0. 들어가기에 앞서
이번에 리뷰해볼 논문은 Neural Machine Translation by Jointly Learning to Align and Translate이다. 지금은 유명해지신 조경현 교수님이 참여하신 논문인데, 본래는 교수님이 제시하신 seq2seq 구조를 개선하고자 attention 매커니즘을 추가하는 정도의 내용이다. 하지만 attention 매커니즘 자체가 워낙 강력해서 이제는 seq2seq은 버려도 attention만 가져다 쓰는 모델들이 많아질만큼 중요한 논문이 되었다.
자주보지 못하는 단어들이 몇개 나오는데, cs224n에서 접했지만 한번 정리하고 시작하자.
- (hard) alignment : 본래의 alignment이다. 전통적인 기계번역 분야에서는 번역할 문장에서 번역된 문장 간의 관계를 파악했다.
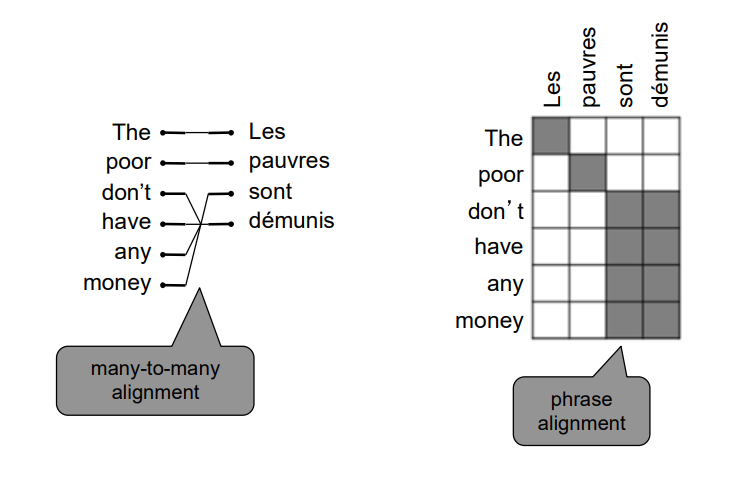
위의 그림은 그 예시인데, 위와 같이 그 관계를 파악해서 테이블 형태로 만들어놓은 것을 alignment라고 한다. 이때 연속해서 1대 1대응이 되는 부분은 하나의 구로 간주하게 된다. 그리고 구 단위로 번역을 수행하는 것을 phrase based SMT(Statistical Machine Translation)이다. 논문이 출간될 당시에는 phrase based SMT가 SOTA 모델이었던 것 같다. - (soft) alignment : 본래의 alignment는 discrete한 개념이었다. 즉, 두 단어의 관계가 있거나, 없거나 둘 중 하나의 binary 변수로 활용되었다. 하지만 실제 번역 시에는 이렇게 완벽하게 구분되기 보다는 해당 단어의 일부 의미만 다른 단어로 번역되는 식으로 비율로서 번역에 활용되게 된다. 그래서 alignment를 0 ~ 1의 비율로 구성한 것이 soft alignment이다.
1. Introduction
조경현 교수님이 이전에 발표하셨던 encoder-decoder 구조는 인코더와 디코더로 이루어져 있었다. 인코더는 번역할 문장을 임베딩 벡터의 sequence에서 고정된 크기의 벡터로 인코딩한다. 디코더는 인코딩된 벡터를 이용하여 번역된 문장을 생성하게 된다. 하지만 여기서 문제가 발생했는데, 번역할 문장의 길이가 짧을 때는 문제가 없었지만, 문장의 길이가 길어지면, 장기 의존성 문제를 가지고 있는 RNN의 특성상 고정된 벡터로 제대로 정보가 담기지 않는 것이다.
그래서 해당 논문에서는 인코더 디코더 모델이 alignment를 학습하고 이를 활용해서 번역하도록 하고 있다. 이때 alignment는 soft하게 구성되며 디코딩 시 매 시점마다 해당 시점과 가장 관련이 있는 번역할 단어의 위치를 찾게 된다. 이렇게 함으로써 모델은 더이상 인코딩하면서 고정된 벡터로 모든 정보를 우겨넣을 필요가 없어진다.
