지도 학습 방법으로 데이터셋의 차원 개수를 줄일 수 있는 선형 변환 기법
Fisher Discriminant Analysis (FDA) 라고도 한다.
LDA
공분산 개념을 통해 데이터를 잘 구분하는 특성을 선택한다.
- 각 클래스 레이블의 샘플의 공분산끼리 최대한 겹치지 않도록 하는 특성을 선택하는 것이 좋다.
- 이때 선택된 특성을 선형 판별 벡터 (Linear Discriminant Vectors) 라고 한다.
- 고유값 분해의 특성상 선형 독립적인 벡터는 최대 개 (c: class label 개수)로 제한된다는 이론적인 이유가 있다.
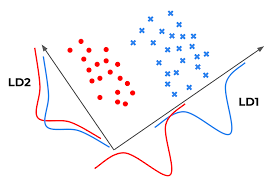
- 이 경우, 우리는 LD1 을 특성으로 선택한다.
가정
데이터가 정규 분포를 따르며, 각 훈련 샘플은 서로 Independent 하다고 가정한다.
LDA 동작 방식
-
차원의 데이터셋을 표준화 한다.
-
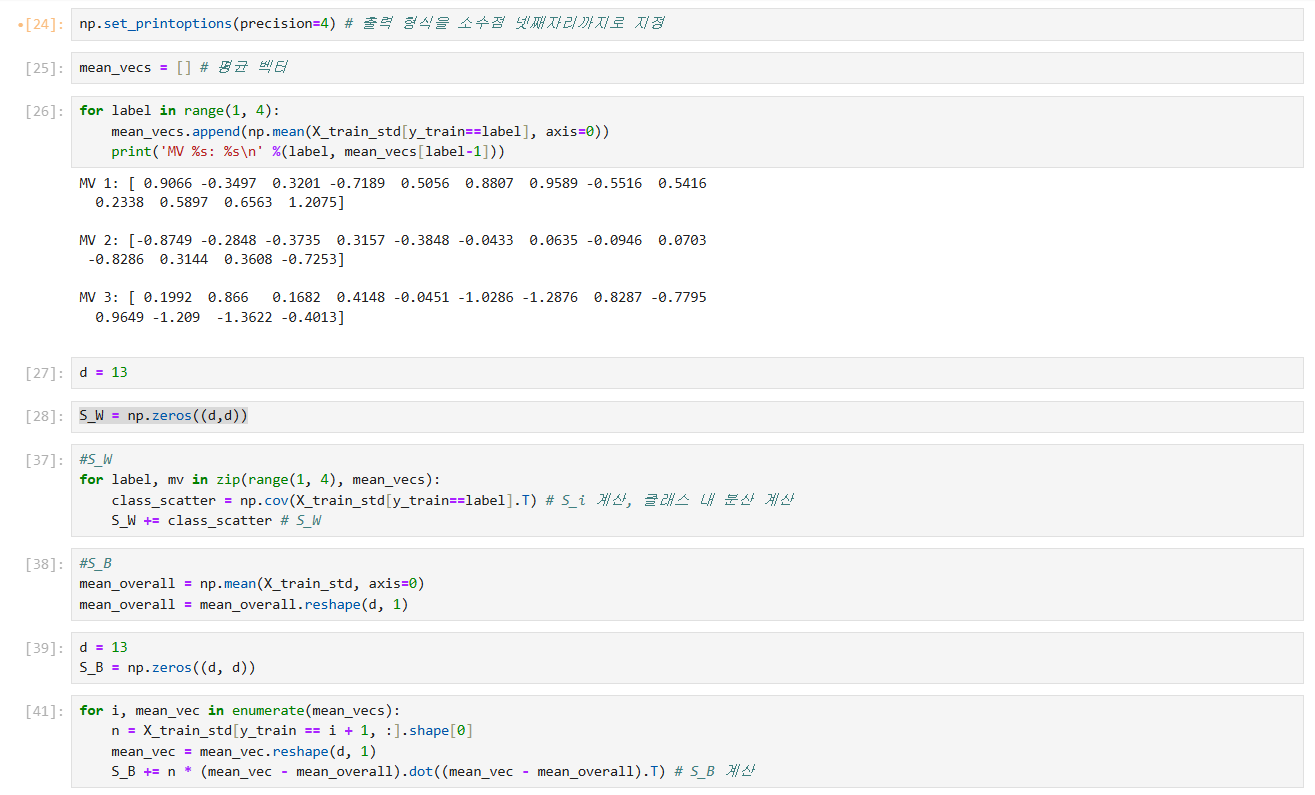
각 클래스에 대해 차원의 평균 벡터를 계산한다.

-
클래스 간의 Scatter matrix 와 클래스 내 Scatter matrix 를 구성한다.


- : 각 클래스별 평균이 전체 평균에서 얼마만큼 떨어져 있는지를 확인
- : 각 클래스 내에서의 분산 각각을 더한 총합
- 모든 클래스 내 분산을 고려하기 위해 모두 더한다.
