목표: Edge에 Weight가 존재하는 Graph에서 Path Weight가 가장 작은 Path를 찾자
Definition
- Path Weight: Path에 존재하는 모든 edge weight의 합
- Shortest path from u to v: to 의 path 중 path weight가 가장 작은 path.
- Shortest-path weight from u to v: Shortest path from u to v의 weight.
- δ(u,v)
Shortest-path problems
4가지의 경우의 수가 존재한다.
- Single-source & single-destination
- Single-source & all destinations
- (SSSP)
- all sources & single-destination
- all pairs
Single-source & all destinations 만을 이용하여 나머지 3가지 경우 모두 해결이 가능하다.
Prove) Single-source & all destinations의 Running time = T(n)이라고 가정하자.
-
Single-source & single-destination은 Single-source & all destinations의 부분집합이므로 해결 가능하다.
-
all sources & single-destination은 원래의 그래프 를 시켜 Single-source & all destinations을 수행한 것과 동일하다.
-
all pairs은 모든 vertex가 source인 경우로 n번 Single-source & all destinations을 수행하면 된다.
- Running time:
Negative-weight edges
Edge Weight가 음수인 경우
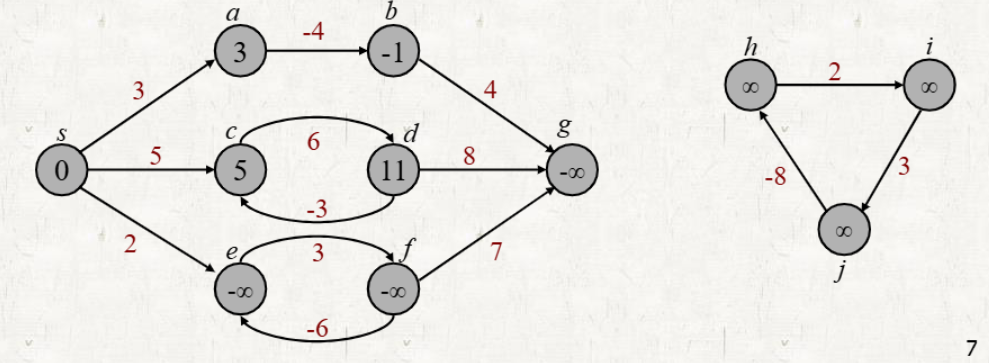 문제가 되는 경우: Source vertex로 부터 reachable한 negative cycle이 존재하는 경우
문제가 되는 경우: Source vertex로 부터 reachable한 negative cycle이 존재하는 경우
- Path weight가 가 될 수도 있다.
- Negative-weight cycle: cylce 내의 edge weight 합이 음수인 cycle
- 위 그림에서 Source vertex: s 일 때, 는 문제가 되지만 는 문제가 되지 않는다.
- 아래의 Single-source shortest path problem에서 전제는 Not any negative-weight cycles reachable from the source
Shortest path problem에서는 cycle을 무시한다.
- Negative-weight cycle은 전제에서 무시되고, Positive-weight cycle은 Shortest path에 사용될 수 없다.
- Zero-weight cycle은 Shortest path에 영향이 없지만 무시하기로 한다.
- 따라서 Shortest-path length의 최대값은 이다.
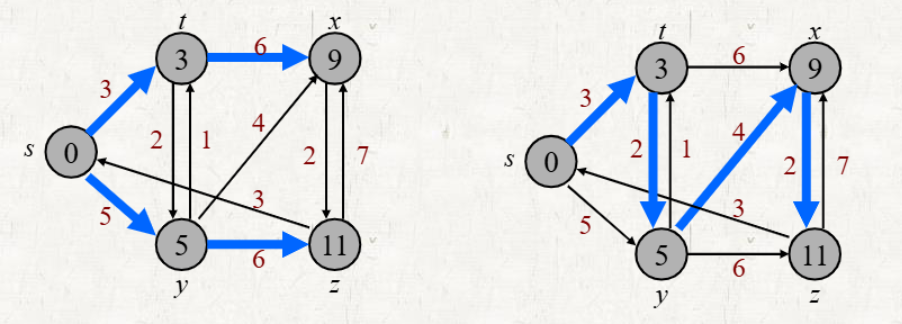
Predecessor subgraph
Shortest path algorithm에서 사용된 edge와 vertex로만 이루어진 Subgraph
- Shortest-path tree는 Predecessor subgraph의 한 종류이다.
- 모든 Single source shortest problem path를 저장한다.
