
🎯개요
- Conversation AI를 위한 Open source framework인 Rasa(https://rasa.com/)의 research paper를 정리한다
- 논문 - https://arxiv.org/abs/2004.09936
❔ Introduction
Two common approaches for data-driven dialouge modeling
-
일반적으로 데이터 주도 대화 모델링(data-driven dialogue modeling)은 크게 다음과 같은 두 가지 방식으로 접근한다
- Modular system
Natural Language Understanding(NLU) 시스템과 Natural Language Generation(NLG) 시스템으로 분리하여 전체 시스템 구성
Dialogue policy가 NLU 시스템에서 나온 분석 결과로 시스템의 다음 행동(action)을 선택한다.
그 다음에 NLG 시스템이 이에 대응하는 응답을 생성한다.
- End-to-End
사용자의 입력을dialogue policy에 직접 넣어 시스템의 다음 예상 발화를 출력한다.
- Modular system
NLU: Intent classification and Entity recognition
대화 시스템의 NLU는 일반적으로 intent classification과 entity recognition의 두 가지 sub-task를 말한다.
단순히 시스템에서 두 개의 task를 별개로 모델링하면 error propagation의 악영향을 받는다.
이와 같은 문제를 해결하기 위해 다중 태스크를 처리하는 단일 아키텍처(single multi-task architecture)를 구성하여, 두 개의 태스크 간의 상호작용의 이점을 얻어야 한다.
최근의 연구들에서 대규모 pre-trained 모델이 높은 성능을 보였지만, 이와 같은 모델을 위한 pre-training 및 fine-tuning의 학습 비용은 상당히 높다.
DIET (Dual Intent and Entity Transformer)
본 연구는 intent classification과 entity recognition를 위한 새로운 다중-태스크 아키텍처(multi-task architecture)를 제안한다.
이 아키텍처의 주요 특징은 아래와 같다.
- Sparse feature + Dense feature
언어 모델의 pre-trained 단어 임베딩(dense)과 character level n-gram 특징과 조합할 수 있다.
DIET sparse features만 사용하여도 복잡한 NLU 데이터셋에 대하여 SOTA(state of the art) 성능을 보여주었고, pre-trained 특징을 추가하면 성능이 더욱 개선되었다.
🔨 DIET architecture
DIET 아키텍처를 구성하는 핵심 요소는 아래와 같다.
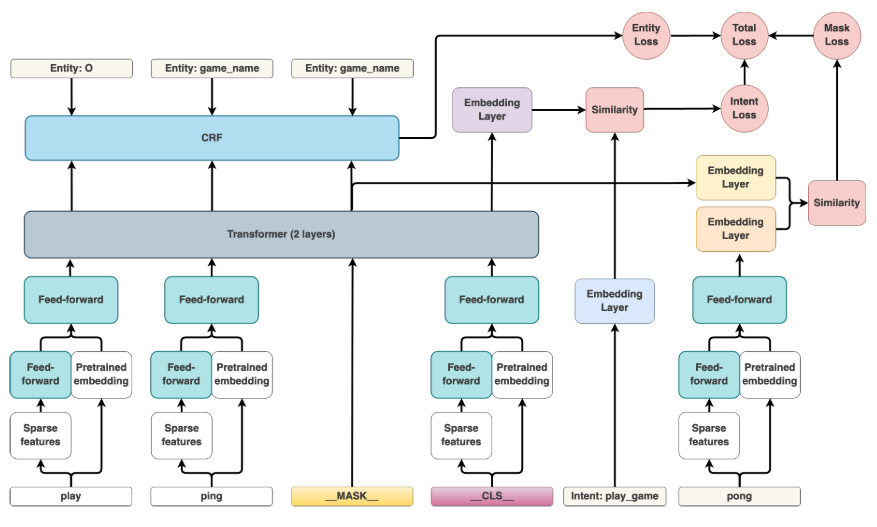
Featurization
- 입력 문장은 파이프라인에 따라 word 또는 sub-word 토큰 sequence로 다룬다.
- 각 문장 끝에는
CLS토큰을 추가한다. - 각 토큰은 sparse feature로 특징화(featureize)되며, 선택적으로 dense feature로도 특징화 된다.
- Fully connected layer를 통과한 sparse feature와 dense feature가 concatenate 되어
Transformer로 입력된다.
- Sparse feature
- 토큰 레벨의
one-hot encoding또는multi-hot encodings of character n-grams - Character n-grams은 불필요한 정보를 많이 포함하고 있어서, 오버피팅(overfitting)을 피하기 위해 드롭아웃(dropout)을 적용한다.
- 토큰 레벨의
- Dense feature
ConveRT,BERT,GloVe와 같은 pre-trained 단어 임베딩을 사용CLS토큰의 경우,ConveRT의 문장 임베딩,BERT의CLS토큰,GloVe의 토큰 임베딩 평균값으로 초기 설정한다.
