오라클 성능 고도화 1,2
1.[DB] DB의 기본 아키텍처란?
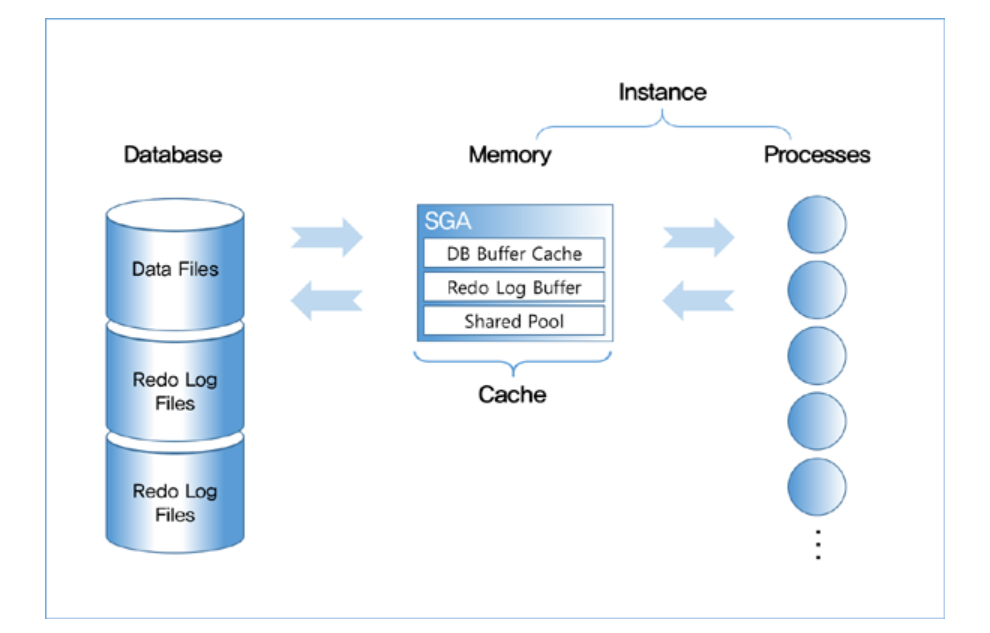
오라클 성능 고도화 1,2 권을 정리할 생각이다.
2.[DB] 성능 튜닝의 핵심 Buffer Cache
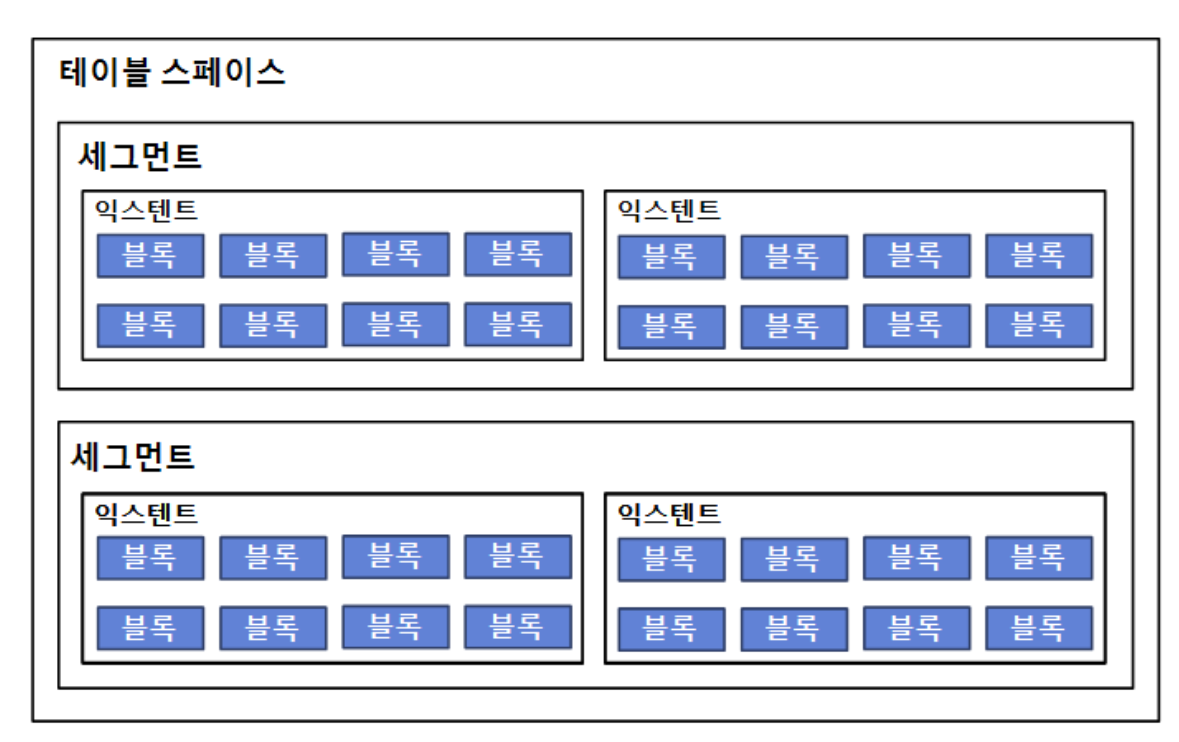
오라클은 데이터 I/O의 단위가 블록단위로 이루어진다.
