뷰 Merging이란
select *
from (select * from emp where job = 'SALESMAN') a
, (select * from dept where loc = 'CHICAGO') b
where a.deptno = b.deptno;위와 같은 쿼리를 자주 볼수있다.
왜냐하면 개발자의 입장에서 보다 더 이해가 쉽다.
서브쿼리도 조인문보다는 직관적으로 눈에 읽힌다.
하지만 옵티마이저는 최적화를 수행하는 입장에서 더 불편하다.
그러므로 옵티마이저는 가급적 쿼리블록을 풀어내려는 습성을 가진다.
따라서 다음과 같은 뷰 Merging을 거치고 쿼리를 변환하여 실행을 수행한다.
select *
from emp a, dept b
where a.deptno = b.deptno
and a.job = 'SALESMAN'
and b.loc = 'CHICAGO';결과집합은 동일하지만 좀 더 많은 액세스 경로를 고려하며 최대효율을 고려한다.
이 기능을 제어하는 힌트로 merge 와 no_merge가 있다.
단순 뷰와 복합 뷰
단순 뷰 란 조건절, 조인문 정도만 적용되는 단순구조의 뷰 이다.
이는 no_merge 힌트를 사용하지 않는 한 항상 뷰merge가 일어난다.
복합 뷰란 group_by절, select-list에 distinct 연산자 가 포함된 쿼리이며 이는 _complex_view_merging 파라미터를 true로 설정할 때만 Merging이 일어난다.
9i 부터는 디폴트가 true이므로 동일한 결과를 가져온다고 판단되면 항상 merge가 일어난다. 이는 merge를 하면 항상 더 나은 실행계획을 찾을 가능성이 높다고 믿기 떄문이다.
뷰Merge가 불가능한 쿼리
뷰머지가 불가능한 조건이 있다.
- 집합 연산자(union, union all, intersect, minus)
- connect by 절
- RowNum pseudo 컬럼
- select-list에 집계함수 사용 (group by없이 전체를 집계하는 경우를 말함)
- 분석 함수
위 조건에서는 뷰머징이 절대 일어나지않는다.
예제
- 예제 코드이다. 인라인 뷰에서 emp테이블을 참조하며, deptno 별로 평균 급여를 리턴한다.
하지만 결국 dept 테이블과 조인한 뒤, d.loc = 'CHICAGO' 조건에 부합하는 레코드만 반환될 것이므로, emp테이블에서 읽히는 데이터중 버려지는 레코드가 다수 있다.

(오라클 성능 고도화 2권 493p에서 10g 이상에서는 비용을 따진뒤
뷰Merge가 더 비용이 적다고 판단될때 자동으로 뷰Merge가 일어난다고 했다.
하지만 실습 환경에서 분명 비효율이 존재하지만 no_merge 힌트가 없어도
자동 뷰merge가 일어나지 않았다.
이부분은 좀 더 찾아봐야겠다.)
어찌 되었건 위 코드의 실행 결과이다.
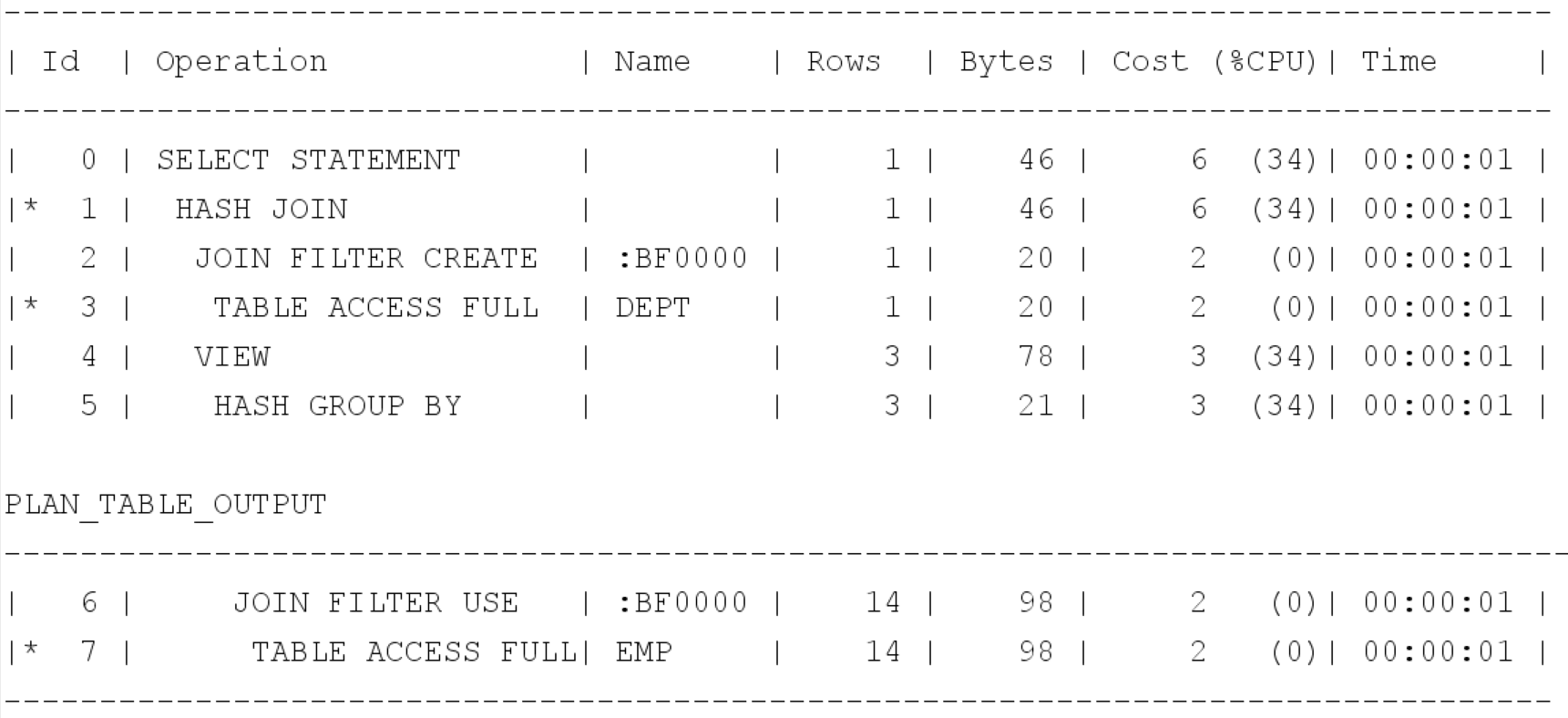
먼저 인라인 뷰를 실행한다. (ID 4,5,6,7)
여기서 4번에 해당하는 VIEW 실행 계획이 EMP테이블 액세스 후 View오퍼레이션에 해당한다.
