개요
- NLP 모델이 입력받는 텍스트 데이터의 에러(오탈자, 잘못된 띄어쓰기 등) 대응하는 모델 survey
- 인코더-디코더 모델까지 주요 페이퍼 정리
📃Papers
🍠 Integrated Eojeol Embedding for Erroneous Sentence Classification in Korean Chatbots
- 논문: https://arxiv.org/abs/2004.05744
- 리뷰: https://jeonsworld.github.io/NLP/iee/
- 한국어 논문은 HCLT 2019 (한국어 언어정보처리 학회) 논문집에 수록
❔ Problem Statement
- 기존 카카오 미니에서 입력 문장의 의도 분류 모델 성능 개선 연구의 연장선
- 기존의 형태소(morpheme) 기반 임베딩은 erroneous inputs에 좋지 않은 성능을 보임
- 모델이 문장을 분류하기 위한 결정적 단서 (vital cue)에 대한 정보가 erroneous input에서는 유실
- 잘못된 문장 분류(intent classification)의 확률이 높아짐
🔨 Approach
-
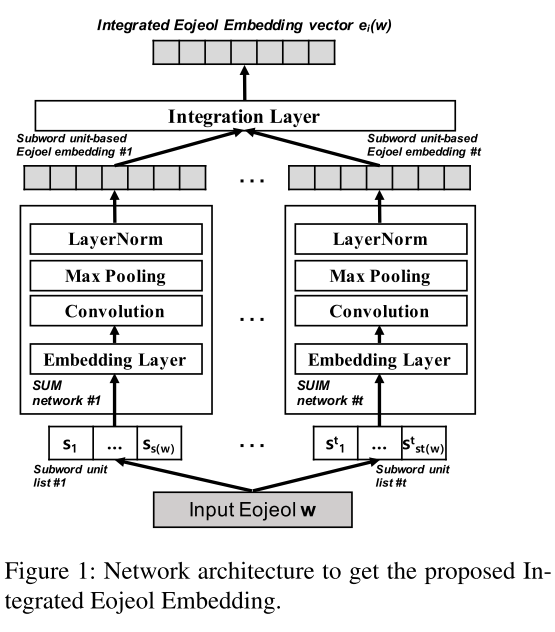
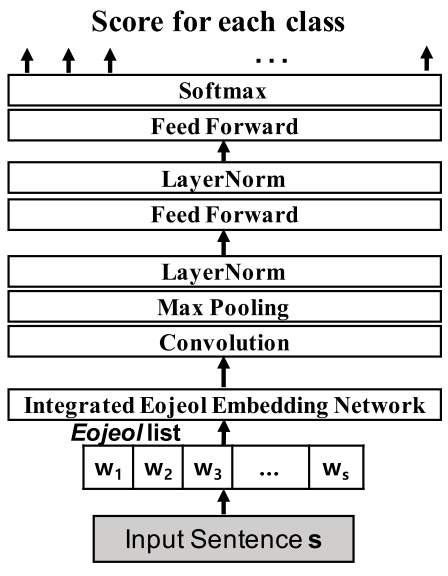
어절 단위마다 자모 / 음절 / subword(BPE) / 형태소 정보를 각각 임베딩 한 후, 통합된 임베딩 벡터를 생성하여 분류 모델에 사용
- 통합된 임베딩 벡터(Integrated Eojeol Embedding; IEE)
- 저자의 기존 연구에서는 수집된 코퍼스로 GloVe 워드 임베딩하여 분류 모델에 입력으로 사용 (KoGloVe)
- 기존 분류 모델에 IEE 벡터를 입력 워드 임베딩으로 사용
- Integrated Eojeol Embedding 네트워크 구조
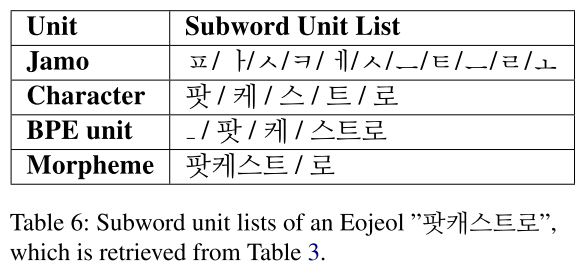
- 어절 단위 기준의 통합 어절 임베딩 생성에 사용하는 subword 리스트
| 기존 연구 분류 모델 | IEE 벡터를 입력으로 하는 기존 모델의 variant |
|---|---|
 |  |
코퍼스
- 기존 연구에서 사용한 127,322개 문장 규모의 intent classification corpus 사용 (48개의 intents)
- weather / fortune / music / podcast 등
- weather / fortune / music / podcast 등
-
기존 코퍼스는 WF(Well-Formed) corpus로 명칭
- 에러 문장이 없는 코퍼스
- 에러 문장이 없는 코퍼스
-
KM corpus(Korean Misspelling)를 별도로 구성
