조건부 Insert

위 수험결과 테이블에서 90점 이상인 과목을 고득점 결과에 삽입하라.
과목 코드 국어 01, 수학 02, 영어 03
insert into 고득점 결과
select * from
(
select 수험일자, 수험번호,
case when lv = 1 then '01'
when lv = 2 then '02'
when lv = 3 then '03' END 과목코드,
case when lv = 1 AND 국어 >= 90 then (국어)
when lv = 2 AND 수학 >= 90 then (수학)
when lv = 3 AND 영어 >= 90 then (영어) END 점수
from 수험결과, (select level lv from dual connect by level <= 3)
where (국어 >= 90 or 수학 >= 90 or 영어 >= 90)
)
where 점수 is not null;- insert into 에서 모든컬럼을 삽입시 컬럼은 선언하지 않아도됨.
- 인라인 뷰에서 모든쿼리 완료하고 점수 is not null로 90점이하는 제한
- 인라인 뷰에서 from dual connect by level <=3 으로 카테시안 곱을 3배로 늘림
- 3배로 복사된 수험결과를 case문과 lv = 1같은 조건을 통해 각각 검사
집계하여 Insert
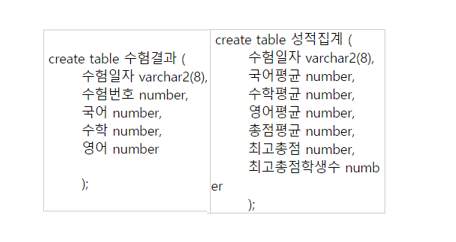
위 수험결과 테이블에서 '20140617' 일자의 시험결과를 성적집계에 Insert 하시오
insert into 성적집계
select 수험일자, ROUND(avg(국어)) 국어평균,
ROUND(avg(수학)) 수학평균,
ROUND(avg(영어)) 영어평균,
ROUND(avg(총점) , 2) 총점평균,
MAX(최고 총점) 최고총점,
count(case when 최고총점 = 총점 THEN 1 END) 최고총점학생수
from (
select A.*, 국어+수학+영어 총점,
First_Value(국어+수학+영어) over(order by (국어+영어+수학) DESC) 최고총점
from 수험결과 A
where 수험일자 = '20140617'
)
group by 수험일자;- 집계함수를 다방면으로 활용함, avg, max, count, first_value
- 다방면으로 활용될 총점, 최고총점을 인라인뷰에서 먼저 가공한다.
- 최소한의 조건을 위해 인라인 뷰에서 수험일자 = '20140617' 함.
- 총점과 최고총점을 활용하여 각각 필요한 컬럼으로 가공.
- COUNT(CASE WHEN 최고총점 = 총점 THEN 1 END) 최고총점학생수 같은 문법 기억할것
세미조인, 조인순서, 힌트, 인덱스 지정

create index idx_b001 on b(type, cls)
create index idx_c001 on c(no)
create index idx_d001 on d(cls, type, order_dt)
select /*+ index(c idx_c001)*/ a.*, c.*
from( select /*+leading(b d) index(b idx_b001) index(d idx_d001)*/ b.*
from b16 b
where b.type = 'zz123'
and exists ( /*+ unnest nl_sj */ select 'x'
from d16 d
where d.cls = b.cls
and d.type = 'df100'
and d.order_dt is null ) a, c16 c
where a.no = c.no;- 조인은 C - B - D 로 B는 가장 카디널리티가 적고 핵심 테이블이다.
- B와 D를 최적 인덱스로 세미조인하여 최고효율로 데이터를 걸러낸다.
- 그 후 C와 미비한 비용의 조인으로 최종 결과집합 도출한다.

🔥🔥🔥🔥 G U N F E 🔥🔥🔥🔥