# 부분범위 처리 하시오. = [소트 생략] 하시오
-
Gorup by도 소트 생략 가능 -> SORT GROUP BY (NO SORT)
-
인라인뷰 안쪽에 ORDER BY 명시하고 바로 바깥쪽에 ROWNUM <= 조건 명시해야한다.
-
위처럼 잘 작성하면 TOP N STOPKey 발생하고, 만약 인덱스가 불충분해서 전체 데이터 읽더라고 TOP N Sort 알고리즘 발생하여 소트 부하를 줄여준다.
-
IN 조건은 소트생략이 불가능하므로 , 아예 필터로 처리하거나 혹은 맨 뒤쪽에 둔다
-
함수에 스칼라를 씌워버리면 캐싱기능이 작동하여 성능 상승함.
단 입력값의 범위가 작아야함. -
DB저장형 함수에 대한 조건절이 필터 조건이면 필터횟수만큼 실행
-
DB저장형 함수에 대한 조건절이 인덱스 액세스 조건이면 단 1회 수행
-
인덱스의 범위조건 (Between Like 부등호) 까지가 액세스 조건이고 나머지는 필터 조건이다.
-
파티션 = 세그먼트
-
주 파티션, 서브 파티션 체크
-
상수 조회 -> 정적 파티션 Pruning : 액세스하는 파티션 번호 출력 (ex 3 | 4)
-
변수 조회 -> 동적 파티션 Pruning : Pstart/Pstop = KEY
-
파티션 조건절 가공 x
(묵시적 형변환 To_Number, 함수 등 가공하면 모든 파티션 읽음)
묵시적 형변환 때문에 파티션 키 컬럼 형태, 조건절 형태등 세밀히 파악 -
Global 인덱스는 Prefixed만 지원하므로 인덱스 선두컬럼을 파티션 키가 아닌 Non-Prefixed 형태로 구성하면 에러가 발생.
-
Intra-Operation-Parallelism : 서로 배타적 범위 독립적으로 동시에 처리 (통신x)
-
Inter-Operation-Parallelism : 병렬 프로세스 집한간의 통신o
-
병렬도 4일때 P->P 같이 두개의 서버집합이 처리하면 8개의 병렬 프로세스 필요함. 통신도 필요함. ( Inter )
-
병렬도 4일때 P->P 이면 필요한 파이프 라인 수는 병렬도의 제곱 = 16개
-
Full Partition Wise 조인
조인하는 두 테이블이 조인 칼럼에 대해 같은 기준으로 파티셔닝 되어 있으므로 독립적(Intra)으로 조인을 수행하므로
통신 x 병렬도2배 x -
Partial Partition Wise 조인
한쪽만 조인칼럼에 대해 파티셔닝 되어있어 나머지 한쪽을 실행 시점에 동적으로 파티셔닝 하고나서 Partition Wise 조인한다.
동적 파티셔닝 과정에서 재분배가 필요하므로 병렬도 2배 필요. -
오퍼레이션에서 'PX PARTITION RANGE ALL'이 나타난다면
Full Partition Wise을 수행한 것. -
Rownum을 병렬 프로세스들이 처리하면 중복값이 생겨서 QC가 Unique한 값을 생성하기위해 정렬-선택의 과정이 생기므로 병목구간이 발생함.
Rownum보다 ROW_NUMBER() 함수를 사용하여 독립적으로 번호를 부여해야함.
- Granule
- 블록기반 Granule 할당
FullScan, 인덱스 FastFullScan 할 때 해당됨
파티션 여부와 상관없이 DOP를 많이 지정 할수록 빠르다. - 파티션 기반 Granule
IF 파티션 인덱스 일때.
인덱스 RangeScan, 인덱스 FullScan 할 때 해당됨
하나의 파티션을 두개 병렬프로세스가 함 처리할 수 없으므로 서버리소스 낭비 없이 DOP 지정할 것.
- 블록기반 Granule 할당
| InOut | 스펠링 | 설명 | 통신 | 설계 |
|---|---|---|---|---|
| SERIAL | (blank) | 시리얼하게 실행 | - | - |
| S->P | Parallel_From_Serial | QC가 처리한 결과를 병렬 서버 프로세스에게 전달 | O | 직렬 |
| P->S | Parallel_To_Serial | 병렬 서버 프로세스가 처리한 결과를 QC에게 전달 | O | 병렬 |
| P->P | Parallel_To_Parallel | 두개의 병렬 서버 프로세스 집합이 처리 지정한 병렬도의 2배만큼 병렬 프로세스 생성 | O | 병렬 |
| PCWP | Parallel_Combined_With_Parent | 병렬 프로세스 집합이 현재 스텝과 그 부모 스텝을 모두 처리 | X | 병렬 |
| PCWC | Parallel_Combined_With_Child | 병렬 프로세스 집합이 현재 스텝과 그 자식 스텝을 모두 처리 | X | 병렬 |
| 속성 | - 설명 |
|---|---|
| Range | - order by또는 sort group by를 병렬로 처리할 때 - 정렬담당인 두 번째 서버 집합의 프로세스마다 처리범위(ex A~G, H~M, T~Z) 지정하고나서, 첫번째 서버집합이 키값에 따라 분배 |
| HASH | - 조인이나 Hash Group by를 병렬로 처리할 때 - 해시 함수에 적용하고 리턴값에 따라 전송 - P->P 뿐만아니라 S->P 방식도 이뤄질 수 있다. |
| BroadCast | - QC또는 첫 번째 서버 집합에 속한 프로세스들이 각각 읽은 데이터를 두번째 서버 집합에 속한 모든병렬 프로세스에게 전송 - 매우 작은 테이블일때 사용 - P->P 뿐만아니라 S->P 방식도 이뤄질 수 있다. |
| KEY | - 특정 칼럼들을 기준으로 테이블 또는 인덱스를 파티셔닝 할때 사용하는 분배방식 |
| Round-Robin | - 파티션 키, 정렬 키, 해시 함수등에 의존하지 않고 반대편 병렬 서버에 무작위로 분배 |
-
PQ_distribute( inner, Outer 분배방식, inner 분배방식)
-
PQ_distribute (inner, none, none) : 이미 같은 기준으로 파티셔닝 되어 있으므로 바로 Full-Partition Wise Join 시작
-
PQ_distribute (inner, partition, none) : Partial-Partition Wise Join 유도시 사용되며 Outer테이블을 inner 파티션 기준에 따라 파티셔닝 하라는 뜻
-
PQ_distribute (inner, none, partition) : Partial-Partition Wise Join 유도시 사용되며 inner테이블을 outer 파티션 기준에 따라 파티셔닝 하라는 뜻
-
PQ_distribute (inner, hash, hash) : 조인 키 칼럼을 해시 함수에 적용하고 반환값을 기준으로 양쪽 테이블을 동적 파티셔닝 하라는 뜻
동적 파티셔닝 후 Partition Wise Join 수행 -
PQ_distribute (inner, none, none) : 이미 같은 기준으로 파티셔닝 되어 있으므로 바로 Full-Partition Wise Join 시작
-
PQ_distribute (inner, broadcast, none) : outer를 브로드 캐스트 하라는 뜻
-
PQ_distribute (inner, none, broadcast) : inner를 브로드 캐스트 하라는 뜻
-
항상 관계차수 필수로 확인!!!!!!!!!

UNION / UNION ALL 시 각 집합간, 집합내에서 중복 있는지 체크

- 갱신작업 만큼은 Current모드로 읽어 Lost Update를 회피한다.