- Optimal substructure
- 문제를 작은 하위 문제들로 나누고, 각 하위 문제를 최적화하여 결합하면 전체 문제를 최적으로 해결할 수 있는 성질
- EX) 만약 𝑠 → 𝑣 에 가 포함되어 있다면, 𝑠 → 𝑢 경로도 최단 경로입니다
- 하나의 SSSP에 대해 여러 개의 Shortest-path tree가 존재할 수 있다.
Space compexity of Predecessor subgraph
-
Worst case
각 vertex가 해당 vertex까지의 path에 있는 모든 vertex를 저장하는 경우
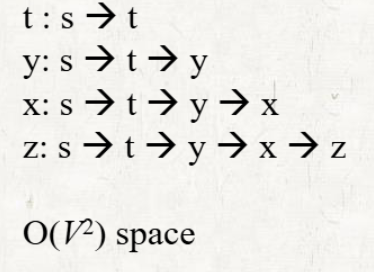
-
Best case
각 vertex가 해당 vertex의 predecessor만 저장하는 경우

Relaxation
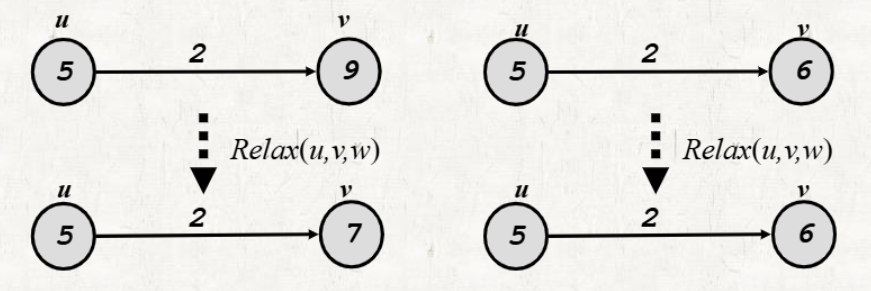 Destination vertex에 저장되어있는 숫자가 (Source vertex에 저장되어있는 숫자 + Edge Weight) 보다 크면 UPDATE한다.
Destination vertex에 저장되어있는 숫자가 (Source vertex에 저장되어있는 숫자 + Edge Weight) 보다 크면 UPDATE한다.
Dijkstra's Algorithm
Nonnegative edge weight인 경우에 한해서 정상적으로 동작한다.
Array를 사용하는 방법
초기 세팅
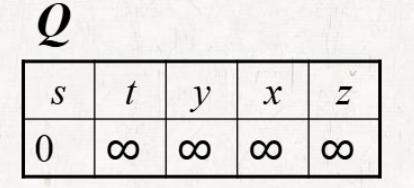
- 배열에는 Distance를 저장하고 source vertex = 0, 나머지는 로 초기화한다.
- S = ∅
과정
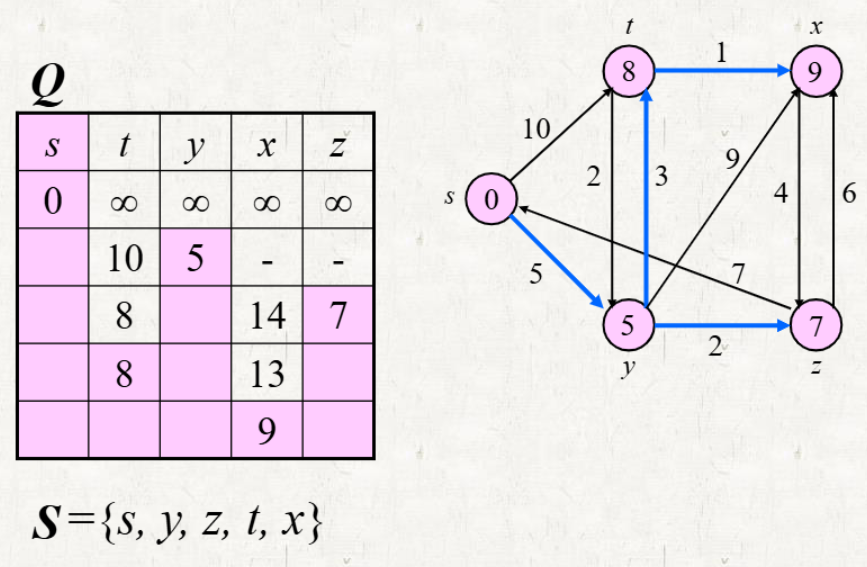
-
선택한 vertex에 대해 해당 vertex로부터 인접한 vertex를 relaxing 한다.
- Source vertex부터 시작한다.