3.[DB] Redo 와 Undo

데이터파일, 컨트롤 파일에 가해지는 모든 변경사항을 Redo 에 기록한다
4.[DB] 문장 수준 읽기 일관성
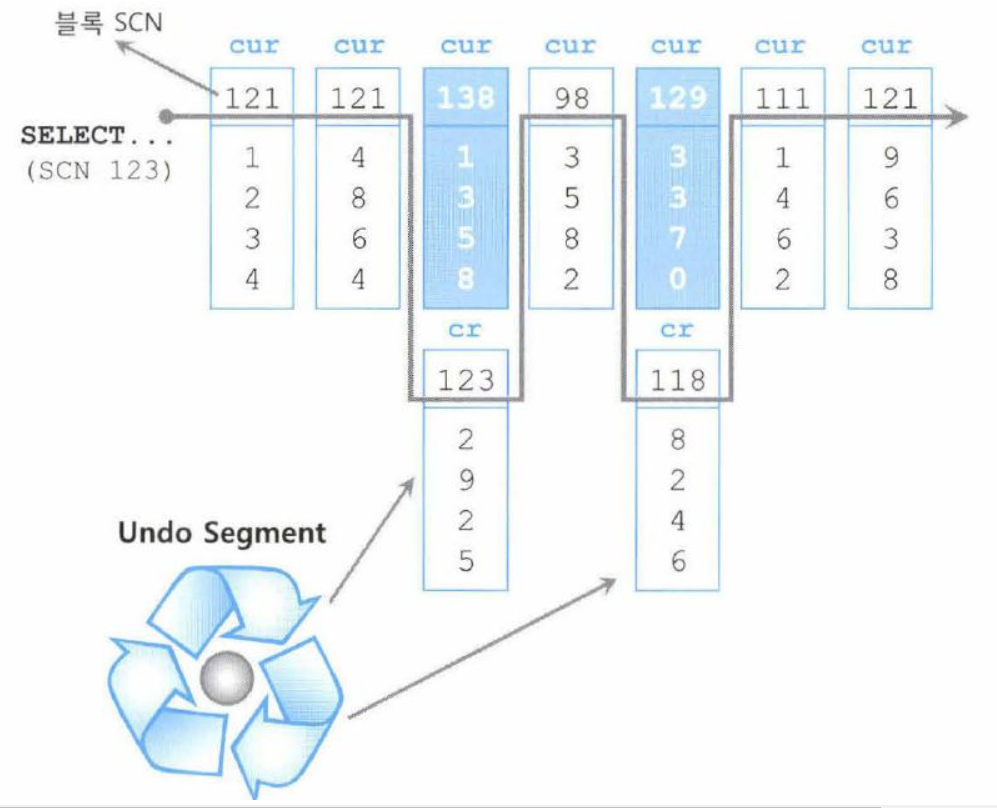
데이터는 일관성있게 제공되어야 한다.SQL문이 수행되는 도중에 다른 트랜잭션에 의해 데이터가 변경,추가,삭제 되었을떄,이를 반영한다면 일관성 없는 결과집합을 리턴 할 것이다.오라클에서는 이를 방지하기 위해 사용하는 '문장 읽기 일관성'이 있다.오라클은 다른 트랜잭션의
5.[DB] 비관적 vs 낙관적 동시성 제어
n-Tier구조가 지배적인 요즘은 DBMS의 트랜잭션 고립화 수준을 변경하는 방법을 사용하기가 어렵다.그리하여 개발자가 직접 동시성 제어를 개발한다.비관적 동시성 제어비관적 동시성 제어는 사용자들이 같은 데이터를 동시에 수정 할 것이라고 가정한다. 따라서 한사용자가 데
6.[DB] 실행 계획과 통계
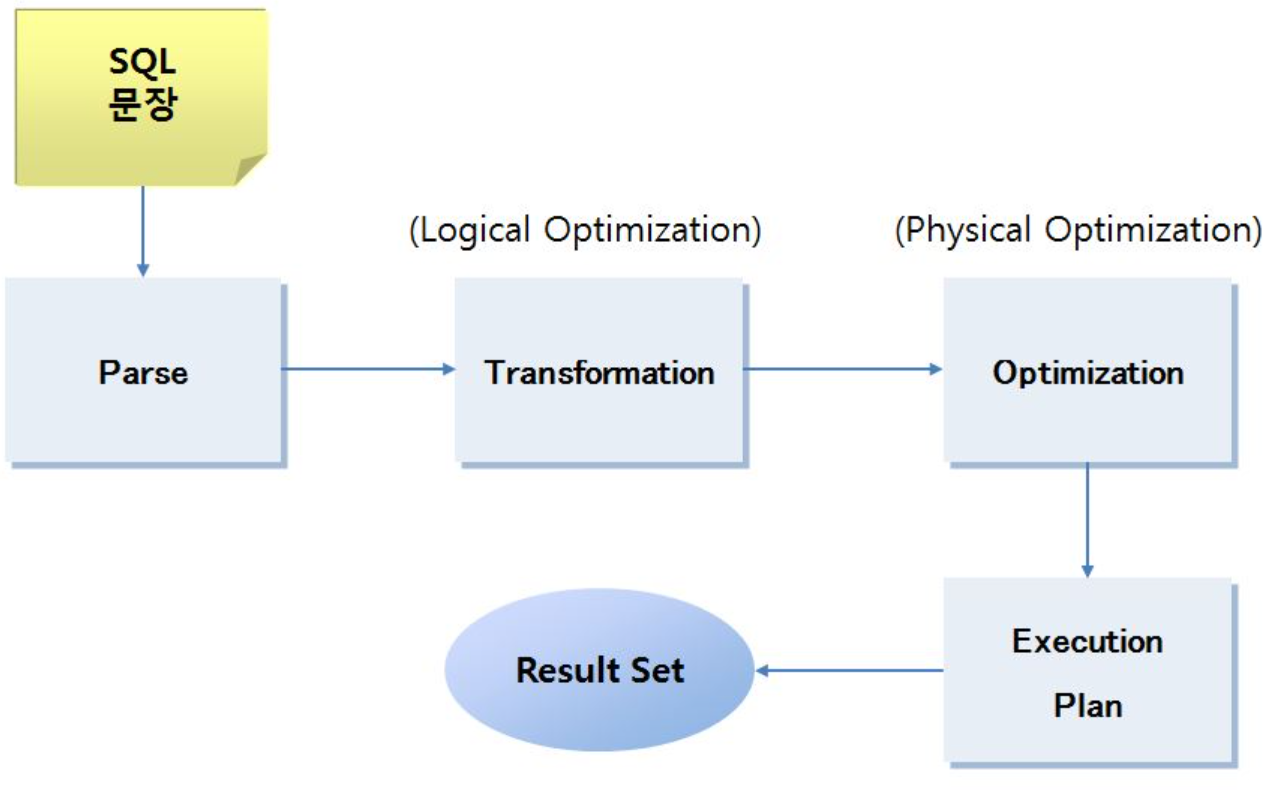
아래는 사용자가 SQL문을 입력시 내부적으로 작동하는 원리이다.Parse : 먼저 옵티마이저는 해당 문장의 문법(오타)등이 없는지 검사하고 Object이름과 권한등을 확인한다.Transformation : Subquery, InlineView 등의 복잡한 부분을 해석하
7.[DB] 커서공유와 바인드 변수
