Titanic - Machine Learning from Disaster
타이타닉 문제는 머신 러닝 초심자가 가장 먼저 접하며 머신 러닝의 개념을 익히는 기초적인 문제이면서, 고차원적으로 접근하려면 끝이 없는 문제라고도 한다.
타이타닉 문제는 영화 타이타닉으로 유명한, 타이타닉 호 침몰 사건에서 승선자들의 정보를 이용하여 생존 여부를 예측하는 것이다.
머신러닝 문제해결 루틴
어떤 머신 러닝 문제든 간에, 대개는 아래의 단계들을 거치며 해결하게 된다.
- 데이터 수집
- EDA
- feature engineering
- 모델링
- 학습 및 예측
- 성능 평가
1. 데이터 수집
타이타닉 문제는 kaggle에 업로드 되어 있다. 따라서 아래 명령어를 이용해서 타이타닉 문제를 해결하기 위한 데이터를 받아오자.
kaggle competitions download -c titanic2. EDA
위 명령어를 이용하면 총 3개의 csv 파일이 받아진다.
train.csv = 학습시키기 위해 생존 여부 정보가 포함된 데이터
test.csv = 성능을 평가하기 위해 생존 여부 정보가 포함되지 않은 데이터
gender_submission.csv = kaggle에 제출할 예시 파일 (나중에 다시 정리)
아래 코드와 같이 이 파일들을 읽어서 EDA를 해보자.
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')우선적으로 할 일은 이들의 column description을 살피는 것이다. 타이타닉 문제를 업로드한 kaggle 페이지를 보면 (https://www.kaggle.com/c/titanic/data) Data 탭에서 방금 받은 파일들과 그 파일들의 column이 어떤 의미인지 설명해주고 있다. (Data Dictionary, Variable Notes)
다음으로 데이터의 shape이 어떻게 되는지 살핀다.
print(train.shape)
print(test.shape)raw 데이터에는 결측치가 포함된 경우가 많으니 이 결측치가 어느 column에 얼마 만큼 있는지 파악하는 것도 중요하다. pandas data frame의 attribute 중 .info()는 각 column의 결측치가 아닌 (Non-Null) 행의 수와 데이터 타입 (Dtype) 을 알려준다.
print(train.info())
print(test.info())
그리고 각 column의 값이 대략 어떤 값을 가지고 있는지 통계치를 알아보자. 자료의 정보를 알려주는 5가지 수치를 5가지 요약 수치 (Five-number summary) 라고 한다.
- 최솟값 (sample minimum)
- 제 1사분위수 (1st quartile) : 하위 25% 에 해당하는 값
- 제 2사분위수 (2st quartile = median) : 하위 50% 에 해당하는 값
- 제 3사분위수 (3rd quratile) : 하위 75% 에 해당하는 값
- 최댓값 (sample maximum)
이는 간단히 pandas data frame의 attribute 중 .describe()를 이용하여 파악할 수 있다.
print(train.describe())
print(test.describe())여기에 평균, 특이값(outlier)까지 추가로 알아본다.
2-1. 시각화를 통한 EDA
training set의 heat map을 그려보자. heat map이란, 2차원 데이터에서 변수 간의 상관 관계를 색상 타일을 이용해서 나타내는 것이다.
import chart_studio.plotly as py
import cufflinks as cf
cf.go_offline(connected=True) # 오프라인에서 실행되게 하는 함수 = Jupyter notebook과 연결
train.corr().iplot(kind='heatmap', colorscale='Blues')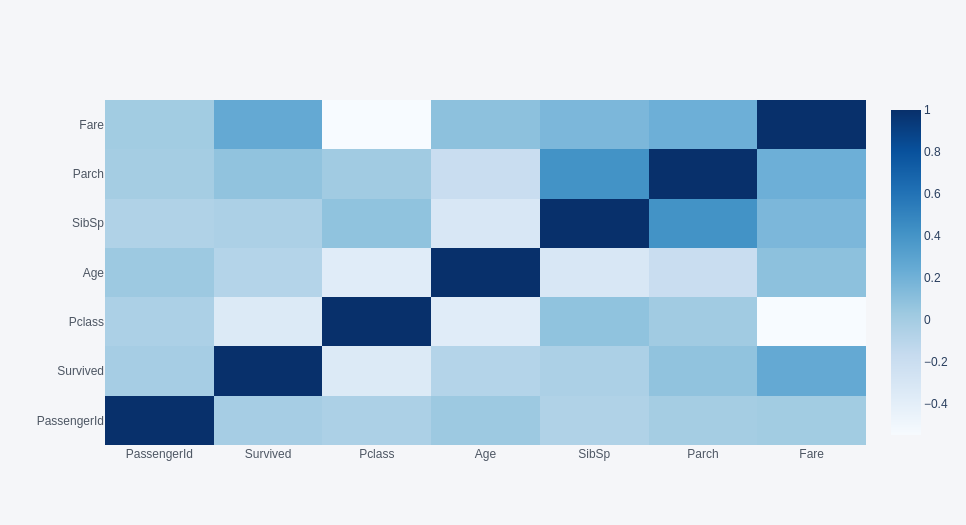
위의 코드를 실행하면, 데이터 타입이 string이 아닌 (float, integer) column 들 사이의 상관 관계를 보여주는 heat map이 그려지게 된다. Jupyter notebook에서는 각 타일에 마우스를 올렸을 때 x, y, z(상관 관계를 나타내는 수치)가 무엇인지 표시도 해 준다. 진한 파란색으로 나타날수록 (수치가 1에 가까울수록) 각 변수 사이의 상관 관계가 강한 것이고, 색이 연할수록 (수치가 작을수록) 각 변수 사이의 상관 관계가 약한 것이다. 대각선 방향의 타일이 모두 진한 파란색인 이유는 같은 변수끼리의 상관 관계를 봤기 때문이다. 여기서는 대략 (Fare, Survived) 등이 상관 관계가 강하고, (Fare, Pclass) 등이 상관 관계가 약하다는 식으로 파악할 수 있다.