- Common / OOD(intent for meaningless)의 두 가지 intent는 제외
- 작업자는 가이드라인에 따라, 에러 문장 생성

-
SM corpus (Space missing)는 WF / KM corpus에서 재구성
- 기존 코퍼스의 테스트 셋에서 문장의 단어 간 0.5 확률로 띄어쓰기를 제거
- 문장에 최소 하나의 띄어쓰기 제거
🍠 Reliable Classification of FAQs with Spelling Errors Using an Encoder-Decoder Neural Network in Korean
❔ Problem Statement
- FAQ와 사용자 query간의 lexical disagreement 문제
- 온라인 뱅킹의 챗봇과 같은 FAQ 서비스
- 동일한 의미의 다른 단어로 인한 lexical disagreement
- Spelling errors로 인한 잘못된 단어로 인한 lexical disagreement

🔨 Approach
- Encoder-Decoder neural network 기반 문장 분류 모델 제안
- 입력으로 multiple word embedding을 사용
- Fixed word embedding (domain-independent meanings of words)
- Fine-tuned word embedding ( domain-specific meanings of words)
- Character-level word embedding (bridging lexical gaps caused by spelling errors)
- FAQ의 각 카테고리 domain knowledge를 표현하기 위한 class embedding
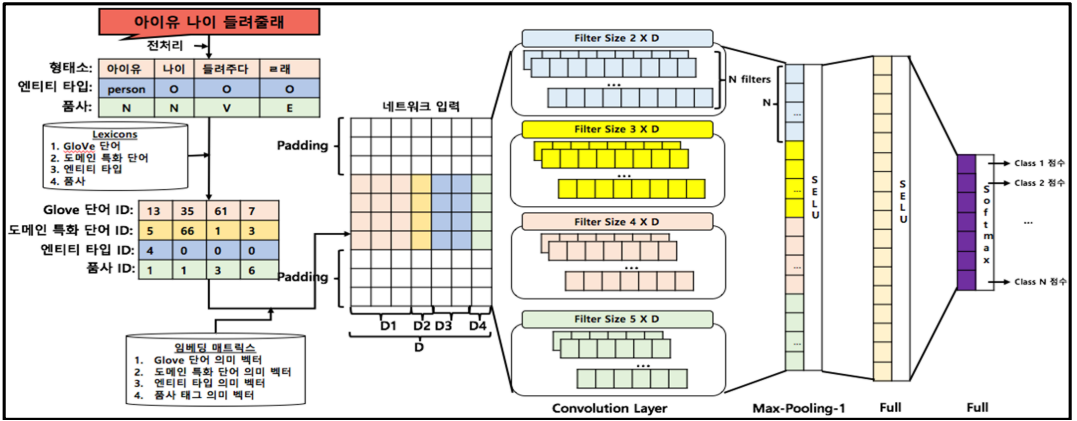
- 제안하는 분류 모델 구조
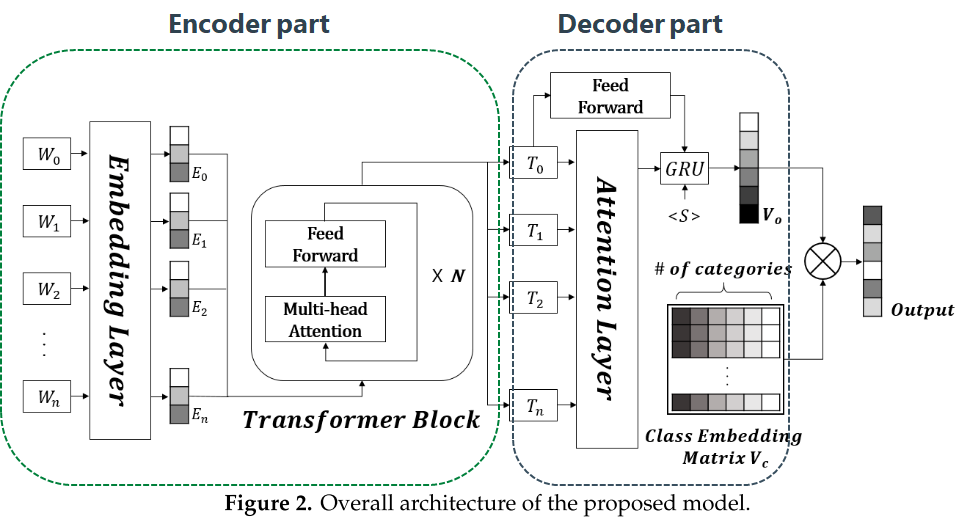
Embedding Layer
- 세 가지 타입의 임베딩을 concatenation
- lexical disagreement에 강건해지는 것을 기대
- [CLS] 토큰을 문장 앞에 스페셜 토큰으로 사용 (BERT의 input example과 동일)
- Character-level word embedding은 자모를 사용
- CNN으로 임베딩 생성
- CNN으로 임베딩 생성
- Embedding layer 구조
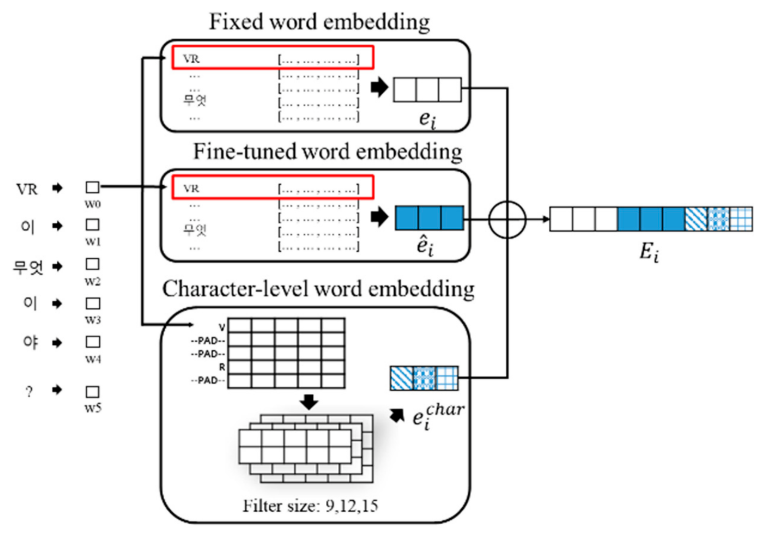
Encoder part
- 앞선 embedding layer를 통과한 단어 임베딩(concatenated by three embedding vector)을 transformer 블록으로 인코딩
- 문장 내의 contextual information을 보강하기 위함 (Self-attention)
