus-node-exporter 172.30.37.211:9100,172.30.63.30:9100,172.30.78.225:9100 9m54s바로, 각 노드의 9100번 포트의 /metrics 엔드포인트에서 node-export 관련 모니터링 데이터를 수집한다. 또 다른 메트릭 정보는 각 endpoint를 호출한다.
배포된 ingress를 통해 Prometheus의 ui로 접속하게 되면 아래와 같은 화면이 나온다.
세팅된 Promethues의 설정값, job_name 등의 정보확인기 가능하고, Graph 탭에 가면 수집중인 metrics 들을 확인할 수 있다.
PromQL 이라는 자체 언어로 메트릭 확인이 가능한데, 뭔가 특정 메트릭 정보를 수집해야한다거나, 조작을 해야할 때 쓰는 것 같다. Grafana 대시보드 중 워낙 가시성이 뛰어난 것들이 많으므로, 특별한 경우가 아니면 기본 세팅을 사용하는 것도 좋은 것 같다.
근데, 이렇게 보면 뭐가 뭔지 잘 보이나? 그닥 친절하지 못한 대시보드 화면인데, 그래서 위에서 설명한 Grafana를 사용하면 뭔가 있어보이는 화면을 접할 수 있다.
2-2. Grafana
우리는 Prometheus-stack을 통해 설치를 했으므로, Grafana도 함께 설치되었다.
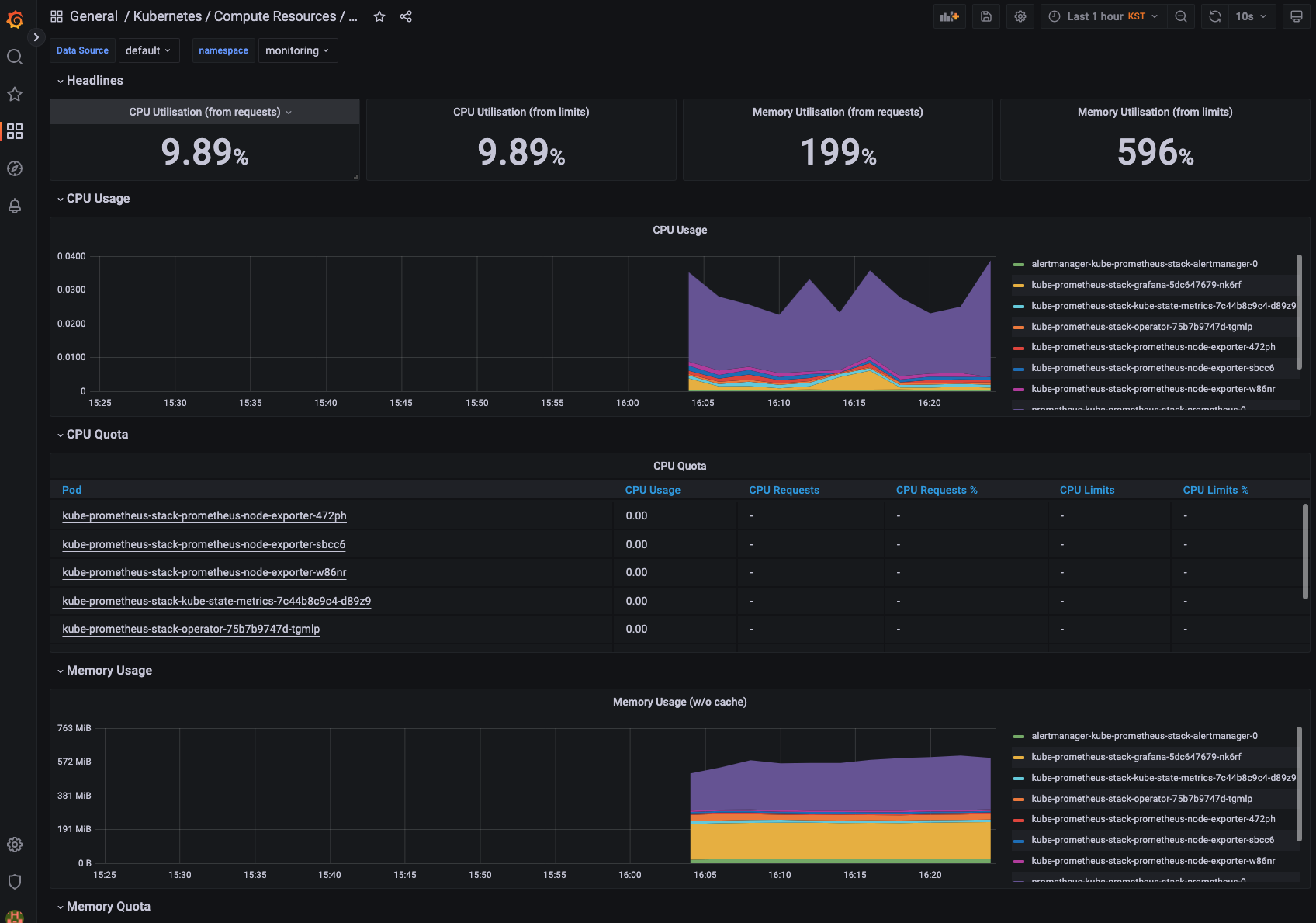
helm chart를 잘보면, grafana password가 기본세팅되어 있다. 이정도는 직접 찾아서 확인해보자.
