AI 서비스를 배포할 때, 최적의 성능을 갖춘 모델을 서빙하는 것이 가장 중요하다. 이를 위해서는 끊임없이 모델의 성능을 평가해야 할 것이다.
모델을 평가하는 방법은 평가하는 환경에 따라 크게 offline과 online으로 나눌 수 있다.
Offline 모델 평가
Offline 모델 평가는 배포하기 전, 모델 학습의 결과가 내는 성능을 실험적으로 확인하는 것이다. 과거 데이터 셋을 이용한다.
hold-out validation
k-fold cross validation
bootstrap resampling
중복을 허용하여 원본 데이터 셋에서 샘플을 랜덤하게 추출하여 여러 개의 부분 집합을 생성한다. 이 부분 집합들로 모델을 반복적으로 훈련 및 평가해서 일반화 성능을 평가하게 된다.
Online 모델 평가
Online 모델 평가는 모델을 실제 환경에 배포한 후 실시간 데이터(실제 사용자 데이터)를 기반으로 성능을 평가하는 방법이다.
AB test
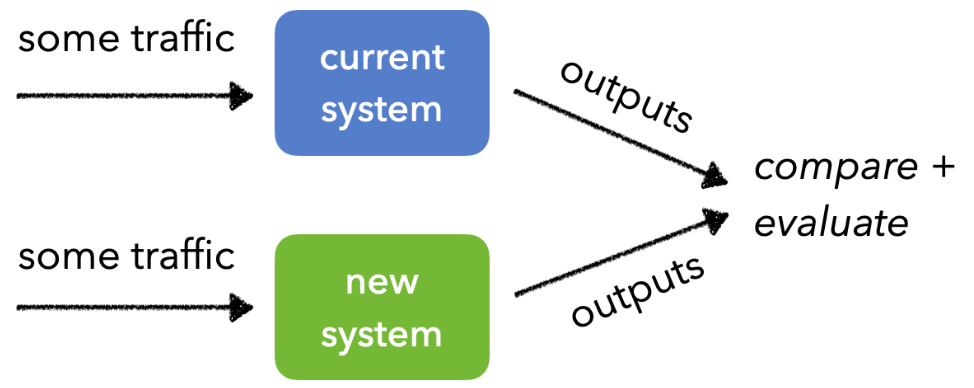
모델의 현재 버전과 새로운 버전(혹은 여러 버전)을 동시에 배포하여 성능을 비교하는 방법이다. 각 사용자 그룹은 한 가지 버전만 경험하며, 결과를 기반으로 어떤 버전이 더 나은 성능을 보였는지 평가한다.
장점
- 실제 사용자 데이터를 기반으로 성능 차이를 직접적으로 확인할 수 있다.
- 통계적으로 분석하여 신뢰성을 보장할 수 있다.
- 실제 사용자 행동을 관찰함으로써 실질적인 효과를 평가할 수 있다.
단점
- 충분한 데이터를 수집하려면 시간이 오래 걸릴 수 있다.
- 사용자 집단을 나누는 과정에서 기존 사용자 경험이 방해될 수 있다.
Canary test
새로운 모델이나 시스템을 소규모 사용자 집단(“카나리아 그룹”)에게 먼저 배포하여 안정성을 평가하는 방법이다. 문제 없이 작동하면 점차 사용자 규모를 확대한다.
장점
- 초기 단계에서 문제를 발견하여 전면적인 서비스 장애를 방지할 수 있다.
- 소규모 사용자 그룹으로부터 빠르게 피드백을 수집할 수 있다.
- 새로운 시스템으로의 전환이 점진적이므로 리스크가 감소한다.
단점
- 모든 사용자에게 새 모델을 배포하기까지 시간이 오래 걸릴 수 있다.
- 초기 카나리아 사용자 그룹이 전체 사용자 집단을 대표하지 않을 수 있다. (→ sample bias)
Shadow test
새로운 모델을 실제 서비스에 반영하지 않고, 실시간 트래픽을 복사해 새로운 모델의 성능을 평가하는 방법이다. 기존 모델이 사용자 요청을 처리하는 동안 새로운 모델도 같은 요청을 처리하지만, 결과는 실제 사용자에게 노출되지 않는다.
장점
- 실제 사용자 경험에 영향을 미치지 않는다.
- 실시간 데이터를 사용하므로 실제 운영 환경에서 성능을 검증할 수 있다.
- 모델의 성능 문제를 사전에 발견하고 수정할 수 있다.
단점
- 트래픽 복사 및 모델 평가를 위한 추가 리소스가 필요하다.
- 실제 사용자 반응이 피드백을 직접적으로 수집할 수 없다.
⇒ offline 평가와 online 평가를 반복하면서 최적의 모델을 서빙할 수 있도록 지속적으로 개선하는 것이 중요하다.
References
https://madewithml.com/courses/mlops/evaluation/#canary-tests
https://mercari.github.io/ml-system-design-pattern/QA-patterns/README_ko.html