오라클에서 커서를 공유한다 라는 표현을 자주 사용하는데 여기서 말하는 커서는 라이브러리 캐시의 공유 커서를 일컫는다. 세션커서, 애플리케이션 커서는 다른 프로세스와 공유할수 없다.공유된 커서는 소프트 파싱을 일으키며 해당 SQL을 캐싱해놓고 가져다 쓰기만 하면 되는 기
8.[DB] Clustering Factor
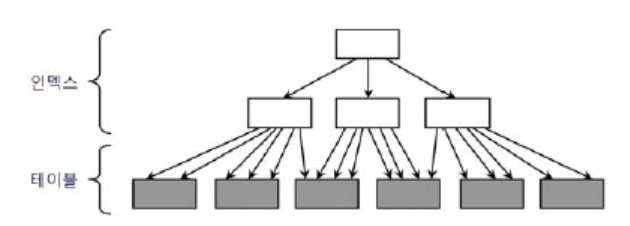
물리적 디스크파일에서 데이터가 모여있는 정도를 나타낸다.예를들어 OLTP의 필수 컬럼으로 날짜가 있는데 데이터가 입력될때마다 날짜로 정렬하듯이 데이터가 입력된다.이것을 보고 날짜별 Clustering Fector가 좋다 라고한다.주의할점은 테이블에는 그저 날짜별로 입력
9.[DB] HashJoin
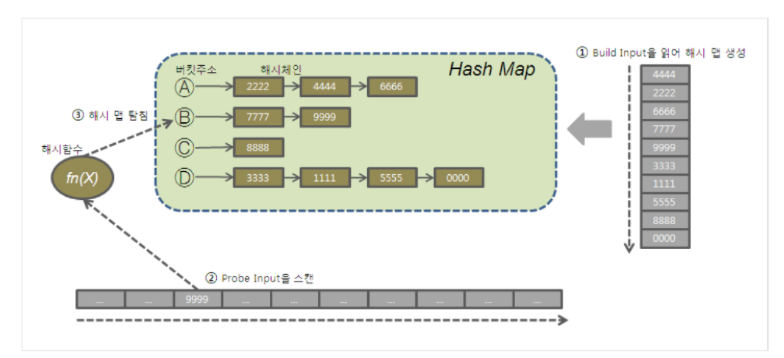
NL조인의 약점을 극복한 HashJoin 7.3버전에서 처음 소개된 해시조인은 소트 머지 조인과 NL조인이 효과적이지 못한 상황에 대한 대안으로써 개발되었다. 해시조인은 둘중 작은 집합을 Build Input으로 읽어 Hash Area에 해시테이블을 생성하고 반대쪽
10.[DB] Nested Loop Join
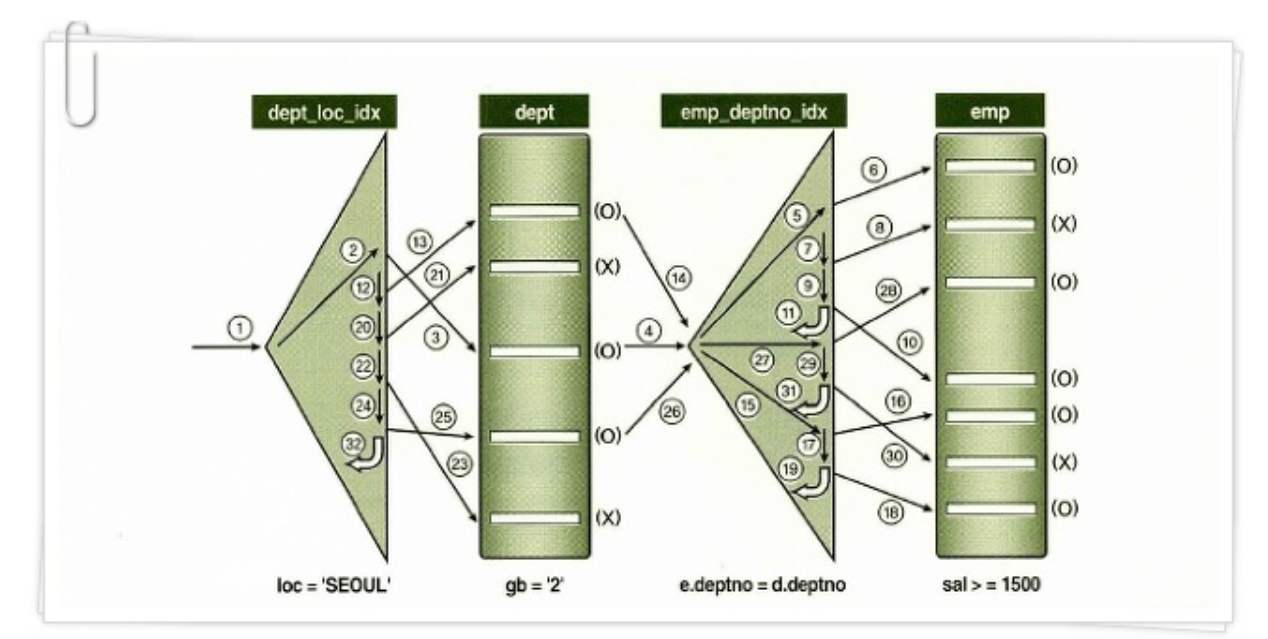
2중 반복문으로 구현이 가능한 Nested Loop Join이다.이 조인 방법은 초대량 테이블에서 아주 나쁜 성능을 보이지만 반대로 극적인 결과를 낼수있다.바로 부분 범위처리에 특화된 특징을 가지기 때문이다.부분 범위처리란?소트 머지조인이나 해시조인같은 경우 PGA에서
