Abstract
1. Introduction
2. Related work
3. Methodology
3.1. Distilling step-by-step reasoning via CoT
3.2. Distilling step-by-step reasoning through SOCRATIC COT
3.2.1. Extracting the Reasoning Capability from the Teacher
3.2.2. Transferring the Reasoning Capability into the Student
3.3. Inference-time Predictions
4. Empirical Analysis
4.1. Datasets
4.2. Experimental Setup
4.3. Implementation Details
5. Results and Discussion
6. Ablation Studies
7. Conclusion
Self Q&A
Opinion
Abstract
chain of thought(CoT)와 같은 Step-by-step reasoning 접근법은 LLM에서 reasoning 능력을 유도하는데 매우 효과적인 것으로 입증되었다.
그러나 CoT의 성공 여부는 근본적으로 model size와 관련이 있으며, CoT가 작동하기 위해서는 billion parameter-scale 모델이 필요한 경우가 많았다.
본 논문에서는 larger 모델의 step-by-step CoT reasoning 능력을 활용하면서, 이 능력을 smaller 모델로 증류하는 knowledge distillation 접근 방식을 제안한다.
이 연구에서는 original problem을 sequence of subproblems으로 분해하여 학습하고 (subquestion이 생긴다는 점이 가장 큰 차이), 이를 intermediate reasoning steps을 guide하기 위해 사용하는(intermediate reasoning answer를 직접적으로 물어보는 subquestion이 생성되기 때문에 guide로 표현), alternative(CoT와 다른) reasoning scheme인 SOCRATIC CoT을 제안한다.
연구자들은 SOCRATIC CoT을 사용하여 2개의 small distilled 모델 조합(problem decomposer, subproblem solver)을 훈련시켰다.
이를 통해, 새로운 문제가 주어지면 2개의 distilled 모델이 동시에 작동하여 복잡한 문제를 분해(problem decomposer)하고 해결(subproblem solver)하도록 했다.
multiple reasoning datasets(GSM8K, StrategyQA, SVAMP)에서, SOCRATIC CoT는 baselines(answer only fine-tuning)과 비교했을 때 더 작은 모델의 성능이 70% 이상 향상되었다.
훨씬 더 작은 모델(GPT-2 large)이 10배 더 큰 모델(GPT-3 6B)을 능가하는 사례를 보여줌으로써, SOCRATIC CoT가 CoT의 효과적인 대안이 될 수 있는지에 대해 조사했다(CoT와 다르게 학습을 해야하지만).
- (코드는 아래 링크를 통해 확인 가능하다)
- https://github.com/kumar-shridhar/Distiiling-LM
1. Introduction
LLM은 다양한 reasoning tasks에서 강력한 성능을 입증해 왔다.
흥미로운 prompting 전략 중 하나는 chain-of-thought(CoT)로, 문제를 해결하는 동안 모델에 intermediate reasoning steps를 통합하도록 요청하여 LLM의 향상된 reasoning 능력을 이끌어 냈다.
그러나 CoT는 주로 hundreds billions parameters(일정 크기 이상의 모델) 모델이나, task-specific fine-tunined 모델에서 효과가 있는 것으로 나타났다.
즉, CoT-capable LLM을 위해서는, 상당한 computational 리소스 또는 API 호출이 필요하기 때문에, smaller 모델에서 reasoning 능력을 이끌어낼 수 있는지에 대해 연구를 진행했다.
Small-sized, non-fine-tuned 언어 모델은 추론 능력이 떨어지는 것으로 알려져 있다(poor reasoners).
따라서, smaller 모델에서 CoT-like reasoning 능력을 유도하기 위한 가능한 접근 방식은 step-by-step examples를 통해 fine-tuning하는 것이다.
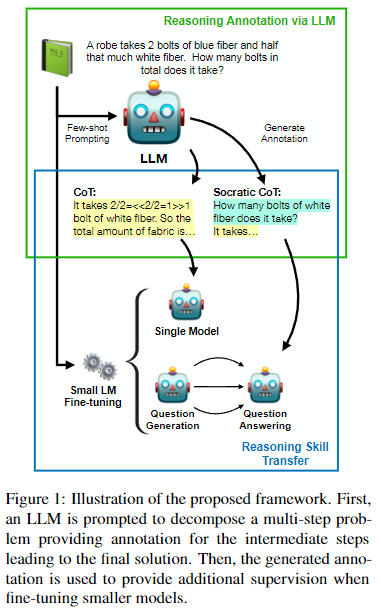
본 연구에서는 LLM의 reasoning 능력을 supervise로 활용하여 smaller 모델의 훈련시킬 수 있는 프레임워크를 제안한다.
이 접근 방식은 larger teacher 모델이 smaller student 모델에 지식을 전수하는 knowledge distillation의 한 형태로 생각할 수 있다.
그러나 standard knowledge distillation와 달리, 이 방법은 generated solutions만을 proxy로 사용해 teacher 모델의 reasoning 능력을 전수한다(즉, teacher 모델의 parameter를 직접 전달하지않고, 생성한 답안만을 활용).
논문의 접근 방식은, prompting을 통해 LLM이 final answer으로 이어지는 set of (sub)problems에 대한 step-by-step annotations을 생성하는 것으로 구성된다(Distilling Step-by-Step은 step 생성과정을 나누지않고 한번에 모든 step에 대해 생성했다면, 이 논문의 경우 step별로 하나씩 생성한다는 의미).
이 annotation은 student모델을 fine-tune하기 위한 supervision으로 사용된다.

