Generative Model
Generative model은 probability distribution을 학습한 model이다. 어떤 training dataset이 있다고 할 때, 해당 dataset을 생성하는 true unknown probability distribution을 잘 근사하는 model을 학습하는 것이 generative model의 목적이다.
Autoregressive Models
Autoregressive model은 data의 random variables들이 순서가 있다고 가정한다. image를 예를 들면 image pixel들을 왼쪽 상단부터 오른쪽 하단 까지 나열하여 순서를 정할 수 있다.(i.e. raster scan)
28 x 28 pixels(784)을 가진 1 channel image를 autoregressive model 방식으로 표현 하면 다음과 같이 쓸 수 있다.
즉, 다음 pixel은 모든 이전 pixels의 conditional probability로 연결된다. 또한 위 과정을 각 pixel에 대한 classification의 연속으로도 볼 수 있다.
다음 pixel을 예측하기 위해 parameterized function을 이용하면, 모델의 복잡도를 줄일 수 있다. 이는 autoregressive model의 대표적인 형태이며, paramterized fucntion은 다양한 형태로 존재한다.(e.g. FVSBN, NADE, RANDE)
Autoregressive Models vs Autoencoders
Autoregressive models과 autoencoders는 서로 비슷한 이름, 비슷한 구조를 보인다.(개인 적으로 딱히 그렇게 보이지는 않음.)
Autoencoders는 encoder와 decoder 구성된 model로 input data를 encoder에 통과시켜 latent space로 mapping 시키고, latent space로 mapping된 데이터를 decoder를 통해 원래 데이터로 복원 시킨다. data에 대한 distribution을 학습하는 것이 아니고 input을 latent space로 mapping 하는 것과, latent variable을 다시 복원하는 것이 목표이기 때문에 generative model이라고 할 수 없다.
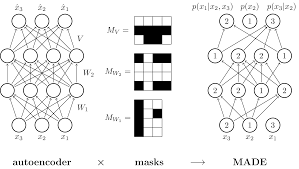
MADE
Autoencoder에 mask를 적용하면 autoregressive model 처럼 쓸 수 있다. autoregressive model 처럼 random variables에 ordering을 가정하고 영향을 미치는 random variables만 연산에 이용되도록 masking 처리를 한다.
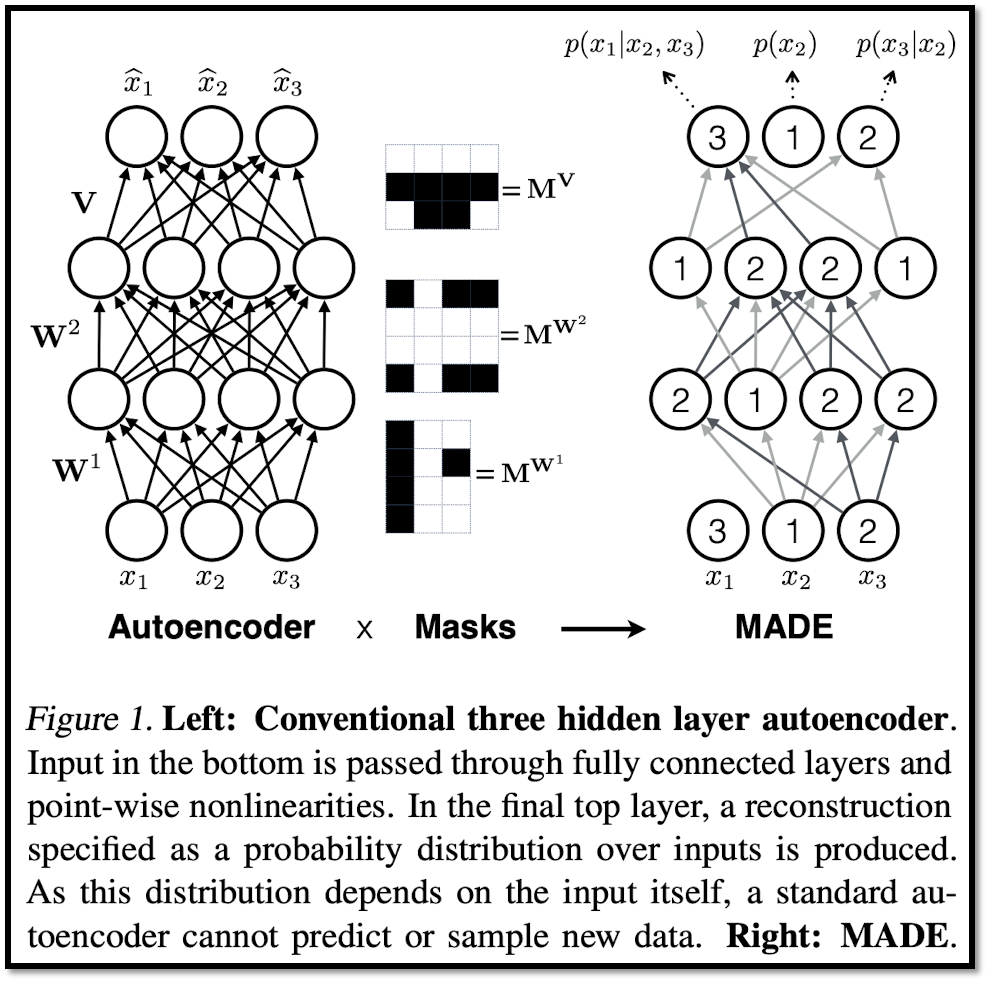
Autoencoder 형태의 generative model은 input을 한 번에 넣을 수 있다는 장점을 갖는다. autoregressive model은 다음 pixel의 예측을 위해 이전 모든 pixel들이 필요하다. input을 ordering에 따라 순서대로 넣어야 한다.
RNN
앞서 본 autoregressive model은 history(sequence length )가 길어질 수록 수식이 길어지는 단점을 갖는다. RNN은 그러한 단점을 보완하여, history에 대한 summary를 갖고 이를 가 커지면서 계속 update 한다.
- summary update rule :
- prediction :
- summary initalization :
Attention Based Models
RNN의 가장 큰 단점은, sequence length 를 하나의 single vector 로 summary 해야한다는 점이다. 또한 잘 알려진대로 gradient vanishing, exploding 등의 문제를 겪는다.
이 외에 RNN은 그 recurrent 한 특성 때문에 parallel 한 연산이 불가능해 GPU와 같은 가속기를 이용할 때 효율을 내기 어렵다.
Attention은 주어진 sequence에 대해 어떤 요소가 더 중요한지 score를 측정하여 연산에 이용한다. 따라서 모든 sequence를 하나로 summary 해야하는 부담이 RNN에 비해 적다.
현재 LLM 모델의 대부분 architecture인 Transformer 구조도 이러한 attention을 이용하며, transformer는 paralle한 연산이 가능해 GPU와 같은 가속기에서 최대한의 효율을 낼 수 있다.
Reference