11.[DB] Sort Merge Join
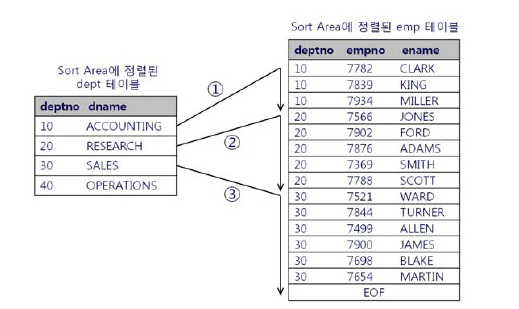
NL조인은 Outer 테이블과 Inner 테이블의 조인키의 인덱스 유무가 매우 중요하다. 인덱스가 없다면 Outer 에서 필터되는 레코드마다 Inner 테이블을 풀스캔 혹은 필터링 할것이고 이떄 많은 비효율이 생긴다.인덱스가 없다면 옵티마이저는 HashJoin과 Sor
12.[DB] 고급 조인 테크닉
선분이력 관련 튜닝먼저 고객테이블과 고객별연체이력 테이블을 생성한다.고객 테이블 총 10건의 데이터고객별 연체이력 (100만건)고객별 연체이력 테이블은 Min 시작일은 2005년 Max 시작일은 2550년도로 100만개의 데이터를 넣었다.이때 인덱스로 고객번호, 종료일
13.[DB] 쿼리 변환 - Unnesting
SQL은 말그대로 구조화된 질의 이다.말 그대로 언어의 한 종류이기에 같은 목적이라도 여러방식으로 표현이 가능하다예를 들어보자.위 두 쿼리는 결과는 같지만 성능은 다를수 있다.쿼리 변환이 작동하지 않을때만 말이다.언제?비용기반 옵티마이저는 서브엔진 으로써 존재하는 Qu
14.[DB] 쿼리 변환 - Push_Subq

먼저 여기서 나오는 Push는 인라인 뷰 안에 조건절을 밀어넣는 조건절 Pushing이 아니므로 헷갈리지 말자.앞서 정리한것 처럼 서브쿼리 Unnesting 되지않은 서브쿼리는 항상 필터방식으로 진행되며 대개 실행계획상 맨 마지막에 처리된다.하지만 서브쿼리의 필터 단계
