[논문리뷰]Chain-of-Thought Prompting Elicits Reasoning in Large Language Models(NeurIPS 2022)
논문 리뷰
Abstract
1. Introduction
2. Chain-of-Thought Prompting
3. Arithmetic Reasoning
3.1. Experimental Setup
3.2. Results
3.3. Ablation Study
3.4. Robustness of Chain of Thought
4. Commonsense Reasoning
5. Symbolic Reasoning
6. Discussion
7. Related Work
8. Conclusions
Self Q&A
Opinion
Abstract
연구자들은chain of thought(중간과정의 reasoning step series)를 생성하는 것이, 복잡한 문제에 대한 LLM의 reasoning 능력을 어떻게 향상시키는지 살펴보았다.
특히, 논문에서는 chain-of-thought prompting이라는 간단한 방법을 통해, LLM에서 reasoning 능력이 어떻게 자연스럽게 발현됐는지를 보여준다(LLM이 왜 reasoning이 가능한지). 프롬프팅에서는 few chain-of-thought examplars가 예시로 함께 입력된다.
LLM에 대한 3가지 task의 실험을 통해, chain-of-thought prompting이 다양한 arithmetic(산술), commonsense(상식), symbolic reasoning(상징적 추론) task에서 성능을 향상시킨다는 것을 확인했다.
실험 결과는 놀라웠다. 예를 들어, PaLM 540B 모델을 이용해 8개의 chain-of-thought examplars만을 사용한 프롬프트으로, math word problems 벤치마크인 GSM8K에서 SOTA 정확도를 달성했는데, 이는 fine-tuned GPT-3를 뛰어넘은 점수이다.
1. Introduction
언어 모델의 크기를 확장하면 성능 및 샘플 효율성 향상과 같은 다양한 이점을 얻을 수 있는 것으로 나타났다.
그러나 모델 크기를 확장(Scaling up)하는 것만으로는 arithmetic(산술), commonsense(상식), symbolic reasoning(상징적 추론-규칙이해-)과 같은 까다로운 작업에서 높은 성능을 달성하기에 부족했다.
이 연구에서는 두 가지 아이디어(가설)로, LLM의 reasoning 능력을 향상시키는 시도를 진행했다.
1) arithmetic reasoning은 final answer로 이어지는 natural language rationale을 생성함으로써 이점을 얻을 수 있다.
이전 연구에서도 모델을 (중간 단계를 출력하는 형태로)처음부터 다시 학습하거나, 사전 학습된 모델을 fine-tuning 하여 중간 단계를 생성하는 시도가 존재했다(또는 neuro-symbolic 방법).
2) LLM은 프롬프팅 과정에서 in-context few-shot learning을 통해 성능을 향상시킬 수 있다(ICL 잠재성은 아직 다 드러나지 않았다).
즉, 새로운 task마다 별도의 언어 모델 checkpoint를 fine-tuning하는 대신, task에 대한 few input–output exemplars를 '프롬프트'하는 것만으로도 성능을 향상시킬 수 있다는 내용인데, 놀랍게도 이 방법은 다양하고 간단한 question-answering tasks에서 성공적으로 적용되어 왔다.
두 가지 아이디어에 대한 기존의 접근법은 limitations이 존재했다(기존의 방법을 의미. 즉, fine-tuning과 일반적인 ICL).
rationale-augmented training 또는 fine-tuning 방법의 경우, 일반 머신러닝에서 사용되는 단순한 input–output pairs보다 훨씬 더 복잡한 고품질의 대규모 rationales set이 필요하다(costly expensive).
전통적인 few-shot prompting 방식은 reasoning 능력이 필요한 작업에서는 제대로 작동하지 않았으며, 언어 모델 규모가 커져도 크게 개선되지 않는 경우가 많았다.
논문에서는 이 두 가지 아이디어의 한계를 피하는 방식으로 두 아이디어의 강점만을 결합했다.
구체적으로, 언어 모델에 few-shot prompting을 적용하여 reasoning task의 성능향상을 이끌어 낼 수 있는지를 알아보기 위해, <input, chain-of-thought, output> 3가지로 구성된 프롬프트가 주어졌을 때 언어 모델이 어떻게 작동하는지 살펴보았다.
chain-of-thought는 final output으로 이어지는 a series of intermediate natural language reasoning steps(일련의 중간과정의 reasoning step)으로, 이러한 접근 방식을 chain-of-thought prompting이라고 한다(Figure 1).
