Dynamic Disjoint Set을 관리하기 위한 자료구조를 알아보자.
Disjoint Sets
의 집합들이 존재할 때, 어떤 에 대해 { } 인 경우에 를 Disjoint Sets 이라고 한다.
- collection of disjoint sets
- { } 인 경우, S를 collection of disjoint sets 이라고 한다.
- representative member
- 에서, 각 집합 내에서() 그 집합을 대표하는 하나의 숫자.
Dynamic Disjoint Sets
Dynamic: 집합이 변한다.
collection of dynamic disjoint sets에서 집합이 변화하는 유형
- 새로운 집합이 추가됨. (created)
- 두 집합이 하나의 집합으로 합쳐짐. (united)
Disjoint Set Operations
MAKE-SET(x)
- x를 representative member로 하는 새로운 집합을 생성한다.
UNION(x, y)
- x, y가 속한 두 집합을 합친다.
FIND-SET(x)
- x를 element로 포함하는 집합의 representative member를 찾는다.
Disjoint set data structures
Disjoint set operations을 이용하여 collection of dynamic disjoint sets을 관리하는 자료구조.
1. Linked List Representation
- 하나의 set은 하나의 Linked List로 표현된다.
- object: 하나의 Linked List에 연결된 set member
- 하나의 Linked List에서 나타나는 object의 순서는 상관이 없다.
- set object: 하나의 Linked list를 시작하는 pointer
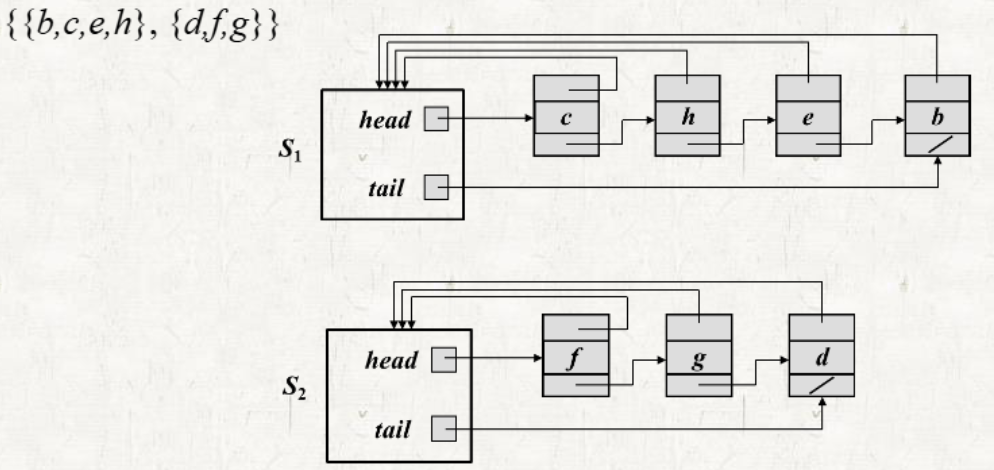
- head: 첫 번째 object를 가리킨다.
- 첫 번째 object는 representative.
- tail: 마지막 object를 가리킨다.
- 모든 object는 set object를 가리킨다.
Operations in linked list
-
MAKE-SET(x)
- x: member
- object가 x뿐인 새로운 Linked list 생성.
-
FIND-SET(x)
- X: Pointer to an set object
- X가 가리키는 set object를 확인한 후, set object의 head가 가리키는 member를 리턴
return X.set -> head -
UNION(x, y)
- X, Y: Pointer to each set object
- Y set을 X set에 이어 붙인다.
- Y member의 set, X의 tail, X의 last member의 next를 변경해야한다.
return X.set -> tail -> next = Y.set -> head return X.set -> tail = Y.set -> tail for each V ∈ Y.set return V.set = X.set
2. Forest Representation
- 하나의 집합은 하나의 tree로 표현된다.
- 각 member는 자신의 parent를 가리킨다.
- Root member: self loop를 가지고, representative member이다.
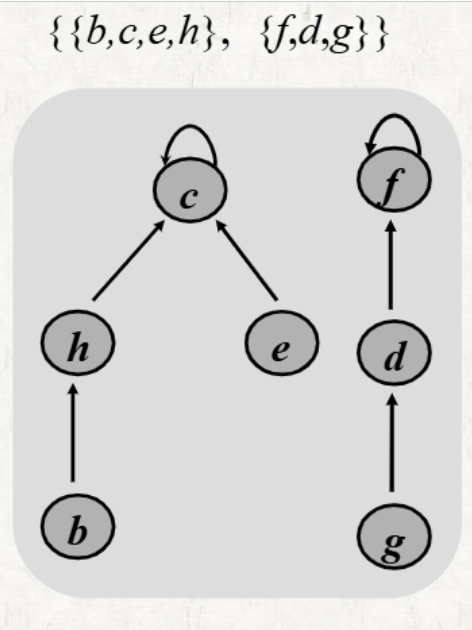
Operations in linked list
MAKE-SET(x)
x.p = x //self loop를 갖도록, x는 objectFIND-SET(x)
if x == x.p //self loop라면
return x;
else
return FIND-SET(x.p)UNION by Rank
Basic Idea: Shorter tree를 higher tree에 연결하자.