이 프레임워크에서, distillation 접근법을 supervising하기 위한 3가지 유형의 annotation structure를 연구했다.
- (i) step-by-step solutions이 있는 datasets 대해, gold step-by-step solution procedure을 이용한 fine-tuning
- (ii) teacher 모델의 chain of thought(CoT)에서 나온 procedural supervision을 통한 fine-tuning
- (iii) SOCRATIC CoT
SOCRATIC CoT 접근법은, 2가지 모델을 사용하여 original problem를 sequence of subproblems-solution pair로 의미적(semantic)으로 분해하여 학습하는 것이다(Sec 3.2).
- a) (question generator) original problem을 sequence of subproblems로 분해하는 방법을 학습
- b) (question-answering model) 다양한 generated subproblems을 해결
이 접근 방식은 chain of thought reasoning의 extension으로 생각할 수 있는데, CoT와 달리 intermediate steps이 subquestion-solution pairs으로 분해되고, subquestions은 문제에 대한 final answer로 이어지는 intermediate steps의 생성을 유도한다(CoT는 subquestion없이 한번에).
3가지 multi-step reasoning datasets(GSM8K, StrategyQA, SVAMP)에 대해 분석을 수행한 결과, CoT-decomposed examples에 의한 supervision이 smaller 모델의 성능을 향상시키는 데 도움이 된다는 것을 확인했으며, SOCRATIC CoT에서 도입한 subquestioning은 더 큰 개선을 가져올 수 있음을 보여줬다.
LLM-generated step-by-step annotations으로 최대 40%의 성능 향상을 달성했으며, 이는 논문의 distillation 프레임워크(SOCRATIC CoT)의 효과를 입증한다(Sec 5).
2. Related work
Decomposing Multi-Step Reasoning Tasks
- 앞선 작업들은 프롬프트에 국한되어 있으며(CoT), billions of parameters의 LLM에서만 작동한다.
- 본 연구에서는 prompting solutions을 제안하는 것이 아니라(fine-tuning까지 진행), 각 step에서 sub-questions을 사용해 student 모델의 reasoning을 명시적으로 guide한다.
Knowledge Distillation
- 연구에서는 LLM을 사용하여 subquestions-solution pairs을 생성하고, 이를 함께 사용하여 smaller 모델에 reasoning 기능을 주입한다.
Subquestioning as supervision
- 연구에서는 multistep reasoning task에 초점을 두고 있다.
- intermediate clarifying questions과 reasoning steps은 항상 제공되지 않을 수도 있으며, teacher 모델에서 추출해야 할 수도 있다(human-label이 없는 경우 LLM을 teacher로 사용한다는 의미).
3. Methodology
setting은 data set 로 구성되며, 각 문제 에 대해서는, 여러 단계의 reasoning을 통해 도달할 수 있는 final answer 가 대응된다.
모델을 사용하여 문제를 푸는 task 는 로 나타낼 수 있다(gold label을 사용했을 경우 ).
solution의 intermediate annotations이 다른 형태(예: step-by-step, semantic decomposition by subquestions)로 제공되거나 존재하지 않을 수 있는 다양한 data scenar를 고려했다.
annotations이 있는 datasets인지에 따라, LLM을 사용하여 에 대한 small모델의 학습을 augment하는 다양한 접근 방식을 제안한다(annotations이 없으면 LLM generated annotations을 쓴다는 의미).
3.1. Distilling step-by-step reasoning via CoT
dataset에 answer 로 이어지는 intermediate reasoning steps을 포함하는 annotation(chain-of-thought annotation)이 존재하는 경우, 이 intermediate annotation을 small 모델을 fine-tune하는 데 직접 사용할 수 있다.
step-by-step information을 포함하지 않은 datasets의 경우, LLM을 사용하여 reasoning steps를 생성하고 이를 small 모델의 성능을 향상을 위해 사용해야한다.
(subsolution 생성)
이를 위해, dataset 의 극히 일부(subset)를 추출하여(prompting을 위한 exemplar로 활용하기 위해), 각 problem 에 대해 수동으로 개의 intermediate reasoning steps로 분해했다(in-context prompting를 위해 몇개의 examples만으로도 충분).
의 (exemplar로 활용한 subset을 제외한)나머지 각 problem 에 대해서는, LLM 에 intermediate reasoning step를 생성하도록 요청했다(subset이 examplar로 사용).
last solution이 ground truth answer과 일치하는지(step-by-step information을 포함하지 않은 datasets도 ground truth answer는 존재), 즉 인지 확인함으로써 chain of reasoning steps이 의미 있는지 확인했다.
last solution이 ground truth answer와 다른 경우, problem을 폐기하고 모델에 다시 prompting하여 new chain을 생성하도록 했다(maximum 3회).
앞선 과정을 통해, subset of problems과 sequence of reasoning steps이 짝을 이루는 augmented dataset 를 생성할 수 있다.
즉, step-by-step information을 포함하지 않은 datasets도 generated intermediate steps를 통해 reasoning 능력을 fine-tuning하여, smaller 모델로 distill할 수 있게 된다.
3.2. Distilling step-by-step reasoning through SOCRATIC COT
- 이 Section에서는 subquestioning을 통해 CoT를 향상시킬 수 있는 방법을 설명한다.