Decoder part
-
Luong's encoder-decoder attention mechanism 사용
- NMT (Neural Machine Translation) 연구에서 attention 기반 모델
- 논문: https://arxiv.org/pdf/1508.04025.pdf
- 논문 요약: Effective Approaches to Attention-based Neural Machine Translation
- https://elapser.github.io/nlp/2018/02/09/NLP-review.html
- NMT (Neural Machine Translation) 연구에서 attention 기반 모델
-
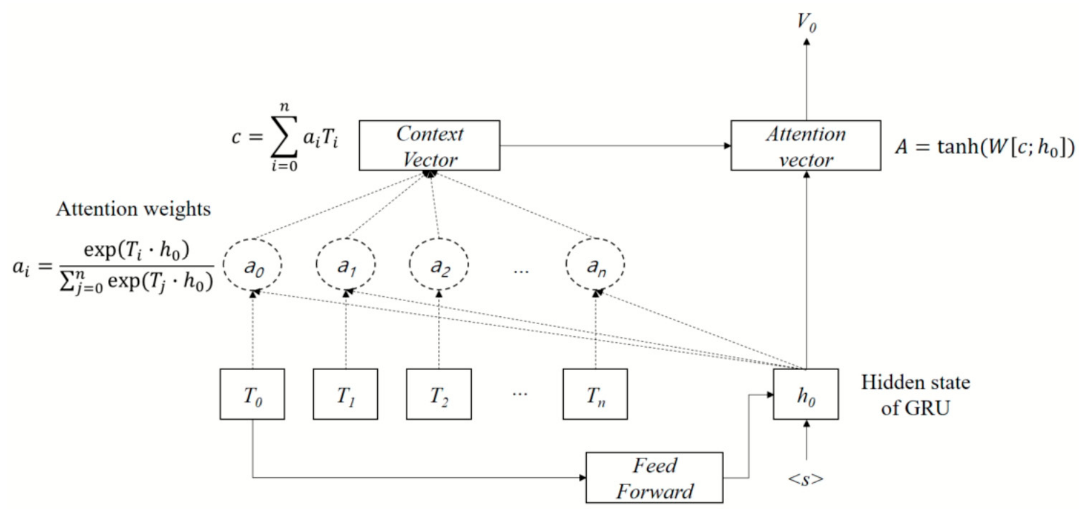
앞선 Transformer block을 통과한 토큰 임베딩(T) 중 CLS 토큰(T0)
- BERT의 CLS 토큰처럼 Self-attention 과정을 거치며, 문장을 나타내는 정보가 임베딩된다고 볼 수 있음
- BERT의 CLS 토큰과 동일한 목적으로 도입한 것으로 예상
-
Attention weights는 T 임베딩이 h0와 어느 정도 연관성이 있는지, inner product로 계산됨
- T와 a의 weighted sum으로 context vector 계산
-
GRU로 구현된 Decoder는 FNN(T0) / S / Context vector로 Attention vector를 생성
RNN decoder 구조 (with Luong's encoder-decoder attention mechanism)
- Decoder의 출력인 V(attention vector)와 class embedding vector를 inner product한 벡터를 넣어 FNN로 분류
- class embedding vector는 카테고리 개수만큼, 각 카테고리의 문장들의 단어 임베딩의 평균값을 사용하여 계산
🍠 Stacked DeBERT: All Attention in Incomplete Data for Text Classification
❔ Problem Statement
-
현재의 챗봇 시스템은 missing 또는 incorrect words를 가진 문장(incomplete data)에 대해 올바른 문장에 비해 좋은 성능을 보이지 못 함
- 사용자가 항상 문법적으로 정확한 문장을 입력할 것이라는 가정은 naive
-
더욱이, 챗봇 시스템에서 Automatic Speech Recognition(ASR) application을 사용하는 것은 높은 에러율로 인하여 적용이 어려움
- ASR을 적용한 챗봇 서비스의 성능 품질을 높이기 위해서는, 사용자의 incomplete data에 대해서 강건한(robust) 시스템 개발이 필요