위 화면은 정말로 기본중의 기본 대시보드다. 네임스페이스 별로 제공되는데, 이정도만 되도 훌륭하다. kubectl top pod, kubectl top node 이렇게 확인할 필요없이, 이렇게 딱! 시각적으로 엄청난 대시보드를 제공해 준다.

기본 세팅값으로 datasource에 prometheus가 세팅되어 있다. Grafana, Prometheus 모두 같은 클러스터에 설치했으므로, 위 URL을 통해 데이터를 가져올 수 있다.
(kimchigood:default) [root@kops-ec2 ~]# k get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 28m
kube-prometheus-stack-alertmanager ClusterIP 100.65.182.35 <none> 9093/TCP 28m
kube-prometheus-stack-grafana ClusterIP 100.69.114.115 <none> 80/TCP 28m
kube-prometheus-stack-kube-state-metrics ClusterIP 100.71.228.8 <none> 8080/TCP 28m
kube-prometheus-stack-operator ClusterIP 100.66.46.33 <none> 443/TCP 28m
kube-prometheus-stack-prometheus ClusterIP 100.71.186.24 <none> 9090/TCP 28m
kube-prometheus-stack-prometheus-node-exporter ClusterIP 100.65.249.133 <none> 9100/TCP 28m
prometheus-operated ClusterIP None <none> 9090/TCP 28m예전에는 Grafana도 뭔가 데이터를 저장하는 줄 알고, 바보같이 PVC-PV를 만든적도 있었다. Grafana는 Visualization 담당이고, 실제 데이터는 Prometheus에 있는 걸 기억하자!
이런 기능은 몰랐는데, Grafana에서 공식 대시보드도 제공해준다. Grafana Dashboard 에서 맘에드는 대시보드 id 값을 골라 운영 중인 Grafana에 import 시킬 수 있다. (이게 다 되는 건 아니고, prometheus에서 수집중인 메트릭 데이터와 대시보드가 맞아야 잘나온다.)