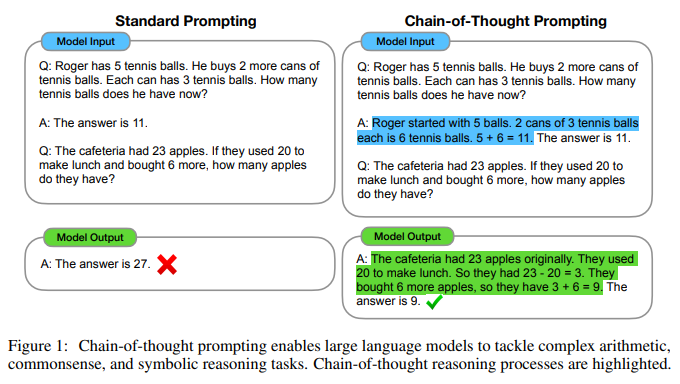
- 왼쪽은 일반적인 ICL
- 오른쪽은 chain-of-thought prompting
- example의 input과 output 사이에 chain-of-thought를 추가해줌으로써, 다른 결과를 생성하도록 유도했는데, 이는 결과의 향상으로도 이어졌다.
arithmetic, commonsense, symbolic reasoning 벤치마크에 대한 경험적 평가를 통해, chain-of-thought prompting이 표준 프롬프트보다 성능이 뛰어나며 때로는 놀라울 정도로 뛰어나다는 것을 확인했다.

Figure 2는 이러한 결과 중 하나를 보여주는데, math word problems 벤치마크인 GSM8K에서 PaLM 540B를 사용한 chain-of-thought prompting은 표준 프롬프트 방식을 큰 차이로 능가하였을 뿐만아니라, SOTA를 달성했다.
이 방식은 대규모 학습 데이터 세트가 필요하지 않으며, checkpoint가 하나인 단일 모델이기 때문에, generalization을 잃지 않고 많은 작업을 수행할 수 있다.
2. Chain-of-Thought Prompting
multi-step math word problem과 같은 복잡한 reasoning task를 풀 때 인간의 사고 과정을 생각해 보면, final answer를 도출해 내기 위해 문제를 여러 단계로 분해하고, 각 단계를 해결한다.
- "After Jane gives 2 flowers to her mom she has 10... then after she gives 3 to her dad she will have 7... so the answer is 7(final answer)"
논문의 목표는 언어 모델에 위와같은 chain-of-thought, 즉 문제의 final answer로 이어지는 일련의 일관된 intermediate reasoning steps를 생성할 수 있는 능력을 부여하는 것이다.
few-shot prompting의 exemplars에 chain-of-thought reasoning에 대한 예시가 제공된다면, sufficiently('일정 규모 이상의'로 의역) LLM은 chain-of-thought를 생성할 수 있다는 것을 입증했다.
chain-of-thought prompting은 언어 모델에서 reasoning을 촉진하는 접근 방식으로서 아래와 같은 매력적인 특성을 가지고 있다.
- 1) chain-of-thought는 원칙적으로 multi-step problems을 intermediate steps로 분해할 수 있도록 허용하므로, 더 많은 reasoning step이 필요한 문제에 추가 계산을 할당할 수 있다(multi-step으로 나눠서 문제 해결).
- 2) chain-of-thought는 모델의 행동에 대한 interpretation(해석 가능한)을 제공하여, 모델이 특정 답에 어떻게 도달했는지를 알 수 있기 때문에, reasoning이 잘못된 부분(어디서 틀렸는지)을 디버깅할 수 있다(intermediate steps에서의 정확도를 높이는 것은 아직 미해결 과제).
- 3) chain-of-thought reasoning은 math word problems, commonsense reasoning, symbolic manipulation과 같은 task에 사용할 수 있으며, 원칙적으로 인간이 언어를 통해 해결할 수 있는 모든 문제에 잠재적으로 적용될 수 있다.