15.[DB] 쿼리 변환 - 뷰 Merging

위와 같은 쿼리를 자주 볼수있다.왜냐하면 개발자의 입장에서 보다 더 이해가 쉽다.서브쿼리도 조인문보다는 직관적으로 눈에 읽힌다.하지만 옵티마이저는 최적화를 수행하는 입장에서 더 불편하다.그러므로 옵티마이저는 가급적 쿼리블록을 풀어내려는 습성을 가진다. 따라서 다음과 같
16.[DB] 쿼리 변환 - 조건절 Pushing

옵티마이저는 뷰 머징을 여러 이유에서건 실패하였을떄, 바로 2차적으로 조건절 Pushing을 시도한다.단순 뷰에서, 조건절을 인라인뷰 안에넣어서, 조건을 먼저 필터링하고 조인한다면 좋은 성능을 기대 할것이다.조건절 Pushing의 종류조건절 Pushdown : 쿼리 블
17.[DB] 소트 수행 원리

SQL수행도중 정렬이 필요할 때면 PGA메모리에 Sort Area를 할당하는데, 그안에서 처리를 완료할 수 있는지 여부에 따라 두가지 유형으로 나뉜다.메모리 소트 : 전체 데이터의 정렬 작업을 메모리 내에서 완료하는것을말함.디스크 소트 : 할당받은 Sort Area에서
18.[DB] 소트 원리 - 인덱스 활용

인덱스는 컬럼 순서대로 정렬하고 있으므로 이를 잘 활용하면 소트 오퍼레이션을 건너뛸수 있다.예제 1emp 테이블에 sal 단일컬럼을 적용하는 인덱스를 미리 만들어 두었다.이떄, 인덱스를 활용하면 order by를 제거할 수 있지 않을까?결과는 풀 테이블스캔 & 소트 오
19.[DB] 파티셔닝