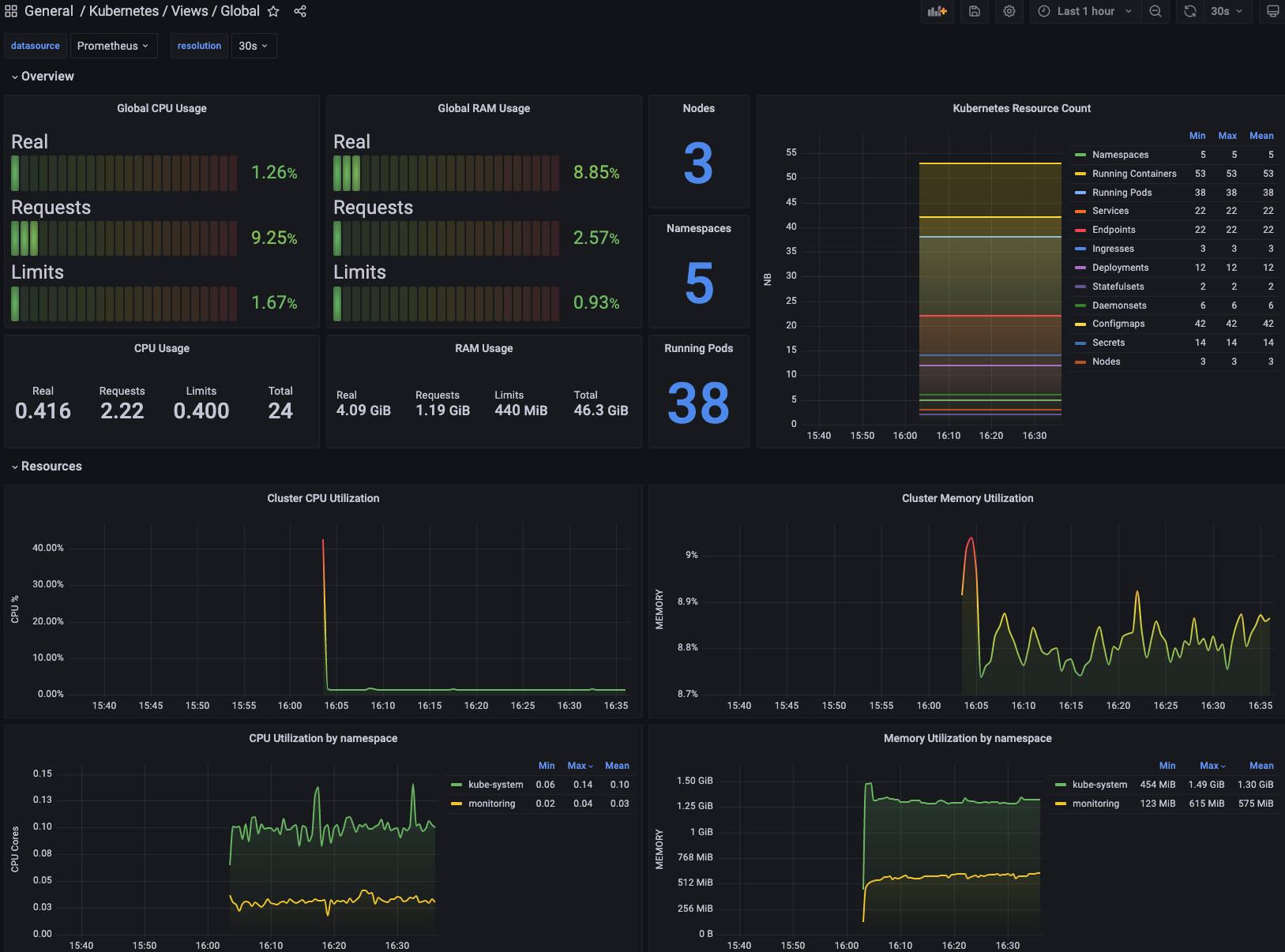
너무 아름답다! 사실 뭐 복잡하게 한 건 없는 것 같은데, 엄청난 기능을 구현한 것 같다. prometheus-stack을 처음 사용할 때, 느꼈던건 정말 내가 뭔가 엄청난 걸 해냈다 라는 느낌을 주었었다ㅎㅎ
3. Alert
kwatch를 통해 모니터링 시스템에서 alert을 줄 수 있다. 링크를 확인해보면 slack, discord, email, telegram 등이 있다.
Alert은 prometheus-stack으로 설치되는 alertmanager 또는 grafana 자체 alert기능도 있는데, 이번 포스팅에서는 kwatch만 다루도록 하겠다.
kwatch는 helm으로 설치가 가능하고, 그냥 yaml파일로 간단하게 설치도 가능하다. 세부적인 기능은 alermanager를 통한 alert을 이용하는게 좋을 것 같다.
# configmap 생성
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'https://hooks.slack.com/services/testesttesstestestestrest'
#title:
#text:
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOT
kubectl apply -f kwatch-config.yaml
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.3/deploy/deploy.yaml위 예제는 alert을 slacke channel로 쏴주는 예제이다. configMap에서 webhook은 각자 실습환경에 맞게 바꿔줘야한다.