-
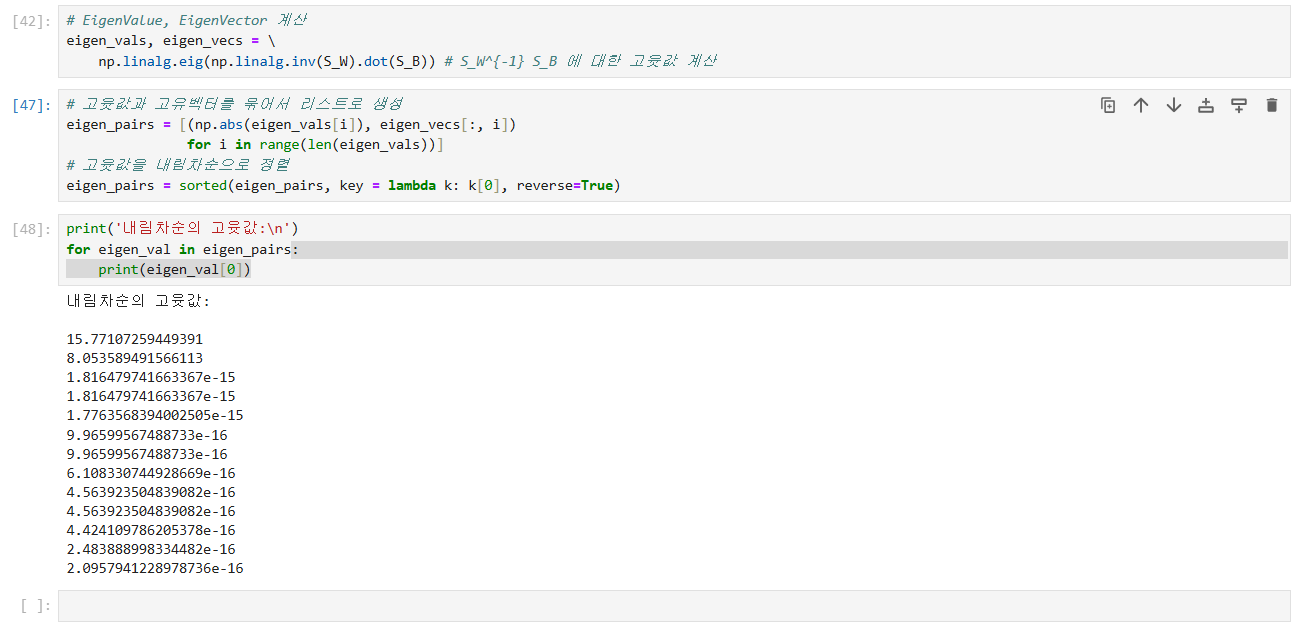
행렬의 EigenVector 와 EigenValue를 계산한다.
-
고윳값을 내림차순으로 정렬하여 고유벡터의 순서를 매긴다.
-
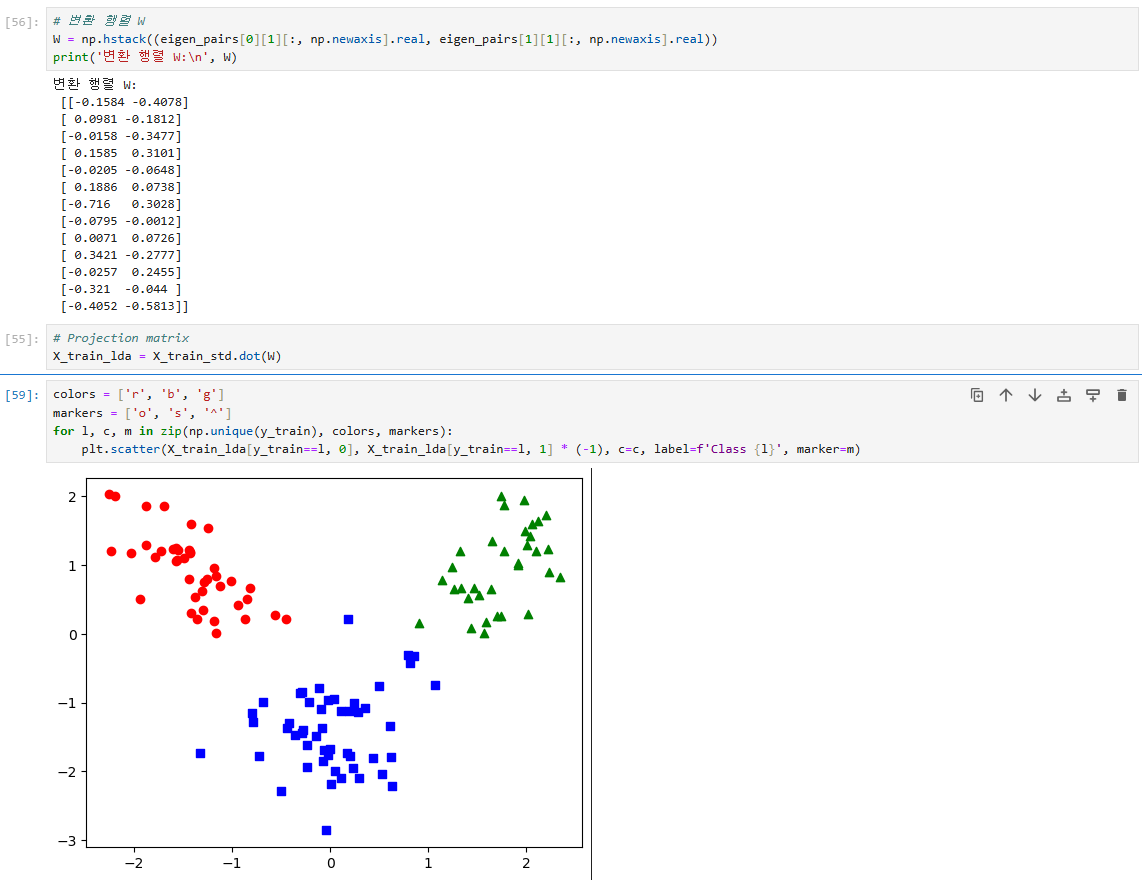
고윳값이 가장 큰 개의 특성을 선택하여 x 의 변환 행렬 를 구성한다.