DEPT 테이블을 액세스후 Hash Join으로 조인하여 결과집합을 도출하고 있다.
분명 emp테이블은 버려질 테이블도 같이 읽었기 때문에 반드시 비효율이 존재한다.
- Merge 상황

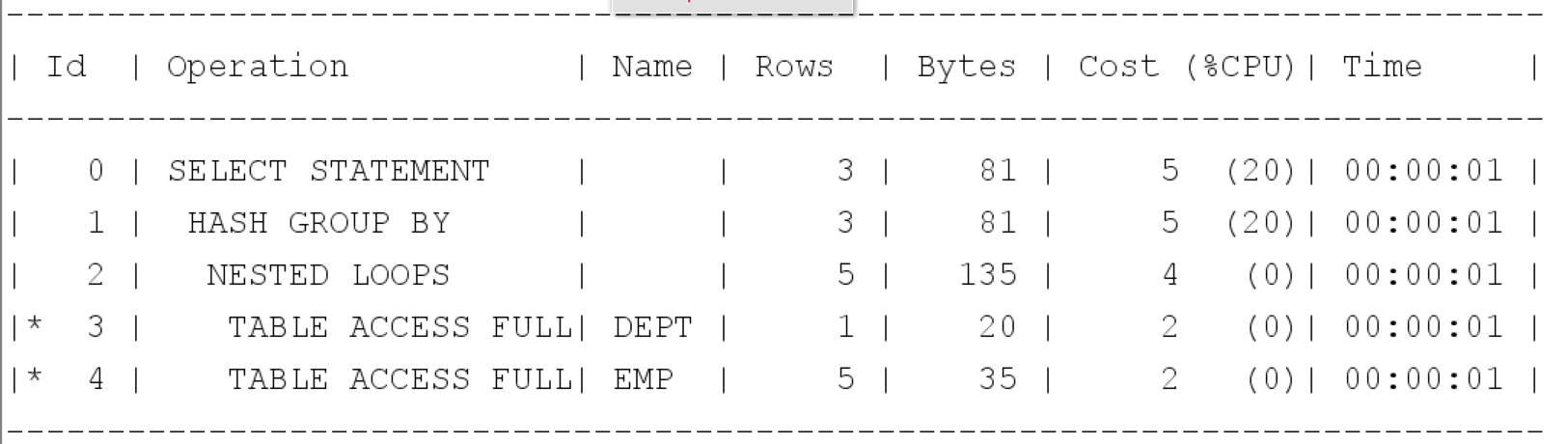
위처럼 뷰 Merge가 일어날때, 이점은 d.loc = 'CHICAGO' 인 레코드만 DEPT 테이블에서 검색후 조인하여 GROUP By함.
언제?
9i에서는 결과집합만 동일하면 무조건 뷰Merge가 일어나도록 했지만, 10g에 와서는 비용을 따져보고 뷰Merge가 일어나게 바뀌었다.
왜냐하면 뷰Merge는 성능을 잘 비교해보고 써야하기 때문이다.
위처럼 d.loc='CHICAGO' 에서 선택된 deptno가 emp테이블에 많다면? 조인 후 액세스가 아닌, Table Full Scand으로 액세스 후 조인이 더 효율적이다.
그러므로 사용자는 비용을 잘 검토하여 merge 또는 no_merge힌트를 잘 사용해야 한다.
안된다면?
뷰머징이 비용이 더 든다고 판단되거나, 결과집합이 부정확 할땐 뷰 머징을 포기한다. 이때는 무조건 2차적으로 조건절Pushing을 시도한다.
이마저도 실패할땐 뷰 쿼리블록을 개별적으로 최적화하고, 거기서 생성된 서브플랜을 전체 실행계획을 생성하는데 사용헌다.