위와같이 고객 테이블을 생성하면서 range partitioning 하였다.이떄 위와같이 조회할때 9~10 파티션을 두개 읽는것을 확인할 수 있다.왜 하나가 아닌 두개 파티션을 읽을까?20091001 보다 작은 문자는 수없이 많다.ex) 200910, 20091000,
20.[DB] 병렬 처리
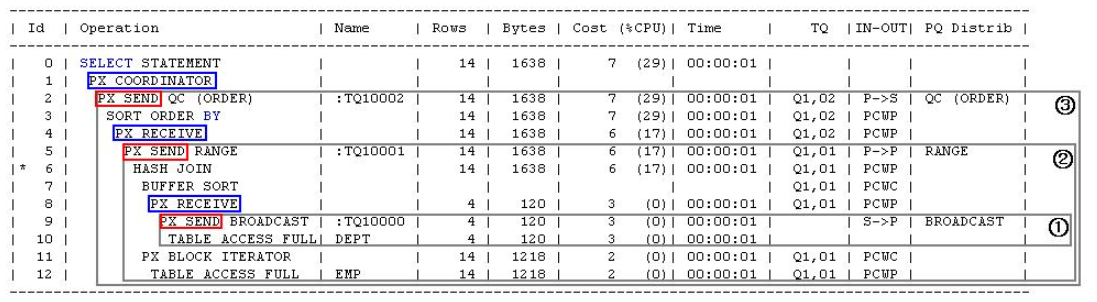
병렬쿼리의 기본매커니즘은 멀티 프로세스(또는 쓰레드)가 동시에 작업을 처리한다는 것을 뜻한다. 다같이 후딱 끝냅시다병렬 처리 관리자 Query CoordinatorQC는 병렬 SQL문을 발행한 세션을 말하고 병렬 서버 프로세스는 실제 작업을 수행하는 개별 세션들을 말한
21.[DB] SQLP 실기문제 - 1

문제 1테이블비효율적 실행 계획위에서 가장 데이터가 많은 테이블을 드라이빙 테이블로 NL 조인하고 있다.그리하여 Product 테이블도 2천만건이나 스캔하며 엄청난 Random 액세스를 발생시키고 결국애는 2000만건을 Distinct하여 500건을 추출한다.이를 튜닝
22.[DB] 바커와 IE 표기법
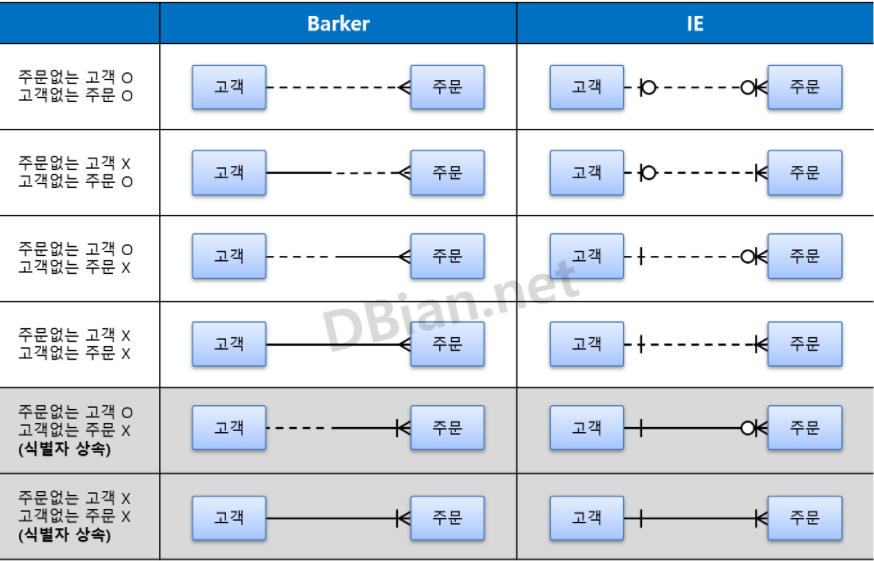
출처 : https://cafe.naver.com/dbian1쪽 M쪽먼저 직선과 세개로 나누어진 닭발 모양의 표시가 보인다.이는 1쪽과 M쪽을 표현한다.즉 고객은 1쪽집합이고 주문은 M쪽집합이다.고객은 여러개의 주문을 할 수 있지만 주문은 여러명의 고객을 가질
23.[DB] SQLP - 핵심 요약

