voting은 ensemble 기법의 일종으로, 여러 weak learner들의 결과를 말그대로 투표를 통해 최종 결정하는 방법이다. 크게 hard voting과 soft voting으로 나눌 수 있다.
Hard voting
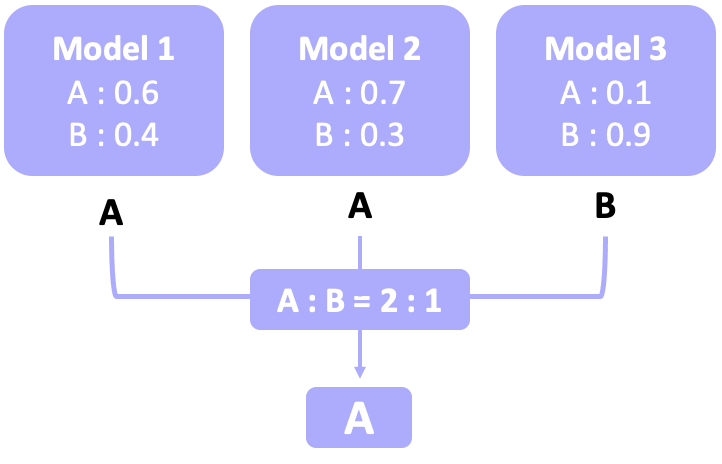
hard voting은 위의 그림에서 볼 수 있듯이, 가장 많은 weak learner가 선택한 분류를 선택하는 것이다. 모델 1과 모델 2가 A로 분류했고, 모델 3만 B로 분류했으므로, 최종적으로 A로 분류하는 것이다.
Soft voting
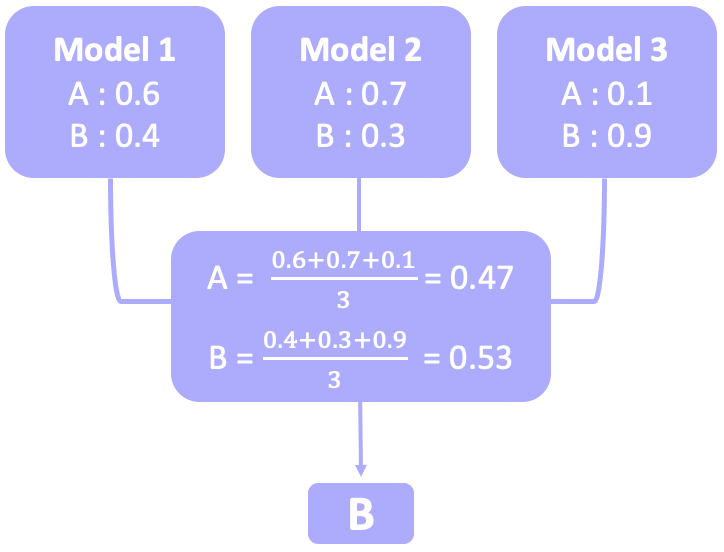
soft voting은 각 분류 확률의 평균으로 판단하는 것이다. 모델 1이 A로 분류할 확률 0.6, 모델 2가 A로 분류할 확률 0.7, 모델 3이 A로 분류할 확률은 0.1이므로, 이를 평균 내면 A로 분류할 확률은 0.47이다. 모델 1이 B로 분류할 확률 0.4, 모델 2가 B로 분류할 확률 0.3, 모델 3이 B로 분류할 확률 0.9이므로 이를 평균내면 B로 분류할 확률이 0.53이다. 평균을 냈을 때 B가 확률이 더 높으므로, 최종적으로 B로 분류하게 된다.
언제 어떤 방식을 이용할까?
| Hard voting | Soft voting | |
|---|---|---|
| 방식 | 다수결 | 평균 확률이 높은 클래스 선택 |
| 모델 confidence 반영 | ❌ | ✅ |
| 계산 비용 | 적음 | 큼 |
| 적합한 데이터 | 균형 잡힌 데이터 | 불균형 데이터 |
| 적합한 모델 조합 | 개별 모델 성능이 유사할 때 | 모델 간 성능 차이가 클 때 |
sklearn의 voting classifier
# weak learner 정의
# Logistic Regression
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
# XGBoost
from xgboost import XGBClassifier
xgb = XGBClassifier()
# Random Forest
from sklearn.ensemble import RandomForestClassifier
random = RandomForestClassifier()
# Extra Tree
from sklearn.ensemble import ExtraTreesClassifier
extra = ExtraTreeClassifier()
# Voting amongst above 4 models
from sklearn.ensemble import VotingClassifier
voting = VotingClassifier(estimators = [('Logistic Regression', logreg),
('XGBoost', xgb),
('Random Forest', random),
('Extra Trees', extra)],
voting='hard')
# voting = 'hard' -> hard voting
# voting = 'soft' -> soft voting
# score
# x_train = training set
# y_train = training set의 정답 데이터
score = cross_val_score(voting, x_train, y_train, cv=5, scoring='accuracy')
print(score)
Let it code