2. Model Structure
2.1 Encoder
인코더는 번역할 문장의 정보를 읽는 부분이다. 즉, 문장을 이해하는 역할을 한다. 기존의 모델들은 RNN을 단방향으로 활용하여 문장의 처음부터 끝으로 정보를 흘려보냈지만, 해당 논문에서는 문장을 이해하기 위해서는 매 시점마다 앞 뒤의 정보를 참고할 필요가 있다고 여겼다. 그래서 BiRNN(Bidirectional RNN)을 사용한다.
우선 순방향으로 흐르는 RNN 은 각각의 시점마다 hidden state을 return하게 될 것이다. 역방향으로 흐르는 RNN 역시 각각의 시점마다 hidden state를 return하게 된다. 그렇다면 i 시점의 입력 단어 는 양방향에서 흘러온 정보를 토대로 hidden state를 가지게 되는데, 이는 두 hidden state를 concat하여 구성된다.
이때 RNN은 장기 의존성 문제로 인해 최근의 정보들만 담고 있게 되므로, 는 주변의 정보만 담게 된다.
2.2 Decoder
NMT에서 디코더는 조건부 확률 모델이다. 다음과 같은 수식으로 모델이 표현될 수 있기 때문이다.
이때 c는 콘텍스트 벡터로 인코더에서 넘어와서 디코더에서 흐르는 hidden state를 의미한다. 즉, 디코더는 이전까지 생성한 문장과 hidden state를 조건으로 이번에 생성할 단어 분포를 계산한다.
이때, 모델은 다음과 같은 함수로 확률을 계산한다.
하지만 해당 논문은 위의 식을 새롭게 만든다.
여기서 는 다음과 같은 식을 통해 만들어진다.
이전 시점의 출력값과 hideen state, 를 이용해 만들어진다.
2.2.1 Bahdanau Attention
트랜스포머에선 dot product attention을 사용하지만, 여기선 반다나우 어텐션을 사용한다. 조금 복잡해보일 수 있지만, 다음과 같다.
=
는 context vector로 인코더의 hidden state인 를 가중치 를 이용해 가중합하여 구성된다. 이때 는 다음을 통해 구해진다.
여기서 다시 는 다음으로 구해진다.
즉, 다시 거꾸로 거슬러 올라가보면, 디코더의 입장에서 이전 시점의 hidden state와 인코더 각 시점의 hidden state를 이용해 연산하여 attention score 를 구한다. 이를 확률분포 형태로 만들고 위해 softmax를 통과하여 attention dist. 를 만든다. 이 를 가중치로 사용해 인코더의 각 시점의 hidden state를 가중합하여 를 만들게 된다.
2.2.2 Attention in GRU
사실 논문 읽으면서 당황하게 된 지점은 이 부분이었는데, 반다나우 어텐션이야 내적을 그냥 레이어로 바꾼것에 불과하지만, 이 부분은 GRU 내부에 를 집어넣으면서 생소해졌기 때문이다. 기존의 GRU 식을 다시 상기해보자면 다음과 같다.
기존의 hidden state 에서 만큼 정보를 지우고 새로운 정보 를 싣는다. 이때 는 이전 시점의 hidden state와 이번 시점의 입력값을 통해 결정된다. 새로운 정보인 는 이번 시점의 입력값과 이전 시점의 hidden state를 잊은 정보를 통해 구성된다. 이때 이전 시점을 얼마나 잊을지는 역시 이번 시점의 입력값과 이전 시점의 hidden state로 구성된다.
여기서 context vector를 추가하려면 사실 아주 간단하다.
새로운 정보를 만들거나 얼마나 싣고, 이전 시점의 hidden state를 얼마나 잊을 지 정할 때 context vector를 더하면 그만이다. 이때 세 식(에서 공통적으로 나타나는 특징은 다음과 같다.
입력값 , hidden state , context vector 를 모두 가중치를 통해 동일한 공간으로 맵핑하고 더한다.