부족한 부분 핵심 요약본
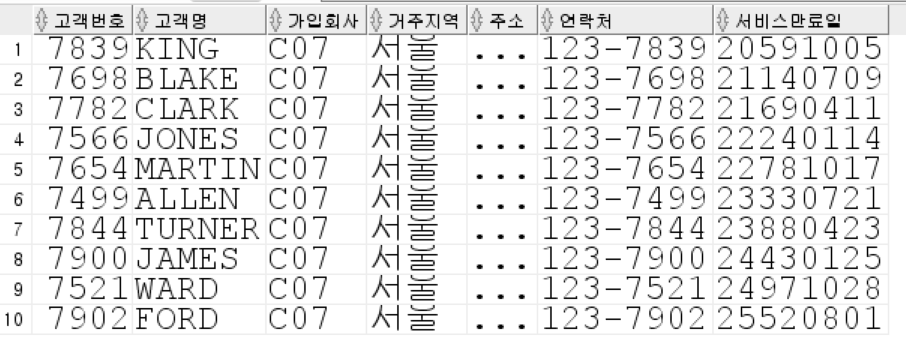
24.[DB] SQLP 실기 - 2
지점, 판매월, 매출을 컬럼으로 가지는 테이블의 월별 누적매출을 윈도우 함수를 사용하여 구하고 사용하지 않고 구하시오파티션 테이블은 인덱스 정의시 파티션 인덱스를 고려하기조인 순서와 방식을 정확히 기술인덱스 적용거주지역 코드와 고객명을 가공하지 않고 정확히 조건지정고객
25.[DB] SQLP 실기 - 3
한번만 테이블을 읽기 위 컬럼을 구하시오 인라인 뷰에서 부서별 사원수, 그것을 정렬한 첫번째값, 역정렬한 첫번째값을 가져온다. 나머지는 sum round 나누기 등으로 연산하고 first_value로 가져온 값을 그룹화 해주기만 하면된다 (인라인 뷰에서 최소사원 등
26.[DB] SQLP 실기 - 4

위 수험결과 테이블에서 90점 이상인 과목을 고득점 결과에 삽입하라.과목 코드 국어 01, 수학 02, 영어 03insert into 에서 모든컬럼을 삽입시 컬럼은 선언하지 않아도됨.인라인 뷰에서 모든쿼리 완료하고 점수 is not null로 90점이하는 제한인라인
27.[DB] SQLP 실기 - 5

위 쿼리에서 order 테이블이 가장 크기가 크지만, orderdt 의 날짜가 2009년 이후인지만 체크하고 있다. 2009년 이후 모든 데이터를 가져와 중복제거를\->원하는 데이터만 가져와 2009년 이후인지만 Exists위처럼 m 테이블 풀스캔,(50건) 을 상품테