잘못된 이미지 배포
# 터미널1
watch kubectl get pod
# 잘못된 이미지 정보의 파드 배포
kubectl apply -f https://raw.githubusercontent.com/junghoon2/kube-books/main/ch05/nginx-error-pod.yml
kubectl get events -w이미지가 없는 nginx 버전을 배포하면, 위에서 설정한 configMap에 의해 slack으로 알람이 오게된다.
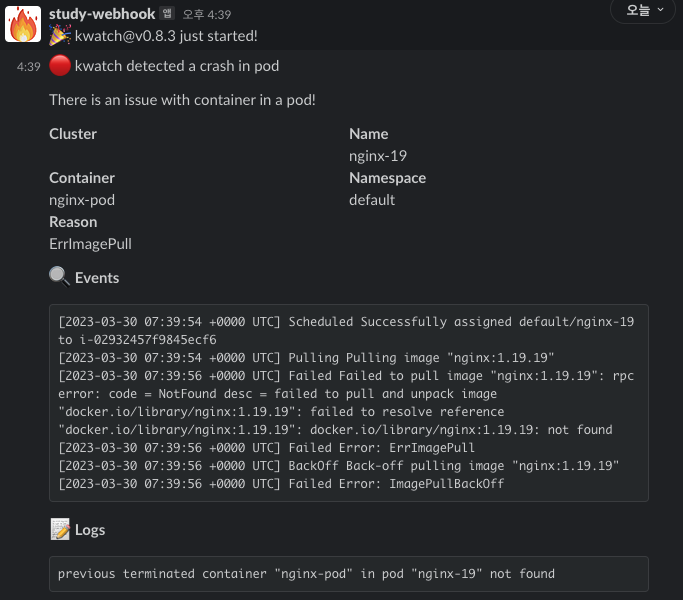
Alert 기능은 모니터링에서 빠져서는 안되는 기능이다. 24/7 항상 Grafana만 보고 있을 수는 없지 않은가! 장애가 나기 전 미리 예방하는 효과도 있고, 꼭 필요한 기능 중 하나다.
4. Logging
Logging도 운영상 매우 중요한 파트이다. 실제로 어플리케이션에서 어떤 에러가 발생했는지, 원인은 무엇인지 파악하기 위해 Logging을 사용하는데, k8s에서는 어떻게 세팅하는 지 알아보자.
컨테이너 로그 권고사항을 참조하면 stdout과 stderr로 나눠서 로그를 보내라고 한다.
Nginx를 예로들면, error 로그와 access 로그가 각각 나눠져 있다.
# Nginx helm 설치 주소
helm repo add bitnami https://charts.bitnami.com/bitnami(kimchigood:default) [root@kops-ec2 ~]# kubectl logs deploy/nginx -c nginx -f
nginx 08:43:13.97
nginx 08:43:13.97 Welcome to the Bitnami nginx container
nginx 08:43:13.97 Subscribe to project updates by watching https://github.com/bitnami/containers
nginx 08:43:13.97 Submit issues and feature requests at https://github.com/bitnami/containers/issues
nginx 08:43:13.97
nginx 08:43:13.97 INFO ==> ** Starting NGINX setup **
nginx 08:43:13.98 INFO ==> Validating settings in NGINX_* env vars
nginx 08:43:13.99 INFO ==> No custom scripts in /docker-entrypoint-initdb.d
nginx 08:43:13.99 INFO ==> Initializing NGINX
realpath: /bitnami/nginx/conf/vhosts: No such file or directory
nginx 08:43:14.00 INFO ==> ** NGINX setup finished! **
nginx 08:43:14.01 INFO ==> ** Starting NGINX **
^C
(kimchigood:default) [root@kops-ec2 ~]# kubectl exec -it deploy/nginx -c nginx -- ls -l /opt/bitnami/nginx/logs/
total 0
lrwxrwxrwx 1 root root 11 Feb 17 14:51 access.log -> /dev/stdout
lrwxrwxrwx 1 root root 11 Feb 17 14:51 error.log -> /dev/stderr공식 Dockerfile을 참조하면 심볼링 링크로 로그 경로가 지정되어 있는 것을 알 수 있다.
바로 Dockerfile에서 관련 세팅을 해줬기 때문에 kubectl log로 로그가 조회가 되는 것이다! 권고사항 문서를 보면 모두 /dev/stdout, /dev/stderr을 사용하는게 아니라, 어플리케이션 마다 다르니 개발 전 참고하도록 하자.