- 4) chain-of-thought reasoning은 few-shot prompting의 exemplars에 chain-of-thought sequences 예제를 포함시킴으로써, 기성 LLM을 그대로 사용하더라도(fine-tuning없이), 원하는 형태의 답변을 쉽게 이끌어낼 수 있다.
경험적 실험을 통해, arithmetic reasoning(Section 3), commonsense reasoning(Section 4), symbolic reasoning(Section 5)에 대한 chain-of-thought prompting의 유용성을 살펴보겠다.

3. Arithmetic Reasoning
arithmetic reasoning(산술)은 인간에게는 간단하지만 언어 모델에게는 종종 어려움을 겪는 task로 알려져 있다.
540B parameter 언어 모델을 이용한 chain-of-thought prompting은 여러 task에서 task specific fine-tuned 모델과 비슷한 성능을 보이며, 심지어 GSM8K 벤치마크에서 SOTA를 달성했다.
3.1. Experimental Setup
Benchmarks
- GSM8K
- SVAMP
- ASDiv
- AQuA
- MAWPS
Standard prompting
baseline으로 GPT3에 의해 대중화된 standard few-shot prompting를 고려하는데, 실제 예측하고자하는 문제를 프롬프트에 제시하기 전에, 언어 모델에 input–output pairs의 in-context exemplars를 제공하는 방식이다(In-Context-Learning).
예제는 질문과 답변 형식으로 제공되며, Figure 1(left)과 같이 모델이 답을 한번에 출력한다.
Chain-of-thought prompting
새로운 접근 방식은 Figure 1(오른쪽)에서 볼 수 있듯이, 최종 답변에 도달하기 위한 chain-of-thought을 통해 few-shot prompting의 각 exemplar를 증강하는 것이다.
연구자들은 프롬프트에 대한 chain-of-thought가 포함된 8개의 few-shot exemplars 세트를 수동으로 구성했다. Figure 1(right)은 chain-of-thought의 exemplar 중 하나이며, 전체 exemplar set는 Appendix Table 20에 나와 있다.
Language models
5가지 LLM 모델에 대해 평가를 진행했다.
- GPT: 350M, 1.3B, 6.7B, 175B (text-ada-001, text-babbage-001, text-curie-001, and text-davinci-002)
- LaMDA: 422M, 2B, 8B, 68B, 137B
- PaLM: 8B, 62B, 540B
- UL2 20B
- Codex: code-davinci-002
3.2. Results

세 가지 핵심 사항이 있다.
- 첫째, chain-of-thought prompting이 모델 규모에 따라 성능이 향상된다.
즉, chain-of-thought prompting는 소규모 모델의 경우 성능 향상이 미미하며, 100B 이상의 모델을 사용할 때만 성능 향상이 나타난다.
규모가 작은 모델은 유창하지만(말은 되지만) 비논리적인 chain-of-thought를 생성하여 standard 프롬프트보다 성능이 낮다는 것을 질적으로 발견했다. - 둘째, chain-of-thought prompting는 더 복잡한 문제에서 더 큰 성능 향상을 가져온다.
baseline의 성능이 가장 낮은 GSM8K의 경우, largest GPT와 PaLM 모델을 사용했을 때 성능이 두 배 이상 증가했다.
반면, 하나의 step만 거치면 풀 수 있는 MAWPS의 SingleOp의 경우, 성능 향상이 마이너스를 기록하거나 향상이 미미했다. - 셋째, GPT-3 175B와 PaLM 540B를 통한 chain-of-thought prompting은 일반적으로 기존의 task-specific fine-tuned 모델보다도 더 좋은 성능을 기록했다.
chain-of-thought prompting이 작동하는 이유를 더 잘 이해하기 위해 LaMDA 137B가 GSM8K에 대해 생성한 chain-of-thought을 직접 확인했다.
모델이 정답을 반환한 50개의 무작위 예시 중, 우연히 정답에 도달한 두 개를 제외하고는 생성된 모든 chain-of-thought이 논리적으로나 수학적으로도 정확했다.
