ML practice
1.머신 러닝 실습 1. 필기 인식하기

scikit-learn을 이용해서 필기로 쓰인 숫자를 컴퓨터가 인식할 수 있도록 학습시켜보자.'''pythonfrom sklearn.datasets import load_digitsdigits = load_digits()'''https://scipy-lectu
2024년 1월 7일
2.머신 러닝 실습 2. 타이타닉 문제 해결하기
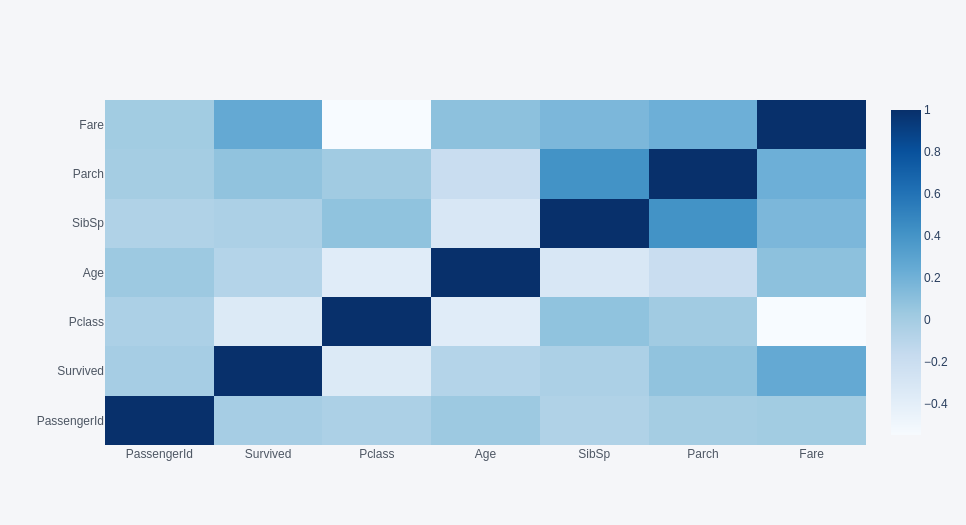
Titanic - Machine Learning from Disaster 타이타닉 문제는 머신 러닝 초심자가 가장 먼저 접하며 머신 러닝의 개념을 익히는 기초적인 문제이면서, 고차원적으로 접근하려면 끝이 없는 문제라고도 한다. 타이타닉 문제는 영화 타이타닉으로 유명한
2024년 1월 11일
3.머신 러닝 실습 7. Iris

Iris 데이터는 붓꽃의 3가지 종류(setosa, versicolor, virginica)의 꽃잎의 길이, 꽃잎의 너비, 꽃받침의 길이, 꽃받침의 너비 정보가 있는 데이터이다.(petal = 꽃잎, sepal = 꽃받침)Iris 데이터는 scikit-learn에서 아
2025년 4월 7일
4.머신 러닝 실습 8. 올리베티 얼굴 데이터셋

올리베티 얼굴 데이터셋은 1990년대 AT&T 연구소에서 만든 얼굴 데이터셋이다. 40명의 얼굴을 각각 다른 표정, 각도 등으로 10장씩 촬영하여 총 400장의 얼굴 이미지로 구성되어 있다. 하나의 이미지는 64 x 64의 흑백 이미지이다. 올리베티 얼굴 데이터셋은 s
2025년 4월 9일