제한사항
Note:
Only the contents of the latest log file are available through kubectl logs.For example, if a Pod writes 40 MiB of logs and the kubelet rotates logs after 10 MiB, running kubectl logs returns at most 10MiB of data
그리고 중요한 것은 kubectl logs로 로그를 읽어 올 때 최대 10MiB까지만 조회가 가능하다. 이런 조건 때문에 Loki를 쓰는 것이기도 하다.
4-1. PLK Stack

그림참조: https://www.infracloud.io/blogs/logging-in-kubernetes-efk-vs-plg-stack/
PLK Stack이란 Promtail + Loki + Grafana로 이뤄진 구조로 여러 파드의 로그들을 저장하고 조회하는 기능을 제공한다.
그럼 바로 설치부터 해보자.
Loki 설치
# 모니터링
kubectl create ns loki
watch kubectl get pod,pvc,svc,ingress -n loki
# Repo 추가
helm repo add grafana https://grafana.github.io/helm-charts
# 파라미터 설정 파일 생성
cat <<EOT > ~/loki-values.yaml
persistence:
enabled: true
size: 20Gi
serviceMonitor:
enabled: true
EOT
# 배포
helm install loki grafana/loki --version 2.16.0 -f loki-values.yaml --namespace loki
# 설치 확인 : 데몬셋, 스테이트풀셋, PVC 확인
helm list -n loki
kubectl get pod,pvc,svc,ds,sts -n loki
kubectl get-all -n loki
kubectl get servicemonitor -n loki
kubectl krew install df-pv && kubectl df-pv
# curl 테스트 용 파드 생성
~~kubectl delete -f ~/pkos/2/netshoot-2pods.yaml~~
kubectl apply -f ~/pkos/2/netshoot-2pods.yaml
# 로키 gateway 접속 확인
kubectl exec -it pod-1 -- curl -s http://loki.loki.svc:3100/api/prom/label
# (참고) 삭제 시
helm uninstall loki -n loki
kubectl delete pvc -n loki --allPromtail 설치
# 파라미터 설정 파일 생성
cat <<EOT > ~/promtail-values.yaml
serviceMonitor:
enabled: true
config:
serverPort: 3101
clients:
- url: http://loki-headless:3100/loki/api/v1/push
#defaultVolumes:
# - name: pods
# hostPath:
# path: /var/log/pods
EOT
# 배포
helm install promtail grafana/promtail --version 6.0.0 -f promtail-values.yaml --namespace loki
# (참고) 파드 로그는 /var/log/pods에 저장
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME ls /var/log/pods
# 설치 확인 : 데몬셋, 스테이트풀셋, PVC 확인
helm list -n loki
kubectl get pod,pvc,svc,ds,sts,servicemonitor -n loki
kubectl get-all -n loki
# (참고) 삭제 시
helm uninstall promtail -n lokiLoki, Promtail 설치가 끝나면, Grafana에서 datasource를 등록해 준다.
Http: http://loki-headless.loki:3100
이제 위에서 설치한 Nginx의 로그를 계속해서 발생시켜보자.
while true; do curl -s http://nginx2.$KOPS_CLUSTER_NAME -I | head -n 1; date; sleep 1; done마지막으로 Grafana에서 확인할 차례이다. Explore 탭에서 아까 추가한 Loki를 선택하고, Lable filters : job = default/nginx를 선택한 후 Run query 버튼을 눌러주자.