따라서 t3의 커밋이 완료될 때 SAL 1100을 +200하여 1300이 도출 됨 - Select - Consistent
- Update - Current
- 오라클은 t2시점에 한번 읽고(consistency) commit 후 한번더 읽음(Current)
- SQL Server는 commit후 그제서야 t2 시작함
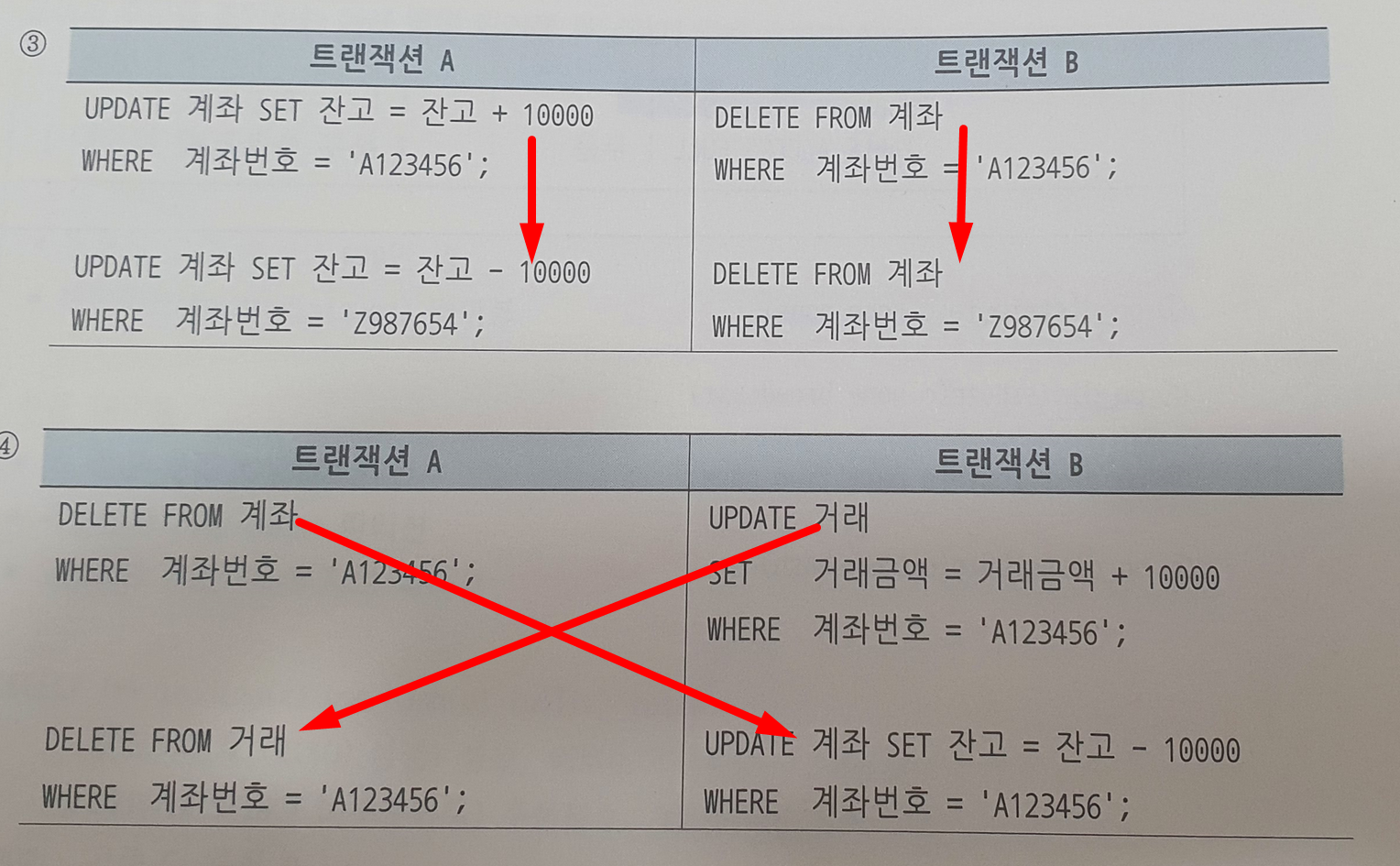
- 3번은 각자 순서 진행으로 block은 발생할 지라도 교착 상태는 x
- 4번은 진행순서상 교착상태 걸릴 수 있음

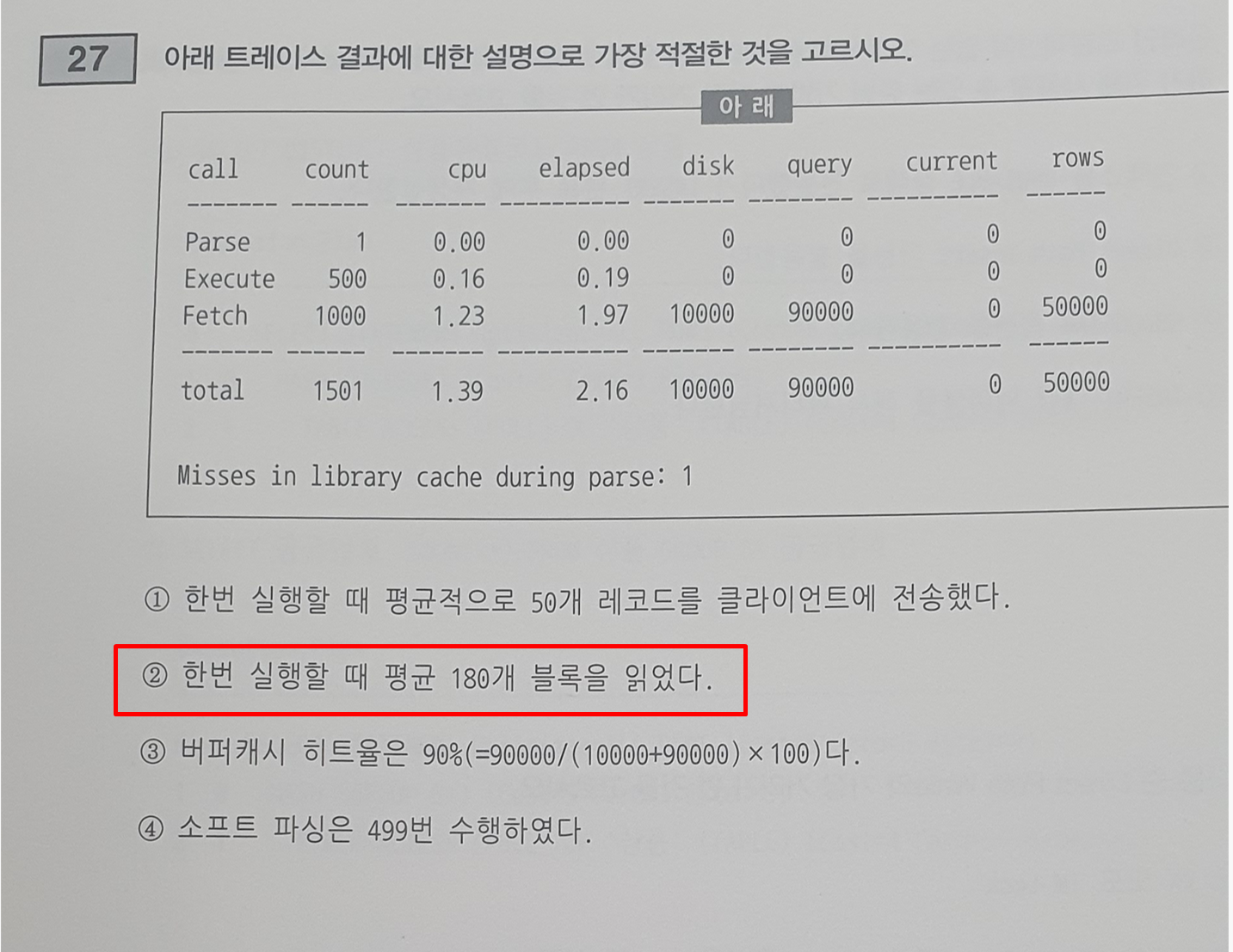
- 실행 Execute 500번 / 출력 50000개
-> 한번 실행할 때마다 평균 100개 레코드 전송 - 실행 500번 / 총 읽은 블록 90000개
-> 한번 실행할 때마다 평균 180개 읽음 - 버퍼캐시 히트율은 1 - disk / query+current
-> 88.89% - 하드파싱 1회, Parse 1회 이므로 소프트파싱 0회
-> Parse 1회 Execute 500회이므로 애플리케이션 캐싱 됨 - Fetch 1000회 레코드전송 50000개 이므로
-> ArraySize는 50으로 설정됨 - Fetch가 이렇게 주로 발생하면 무조건 select임.
-> DML은 Fetch가 발생하지않는다.

- gruop by 표현식이 아닌 값으로 정렬 불가

- 주문일자 액세스 조건이므로 단 1회 함수 실행
- 입금일자는 인덱스 순서상 필터 조건이므로 주문일자를 만족하는 3만건에 대해 각각 함수 실행 (3만건)
- 조건으로 필터한 레코드 2만건에 대해 Select절에서 각각 함수 실행 (2만건)
- 총 대략 5만건 함수 실행함.


- Commit이 수행되어 격리성 수준이 Read Committed로 변환되어 5건 1건이 출력됨


- 상담결과 코드는 화살표 범위
- 색 블록은 상담원 ID가 뭉쳐있는것
- 상담일자가 상담원보다 앞에있으면 상담원 ID가 흩어지고 Group 소트를 생략불가능하다.