3.2.1. Extracting the Reasoning Capability from the Teacher
Section 3.1에서는 LLM을 사용하여 problem 의 answer 로 이어지는 intermediate step의 annotation(subsolution)을 생성하는 방법에 대해 설명했다.
Section 3.2에서는 solution의 각 step에 'subquestion'을 포함시키는 방법에 대해 다루겠다.
Section3.1에서 설명한 것과 유사한 절차에 따라, problems의 subset을 사용하여 few exemplars를 만들고, 이를 활용해 LLM이 prompting을 통해 problem을 intermediate subquestion-solution pairs의 집합으로 분해하는 능력을 갖도록 했다(subquestioning이 포함된 intermediate annotation을 얻는 과정).
~~- subquestion을 포함하는 datasets은 없으므로, step-by-step information을 포함하는 datasets에 대해서도 진행한 것 같음
~~
전체 solution을 구성하는 각 step 는, 각각 subquestion-solution pair가 되고, 로 표기된다(Figure 2).
- i는 의 problem index(몇 번째 problem인지)
- j는 의 step index (몇 번째 step인지)
problem 에 대한 subquestion-solution pairs를 정렬하면, 라고 할 수 있다.
3.2.2. Transferring the Reasoning Capability into the Student
LLM에서 제공하는 reasoning annotation을 smaller 모델로 distill하기 위해 두 가지 전략을 제시한다.
- 첫 번째 전략: single
unifiedstudent이 subquestion-solution pairs을 동시에 생성하도록 학습 - 두 번째 전략: question generation과 question-answering tasks를 two separate 모델로 학습
두 번째 전략을 iterative이라고 부르는데, 이는 question-answering 모델이 각 subquestion을 반복적으로 풀도록 학습되기 때문이다.
Unified
unified student 모델 는, chain of intermediate questions과 solutions을 포함하는 의 problems 를 사용하여, 주어진 problem의 solution을 맞추기 위한 subquestion-solution pairs 을 생성하는 방법을 학습한다.
pre-trained transformer-based model을 사용하여 각 문제 에 대한 chain of subquestion-solution pairs에 대해 훈련을 진행한다.
problem 의 step (즉, 와 의 concatenation)가 주어지면, 의 token sequence (즉, 1~j step에 대한 각 step별 subquestion-solution)에 대해, typical auto-regressive language modeling loss인 을 적용해 훈련을 진행했다:

여기서 는 context 가 주어졌을 때 가 token 에 할당하는 확률이고, 는 를 나타낸다.
loss 는 각 problem 에 대해, final answer 로 이어지는 각 쌍()에 대해 계산된다.
Iterative
Iterative 모델은, subquestions을 생성하는 모델(QG)과, 각 subquestions에 대한 intermediate answer을 제공(QA)하는 2개의 독립된 모델로 구성된다.
QG모델과 QA모델 모두 Transformer-based language model을 사용하여 구현되었다.
특히, QA모델 는 teacher-generated subquestions에 답하도록 반복적(한 step마다)으로 훈련된다(subquestions은 전부 LLM-generated이기 때문).
학습 objective는 각 intermediate solution에 대해 token level에서 계산된다:

여기서 는 길이, 는 intermediate solution 의 각 token을 나타낸다.
는 QA모델에 의해 반복적으로 생성된 이전 솔루션들로 구성된다.
마찬가지로, QG모델은 teacher 모델이 problem의 main question을 여러단계의 sub-steps(subquestion)으로 분해하는 능력을 습득하도록 훈련된다.
이 모델의 loss은 Equation 1과 유사하지만, QG 모델에서는 intermediate solutions이 고려되지 않는다는 점이 다르다(QA는 subquestion과 subsolution 모두 사용).
훈련과정에서는, QA모델에서 생성된 직전 step의 intermediate solutions을 대신 teacher-generated solutions을 사용하여 teacher forcing을 진행한다.
그러나 inference-time에는 모델에 의해 생성된 intermediate solutions이 사용된다.
3.3. Inference-time Predictions
새로운 problem 가 주어지면, unified student모델은 여러 단계의subquestions과 subsolution을 거치며 solution을 직접 예측할 수 있다.
iterative방식에서는, 먼저 에 대해서 QG모델을 이용해 subquestions을 생성한다(하나씩이 아닌 일괄생성).
subquestions이 생성되면, 각 step 에서 token 단위로 모델의 vocabulary에 대한 확률 분포에 따라(Language modeling한다는 의미) intermediate solution 를 디코딩(생성)한다.

여기서 는 greedy 방식으로 디코딩되는 번째 토큰을 의미한다.
4. Empirical Analysis
4.1. Datasets
- GSM8K
- StrategyQA
- SVAMP
4.2. Experimental Setup
-
3종류의 annotation을 사용했다(dataset의 annotation 유형).
-
Step-by-step solution(GSM8K): intermediate information이 있는 경우 subsolution으로 활용(없는 경우 LLM에 CoT 프롬프팅), intermediate subquestions은 모두 LLM(GPT-3)에 의해 만들어짐(LLM에 CoT 프롬프팅)

-
Supporting facts(StrategyQA): StrategyQA는 final answer가 참/거짓인 datasets.
-
질문에 대한 subquestion과 Additional supporting facts(subsolution)가 주어지지만, GSM8K처럼 매 step의 supporting facts가 final answer를 해결하는데 무조건 사용되지 않는 경우
-
따라서, 2가지 방법으로 나누어 학습을 진행했는데, 1)supporting facts를 CoT처럼 사용하여 LLM이 subquestion 생성(GSM8K과 유사) 2)subquestion을 LLM에 입력하여 sub facts(subsolution) 생성

-
Final answers only(SVAMP):
-
datasets에 final answer만 있는 경우, LLM을 통해 subquestion-solution pairs을 모두 생성
4.3. Implementation Details
student 모델로는 GPT-2-variants(Radford et al., 2019) 을 사용했다.
complex problems를 여러단계의 simpler substeps로 분해하기 위한 teacher 모델로는 GPT-3 175B(Brown et al., 2020) 를 사용했다.
모든 모델 NVIDIA Tesla A100 40GB GPU에서 Huggingface library를 사용하여 훈련되었다.
각 실험은 validation set에 대한 주기적인 평가를 통한 공정성을 보장하기 위해, 동일한 횟수의 반복으로 실행되었다.
훈련 중에는 생성된 답변을 훈련 데이터 세트의 ground truth answers으로 대체하는 Teacher forcing 학습을 적용했다.
5. Results and Discussion
Can our framework improve the reasoning capabilities of smaller models?