모델이 오답을 제시한 50개의 무작위 표본의 경우, 사소한 실수(calculator error, symbol mapping error, one reasoning step missing)를 제외하면 46%의 chain-of-thought가 거의 정답이었으며, 나머지 54%의 chain-of-thought는 의미나 일관성에서 중대한 오류가 있었다.
scaling(모델 크기를 키우는 것)이 chain-of-thought reasoning 능력을 향상시키는지에 대해 확인하기 위해, PaLM 62B에서 발생한 오류가 PaLM 540B로 확장했을 때 해결되었는지에 대해 분석했다.
그 결과 PaLM을 540B로 확장하면 62B 모델에서 발생한 one-step missing, semantic understanding error의 상당 부분이 해결되었다.
3.3. Ablation Study

chain-of-thought prompting을 사용할 때 관찰된 이점이, 다른 유형의 프롬프트를 통해서도 동일한 성능 향상을 이끌어 낼 수 있는지에 대한 자연스러운 의문이 제기된다.
Figure 5는 아래에 설명된 세 가지 chain-of-thought prompting의 변형을 적용했을 때의 결과를 보여준다.
Equation only
chain-of-thought prompting의 성능 향상 이유로는, 예측과정에서 mathematical equation(방정식)을 생성한다는 점이다.
따라서 final answer를 제공하기 전에 모델이 mathematical equation을 출력하라는 메시지가 표시되도록 테스트해 보았다(자연어 추론단계는 생성하지 못하며, mathematical equation만 생성).
Figure 5는 mathematical equation을 출력하는 프롬프트가 GSM8K에 큰 도움이 되지 않는다는 것을 보여주며, 이는 GSM8K에서 질문의 의미를 natural language reasoning steps 없이 mathematical equation만으로 직접 변환하기에는 너무 어렵다는 것을 의미한다.
그러나 one-step 또는 two-step 문제로 구성된 데이터 세트의 경우, 질문에서 방정식을 쉽게 도출할 수 있기 때문에 방정식만 프롬프트하는 것이 성능을 향상시키는 것으로 나타났다.
Variable compute only
다음은 chain-of-thought prompting이 더 어려운 문제에 더 많은 계산을 할애할 수 있게 해준다는 점이다.
chain-of-thought reasoning에서 variable computation(변수를 사용한 연산)의 효과를 분리하기 위해, 모델에 문제 해결에 필요한 equation의 문자 수와 동일한 점(...)을 출력하라는 메시지가 표시되도록 테스트했다(중간 과정의 값으로 무엇이 필요하다는 내용).
이 방법은 baseline과 거의 동일한 성능을 보였는데, 이는 variable computation 자체가 chain-of-thought prompting의 성공 원인이 아니며, 자연어를 통해 중간 단계를 표현하는 것(왜 필요한지)이 유용하다는 것을 시사한다.
Chain of thought after answer
chain-of-thought prompting의 또 다른 잠재적 이점은, 단순하게 모델이 pretraining 중에 습득한 relevant knowledge에 더 잘 접근할 수 있게 해준다는 점일 수 있다.
따라서 모델이 실제로 생성된 chain-of-thought prompt에 의존하여 final answer를 제공하는지 여부를 분리하기위해, 최종 답변 후에만 chain-of-thought prompting가 제공되는 구성을 테스트했다.
이 방법은 baseline과 거의 동일한 성능을 보였으며(성능 향상이 없없음), 이는 chain-of-thought prompting에 구현된 sequential reasoning이 단순히 지식을 활성화하는 것 이상의 이유로 유용하다는 것을 시사한다(리뷰어는 s보다 이전 시점만 참고하는 language modeling의 특성 때문이라고 생각).
3.4. Robustness of Chain of Thought

exemplar-based prompting를 사용할 때 예상할 수 있는 바와 같이, 다양한 chain-of-thought annotations 간에 차이가 있지만, 모든 chain-of-thought prompt set가 standard baseline을 큰 폭으로 능가하는 것으로 나타났다.
이 결과는 chain-of-thought의 성공적인 사용이 특정 언어 스타일에 의존하지 않는다는 것을 의미한다(examplar의 개수, 순서도 크게 영향 없음).