- 트랜잭션별 TX Lock 1개
- 테이블 별 TM Lock 1개
- 총 TX 1개 TM 2개
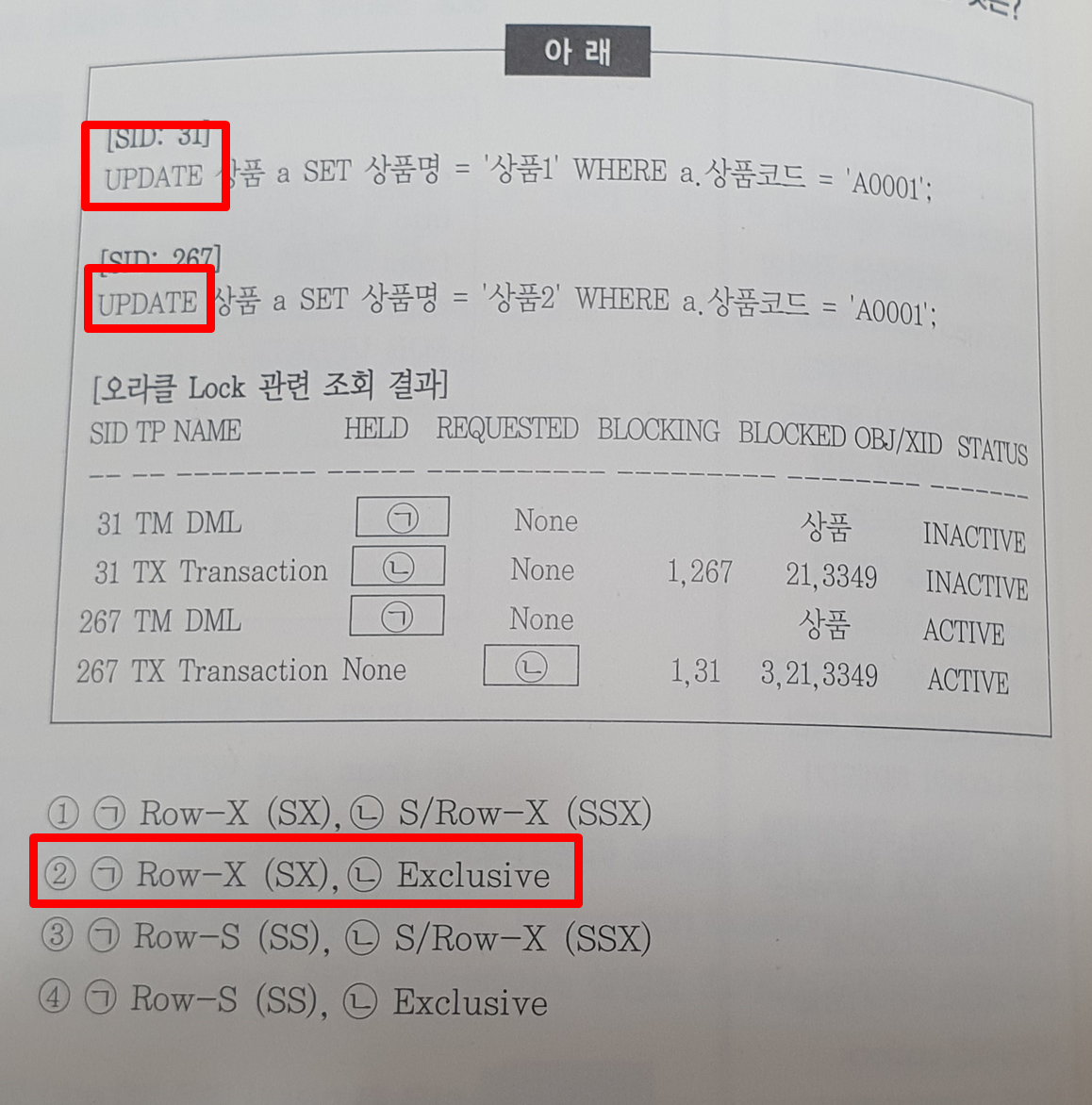
- RX(=SX) : insert, update, delete, merge, select for update (11g이상)
- RS(=SS) : select for update (10g 이하)

- SQL Server에서 insert 중인 데이터를 읽지 않더라도, 인덱스가 없어 풀스캔하거나, 그냥 풀스캔 하면 그 데이터를 지나가므로 블록됨
-
서브쿼리가 드라이빙 테이블이 된것은 서브쿼리 안에서 qb_name으로 이름을 지정하고 메인쿼리에서 서브쿼리 이름을 사용해서이다.
ex) qb_name(subq) -> unnest(@subq) leading(@subq) use_nl(@subq)
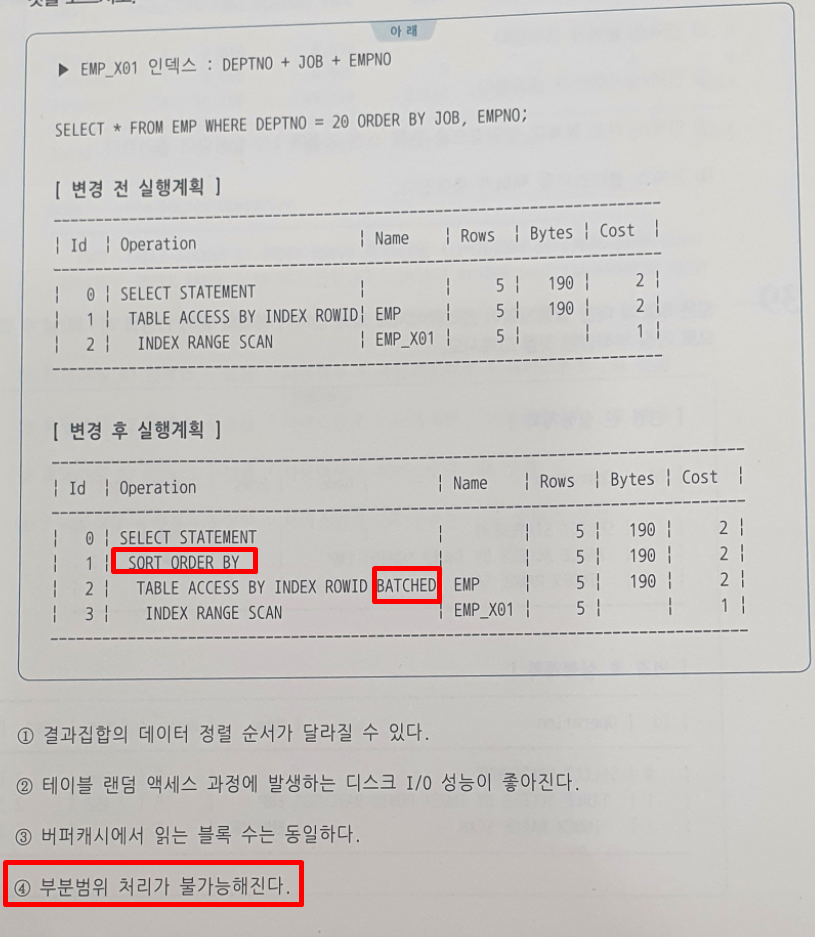
-
배치작업이 일어나면 정렬순서를 보장하지 못함 (BCHR != 100%)
-
SORT ORDER BY 연산이 일어나면 정렬순서 보장 + 부분범위 처리 불가능
-
트랜잭션의 특징( ACID )
- 원자성( Atomicity ) : 트랜 잭션은 ALL OR Nothing - 실행되던지 전혀 실행되지 않던지
- 일관성( Consistency ) : 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환, 실행의 결과로 데이터베이스 상태가 모순되지 않음
- 격리성( lsolation ) : 트랜잭션이 실행 중에 생성하는 연산의 중간 결과는 다른 트랜잭션이 접근 할 수 없음
- 영속성( Durability ) : 트랜잭션이 일단 그 실행을 성공적으로 완료하면 그 결과는 데이터베이스에 영속적으로 저장된다.
-
Buffer State
- Free Buffer : 사용 가능한 버퍼 블록
- Dirty Buffer : 현재 버퍼캐시에서 값이 변경되었지만, 디스크에서는 변경되지 않아 일관성이 없는 상태
- Pinned Buffer : 현재 사용중인 버퍼
- Checkpoint : 새로운 데이터 블록을 적재할 버퍼캐시 공간 확보, 장애 대처 등을 위해 주기적으로 Dirty버퍼를 데이터파일에 기록하는 과정
-
트랜잭션 고립화 수준
- 레벨0 : Read Uncommitted = 커밋되지 않은 데이터를 허용함. Oracle은 이 레벨 지원하지 않음
- 레벨1 : Read Committed = Dirty Read방지, 대부분 DBMS가 기본모드, Non-Repeatable, Phantom Read 는 여전히 발생
- 레벨2 : Repeatable Read = 선행 트랜잭션이 읽은 데이터는 트랜잭션 종료까지 다른 개입 불가. Phantom Read 여전히 발생
- 레벨3 : Serializable Read = 선행 트랜잭션의 데이터를 갱신,삭제 뿐만아니라 삽입도 방지. 완벽한 일관성 제공
SET Transaction Isolation Level Serializable; 로 적용 가능
-

-
For Update문은 Select수행중 Lock을 만나면 같이 진행할 수 없다 NoWait은 Lock 을만나는 순간 에러, Wait 3은 3초간 기다렸다가 에러, 아무것도 없다면 무한정 대기
-
기본 For Update문은 조인 테이블 모두에게 Lock을 건다
-
Lock 은 커밋할때까지 유지
-
인덱스가 없어서 조건절을 만족하는 레코드만 Lock
-
for update는 테이블에 TM Lock 10g 이하는 RS모드, 11g 이상은 RX 모드
-
Snapshot too old : 쿼리를 수행하는 동안 발생하는 다른 Transaction들에 의해 UNDO 세그먼트(롤백 세그먼트) 덮어씌워져서 발생한다.
-
shapshot too old 회피방법
- 불필요하게 커밋 자주수행 x
- fetch across commit 형태 x
- 트랜잭션 몰리는 시간에 배치 프로그램 수행 x
- 부분범위처리, 파티셔닝 활용
- 오랜 시간에 걸쳐 같은 블록을 여러번 방문하는 NL, 테이블 액세스를 수반하는 프로그램 등 체크
- 소트 부하를 감수하더라도 order by를 강제 삽입해 소트연산 실시
- 대량 업데이트 후 풀스캔
-
Redo
- Database Recovery : DB복구
- Cache Recovery : 버퍼캐시와 디스크를 동기화. Undo를 이용해 커밋을 검사하여 완전한 동기화
- Fast Commit : Redo 로그를 믿고 버퍼에만 기록한채 커밋
-
LGWR이 REDO 로그버퍼를 Redo에 기록하는 시점
- 3초마다 DBWR 프로세스로부터 신호를 받을 때
- 로그 버퍼의 1/3 이 차거나 기록된 REDO 레코드량이 1MB 가 넘을 때
- 사용자가 커밋 또는 롤백명령을 날릴 때
-
Undo
- Transaction Rollback : 롤백할때 사용
- Transaction Recovery : 앞에 설명한 Redo에서 비정상 종료를 복구할때 최종 커밋하지않은 변경사항도 복구된다. 이후 Undo 데이터로 커밋하지않은 트랜잭션을 모두 롤백한다.
