Weighted Undirected Graph
모든 edge가 weight 를 가지는 그래프
Spanning Tree
그래프에 존재하는 모든 vertex를 포함하는 tree
- Tree이기 때문에 Acyclic, Connected
- 하나의 그래프에 대해 가능한 Spanning tree는 여러 종류가 있다.
- Minimum Spanning tree인 경우에는 정확히
Cost of Spanning tree
Minimum Spanning에Tree
Cost()가 최소인 spanning tree
GENERIC-MST(G, w)
1. A = ∅
2. while A does not form a spanning tree
3. do find an edge (u, v) that is safe for A
4. A = A ∪ {(u, v)}
5. return A- Line 4에서 추가되는 는 safe edge라고 한다.
Minimim Spanning Tree Algorithm
대표적인 두 개의 알고리즘이 존재한다.
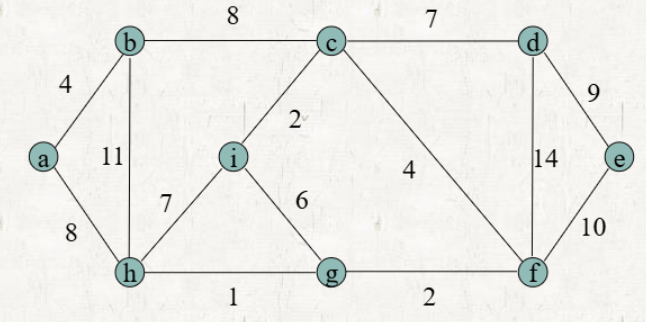
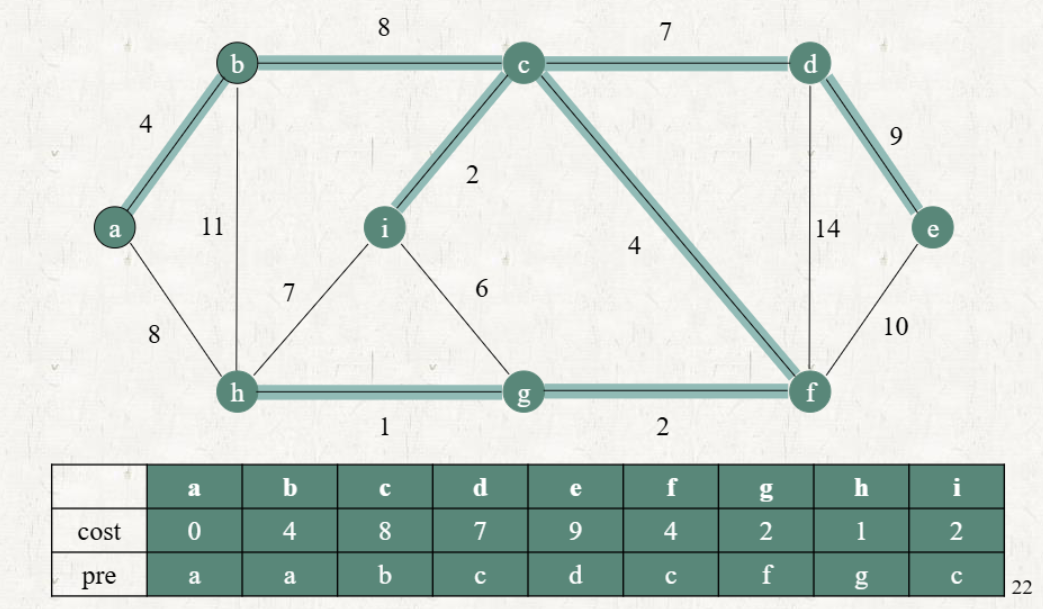
Prim's Algorithm
cost: Distance from the current tree
pre: Parant node
과정
-
초기 세팅
- 루트 노드의 cost = 0, 나머지 노드의 cost =
- 루트 노드의 pre = 자기 자신 (self loop), 나머지 노드의 pre는 설정하지 않는다.
-
선택된 노드로부터 인접한 vertex까지의 weight를 해당 vertex의 Cost에 저장한다.
- 이미 저장되어 있는 Cost가 존재한다면, 기존 cost보다 weight가 작은 경우에만 업데이트한다.
