정렬후 병합하므로 성능개선
NL조인은 Outer 테이블과 Inner 테이블의 조인키의 인덱스 유무가 매우 중요하다. 인덱스가 없다면 Outer 에서 필터되는 레코드마다 Inner 테이블을 풀스캔 혹은 필터링 할것이고 이떄 많은 비효율이 생긴다.
인덱스가 없다면 옵티마이저는 HashJoin과 Sort Merge Join을 고려한다.
내부 원리
sm join은 두 테이블을 각각 정렬한 다음 두 집합을 병합하면서 조인을 수행한다.
- 정렬 단계 : 양쪽 집합을 조인 컬럼 기준으로 정렬한다.
- 병합 단계 : 정렬된 양쪽 집합을 병합한다.
아래는 소트 머지 조인 방식을 그림으로 표현한 것이다.
SELECT /*+ ordered use_merge(e) */ D.DEPTNO, D.DNAME, E.EMPNO, E.ENAME
FROM DEPT D, EMP E
WHERE D.DEPTNO = E.DEPTNO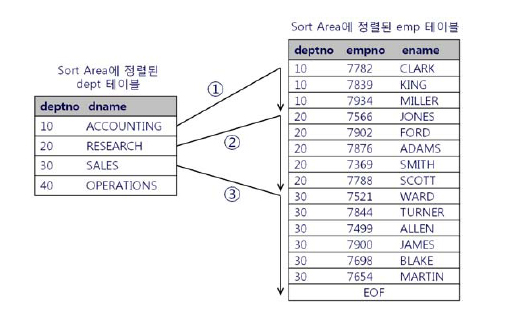
조인 키 컬럼인 DEPTNO순으로 각 테이블을 정렬한다.
dept=10인 레코드는 EMP테이블에서 조건에맞는 레코드를 검색하다가 dept=20을 만나는 순간 멈춘다.
dept=20인 레코드는 EMP테이블에서 멈춘 지점을 기억하고 거기서부터 탐색을 시작한다.
두테이블을 정렬 후 조인하므로 옵티마이저는 테이블 순서를 신뢰하고 빠르게 병합할 수 있다.
특징
- 정렬할 집합이 초 대용량이라면 정렬 자체만으로도 큰 비용을 수반하므로 성능 개선효과가 없음
- 하지만 인덱스 혹은 클러스터형 인덱스처럼 미리 정렬되어 있다면 좋은 대안
- 부분 범위 처리 가능
- NL조인은 Outer테이블의 건수에 대해 성능이 좌우 되지만, Sort Merge Join은 두 집합을 각각 정렬한 후 조인하므로 각 집합의 크기로 전체 일량이 좌우됨
- Random 액세스가 아닌 스캔 위주의 방식

🔥🔥🔥🔥 G U N F E 🔥🔥🔥🔥