- Array의 predecessor vertex
- Relaxion 참고
-
(1)의 과정이 종료되고, S 집합에 (1)에서 사용한 vertex를 추가한다.
-
집합 S에 존재하지 않는 vertex 중 distance가 가장 작은 vertex에 대해 (1) ~ (2) 의 과정을 반복한다.
-
집합 S에 모든 vertex가 추가되면 알고리즘을 종료한다.
Running time
하나의 vertex 마다 집합 S에 존재하지 않는 vertex 모두를 탐색한다.
Min-heap을 사용하는 방법
Running time을 줄일 수 있다.
초기 세팅
- 배열을 predecessor vertex를 저장하는데 사용한다.
과정
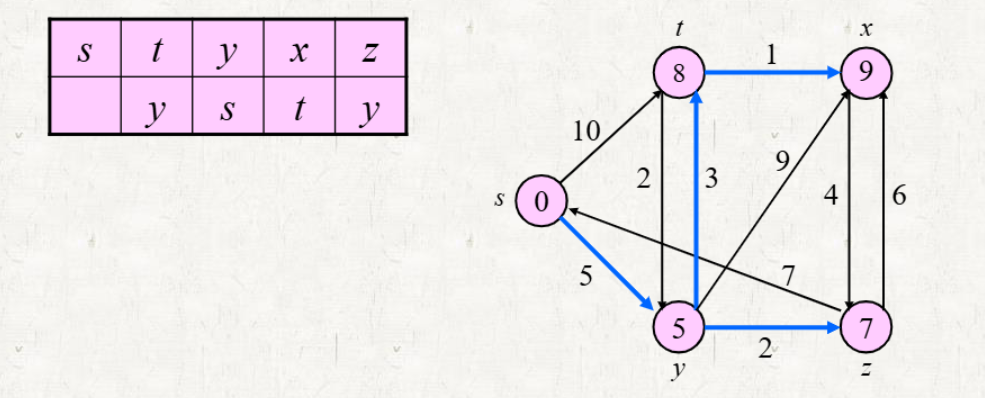
-
EXTRACT-MIN의 결과로 나온 vertex에 대해 해당 vertex로부터 인접한 vertex를 relaxing 한다.
- Source vertex부터 시작한다.
- 배열에 predecessor vertex를 저장한다.
- Relaxion 참고
-
(1)의 과정에서 Relaxing의 결과로 Update 되었다면 HEAP-DECREASE-KEY 진행한다.
-
Min-heap에 존재하는 vertex가 없을 때까지 (1) ~ (2) 의 과정을 반복한다.
Pseudo code
DIJKSTRA(G, w, s)
1. INITIALIZE-SINGLE-SOURCE(G, s)
2. S = ∅
3. Q = G.V //priority queue
4. while Q != ∅
5. u = EXTRACT-MIN(Q)
6. S = S ∪ {u}
7. for each vertex v ∈ G.Adj[u]
8. RELAX(u, v, w) //DECREASE-KEY(V, d[V])를 수행Running time
- Line 1 ~ 3:
- Line 5:
- Line 6 ~ 7:
- Line 8:
Dijkstra's algorithm 정리
-
: Unsorted array를 사용할 때
-
: Min-heap을 사용할 때
-
Prim's algorithm과 다르게 VlogV를 무시하지 않는 이유는 Minimum spanning tree를 결정할 때에 비해 방문하는 vertex의 개수가 많기 때문이다.
-
인 경우에는 오히려 Unsorted array를 사용하는 것이 유리하다.
-
-
: Fibonacci heap를 사용할 때
- Best case이나, 따로 증명하지 않음.
The Bellman-Ford algorithm
Negative-weight edge가 존재할 때도 single source shortest paths problem을 해결할 수 있는 알고리즘
초기 세팅
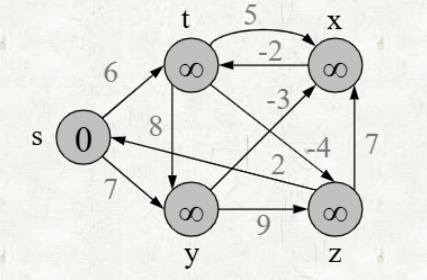
- Distance: source vertex = 0, 나머지 vertex =
과정
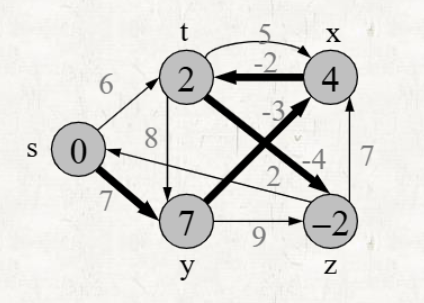
-
번 반복하며 각 단계마다 Graph에 존재하는 모든 edge를 Relaxing 한다.