- 대부분의 datasets에 대해서 resoning 결과 개선
- StrategyQA의 경우 큰 모델(1.5B)에서 로 fine-tuning한 방법이 774M모델보다 성능이 떨어지는 결과(반대로 GT Facts만으로 fine-tuning 했을 때 규모가 커질수록 성능이 향상)
Step-by-Step Solution(GSM8K)
- human-annotated step-by-step solutions이 존재하는 GSM8K()의 경우 LLM-generated CoT는 효과적이지 않았는데,
- 수학문제를 푸는 과정에서 생성하는 intermediate step이 CoT에서 제대로 생성되지 않았기때문이라고 생각한다(CoT paper에서 100B 이상이여야 효과적이었다고 언급).
Supporting facts(StrategyQA)
- ground-truth supporting facts를 포함하는 StrategyQA의 경우, CoT를 생성하도록 한 결과가 Answer만으로 fine-tuning한 것보다 결과가 좋지 않았다(60.51->58.07).
- 또한, GT Facts만으로 fine-tuning했을 때, 모델의 크기가 작을 때(355M)는 Answer만으로 fine-tuning한 것보다 결과가 좋지 않았지만, 774M 이상에서는 크기가 커질수록 성능이 향상되었다.

Answers only(SVAMP)
- final answer만 있고, intermediate annotation이 없는 경우(SVAMP), subquestions이 없는 CoT와 subquestions이 있는 모두에서 성능 향상으로 이어졌다.
- 이 경향은 StrategyQA에서 관찰된 것과 유사하지만, 774M을 넘어갔을 때 SOCRATIC COT의 성능이 오히려 CoT보다 떨어졌다(supporting fact가 무조건적으로 final answer로 이어지지않기 때문에, fine-tuning까지 할 경우 noise가 주입되는 것 같음).
Can SOCRATIC COT be used as a prompting strategy?
- SOCRATIC CoT를 fine-tuning이 아닌, in-context learning으로 활용했을 때에도 성능향상이 있을지에 대해서도 실험한 결과,
- 기존 CoT보다 성능향상이 있었다.
- (제한된 리소스로 인해 examplar를 1개만 사용하는 1-shot으로 비교했지만, CoT의 경우 8개였을 때 performance가 가장 높았으므로, 추가적인 검증이 필요해 보인다).

6. Ablation Studies
이 Section에서는, 우리가 제안하는 프레임워크의 specific components에 대한 추가 분석과, SOCRATIC CoT의 부정적인 결과에 대해 설명한다.
How good are the sub-questioning capabilities of a smaller model?
GPT-3에 의해 생성된 step의 수가 annotation의 step 수와 얼마나 일치하는지에 대해 평가했다.

그 결과, 대부분의 fine-tuned GPT-2(smaller 모델)가 잘못된 수의 subproblem(step)을 예측하는 것으로 나타났기 때문에, problem 에 대한 subquestion의 생성을 의 intermediate solutions를 설명하는 equations을 도입했다(guidance mechanism).
이 전략은 3가지 metric 모두에서 개선된 성능을 가져왔다(probelem을 분하는 품질 개선).

Eliminating the need for a subquestion module

- QG model을 사용하지않은 결과(QA만 가용), 상당한 성능 저하를 초래했다.
- 이를 통해 inference시 하위 질문의 필요성을 확인했다.
Example outputs
- GSM8K, SVAMP에 대해 GPT-2 모델이 예측한 example ouput


7. Conclusion
LLM에 chain-of-thought style of step-by-step를 사용하는 것은 reasoning에 매우 효과적인 것으로 입증되었다.
본 연구에서는 LLM의 reasoning 능력(chain-of-thought style of step-by-step)을 smaller 모델로 distill하는 방법을 제안한다.
추가적으로 step별로 subquestion을 생성함으로써(QG모델), 이를 더욱 개선시킬 수 있는 방법을 제안했다.
3가지 인기 있는 multi-step reasoning datasets에 대해, 제안한 방법론의 효과를 입증하고였다.
Limitations
본 연구에서는 student 모델에 정보를 distill하는 과정에서 LLM으로부터 하나의 solution만 추출했다(voting을 사용하여 가장 빈번한 subquestion-solution pairs을 사용하는 방법이 있었다.)
또한, 1-shot을 통해 CoT와 SOCRATIC COT를 비교했는데, 더 많은 examplar(최대 8개)를 사용하면 더 공정한 비교와 더 나은 결과를 얻을 수 있었을 것이다.
Ethical Considerations
이 작업을 통해 smaller 모델의 reasoning 능력이 향상되었지만, education과 같은 민감한 환경에서 사용하기에는 아직 충분히 강력하지 않다.