3. Experiment
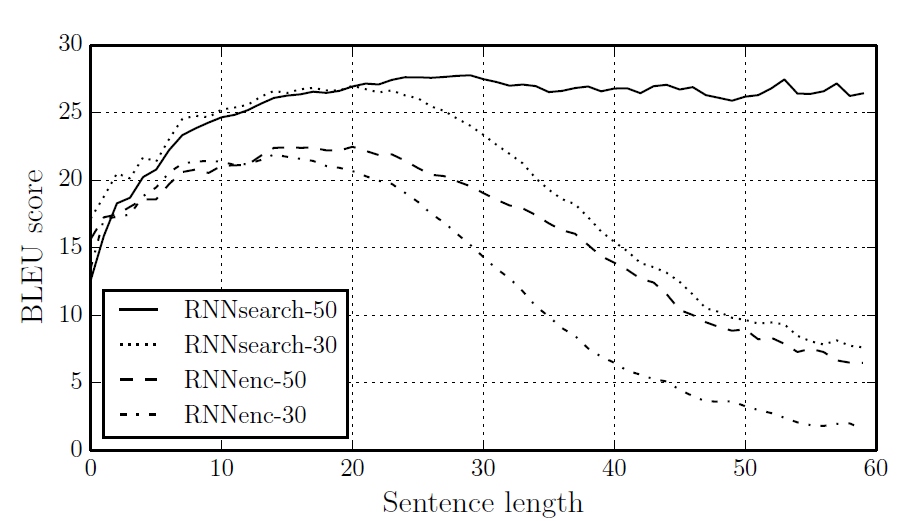
조경현 교수님이 이전에 발표한 RNNenc 모델과 비교해보자면, 전반적으로 성능이 상승한 것을 볼 수 있다. 특별한 점은 RNNsearch-50ㅡ은 학습할 때 사용한 문장 길이이 50보다 긴 경우에도 성능하락이 나타나지 않는다는 점이다.
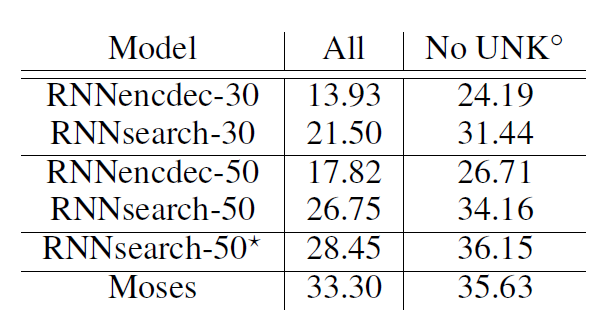
특히 phrase based NMT인 Moses와 비교해서도 우수한 성능을 보이고 있다. UNK 토큰이 없는 문장에 대한 BLEU를 보면 오히려 성능이 더 좋도록 튜닝할 수도 있었다(star는 Early Stopping 적용)
4. Qualitative Analysis

위 테이블은 attention dist.를 시각화한 표이다. 1에 가까울 수록 밝게 표시되었다. 특이할 만한점은 hard alignmnet처럼 실제로 동작하고 있다는 점인데, 대부분의 단어가 어순에 맞추어 align되기 때문에 대각 성분들이 밝은 것을 알 수 있다. 하지만 몇몇 단어들은 어순에 반대되어 정렬되어 있다. 특히 오른쪽의 European Economic Area는 불어로 zone economique europeenne인데, 정확히 세 단어의 align이 반대인 것을 잘 잡아낸 것을 볼 수 있다.
5. Conclusion
결국 seq2seq with attention은 alignment를 구하는 내부 모델이 있는 것 외엔 seq2seq과 크게 다르지 않다. 하지만 alignment라는 것이 모델 성능에 큰 변화를 가지고 왔고, 최종적으론 alignmnet만 떼어다 쓰는 모델들이 각광 받게 되었다. 구현을 해봐야 알겠지만, RNN 기반의 모델인 만큼 무척 어렵지는 않지 않을까....?
Hyperparameter
- encoder : 1000 hidden unit
- decoder : 1000 hidden unit
- optimizer : Adadelta
- minibatch : 80