- Read Consistency : 읽기 일관성에 사용된다.
예를들어 사용자a의 변경사항을 커밋하지 않을때 사용자 b는 커밋되지 않은 변경사항을 볼 수 없다.
-
블록원본인 Current Block의 SCN 이 쿼리 SCN 보다 크면
복사본인 CR Block을 생성. CR Block 을 읽을수 있는 레벨까지
Undo를 활용해 과거로 되돌린다. -
Wirte Ahead Logging : 버퍼 캐시블록을 갱신하기 전 변경사항을 먼저 Redo 로그 파일에 기록한걸 보장해야함
-
Log force at Commit : 최소한 커밋할때는 데이터 파일에 써야함
-
Delayed Block : 커밋시점에 블록을 Cleanout 하지않고 그대로 두엇다가 나중에 해당 블록을 읽는 세션이 이를 정리하도록 하는 것
-
커밋 절차
- 커밋
- 서버 프로세스가 Redo 로그버퍼에 커밋 레코드 기록
- LGWR에 신호 보낸후 대기
- LGWR은 Redo 로그버퍼를 디스크 로그파일에 기록 후 완료
- 변경된 버퍼블록이 커밋시점에 바로 데이터 파일에 기록되진 않는다. 나중에 DBWR에 의해 기록됨.
- 디스크 로그파일에 작성만 하면 언제든 복구 가능
-
뷰Merge가 불가능한 쿼리
- 집합 연산자(union, union all, intersect, minus)
- connect by 절
- RowNum
- select-list에 집계함수 사용 (group by없이 전체를 집계하는 경우를 말함)
- 분석 함수
-
소트 오퍼레이션
- Sort Aggregate : 집계함수에서 발생, 실제 소트 발생하지 않음
- Sort Order By : Order By 에서 발생
- Sort/hash Group By : 그룹별 집계함수에서 발생
- Sort/hash Unique : Union, Minus, Intersect 등 집합 연산자, Unnesting된 서브쿼리가 M쪽 집합이거나, Unique인덱스가 없을때, 세미조인도 아닐때 조인하기전에 발생,Distinct
- Sort Join : 소트 머지 조인
- Window Sort : 분석함수 수행시 정렬 발생
- Sort Area에서 작업을 완료하는것을 Optimal 소트
- Disk 공간까지 사용하여 작업하는것을 External 소트
- Temp 영역에 저장해둔 집합을 Sort Runs
- 디스크에 한번만 기록하고 완료 Onepass 소트
- 디스크에 여러번 기록하고 완료 Multipass 소트
- temp 테이블 스페이스에 쓰고 다시 읽을때 대기이벤트 2가지
> Direct path write temp
> Direct path read temp
-
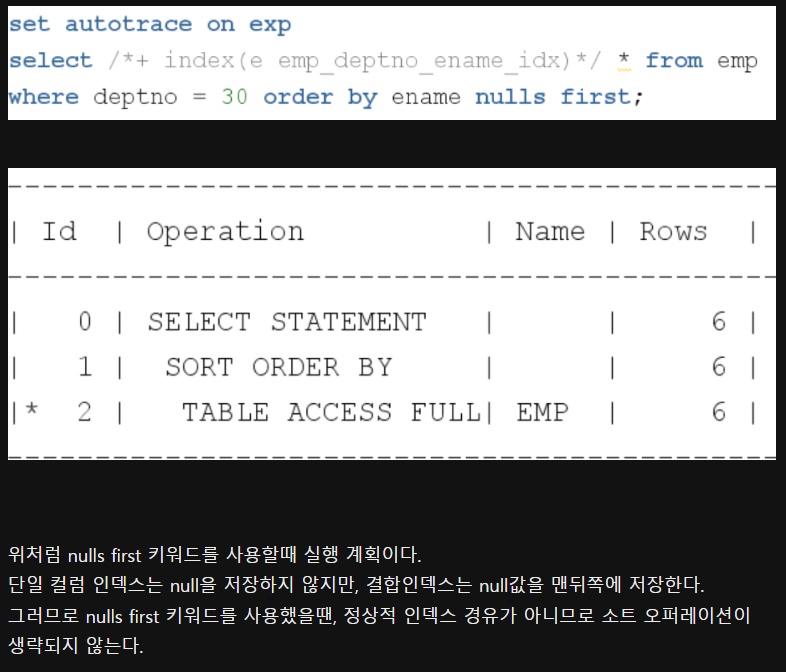
Null 허용 컬럼은 인덱스 정렬 불가능 (결과집합에 변동가능성)
-
결합 인덱스에서 Nulls first 시 정렬생략 불가능 (null포함 데이터는 맨뒤에 있기때문)

-
Oracle
- 위 그림에서 오라클은 ㄴ을 시작하는 시점에 C1=2인 레코드가 없으므로 변경 x
- Oracle : Create table에 대해 묵시적 Commit 발동
- Oracle에서 '' Insert시 Null로 입력
- Serializable 일때 Select문은 Lock없음
-
SQL Server
- 위 그림에서 SQL Server는 ㄱ이 끝나기를 기다렸다가 ㄴ을 실행한다.
- SQL Server : Create table에 대해 묵시적 Commit 발동안함
- SQL Server에서 '' Insert시 ''로 입력됨 (문자)
- Select문에서 DML과 마주치치 않는 레코드 조회는 Block 안됨 ex) 인덱스 경유로 인해 마주치치 않음
- Read Committed 일때레코드 읽기전에 Lock을 걸고 다음레코드로 이동하는 순간에 해제
- Repeatable Read 일때 레코드를 읽기전에 Lock을 걸고 커밋&롤백 시 해제
- PK 제약 조건 Create table ~ Constraint product_pk primary key (prod_id)
- TO_CHAR(END_DATE, 'YYYYMM') = '201501'
- 2015년 1월의 모든 데이터 가능
- TO_DATE('201501', 'YYYYMM') = END_DATE
- 2015년 1월 1일 0시 0분 0초 찰나의 순간만 적용됨
- 2015년 1월 1일 0시 0분 0초 찰나의 순간만 적용됨
- 1과목
- 모델링 정의: 추상화(모형화), 단순화, 명확화 하는것
- 데이터 모델링의 중요성: 파급효과, 간결한 표현, 데이터 품질
- 데이터 모델링 유의점 : 중복. 비유연성. 비일관성
- 개념적 모델링 - 추상화 업무 중심적 포괄적
- 논리적 모델링 - 키 속성 관계 등 정의
- 물리적 모델링성능 저장등 물리적 성격 정의
- 외부스키마 : 사용자 관점, 접근하는 특성에 따른 스키마 구성
- ----논리적 독립성 : 개념 스키마 변경되어도 위부스키마에 영향 없음.
- 개념스키마 : 통합 관점, DB 데이터와 사용자 간의 관계를 표현
- ----물리적 독립성: 내부 스키마 변겨오디어도 외부,개념 스키마에 영향 없음
- 내부스키마 : 물리적 저장구조 관점
- 모델링 세가지 요소
- 업무가 관여하는 어떤 것 : Things (Entity)
- 어떤 것이 가지는 성격 : Attributes
- 업무가 관여하는 어떤 것 간의 관계 : Relationships
- 엔터티
- 명사
- 업무상 관리가 필요한 관심사
- 저장이 되기 위한 어떤 것(Things)
- 다른 엔터티와 관계 필수, 인스턴스 2개이상, 속성 2개 이상, 식별가능, 업무에 이용 필수
- 엔터티 이름 약어 x
- '학생' 엔터티는 '학번 이름' 등의 속성을 가짐.
- 유무형에 따른 엔터티 분류
- 유형 엔터티 : (사물)
- 개념 엔터티 : (보험)
- 사건 엔터티 : (주문, 청구)
- 발생 시점에 따른 분류
- 기본 엔터티 : (사원, 부서)
- 중심 엔터티 : 업무 중심적 (계약, 주문, 청구)
- 행위 엔터티 : 두개 이상의 부모엔터티로 발생 (주문목록)
- 속성
- 의미상 더 이상 분리되지 않는 최소의 데이터 단위
- 각각의 속성은 하나의 속성값만 가짐
- 업무에서 필요, 엔터티를 설명하고 인스턴스의 구성요소
- 속성에 따른 분류
- 기본 속성 : 업무로 부터 추출한 모든 속성
- 설계 속성 : 업무 이외에 모델링을 위해 새로 정의(시퀀스)
- 파생 속성 : 다른 속성에 영향 받음 (계산 값)
- 관계
- 존재에 의한 관계 (소속)
- 행위에 의한 관계 (주문)
- 관계명 : 관계의 이름 (현제시제 동사로 기술)
- 관계차수 : 1:1 1:M M:N
- 관계 선택 사양 : 필수관계(지하철 문), 선택관계(지하철 방송) ER 표기법 학습 필수
- 식별자
- 주식별자 <> 보조식별자 : 대표성을 가지는가?