-
남아있는 vertex에 대해 Cost가 가장 작은 vertex로의 edge를 tree에 추가한다.
- 선택된 vertex는 따로 표시해놓고 다시 사용하지 않는다.
- 이 과정에서 추가되는 edge를 safe edge라고 한다.
-
(3)번에서의 vertex에 대해 (2) ~ (3)의 과정을 반복한다.
-
모든 vertex가 선택되면 알고리즘을 종료한다.
Running time of Prim's Algorithm
: 각 단계에서 최솟값을 찾을 때
: 모든 vertex와 edge를 확인할 때
따라서 라면, Running time은 이다.
효율적인 Prim's Algorithm
최솟값을 찾고, 관리하는 과정에서 MIN-HEAP을 사용하자.
-
EXTRACT-MIN: 남은 Tree에서 Cost가 가장 작은 vertex를 선택하는 것
-
DECREASE-KEY: 인접한 vertexs에 대해 Cost를 업데이트하는 것
-
MIN-HEAP에 남은 node가 존재하지 않으면 알고리즘을 종료한다.
MST-PRIM(G, w, r) //w: weight, r: root
1. for each u ∈ G.V
2. u.key = ∞
3. u.π = NIL
4. r.key = 0
5. Q = G.V //Priority Queue
6. while Q != ∅
7. u = EXTRACT-MIN(Q)
8. for each v ∈ G.Adj[u]
9. if v ∈ Q and w(u, v) < v.key
10. v.π = u
11. v.key = w(u, v)
12. DECREASE-KEY(Q)Running time of Prim's Algorithm using MIN-HEAP
Line 1 ~ 5:
Line 7:
Line 8 ~ 11:
Line 12:
Total Running time:
- Miminum Spanning Tree이기 때문에 원래의 그래프 G의 이다.
- 여러 개의 Spanning tree가 존재할 수 있기 때문이다.
Kruskal's Algorithm
Disjoint Set data structure의 forest를 사용한다.
과정
-
초기 세팅
- 그래프의 모든 vertex를 하나의 tree로 만들고 self loop를 갖도록 한다.
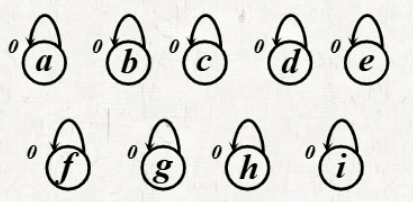
- Weight를 기준 오름차순으로 정렬한다.
- Rank = 0 으로 세팅한다.
- 그래프의 모든 vertex를 하나의 tree로 만들고 self loop를 갖도록 한다.
-
Weight가 작은 것부터 시작하여 해당 vertex들을 UNION 한다.
- 이미 같은 Tree에 존재하는지 여부를 FIND-KEY의 값이 같은지로 확인한다.
- 이미 같은 Tree에 존재하더라도 Path Compression이 가능하다면 Path Compression을 수행한다.
-
(2)의 과정에서 UNION하는 두 vertex의 root node의 Rank가 동일하다면 Rank += 1, 동일하지 않다면 변화시키지 않고 UNION 한다.
-
모든 vertex가 Tree에 포함되면 알고리즘을 종료한다.
MST-KRUSKAL(G, w)
1. A = ∅ //edge set
2. for each vertex v ∈ G.V
3. MAKE-SET(v) //initial setting
4. sort the edges of G.E into nondecreasing order by weight w
5. for each edge (u, v) ∈ G.E, taken in nondecreasing order by weight w
6. if FIND-SET(u) != FIND-SET(v) // 같은 tree에 존재하는지 확인
7. A = A ∪ {(u, v)}
8. UNION(u, v)
9. return ARunning time of Kruskal's Algorithm
: MAKE-SET(v)의 실행 횟수
: FIND-SET(u)의 실행 횟수
: UNION(u, v)의 실행 횟수
Line 4:
Disjoint Set data structue
- , ,
- Forest representation에서,
Total Running time
- 는 에 비해 매우 작아서 무시할 수 있다.

- : Rank computation와 Path compression을 진행하는데 걸리는 시간