Transformer
- 2-layer transformer로 문장을 인코딩한다
- Transformer layer와 입력의 차원은 동일하게 맞추어야 하므로, concatenate한 입력 feature를 또 다른 fully connected layer를 통과시킨다.
Named entity recognition
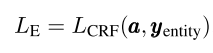
- 개체 레이블 시퀀스는 transformer 위에 CRF layer를 통과하여 예측된다.
Intent classification
- Transformer를 통과한
__CLS__토큰의 출력 aCLS와 인텐트 레이블 yintent은 단일 벡터 공간에 임베딩된다.
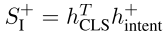
- Dot-product loss로 타겟(정답) 레이블 y+intent과의 유사도 값을 최대화
- Negative sample인 y-intent과의 유사도 값은 최소화시킨다.
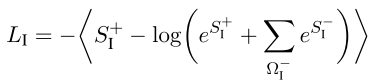
- Intent loss(LI)는 위에서 구한 positive/negative 각각의 유사도 값을 사용하여 계산한다.
Masking
- BERT에서와 마찬가지로 입력 토큰을 무작위로 마스킹하는 학습 설정.
- 입력 시퀀스의 15%를 마스킹
- 마스킹하는 토큰은 70%의 확률로
__MASK__토큰으로, 10%의 확률로 랜덤 토큰으로, 20%의 확률로 원래 토큰을 유지한다.
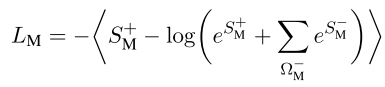
- Intent loss를 구하는 방식과 동일하게 Mask loss(LM)를 구한다.
Total loss
- Multi-task 학습 방식의 모델로 각각의 task의 loss를 총합한 loss를 최소화하는 방향으로 학습된다.
- 이 아키텍처에서는 특정 loss를 turn-off 하여 구성할 수 있다.
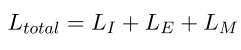
🧪Experiments
Experiments on NLU-benchmark dataset

- NLU-benchmark dataset은 10개의 fold로 구성
- 각 fold별로 모델을 학습하여 성능의 평균 계산
- 실험한
DIET모델은 token level에서 one-hot encoding과 character n-grams의 multi-hot encodings을 사용 /ConveRT의 dense embedding을 사용 - Entity task의 precision을 제외한 모든 지표에서 높은 성능을 보임
Importance of different featurization components and masking
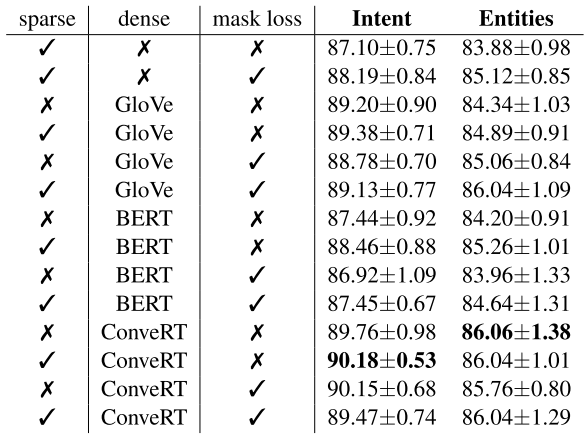
- Feature의 다양한 조합으로 인한 성능을 비교
Comparison with fine-tuned BERT (NLU-benchmark dataset)
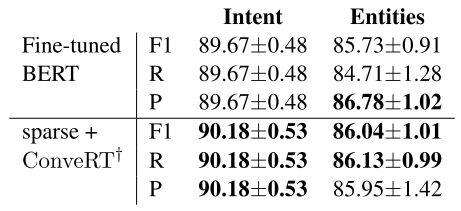
DIET모델은ConveRT의 임베딩을 dense feature로, 단어-캐릭터 레벨의 sparse feature를 사용BERT는DIET모델 안에서 fine tuning하는 방식- 두 모델의 성능은 대등하게 나오지만, 학습 속도가
DIET이 6배정도 빠름
🔎Conclusion
- 여러가지 종류의 다른 데이터셋에서 모든 최고의 성능을 보여주는 임베딩 구성은 없는 것을 확인.
- 따라서, 이는 모듈화된 아키텍처(modular architecture) 방식의 중요성을 강조함.
GloVe와 같은 단어 임베딩도 대규모 언어 모델의 임베딩과 비교하여 대등한 성능을 보여주는 것을 확인.- Pre-trained 임베딩을 굳이 사용하지 않더라도, 다른 모델과 대등한 성능이 나온다는 것을 확인
- 가장 높은 성능을 보여주는 pre-trained 임베딩 구성으로, DIET 모델이 fine-tuning BERT 보다 학습속도가 여섯배 빠르면서도 성능을 능가하는 것을 확인할 수 있음

본질에 집중하려고 노력합니다. 🔨