- 내부식별자 <> 외부식별자 : 스스로 생성되었는가?
- 단일식별자 <> 복합식별자 : 단일 속성으로 식별이 되는가?
- 본질식별자 <> 인조식별자 : (대체여부) 임의로 새롭게 만들었는가?
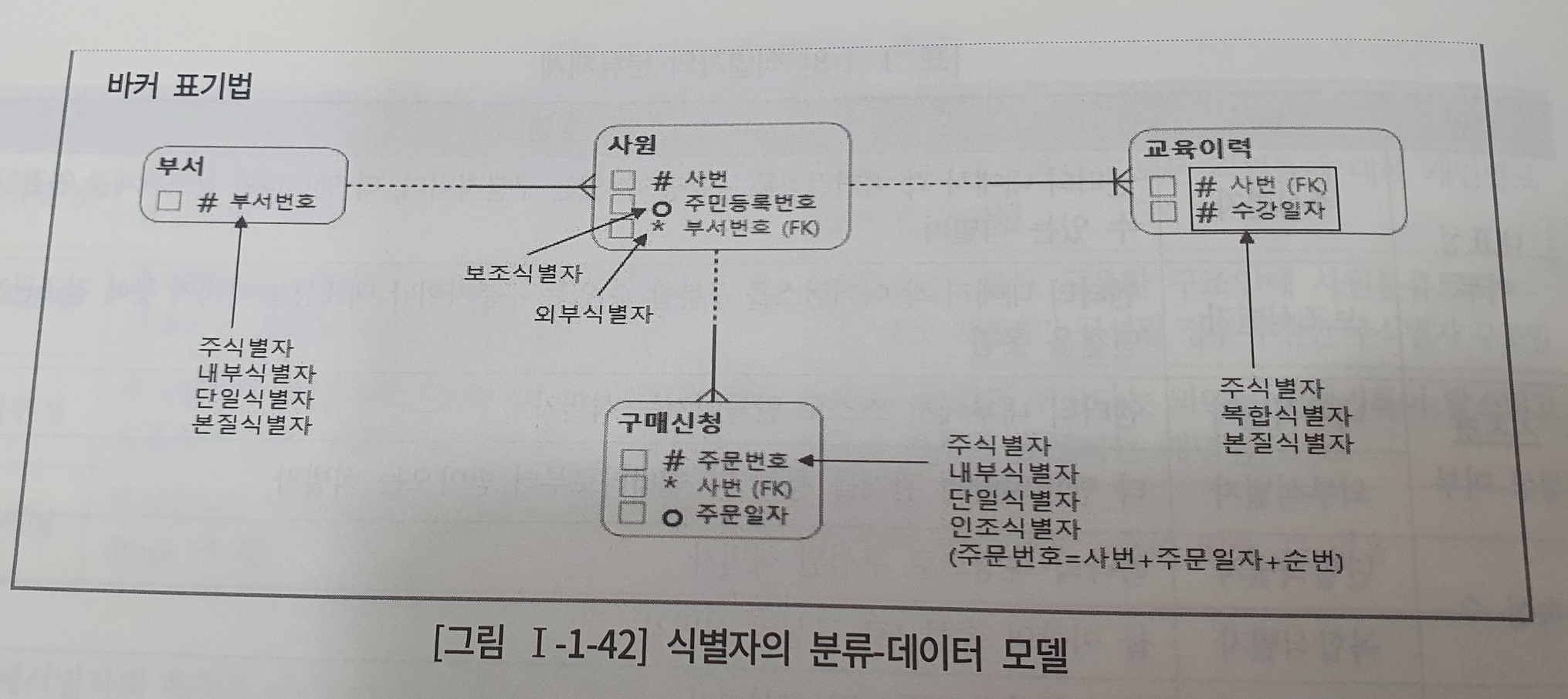
- 주식별자 : 유일성, 최소성, 불변성, 존재성
- 업무와 관련된 속성을 지정 : 사원번호 o / 주민번호 x
- 속성수 많지 않게 설정
- 명칭, 내역과 같이 이름으로 기술되는것은 피함.
(부서이름 보다는 부서코드로 설정)
- Unique Key (고유키)는 유일성을 만족하지만 Null값 가능
-
1정규형 : 하나의 속성은 하나의 값만 가진다.
혹은 하나의 엔터티에는 반복되는 속성을 가지지않는다. -
2정규형 : 함수적 종속성 제거
일반 속성은 주식별자 전체에 대해 식별되어야 한다.
주식별자(주문번호, 상품번호) 속성(상품명) -
3정규형 : 이행함수 종속성 제거
일반 속성이 일반속성에게 식별될때. -
반정규화 기법
> 중복칼럼추가 : 여러 테이블에 동일 컬럼 추가
> 파생칼럼추가 : 조회 성능 위해서 미리 계산된 칼럼 추가
> 기능성 칼럼추가 : 최신값 처리하는 이력특성 고려 -
OLTP 환경이라도 3티어인 클라이언트와 서버 연결을 지속하지 않는 환경(웹 브라우저, 쇼핑몰 등)이라면 최초 응답속도 최적화가 아닌 페이징 처리된 쿼리를 전체 처리속도 최적화가 맞다.
-
조건절의 In 키워드는 인덱스로 조회시 비효율은 없을 수 있으나 수직탐색을 반복하는 비효율이 존재할 수 있음
-
Case When C1='none' Then 'false' Else 'true' END
-
단일행 서브쿼리는 단일행, 다중행 비교 연산자 모두 가능
-
다중행 서브쿼리는 다중행 연산자만 가능
-
SQL : 구조적, 집합적, 선언적
-
선택도 = 조건절 범위 / 전체 범위 (등치 조건)
-
선택도 = 1 / Distinct Value 갯수 (부등호, Between 조건)
-
카티널리티 = 총 로우 수 * 선택도
-
Elapsed time = CPU time + Wait time = Response 시점 - Call 시점
-
Response Time = Service time + Wait time = CPU time + Queue time
-
힌트안에 인자끼리는 콤마 사용가능, 힌트끼리는 콤마 x
-
테이블 지정시 스키마 까지 명시 x
-
from절에 별칭 사용하면 힌트에 반드시 별칭사용
-
set arraysize 2;
-
ROLE을 이용하면 권한 부여와 회수를 쉽게 할 수 있다.
-
Granule 병렬쿼리 최소단위
-
Append모드로 insert하면 Exclusive모드의 TM락이 걸린다.
-
Nologging모드는 Insert문에만 가능하다. (update 불가능)
-
ArrayProcessing은 Insert into Select 문보다 성능이 떨어짐
-
delete 문보다 truncate가 redo undo 안쓰므로 효율적임
-
애플리케이션 커서를 캐싱해야 하드파싱1회로 계속 사용가능
-
함수형 조건문의 컬럼이 인덱스 액세스 조건이라면 단 1회만 함수실행, 필터조건이라면 건건이 함수 실행
ex) where 생년월일 like '1970%'
and 전화번호 = encryption( :phone);
일때 전화번호가 선두컬럼이어야 1회만 실행됨 -
List 파티션은 단일 컬럼으로만 파티션 가능
-
Hash 파티션은 해싱알고리즘으로 파티션 하므로 값이 몰리는 현상 발생할 수 있음. 해결 방법은 분포도를 따져가며 파티션 기준 선정
-
상수형 조건절은 정적 파티션 Pruning 작동 - 최적화 시점에 미리 결정, 실행계획에는 파티션 번호가 적힘
-
바인드 변수형 조건절은 동적 파티션 Pruning 작동 - 실행시점
실행계획의 Pstart Pstop에는 Key라고 적힘 -
index range scan은 파티션 갯수만큼의 병렬도가 최적이다
-
full scan은 병렬프로세스 DOP가 많으면 많을수록 빠르다
-
Index Skew : 인덱스 엔트리가 한쪽에 치우치는 현상
-
Index Sparse : 인덱스 전반적으로 밀도가 떨어지는 현상
-
비트맵 인덱스
- 대용량 DW (특히 OLAP) 환경에 적합
- Distinct Value 적으면 저장효율 좋음
- Lock에 의한 부하 심함
-
Grant Select, Update on tbl to User
업데이트는 select와 update 둘다 권한 줘야함. -
With Grant Option 주면 대상이 권한을 줄 수 있는 권한이 생김

-
단일컬럼 인덱스에서 Null 저장안함. 검색불가
-
결합 인덱스에서 null 검색시 둘다 null허용이면 불가능.
-
만약 위에서 부서번호가 Not null이면 3번 쿼리도 가능.
-
조건절에서 문자형 컬럼에 숫자 대입하면 안됨
where To_number(컬럼) = 100 인덱스 사용 불가 -
조건절에서 숫자형 컬럼에 LIKE 사용하면 안됨
where To_Char(계좌번호) LIKE :no || '%' -
조건절에 or 로 인덱스를 사용하려면 or 양쪽 둘다 인덱스 range scan이 가능해야함. 아니면 Use_concat 사용하여 UNION ALL로 분기하지 않는다.
