
고차원에서 저차원으로의 차원 축소 기법으로 PCA 라고도 한다.
데이터에 대해 가장 많은 정보를 남기기 위한 방법이며, 이를 위해 분산이 큰 것을 선택한다.
PCA
목표는 행렬을 낮은 차원의 행렬로 변환한 후, 분산이 가장 큰 k개를 선택하여 최대한 많은 정보를 남기는 것이다.
- 분산이 커 데이터가 많이 퍼져 있는 방향일수록 데이터가 더 다양한 값을 가지므로, 더 많은 정보를 담고 있다고 볼 수 있다.
- 선택된 각 주성분들은 x, y, z, ... 축과 평행하지 않을 수도 있다.
고윳값 분해
📌 고윳값 분해의 핵심
어떤 정방행렬 𝐴에 대해 고윳값 𝜆과 고유벡터 𝑣는 다음 관계를 만족한다.
-
-
즉, 정방행렬 A에 대해, 방향을 바꾸지 않고 크기만 변화시키는 vector 가 존재한다.
과정
-
d차원 데이터셋을 표준화 전처리한다.
- PCA는 분산을 다루기 때문에 데이터 스케일에 영향을 크게 받는다.
-
Covariance matrix 를 만든다.
- x 행렬이고 , 이다.
-
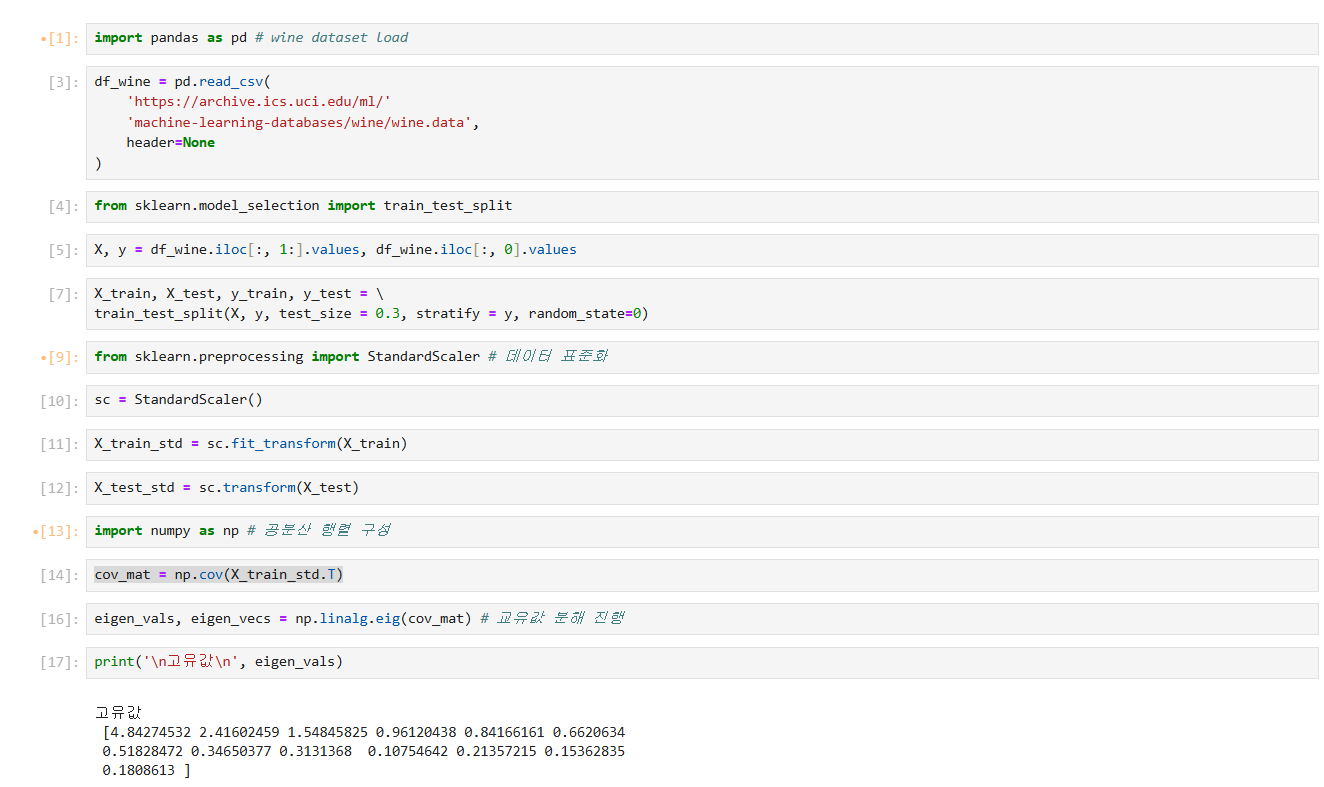
Covariance matrix 를 eigenvector와 eigenvalue 로 분해한다.
-
Eigenvalue 를 정렬한다.
-
고윳값이 가장 큰 개의 eigenvector를 선택한다.