Rank: 트리 높이의 최대 상한선으로, UNION by Rank를 위해 각 member가 사용한다.
- Rank가 작은 것을 Rank가 큰 것에 연결한다.
MAKE-SET(X)
x.p = x
x.rank = 0FIND-SET(x)
if x == x.p //self loop라면
return x;
else
return FIND-SET(x.p)LINK(x, y) //x, y: root of each tree
if x.rank > y.rank
y.p = x
else
x.p = y
if x.rank == y.rank
y.rank = y.rank + 1UNION(x, y)
LINK(FIND-SET(x), FIND-SET(y))Path compression
- 각 member가 parent를 가리키던 것을 root member를 가리키도록 바꾼다.
- Path compressiong 이후, FIND-SET(x)의 실행 시간이 압도적으로 줄어든다.
- 보통 FIND-SET(x) 수행 시, 계산의 효율성을 위해 Path Compression이 처리되는 경우가 많다.
- UNION 연산시에만 FIND-SET()을 사용하는데 UNION을 빠르게 처리할 수 있도록 해준다.
FIND-SET(x)
if x != x.p //x가 root가 아니라면
x = FIND-SET(x.p);
else
return x.pRunning time analysis
기본 가정
- #Total operations:
- #MAKE-SET operations:
- #UNION operations:
- #FIND-SET operations:
- 개의 operations 중 처음 n개는 MAKE-SET operation 이다.
- 개의 MAKE-SET operation으로 생기는 집합은 개이다.
- 각 집합은 하나의 element만을 가지고 있다.
- UNION operation은 집합의 개수를 하나씩 줄인다.
- 이라면 개의 element를 지닌 하나의 집합만이 존재하게 된다.
Running time of Linked list
-
UNION (x, y)
- : Set Y의 object 개수
- Changing tail poiner & linking two linked lists:
- Changing pointers to the set object:
- Y set의 모든 member가 가리키는 set을 변경해야하기 때문이다.
-
Total Running time of operations
개의 MAKE-SET(x): x
개의 FIND-SET(x): x- Simple implementation of union
- worst case: and 긴 Linked list를 짧은 Linked list에 연결한다.
- UNION: x
- Total
- Weighted-union heuristic
- 짧은 Linked list를 긴 Linked list에 연결하는 경우
- 이 경우, Worst case는 UNION할 두 set의 #member가 동일한 경우이다.
- UNION의 결과인 set의 #member는 최대 2배씩 늘어날 것이다.
- Length: x x x =
- : UNION 연산의 개수 (= #set object pointe update)
- Simple implementation of union
Running time of Forest
Path compression 과 Union by rank 를 이용하여 트리의 높이가 불필요하게 높아지지 않도록 유지한다.
: 매우 느리게 증가하는 함수
- 현실적인 상황에서는 대부분 이다.
FIND-SET(X):
UNION(X, y):
Total Running time:
- 개의 operation
- 라면,
Application of Disjoint Set data structures
Connected Component의 개수를 세는 데에 사용이 가능하다.
connected components (CC)
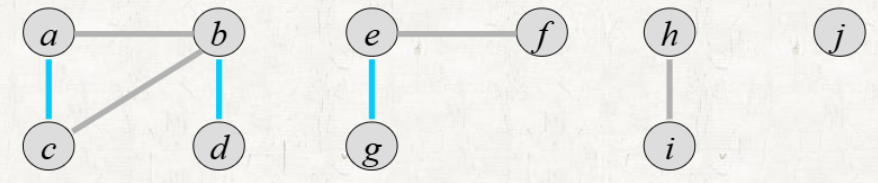
- 연결 요소에 속한 모든 정점을 연결하는 경로가 있어야 한다.
- 다른 연결 요소에 속한 정점과 연결하는 경로가 있으면 안된다.
Static graph
Set이 변하지 않는 경우로, DFS를 사용하여 connected components computing 해도 무방하다.
- Depth-first search:
Dynamic graph
Set이 변하지 않는 경우로, DFS를 사용하여 connected components computing 하게 되면 비효율적이다.
- 비효율적인 이유: collection of sets이 변화할 때마다 전체 DFS를 다시 수행해야하기 때문이다.
- 즉, 추가적인 가 필요하다.
대신, Disjoint Set data structure 를 이용한다면 효율적이다.
Running time of counting connected component
1. New Edge 가 추가되는 경우
- DFS:
- Disjoint Set data structure: UNION()
2. New Set 이 추가되는 경우
- DFS:
- Disjoint Set data structure: UNION()
Pseudo code of Computing connected components
CONNECTED-COMPONENTS(G)
1. for each vertex v ∈ G.V
2. MAKE-SET(v)
3. for each edge(u, v) ∈ G.E
4. if FIND-SET(u) != FIND-SET(V)
5. UNION(u, v)line 1 ~ 2: Element가 하나인 집합 |V|개 생성
line 3 ~ 5: 가 같은 집합에 존재하는지 확인하고 아니라면 둘을 합친다.
SAME-COMPONENT(u, v)
1. if FIND-SET(u) == FIND-SET(v)
2. return TRUE
3. else
4. return FALSE