- ASR을 적용한 챗봇 서비스의 성능 품질을 높이기 위해서는, 사용자의 incomplete data에 대해서 강건한(robust) 시스템 개발이 필요
-
기존 Text Classification tasks는 효율적인 embedding representations에 초점
- Complete data로 구성된 데이터 셋을 기준으로 방법이 적용됨
- Incomplete data 문제는 대개 reconstruction 또는 imputation task로 접근됨
- 보통 missing number imputation
- 보통 missing number imputation
🔨 Approach
- Stacked Denoising BERT (DeBERT): BERT power와 denoising strategies를 이용한 data reconstruction 방법
-
Input representations의 정보를 더 rich하게 표현하기 위해서 denoising transformers를 stacking한 layer 구성
-
Embedding layer and Vanila transformer
- Vanilla transformer는 input token으로부터 intermediate input features를 추출
- BERT transformer block으로 denosing transformer로 전달되기 전, encoding하여 중간 단계 feature 추출
-
Denoising transformers
- Intermediate input features로부터 오타와 같은 noise에 강건한 richer input representations을 얻어냄
- Intermediate input features로부터 오타와 같은 noise에 강건한 richer input representations을 얻어냄
-
Proposed model
세 개의 레이어(embedding, conventional BERT, Denoising BERT)로 구성된 제안 모델 구조
-
Embeding layer
- 기존 BERT pretrained 모델과 동일
- Special token(cls, sep) 붙이기
- Token / Segmentation / Position 임베딩 값 sum
- 기존 BERT pretrained 모델과 동일
-
Transformer block layer
- BERT의 transformer block
- Pretrained 모델을 load하여 incomplete 텍스트 분류 코퍼스로 fine-tuning
- intermediate input features를 얻어 denoising transformer layer로 입력