-
선분이력에서 최근 시점을 주로 조회 : 종료일자를 선두로 검색
-
선분이력에서 과거 시점을 주로 조회 : 시작일자를 선두로 검색
-
해시조인은 =조건이 많을수록 해시 맵을 세밀하게 구성하여 충돌률을 낮춘다.
-
스칼라 서브쿼리는 반드시 캐시 영향을 고려하여 사용
-
필수/옵션 관계의 구조일때 스칼라 -> 일반 조인시 Outer 조인 고려해야함
-
1:M M:1 구조일때 일반조인 -> 스칼라시 집계함수 / Rownum <=1 고려해야함
-
~~개 상품/ 주문 등을 고르게 입력한다 or 주문한다 -> 해시 조인시 충돌 낮음 암시하므로 해시조인 검토
-
규칙기반 옵티마이저는 통계정보 전혀 활용 x
-
바인드 변수는 최적화 과정에 컬럼 히스토그램 사용 못하므로 상수값을 사용할 때보다 안좋은 실행계획을 세울 가능성이 있음
-
라이브러리 캐시: SQL문을 캐싱하여 같은 실행계획을 바로 사용함
-
세선 켜서 캐싱 : SQL문과 공유커서를 가르키는 포인터 저장
-
애플리케이션 커서 캐싱 : 라이브러리에서 SQL을 찾는 과정을 생략하고 바로 반복적 수행. (Parse != Execute)
-
파티셔닝 된 테이블 풀스캔 하면 조건절에 알맞게 스캔함.
-
Index FFS : 세그먼트 전체를 스캔, 순서 보장x, MultiBlock IO, 병렬스캔 가능, 인덱스에 포함된 컬럼만 조회 가능
-
인라인뷰가 있는데도 실행계획에 VIEW가 없다면 뷰머징이 발생한 것.
-
내장 함수
함수 내용 LOWER 소문자로 변환 UPPER 대문자로 변환 CONCAT 문자 결합 SUBSTR 문자 자르기 LENGTH, LEN 문자 길이 LTRIM, TRIM, RTRIM 소문자로 변환 ASCII 문자 -> ASCII코드 CHR ASCII코드 -> 문자 LPAD, RPAD (값, 총길이, 채움문자) ----------------------------------------- ----------------- ABS 절대값 SIGN 음수,양수,0 판별 MOD (A,B) A%B CEIL 큰 정수 리턴 FLOOR 작은 정수 리턴 ROUND 반올림, 소수점자리 지정 TRUNC 소수점 버림, 자리지정 ----------------------------------------- ---------------- SYSDATE 오늘날짜 시간 EXTRACT('YEAR', 'MONTH', 'DAY' FROM DATE) 날짜 추출 TO_CHAR(DATE,'YYYY') 날짜 추출 TO_NUMBER 숫자로 변환 TO_DATE0 날짜로 변환 -
분석 함수
- 순위 : Rank, Dense_Rank, Row_Number
- 순서 : First_value, Last_value, LAG, LEAD
- 비율 : CUME_DIST, PERCENT_RANK, NTILE, RATIO_TO_REPORT
- 문법 : WINDOW_FUNCTION (인수) OVER (Partition, order, windowing)
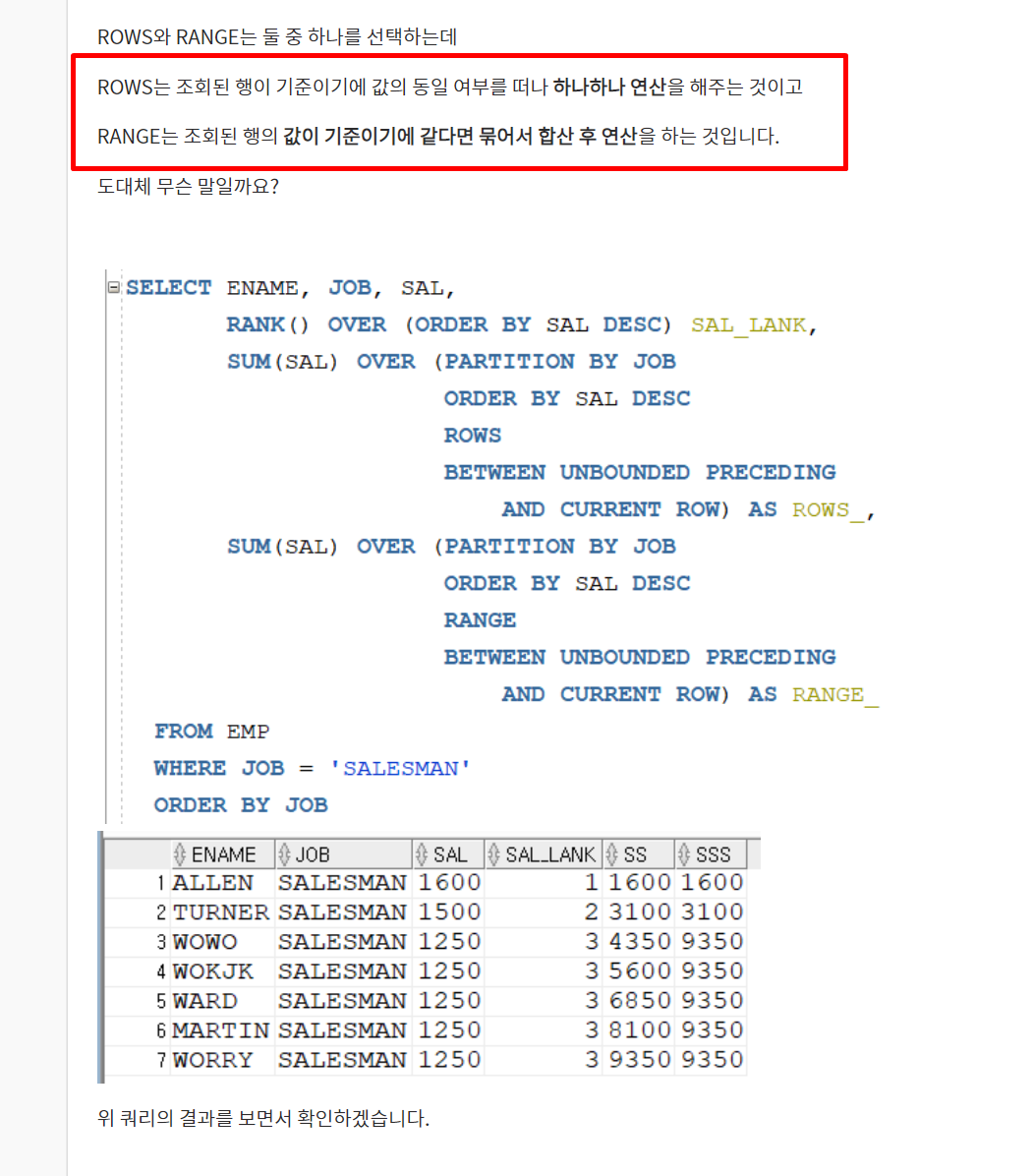
- Rows Unbounded Preceding : 파티션 내 첫번째 행부터 현재 행까지
- Rows Between 1 Preceding and 1 Following : 현재행 기준으로 앞의행 하나, 다음행 하나까지 대상으로 한다.
- Range Between 50 Preceding and 150 Following : 현재행 기준으로 -50 ~ +150 까지의 행을 대상으로 한다.
- Rows Between Current row and Unbounded Following : 현재행 기준으로 마지막행 까지를 대상으로 한다.