- 고윳값은 해당 고유벡터(주성분)가 나타내는 데이터의 분산 크기를 나타낸다.
- 고윳값이 크다는 것은 데이터가 그 주성분 방향으로 더 많이 퍼져 있다는 것이고, 이는 그 방향에 더 많은 정보가 있다는 뜻이다.
-
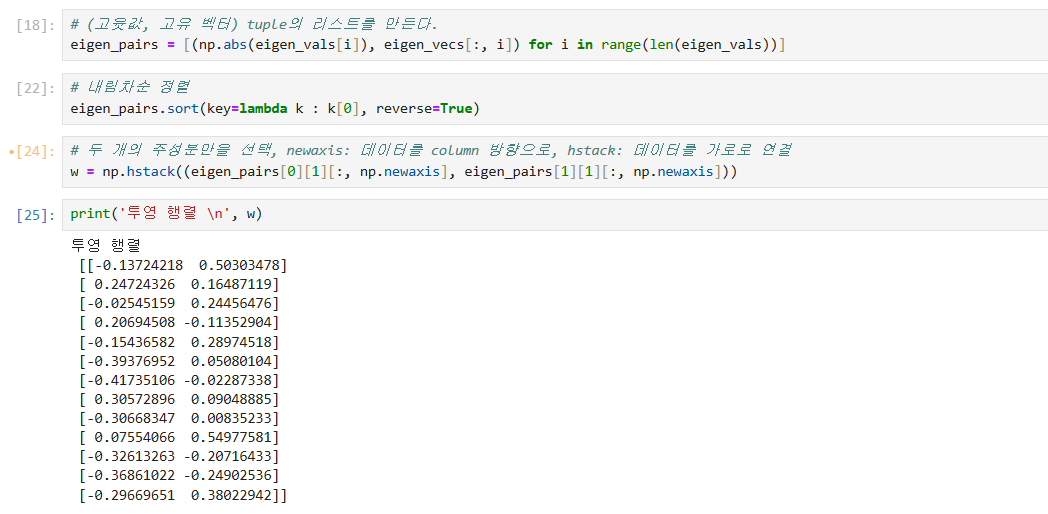
최상위 개의 eigenvector 로 Projection matrix W를 만든다.
-
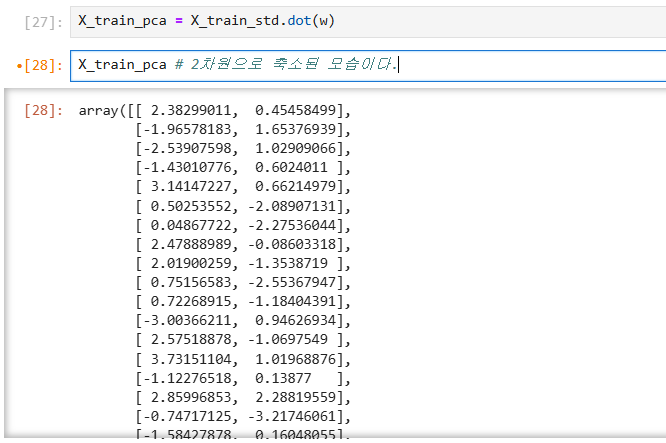
Projection matrix W 를 사용하여 차원 입력 데이터셋 X를 새로운 차원의 특성 부분 공간으로 변환한다.





PCA 파이썬으로 구현하기
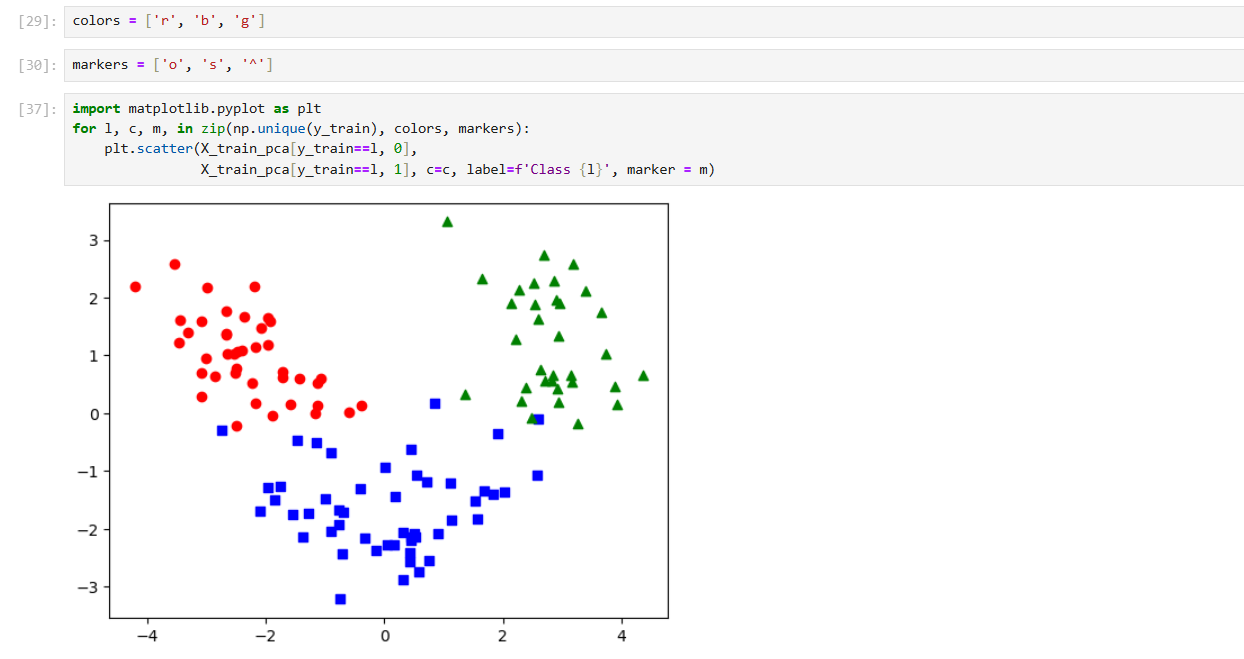
- 결과를 보면 X축 (제1주성분) 방향으로 데이터가 비교적 넓게 펴져있는 것을 확인할 수 있다.