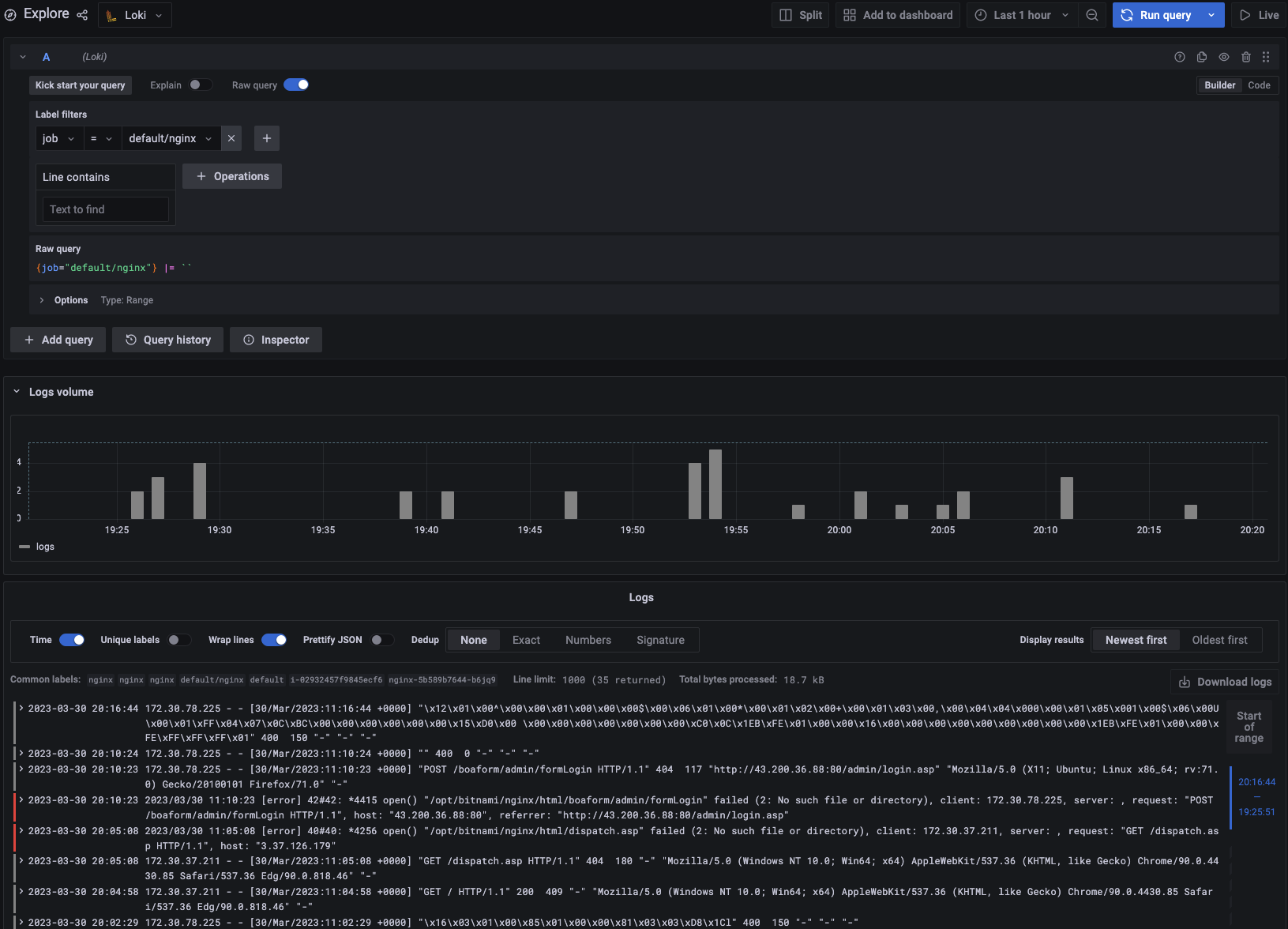
야~멋지다! 우리 Loki! 로그들이 이제 Grafana에서 보인다!
실습 클러스터 삭제
kops delete cluster --yes && aws cloudformation delete-stack --stack-name mykopswrap up
이번 포스팅에서는 Monitoring과 Logging에 대해 실습해보았다. 그동안 개발자로 일하면서 이런 시스템은 사용하기만 했었는데, k8s를 접한 후 부터 꼭 다뤄야만 했던 시스템들이다.
특히 prometheus-stack으로 엄청 간편하게 Monitoring 시스템 구축이 가능한건 혁명에 가깝다고 할 수 있다. 대시보드도 얼마나 화려하고 가시성이 좋은가?!
Loki도 Grafana 찾아보면서 그냥 잠깐 들어보기만 했는데, 이렇게 간편할줄은 몰랐다. 예전에는 잘몰라서 k8s에 Logging 시스템을 만드려고 ELK를 설치하려고 했던 적이 있다.
Loki 하나면 다 되는데, prometheus + grafana가 있는 클러스터에 Logging을 위해 ELK Stack을 구성하는 건 정말..
역시 사람은 배워야 한다.