4. Commonsense Reasoning
chain-of-thought는 math word problems에 특히 적합하지만, chain-of-thought의 'language-based' 특성 덕분에, 일반적인 배경 지식을 전제로 물리적, 인간적 상호작용에 대해 추론하는 광범위한 종류의 commonsense reasoning problems(상식)에도 적용할 수 있다.
Commonsense reasoning은 세상과 상호작용하는 데 있어 핵심적인 역할이지만, 현재의 자연어 이해 시스템으로는 아직 도달할 수 없는 영역이다('학습'이 아니라 '지식(아는가)'의 영역이기 때문이라고 생각).
Benchmarks
- CSQA
- StrategyQA
- BIG-bench effort(Date Understanding, Sports Understanding)
- SayCan
Prompts
Section 3와 동일한 실험 설정을 따른다.
Results

Figure 7은 PaLM에 대한 실험 결과를 보여준다. 모든 task에서 모델 크기가 커질수록(scaling up) standard prompting의 성능이 향상되었으며, chain-of-thought prompting을 사용할 경우 추가적인 성능 향상을 가져왔다.
- 리뷰자의 의견: arithmetic reasoning의 step의 문제는 간단하기 때문에, commonsense reasoning보다 LLM 크기의 영향이 적을 것이라고 생각했는데, 의외로 commonsense reasoning이 선형적으로 증가하는 것을 보니, 모델의 크기는 각 step의 문제자체를 해결능력보다도, 적절한 step을 생성하는 것에 큰 영향을 미치는 것 같다(arithmetic reasoning은 일정 규모 이상에서 성능이 크게 향상). -이는 후술할 Symbolic Reasoning의 Results에서 다시 한번 검증
PaLM 540B의 경우 성능 향상 효과가 가장 큰 것으로 나타났는데, chain-of-thought prompting을 통해 PaLM 540B는 baseline 대비 강력한 성능을 달성하여 StrategyQA에서 이전 SOTA를 능가했으며, sports understanding에서도 더 나은 성능을 보였다.
이러한 결과는 chain-of-thought prompting을 다양한 commonsense reasoning 능력을 필요로 하는 작업에서도 성과를 향상시킬 수 있음을 보여준다(CSQA에서는 성능이 미미).
5. Symbolic Reasoning
마지막 실험 평가에서는 인간에게는 간단하지만 언어 모델에게는 어려운 task인(symbolic을 이해해야하기 때문) symbolic reasoning(상징적 추론-규칙이해-)에 대해 진행했다.
chain-of-thought prompting을 적용할 경우, 언어 모델이 standard prompting 설정에서 어려워하던 symbolic teasoning task를 수행할 수 있을 뿐만 아니라(같은 조건에서의 성능 향상), few-shot exemplars보다 더 긴 inference-time input에 대한 length generalization도 용이하다는 것을 보여주었다.
length generalization도 용이하다는 말은, examples의 step 수가 training/few-shot exemplars와 동일한 in-domain 테스트 세트와, 평가 예제를 푸는데 필요한 step 수가 examples의 step 수보다 많은 out-of-domain(OOD) 테스트 세트에 대해서도 성능이 보장된다는 의미이다.
Last letter concatenation
이 task는 모델에게 이름에서 단어의 마지막 character를 연결하도록 하는 task이다(예: "Amy Brown"! "yn").
- OOD 조건 : 모델은 두 단어로 구성된 이름의 exemplars를 확인한 다음, 세 단어 및 네 단어로 구성된 이름에 대한 last letter concatenation 작업을 수행
Coin flip
이 task는 사람들이 동전을 뒤집거나 뒤집지 않은 후에도 동전이 여전히 앞면인지 예측하는 task이다(예: "A coin is heads up. Phoebe flips the coin. Osvaldo does not flip the coin. Is the coin still heads up?" -> "NO").
- OOD 조건 : 잠재적인 뒤집기 횟수(뒤집거나 뒤집지않은 상황의 횟수)에 대해서 examplars와의 횟수를 다르게하여 수행
Results

PaLM 540B의 경우, chain-of-thought prompting는 거의 100%에 가까운 정답률을 보였다.
하지만 작은 모델의 경우 성능이 여전히 좋지않았다. 보이지 않는 규칙를 추상적으로 조작할 수 있는 능력은 모델 parameters의 규모가 100B에 달할 때만 발생한다.