-
변환 행렬 를 이용하여 Projection matrix로 차원을 줄인다.
수학적 증명

- 를 으로 나누어주는 이유는 만약 훈련 데이터셋의 클래스 레이블이 균등하게 분포되어있지 않으면 가 각 클래스 레이블의 데이터 샘플 개수가 큰 것에 편향될 수 있기 때문이다.
파이썬으로 LDA 구현
사이킷런으로 LDA 구현
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
# solver: 'eigen': 고유값 분해(Eigen decomposition) 방법을 사용.
# solver:'lsqr': 최소 제곱법(Least Squares) 방법을 사용.
lda = LDA(n_components=2, solver='eigen')
X_train_lda = lda.fit_transform(X_train_std, y_train)사이킷런 LDA에서의 차이점
# 클래스 내 공분산을 구할 때, 분모에 (n-1) 대신 n을 사용하기 위해 bias: True를 추가하였다.
class_scatter = np.cov(X_train_std[y_train==label].T, bias: True)
PCA vs LDA
두 방법 모두 선형 변환 기법으로 차원의 개수를 줄이는 방법이다.
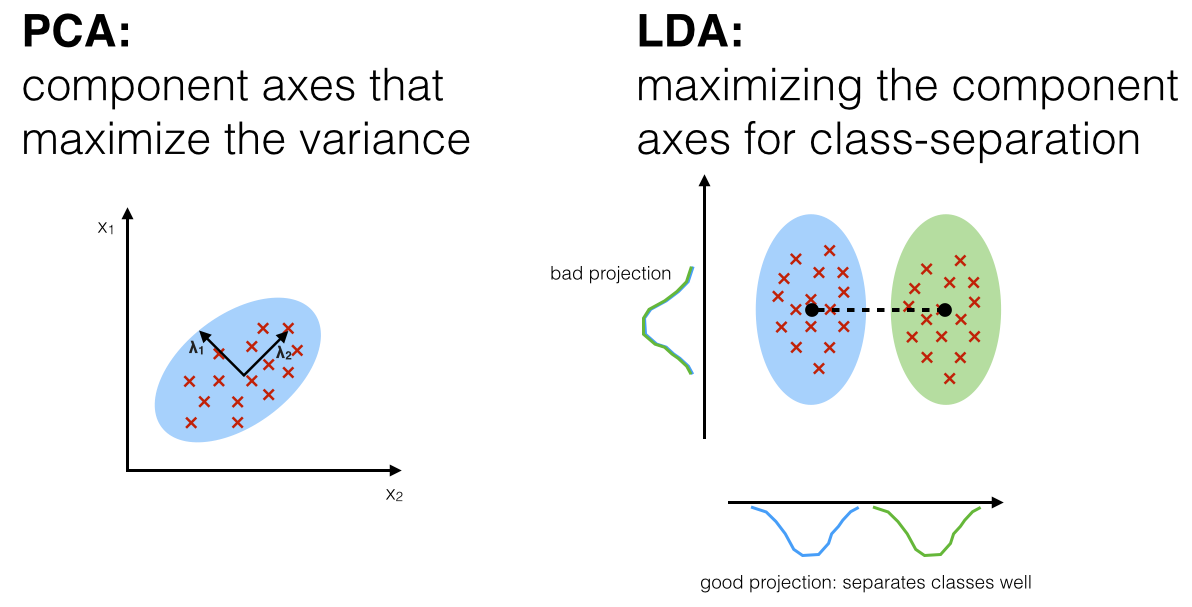
-
PCA가 데이터의 전체적인 분산을 최대화하는 방향으로 차원을 줄이는 반면, LDA는 클래스 간 분산을 최대화하는 방향으로 차원을 줄인다.
-
PCA는 비지도 학습, LDA는 지도 학습이라는 차이점이 있다.
-
분류 문제의 경우, LDA가 더 효율적이라는 연구 결과가 있다.