- 각 vertex는 distance를 저장한다.
- Edge를 Relaxing하는 순서를 지정할 수 있다.
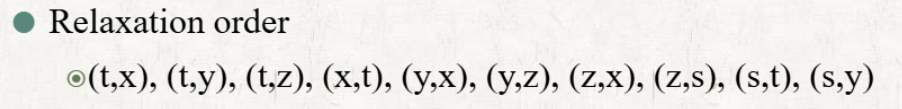
-
(1)의 과정이 종료되었을 때, 각 vertex에 저장되어있는 것이 shoretest distance이다.
Pseudo code of Bellman-Ford algorithm
BELLMAN-FORD(G, w, s) //w: weight, s: source
1. INITIALIZE-SINGLE-SOURCE(G, s)
2. for i = 1 to |G.V|-1 //source vertex 제외
3. for each edge (u, v) ∈ G.E
4. RELAX(u, v, w)
5. for each edge (u, v) ∈ G.E
6. if v.d > u.d + w(u,v)
7. return FALSE
8. return TRUELine 5 ~ 8: BELLMAN-FORD 알고리즘이 제대로 작동할 수 있는지를 판단하는 부분이다.
- Line 2 ~ 4는 번 실행되기 때문에 번째 실행에서 distance가 달라지게 된다면 Negative-weight cycle이 존재할 가능성이 크다.
- 따라서 이 경우에는 최단 거리를 정확하게 계산할 수 없으므로 FALSE를 리턴한다.
Running time
- Line 2 ~ 4:
- Line 5 ~ 7:
- Total running time:
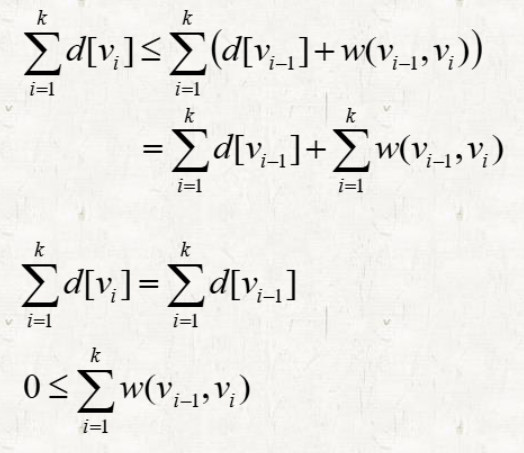
- 첫번째 식은 만약 Relaxing이 된 경우에 성립해야하는 식이다.
- Update가 되지 않았다면 세번째 식과 동일하다. 이때 Weight의 합이 음수가 되지 않음을 보장받을 수 있다.
- 세 번째 식은 가 성립하기 때문에 가능하다.
Dijkstra's Algorithm 보다 Running time은 크지만, Negative-weight edge가 존재하는 경우까지 계산할 수 있다는 이점이 존재한다.
Single-source shortest paths in directed acyclic graphs
DAG에서 사용가능한 Single-source shortest paths 알고리즘
초기 세팅
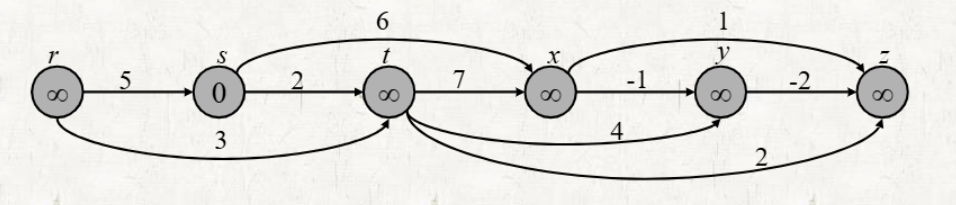
- Distance: source vertex = 0, 나머지 vertex =
- Topologically sorted order로 정렬한다.
과정
- Topologically sorted order에서 가장 첫 번째 vertex부터 시작하여 각 vertex에 인접한 edge를 Relaxing 한다.
Pseudo code
DAG-SHORTEST=PATHS(G, w, s)
1. topologically sort the vertices of G
2. INITIALIZE-SINGLE-SOURCE(G, s)
3. for each vertex u, taken in topologically sorted order
4. for each vertex v ∈ G.Adj[u]
5. RELAX(u, v, w)Running time
- Total running time:
- Dijkstra나 Bellman-Ford 알고리즘보다 빠르다.