6. Discussion
LLM을 통한 multi-step reasoning을 유도하기 위한 간단한 메커니즘으로 chain-of-thought prompting를 제시했다.
Section 3에서는 chain-of-thought prompting가 arithmetic reasoning에서 기존 SOTA와 비교해 큰 성능 향상을 기록했음을 확인했으며, 특정 annotators, exemplars, 언어 모델에 따른 영향을 받지않고 동일한 ablations, robustness를 가져온다는 사실을 확인했다.
Section 4에서는 commonsense reasoning에 대한 실험을 통해 chain-of-thought reasoning의 언어적 특성이 일반적으로 적용(상식 문제)될 수 있는지를 강조했다.
Section 5에서는 symbolic reasoning의 경우 chain-of-thought prompting가 더 긴 시퀀스 길이에 대한 out-of-domain에 대해서도 generalization를 용이하게 한다는 것을 보여주었다.
모든 실험에서 chain-of-thought reasoning은 기성 언어 모델에 적절한 프롬프팅을 제시하는 것만으로 유도되었으며, 별도의 fine-tuning을 진행 하지 않았다.
Standard prompting에서 크기를 키우더라도 성능향상이 이루어지지않던 (flat scaling curve) 많은 reasoning task에서, chain-of-thought reasoning을 사용했을 때 dramatically increasing scaling curves가 나타났다(크기를 키웠을 때 성능이 크게 향상).
Chain-of-thought prompting은 LLM이 성공적으로 수행할 수 있는 task의 범위를 확장하는 것으로 보인다(Figure 8을 보면, Letter concat과 같은 task는 기존 LLM이 거의 수행하지 못했으나, Chain-of-thought를 적용했을 때 100점에 가까운 점수).
즉, 본 연구는 standard prompting은 LLM의 기능에 대한 하한선을 제공할 뿐이라는 점을 강조한다(prompting에 따른 가능성이 무궁무진).
이러한 결과는 추후 연구해야할 과제를 제시하는데, 모델 크기만으로 reasoning 능력이 얼마나 더 향상시킬 수 있을까에 대한 기대와, 언어 모델이 해결할 수 있는 task의 범위를 확장할 수 있는 다른 promting 방법이 있을까에 대한 기대이다.
Chain-of-thought의 한계도 존재한다.
- 1) Chain-of-thought는 인간 의 사고 과정을 모방하지만, 신경망이 실제로 'reasoning'을 하는지 여부에 대한 해답을 제시하지 못한다.
- 2) Chain-of-thought의 exemplars를 수동으로 작성(증강)하는데 드는 비용은 few-shot 환경에서는 미미하지만, fine-tuning을 위한 annotation 비용이 많이 든다(synthetic data generation 또는 zero-shot generalization을 통해 해결할 가능성 있음).
- 3) 올바른 reaoning 경로를 보장할 수 없기 때문에, 오답이 모두 나올 수 있으며, 언어 모델의 factual generations(=성능)을 개선하는 것은 향후 해결해야할 연구 방향이다.
- 4) 일정 크기 이상의 LLM에서만 chain-of-thought이 작동하기 때문에, 실제 애플리케이션에 적용하기에는 비용이 많이 들며, 추가 연구를 통해 작은 모델에서 reasoning을 유도하는 방법을 모색할 수 있다.
7. Related Work
8. Conclusions
본 논문은 언어 모델의 reasoning 능력을 강화하기 위한 간단하고 방법으로 chain-of-thought reasoning을 제시한다.
arithmetic, commonsense, symbolic reasoning에 대한 실험을 통해 모델 크기(scaling)가 chain-of-thought reasoning의 새로운 속성이라는 사실을 발견했다.
즉, sufficiently(일정 크기 이상의) LLM에서는 chain-of-thought reasoning가 잘 작동했지만, 일정 크기가 도달하기 전까지는 chain-of-thought를 사용하더라도 성능향상이 미미했다(flat scaling curves).
언어 모델이 수행할 수 있는 reasoning task의 범위가 넓어지면, reasoning에 대한 language-based 접근방식에 대한 연구가 촉진될 것으로 기대된다.