Explained variance ratio
특성 고유값을 전체 고윳값의 합으로 나눈 것
- 개의 특성을 선택하기 전에 특정 Eigenvalue 가 차지하는 비율을 확인할 수 있다.
PCA 사이킷런으로 구현하기
from sklearn.decomposition import PCA
# 주성분 개수 지정
pca = PCA(n_components=2)
# 차원 축소
X_train_pca = pca.fit_transform(X_train_std)
X_train_pca = pca.transform(X_test_std)
# 전체 주성분 모두 사용
pca = PCA(n_components=None)
X_train_pca = pca.fit_transform(X_train_std)
# 전체 주성분의 Explained variance ratio를 확인하자
print(pca.explained_variance_ratio_)
# n_components = 0 ~ 1 사이 실수
# Cumulative Explained variance ratio가 실수값 이상이 될 때까지 진행
pca = PCA(n_components=0.8)- 사이킷런의 PCA 클래스는 Singular decomposition 방식으로 고윳값 분해를 진행한다.
from sklearn.decomposition import IncrementalPCA
ipca = IncrementalPCA(n_components = 9)
for batch in range(len(X_train_std)//25+1):
X_batch = X_train_std[batch*25:(batch+1)*25]
ipca.partial_fit(X_batch)- 전체 데이터를 한 번에 처리하는 PCA와 달리, IncrementalPCA는 작은 배치 단위로 데이터를 업데이트하면서 주성분을 학습한다.
- 메모리 절약이 가능하다.
특성 기여도(Loading) 확인
Loading(로딩 행렬)은 각 원본 특성이 주성분에 얼마나 기여하는지를 나타내는 값이다.이는 주성분을 해석하는 중요한 지표로, 특정 주성분이 어떤 원본 특성과 관련이 있는지를 파악할 수 있다.

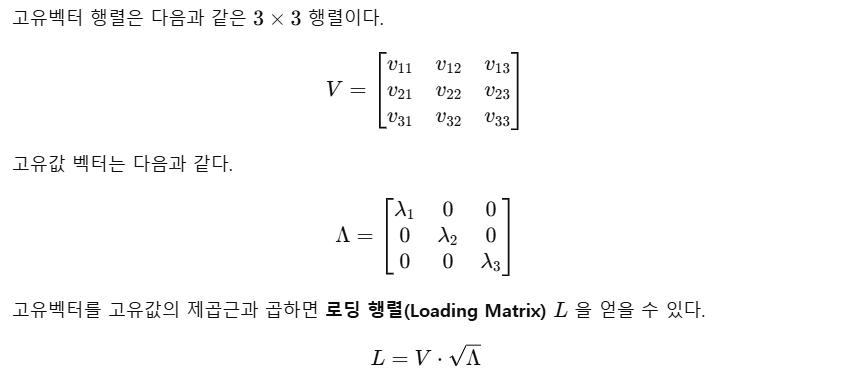
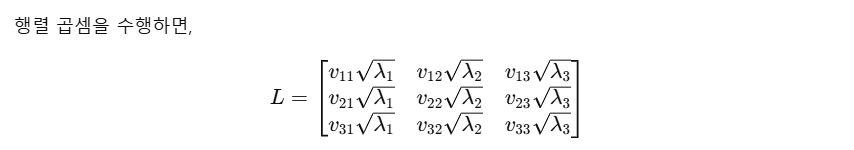


-
Eigen vector 자체가 Covariance matrix로부터 도출되었기 때문에 가능하다고 생각하면 편하다.
-
양의 상관관계: 정비례
-
음의 상관관계: 반비례
파이썬으로 구현
loadings = eigen_vecs * np.sqrt(eigen_vals)사이킷런으로 구현
from sklearn.decompositino import PCA
sklearn_loadings = pca.components_.T * np.sqrt(pca.explaned_variance_)