- ROWS BETWEEN UNBOUNDED PRECEDING AND 4 Following : 처음 행부터 지금행+4 까지 0~(now+4)
- ROWS BETWEEN UNBOUNDED PRECEDING AND 4 Precending : 처음 행부터 지금행-4 까지 0~(now-4)
| 함수 | 내용 |
|---|---|
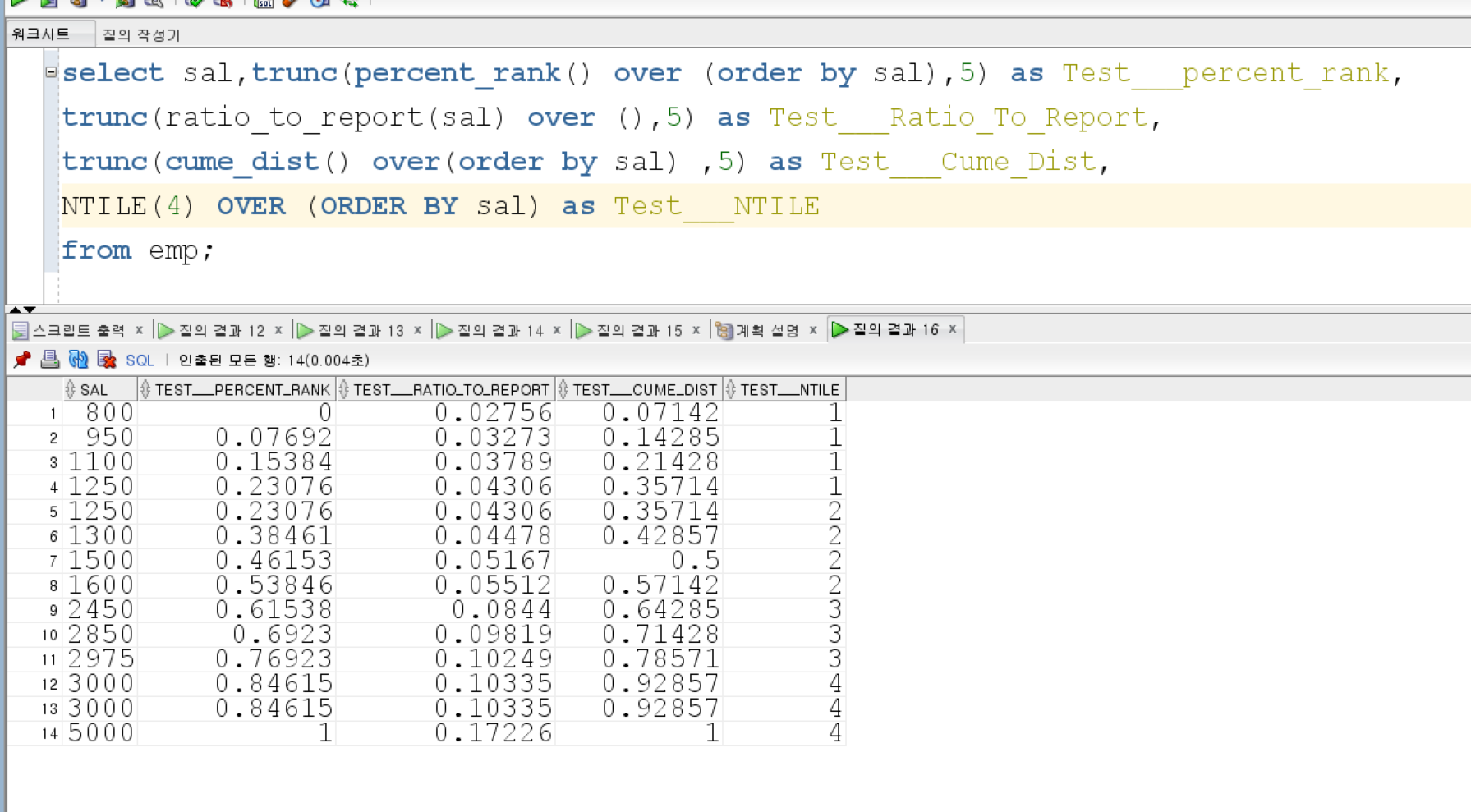
| RATIO_TO_REPORT (백분율을 소수점) | 0.22 0.29 0.22 0.27 |
| PERCENT_RANK (순서별 백분율) | 0.00 0.50 1.00 |
| CUME_DIST (누적 백분율) | 0.33 0.67 1.00 |
| NTILE (4) (테이블을 4등분으로 나누고 각 구역에 순서를 매김) | 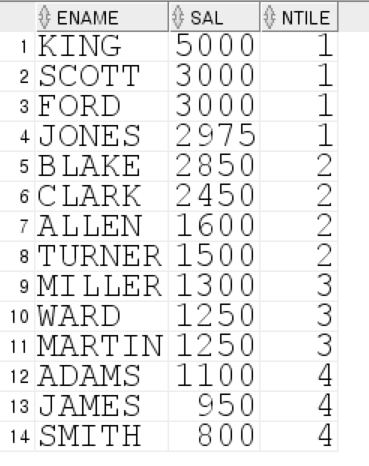 |
- 그룹 함수
- Grouping sets(a,b,c,()) = a, b, c, ()
- RollUp(a,b,c) = abc, ab, a, ()
- CUBE(a,b) = a, b, ab, ( )
- 계층 함수
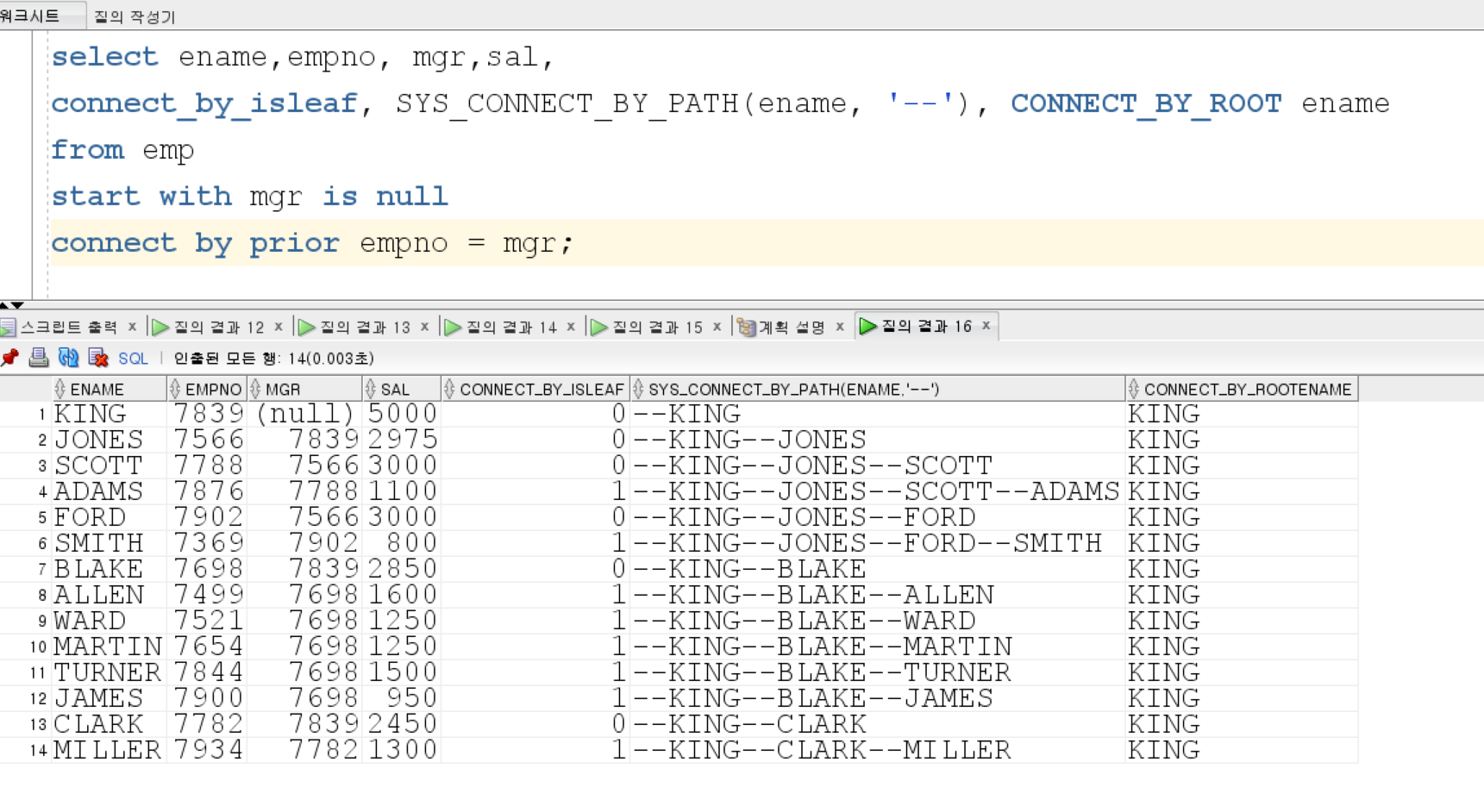
- Level : root 는 1이고 Leaf까지 1씩 증가
- CONNECT_BY_ISLEAF : leaf라면 1
- CONNECT_BY_ISCYCLE : 자식이 조상일떄, 1 아니면 0
- SYS_CONNECT_BY_PATH : (칼럼, 구분자) 로 루트부터 자신까지 경로
- CONNECT_BY_ROOT : 루트를 출력
- start with 구문의 행은 무조건 출력
| 조건 | 쿼리 |
|---|---|
| 루트의 조건 | start with mgr is null and sal > 3000 connect by prior empno = mgr |
| 계층의 조건 | start with mgr is null connect by prior empno = mgr and sal > 3000 자식의 급여 3000이상 ----------------------------------------- start with mgr is null connect by prior empno = mgr and prior sal > 3000 부모의 급여 3000이상. ----------------------------------------- |
| 결과의 조건 | where sal > 3000 start with mgr is null connect by prior empno = mgr |
- NULL
- NVL(a,b) : a가 NULL이라면 b를 반환
- NVL2(a,b,c) : a가 NULL이 아니라면 B / a가 NULL 이라면 C
- ISNULL(a,b) : a가 NULL이라면 b를 반환
- NULLIF(a,b) : a == b라면 NULL을 반환, 아니라면 a를 반환
- Coalesce(a,b,c) : abc순서대로 NULL이 아니라면 반환
- Decode(a,b,c,d) : a와 b가 같으면 c를 반환 아니라면 d를 반환
- Clustering Factor (CF, 클러스터링 팩터)
- Table Prefetch : 한번의 Disk I/O를 통해 곧 읽을 가능성이 큰 블록을 미리 적재
- 힌트
| 힌트 | 내용 |
|---|---|
| ALL_ROWS | 모든 로우를 출력하는것을 목표로 실행계획 수립 |
| FIRST_ROWS | 조건에 맞는 첫번째 row를 리턴하는 실행계획 수립 |
| FULL(table) | table FullScan |
| HASH(table) | Hash Scan |
| INDEX(table index) | Index Scan |
| INDEX_DESC(table, index) | 해당 테이블 특정 인덱스로 내림차순 스캔 |
| INDEX_FFS(table, index) | 인덱스 Fast Full Scan |
| ORDERED | From 절에 기술된 순서대로 Join 진행 |
| Leading(table1, table2 . .) | 기술한 순서대로 조인 진행 |
| USE_NL, USE_HASH, USE_MERGE | 조인 방식 |
| Unnest | 서브쿼리를 풀어내어 조인 |
| No_Unnest | 서브쿼리를 풀어내지 않고 실행 |
| HASH_AJ, NL_AJ, MERGE_AJ | 안티 조인 (Not Exists) |
| HASH_SJ, NL_SJ, MERGE_SJ | 세미 조인 (Exists) |
| push_subq | 서브쿼리를 먼저 실행 (항상 No_Unnest) |
| no_push_subq | 서브쿼리 push를 방지 |
| merge | 뷰 머징 실행 |
| no_merge | 뷰 머징 방지 |
| push_pred(table) | 조인 조건 PushDown (항상 no_merge, use_nl) |
| no_push_pred(table) | 조인 조건 PushDown 방지 |
| swap_join_inputs(table) | Hash Join에서 Build Table 지정 |
