Machine Translation 모델에서 UNK Token 처리 방법
UNK token 이란?
UNK token이란 unknown token을 말한다.
기계번역은 source 언어 sentence를 target 언어 sentence로 번역한다. 모델이 배우지 못한 단어이거나, 학습이 덜 되어있으면 모델이 번역을 하지 못하고, 모르는 단어라는 뜻의 unk token을 생성할 수 있다. (생성하지 않게 할 수도 있다.)
기계번역 모델을 공부할겸 번역모델인 OpenNMT-py 코드를 읽고 있는데, 다음의 방법들로 unk token을 replace하고 있어 정리해보았다.
--replace_unk
OpenNMT 코드에서 --replace_unk 옵션을 통해 unk token이 생성되면 어떻게 할지 사용자가 지정할 수 있다.
--replace_unk 옵션은 boolean자료형의 default값은 False이다.
False로 지정되어있는 경우, UNK 토큰 생성시 output으로 UNK토큰이 바로 등장한다.
ex.) ['I', 'like', 'UNK', 'too']
True로 설정된 경우, attention을 통해 source언어의 단어로 대체한다.
OpenNMT-py의 onmt/translate 폴더내의 모든 파일의 코드를 읽어보면, replace_unk가 수행될 때 src attention, src_map 등 source의 attention을 사용한다는 것을 알 수 있다.
아래는 translation.py 의 코드이며, replace_unk 과정을 간략하게 보여준다.
OpenNMT-py/onmt/translate/translation.py
if self.replace_unk and attn is not None and src is not None:
for i in range(len(tokens)):
if tokens[i] == DefaultTokens.UNK:
_, max_index = attn[i][: len(src_raw)].max(0)
tokens[i] = src_raw[max_index.item()]
if self.phrase_table_dict:
src_tok = src_raw[max_index.item()]
if src_tok in self.phrase_table_dict:
tokens[i] = self.phrase_table_dict[src_tok]만약 번역한 결과 중 DefaultTokens.UNK 토큰이 발견되면,
-> src_raw에서 해당 토큰의 인덱스값을 가져와서 src의 토큰을 출력한다.
-> 그리고, 만약 phrase_table_dict가 설정되어 있다면, 해당 src에 대해 미리 설정된 target 토큰을 출력한다.
예시를 들면 다음과 같다.
source sentence: ['I', 'am', 'a', 'student']
translation: ['Ju', 'suis', 'UNK']
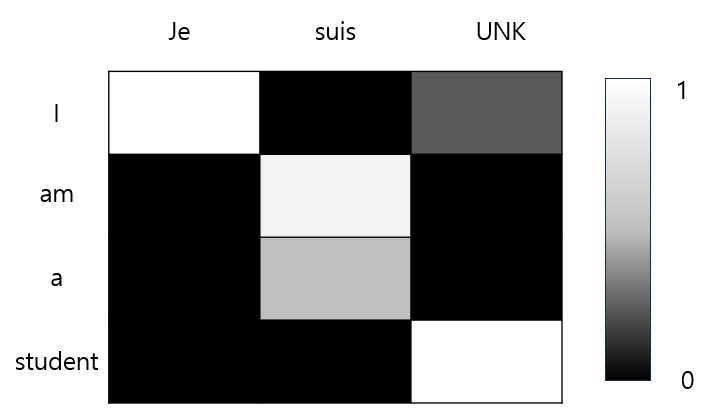
UNK토큰이 나왔으므로 attention distribution을 보고, UNK가 나온 position에서 가장 연관성이 높은 source에서의 token을 찾는다. 그리고 해당 토큰을 출력한다.
여기에서는 UNK와 student의 연관성이 가장 크므로 UNK토큰을 student로 대체할 수 있다.
이때, 미리 정의된 phrase table dict가 있었다면, source token이 'student'일 때의 target token 'étudiant'를 출력하는 방법도 사용할 수 있다.
여기서 phrase table dict는 context가 중요한 일상번역보다는 의학이나 법학처럼 전문용어 번역이 필요한 번역에서 사용하면 모델의 성능을 높일 수 있을 것이다.
가벼운 예시를 들자면 '홍차'를 'red tea'가 아닌, 'Black tea'로 번역할 때 사용할 수 있다. 찻잎을 보는지, 차가 우려진 후 그 찻물의 색을 보는지에 따라 이름을 붙인 것이기 때문에, 문장 내 context를 모델에게 학습시켜도 이 문제는 해결할 수 없다. '홍차'가 'red tea'로 번역되는 오류를 줄이려면 phrase table dict를 사용하는 것이 좋을 것이다.
Reference
- OpenNMT-py https://github.com/OpenNMT/OpenNMT-py.git
- Seq2Seq with Attention 포스팅 https://velog.io/@stapers/Seq2Seq-with-Attention
- [paper] Neural Machine Translation by Jointly Learning to Align and Translate https://arxiv.org/abs/1409.0473