다음으로, 특정 feature에 따른 생존 비율도 살펴보자.
survived = train[train['Survived']==1]['Sex'].value_counts()위와 같이 코드를 실행하면 생존한 사람들의 성비를 확인할 수 있다.
이외에도 다른 feature들도 확인해보자. 그리고 각 데이터를 잘 표현할 수 있는 시각화도 해보자. (ex) 막대 그래프)
3. feature engineering
EDA를 통해서 데이터의 특성과 변수 간의 상관 관계를 파악했으면, 이제 머신 러닝을 할 수 있도록 데이터를 가공하는 단계에 들어선다.
-
training set과 test set 합치기
test set까지도 같이 가공해야 하기 때문에 pd.concat()으로 training set과 test set을 합치자. (단, 나중에는 다시 분리해야 하기 때문에 어디까지가 training set인지 test set이고 구분은 할 수 있어야 한다.) -
범주형 데이터들 중 수치로 변화할 수 있는 것은 수치로 변환하기
ex) 'Sex' column을 'male' = 1, 'female' = 2로 변환하기 -
결측치를 적당한 값으로 바꾸기
여기서 "적당한"이라고 함은 적절한 추론이 요구되는 것이다. 임의로 값을 채워넣기 보다는 다른 column 정보나 도메인 지식 등을 이용하여 추론하여 입력한다. 예를 들면 'Pclass' column에 결측치가 있다면, 같은 행의 'Fare' 항목을 보고 값이 비싸다면 'Pclass'가 1등급이었을 것이라고 추측하여 그 값으로 채워넣는 것이다. 도저히 추론하기 힘들 때는 median 값을 사용하는 것도 하나의 방법이다. 분명한 것은 본격적으로 학습을 할 때에 nan 값이 남아있으면 정확한 학습에 방해가 되므로 nan 값을 그대로 두지말고 'Unknown' 등의 이름으로라도 범주화를 해둬야 한다는 것이다. -
필요없어 보이는 자료는 과감하게 삭제하기
예를 들어 탑승자 이름과 생존율은 전혀 상관 관계가 없을 것이니 아예 'Name' column 자체를 삭제한다. -
수치형 데이터를 범주화하기
'Age' 같은 경우를 예로 들면, 1살 차이가 난다고 해서 생존율이 크게 차이 나지는 않을 것이다. 그렇다면 10대, 20대, 30대,... 정도로 (숫자)범주화 하는 것이 더 경향성을 잘 보이고 머신 러닝에서 적용하기도 좋을 것이다. -
EDA 과정을 통해 분석한 경향성을 바탕으로 'High chance feature' column과 'Low chance feature' 만들기
EDA 과정을 거치며 높은 등급의 좌석에 탑승할수록, 나이가 어릴수록, 여성일수록, 신분이 높을수록 생존율이 높다는 것을 파악했다. 따라서 이에 해당하는 사람들에 High chance feature 수치를 매긴다.
또한 낮은 등급의 좌석에 탑승할수록, 나이가 많을수록, 남성일수록 생존율이 낮다는 것을 파악했다. 따라서 이에 해당하는 사람들에 Low chance feature 수치를 매긴다.
- 인코딩 (encoding)
일반적인 머신 러닝 알고리즘은 숫자를 기반으로 예측하므로, string 데이터가 있다면 숫자로 변환해주어야 하는데 이를 인코딩이라고 한다. 인코딩에 대한 자세한 내용은 인코딩 포스팅에서 참고하자.
4. 모델링
다양한 모델을 이용하여 training set으로 cross validation 작업을 해서 어떤 모델이 잘 학습되는지 확인하고, hyperparameter tuning 작업을 하면서 모델에 들어가는 적절한 파라미터 값을 찾는다.
5. 학습 및 예측
4번 단계에서 선정한 가장 성능이 좋은 모델과 그 모델에 들어가는 최적의 hyperparameter 값을 입력해서, training set으로 학습을 하고 test set으로 예측을 한다. 이 때 단일 모델의 성능이 좋다면 단일 모델로 학습 및 예측을 할 수도 있지만, 여러 모델을 이용한 다음 voting을 통해서 최종 결과를 낼 수도 있다. (→ voting)
6. 성능 평가
test set으로 예측을 해서 결과를 냈으면, 이제 kaggle에 제출해서 점수를 확인해보자. kaggle titanic competitions의 overview 탭 아래쪽에 보면, 결과를 제출하는 방법을 알려준다. 제출하는 파일의 포맷이 정해져 있으므로 정해진 포맷으로 수정해서 업로드하자. 홈페이지에서 Submit Prediction 버튼을 눌러서도 업로드할 수 있지만, 터미널에서 명령어로도 업로드 할 수 있다.
kaggle competitions submit -c titanic -f result.csv -m "Test"그러면 몇 초 후 페이지에서 나의 점수를 확인할 수 있다. Leaderboard 탭에 이 competition에 참여한 사람들의 점수와 순위가 기록되어 있는데, 그것을 바탕으로 내가 상위 몇 %에 속해있는지 판단할 수 있다.
References
https://www.kaggle.com/c/titanic/data
https://en.wikipedia.org/wiki/Five-number_summary
https://velog.io/@astrhhn/Hmap