- 기존 BERT는 다른 baseline 모델들보다 incomplete data에 대해 더 좋은 성능을 보여줬음
- 하지만 incomplete data를 충분히 핸들링 필요
- Missing words가 있는 문장으로부터 얻는 hidden feature vectors의 개선이 필요
-
Denoising transformer layer
-
MLP stack으로 구성된 AutoEncoder
-
Transformer block으로 인코딩한 incomplete data의 representation vector를 입력으로 사용
-
AutoEncoder는 해당 벡터 값으로부터 missing words embeddings을 재구성(reconstruction) 하기 위한 목적으로 사용
- 단순히 transformer로 인코딩한 벡터보다 더 abstract / meaningful를 도출하기 위함
- Incomplete data에 대응하는 complete data의 representation을 target으로 하여 AutoEncoder로 denoising
-
AutoEncoder 코드
- MLP stack은 세 개의 레이어를 가진 두 개의 스택으로 구성
- 첫 번째 set에서 intermediate hidden vector를 latent-space representation으로 압축
- BERT base 모델의 hidden size인 768부터 12까지 압축
- 두 번째 set에서 다시 복원
-

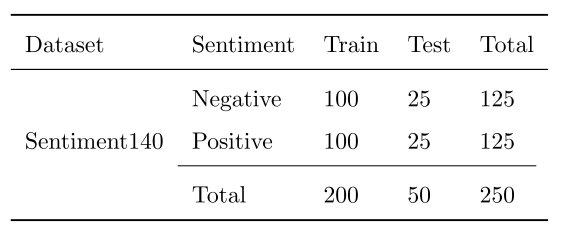
Dataset
Twitter Sentiment Classification
- 실제 사람이 만드는 에러가 있는 문장의 데이터셋
- Kaggle의 two-class Sentiment140 데이터셋 사용
- 비문 또는 문법 오류와 무관한 spoken text로 구성
- 문장에 대한 긍정/부정 label
- 제안한 모델을 학습하려면 대응하는 corrected sentence가 필요
- Amazon Mechanical Turk(MTurk)에서 crowd sourcing하여 생성
- 데이터셋 구성
- 테스트 셋은 incorrect data
- 50문장은 evaluation
Intent Classification from Text with STT Error
-
의도 분류 데이터셋은 corrected sentence로 구성
- incomplete data 필요
-
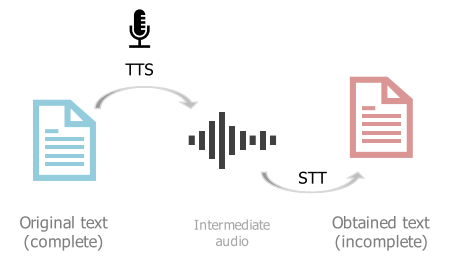
올바른 문장에 대응하는 잘못된 문장을 만들기 위해서 TTS와 STT 사용
- TTS와 STT를 거치면서 noise 발생한 문장으로 문장 쌍 구성
- STT error를 가진 문장 생성 스텝