| no_swap_join_inputs(table) | Hash Join에서 Build Table 지정 안함 |
| append | direct Path Insert를 활용하여 버퍼캐시를 거치지않아서 빠름 |
| alter table table_name nologging; | 로그 남기지 않게 설정 |
| alter session enable parallel dml; | 대량 인서트시 병렬로 가능 |
| NOPARALLEL(table) | Parallel Query 방지 |
| PARALLEL(table, degree) | Parallel Query 실행, process 갯수 지정 |
| PARALLEL_Index(table, index) | 병렬로 인덱스 스캔 |
| use_concat | OR_Expansion 지정 실행 계획에는 CONCATENATION 출력 |
| No_Expand | OR_Expansion 지정 안함 |
| qb_name(subq) | 메인쿼리에서 사용할 수 있도록 서브쿼리의 이름 지정 사용시엔 unnest(@subq) / leading(거래@subq) 로 사용 |
| pq_distribute | (inner집합, outer집합 분배방식, inner 집합 분배방식) |
| Materialize | WITH 문으로 정의한 집합을 물리적으로 생성하도록 유도 WITH /*+Materialize*/ T AS (select-- |
| Inline | WITH 문으로 정의한 집합을 물리적으로 생성하지 않고 Inline으로 처리하도록 유도 |
| No_NLJ_Batching | 배치 NL 조인 방지 |
| FORCE ORDER | SQL Server에서 Ordered의 역할 |
| Hash, Sort Group | Group by 수단 지정 |
| LOOP JOIN | NL 조인 |
| from emp with (forceScan) | Fullscan |
| from emp with (forceSeek) | 인덱스 스캔 |
- 선분이력 인덱스 설계시 시작일자와 종료일자 분포도에 따른 조회조건이 어느정도 효율인지
- 월별 Range 파티셔닝을 like '200910%' 와같이 조회할땐, 10월만 읽을순 없다. 9월에도 있을수 있기에.
- between '20091001' and '20091031'과 같이 정확하게 조회한다
- 드라이빙 테이블이 작은테이블
- OLTP는 NL조인, 배치나 대용량은 Hash조인
- 인덱스 컬럼 추가로 테이블 랜덤 액세스 방지 고려
- 인덱스 정의시 local index 등 고려
- 컬럼을 가공하지 않기
- union all로 여러 조건에 대비하여 최적의 쿼리문 작성
- 정렬은 마지막에
- date 컬럼 정확히 기술
- add_months(sysdate, 1) to_date('20201020', 'yyyymmdd') +1 등
- 페이징시, 조건과 정렬을 마치고, 1차 페이징, 2차 페이징 순서
- left outer join은 왼쪽 테이블 기준
- 인라인 뷰에서, 총점, 부서최대사원수 등을 Window함수로 빼놓고 select list에서 가공
- 파티션 키 값으로 정확히 조인해야 Partition Pruning 발생.
- 일자, 시간등 정확히 기술
- 인라인 뷰에서 dual connect by level = 3 등으로 복제하여 select 문에서 case 문법으로 분기
- count(case when id = 'z2005' then 1 END )
- 세미조인으로 존재 체크, unnest nl_sj
- order by case :value when 'Price' then Price END desc 등으로 정렬이 가능. 변수값에 따라 대응

- 대용량 insert 배치일떄, alter table table_name nologging; 으로 로그남기지 않게 설정
- 그 후 Append 힌트로 insert 설정. Parallel은 자동으로 nologging
- 대신 alter session enable parallel DML로 병렬로 한다고 먼저 미리 설정해야함
- nologging 옵션은 Direct Path Insert 할 때만 작동함.
- Direct path Insert = Exclusive 모드 TM 락 걸려서 다른 프로세스들은 이용 못함, 한마디로 주간에 사용 불가능
-
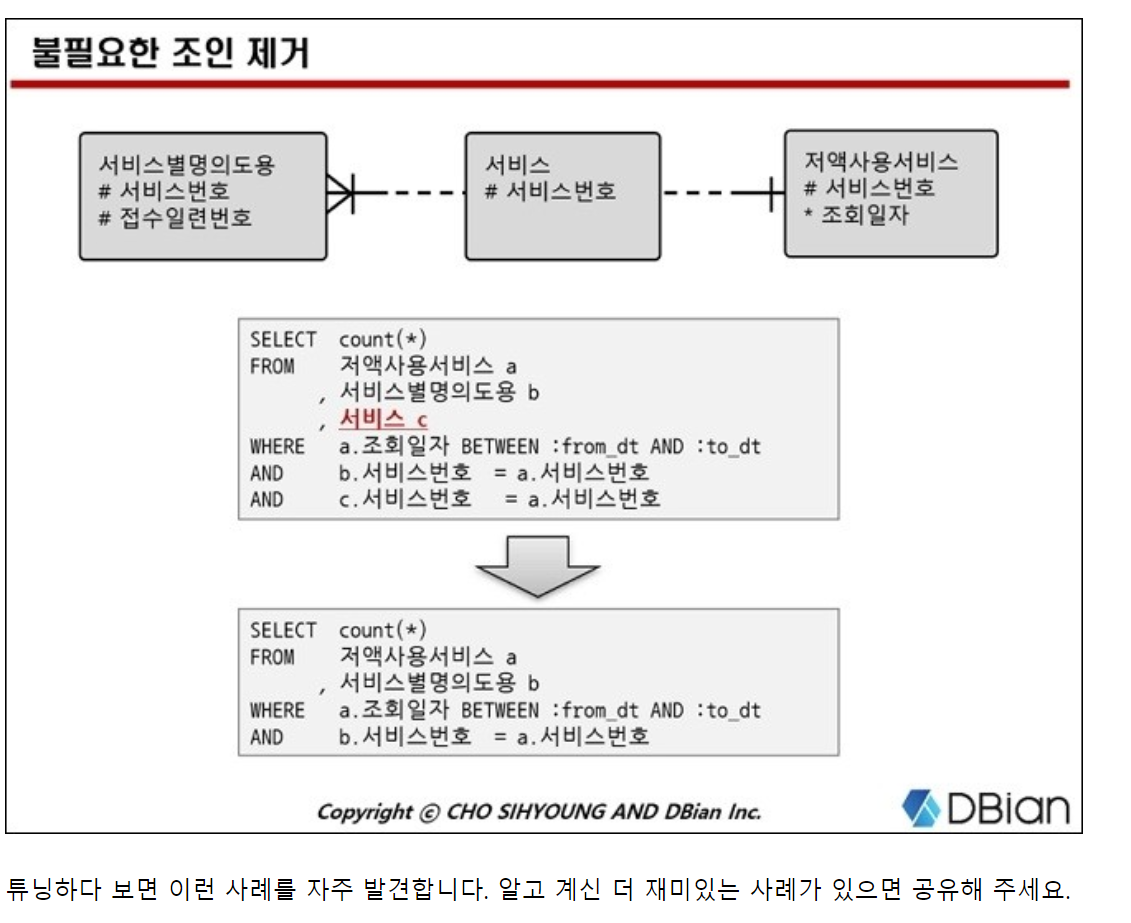
Select 절을 분석하여 불필요한 조인이 있는지 검토 필수, 튜닝 중 제일 먼저 분석하길
-
스칼라 서브쿼리, 중첩 서브쿼리 등 일때 1:M인지 체크할것, 1:M이라면 에러나므로 rownum을 하던지 그룹화 하던지해서 1:1로 맞춰야함
-
소트 연산 생략은 곧 부분 범위 처리와 같다. 소트 생략의 목적이 전부다 읽고 소트가 아닌 필요한 부분만 읽을려고 하는것이다.
곧 소트연산 생략 = 부분 범위 처리 = NL 조인
실행계획의 블록, 로우 출력값을 보고 어떤 조인이 필요없는지 병목구간 어딘지 체크
스칼라를 쓸때는 무조건 입력값의 범위를 보고 캐싱효과가 있을지 체크
스칼라는 PGA에 캐싱됨
