논문 출처 : https://doi.org/10.48550/arXiv.2405.12130
0. Abstract
- LoRA는 LLM이 새로운 지식을 효과적으로 학습하고 기억하는 능력이 제한됨
- MoRA라는 새로운 방법을 제안
- MoRA는 정사각 행렬을 사용해서 동일한 수의 학습 가능한 파라미터를 유지하여 고차원 업데이트를 달성
- 정사각 행렬 사용을 위해 입력 차원을 줄이고 출력 차원을 늘리기 위한 비파라미터 연산자를 도입
- 이를 통해 MoRA가 LoRA와 유사하게 배포될 수 있고 메모리 집약적인 작업에서 LoRA보다 우수한 성능을 보임. 또한 다른 작업에서도 유사한 성능을 달성함
1. Introduction
- 언어 모델의 크기가 커짐에 따라 특정 다운스트림 작업에 모델을 적응시키기 위한 파라미터 효율적 미세조정(PEFT) 기술이 떠오르고 있음
- 이를 통해 옵티마이저의 메모리 요구 사항이 크게 줄어들고 미세 조정된 모델의 저장 및 배포가 용이해짐
- 특히 저차원 적응(LoRA)은 프롬프트 튜닝이나 프리픽스튜, P-튜닝(어댑터를 사용하는 튜닝)과 같은 다른 PEFT 방법보다 더 나은 성능을 제공함
- LoRA는 미세 조정을 통해 지식과 능력을 강화해야 하는 다른 작업에서는 어려움을 겪음 ⇒ 이러한 한계는 저차원 업데이트에 의존하기 때문일 수 있음
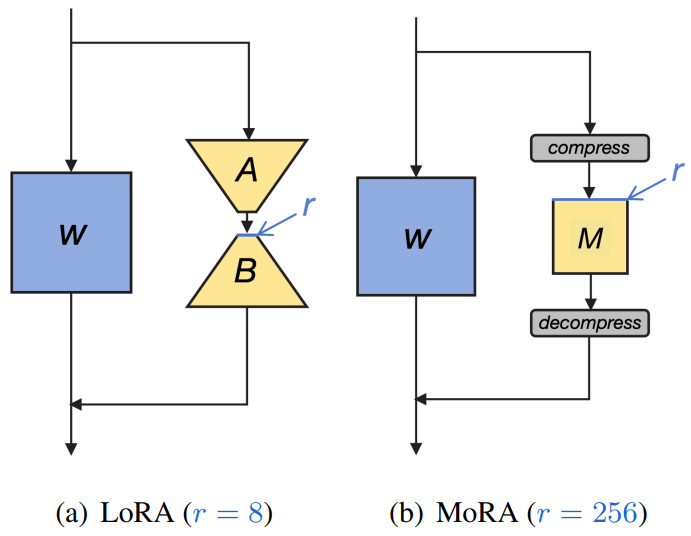
- 이에 따라 본 논문에서는 저차원 행렬 대신 정사각 행렬을 사용하여 LoRA와 동일한 학습 가능한 파라미터 수를 유지하면서 rank를 최대화 하는 방법인 MoRA를 제시함
(예를들어 LoRA에서 rank가 8인 4096x8=A, 8x4096=B 행렬을 사용할때 MoRA는 동일한 파라미터를 가지도록 256x256 의 정사각행렬을 사용함)
본 논문에서 핵심은
- MoRA는 LoRA에서 저차원 행렬 대신 정사각 행렬을 사용하여 고차원 업데이트를 수행하면서 동일한 학습 가능한 파라미터 수를 유지하는 새로운 방법
- MoRA의 입력 차원을 줄이고 출력 차원을 늘리기 위해 비파라미터 연산자들을 사용하여 가중치가 LLM에 병합될 수 있도록 함
- 메모리 집약적인 작업에서 LoRA보다 우수한 성능을 보였고 다른 작업에서도 비슷한 성능을 달성하여 고차원 업데이트의 효과를 입증함
2. Related Work
2.1 LoRA
- LoRA는 레이어의 가중치를 저차원 행렬 두 개로 분해하여 사용하게 됨
- 이렇게 파인튜닝 후 가중치를 병합함으로써 전체 파인튜닝과의 추론시간 차이가 나지 않음
- LoRA를 더욱 개선하고자 하는 많은 방법이 있음
- DoRA는 원래의 가중치를 크기와 방향 요소로 추가 분해하고 LoRA를 사용해 방향 요소를 업데이트 함
- LoRA+는 두 저차원 행렬에 서로 다른 학습률을 적용하여 학습 효율성을 높임
- ReLoRA는 학습 중 LoRA를 LLM에 통합하여 최종 행렬의 rank를 높이는 방식을 제안함
2.2 Fine-Tuning with LLMs
- LLM이 맥락 학습을 통해 뛰어난 성능을 보이지만, 여전히 미세 조정이 필요한 경우가 있음. 이는 크게 3가지 유형으로 나눌 수 있음
-
Instruction Tuning
LLM의 지식이나 능력을 크게 향상시키지 않으면서 LLM을 최종 작업 및 사용자 선호에 더 잘 맞추기 위해 사용함. 이 접근 방식은 다양한 작업을 다루고 복잡한 명령어를 이해하는 과정을 단순화함
-
복잡한 추론 작업
일반적인 명령어 튜닝만으로는 수학 문제 해결과 같은 복잡하고 상징적인 다단계 추론 작업을 처리하기에 부족함. LLM의 추론 능력을 개선하기 위해 대다수의 연구는 GPT-4 와 같은 더 큰 모델을 활용하여 해당 학습 데이터를 만드는데에 초점을 둔다
-
연속적 사전 학습
LLM의 특정 도메인 관련 능력을 향상하는 데 목적이 있음. 이는 Instruction Tuning과 달리 도메인별 지식과 능력을 확장하기 위한 미세 조정이 필수적임
-
- 그러나 대부분의 LoRA 변형은 LLM의 효율성을 검증하기 위해 주로 Instruction Tuning 이나 GLUE의 텍스트 분류 작업을 활용함.
- Instuction Tuning은 다른 유형에 비해 미세 조정에 대한 요구가 가장 적어서 LoRA 변형의 실제 효율성을 정확히 반영하지 못할 수 있음. 그리고 때로는 사용된 학습 데이터셋이 LLM이 효과적으로 추론을 학습하기엔 너무 작음 ⇒ 추론 성능이 저하되고 효과성을 평가하기 어려움
3. Analysis the Influence of Low-rank Updating
- LoRA의 핵심 아이디어는 저차원 업데이트를 사용하여 FFT에 근접하는것
- 사전 학습된 파라미터 행렬 d x k 를 d x r, r x k 의 저차원 행렬 두 개로 분할하여 가중치 업데이트를 계산함
- 이러한 저차원 업데이트는 텍스트 분류나 명령어 튜닝(Instruction Tuning)과 같은 일부 작업에서 FFT과 유사한 성능을 보이지만 복잡한 추론 작업이나 연속적인 사전 학습 작업에서는 성능이 떨어짐
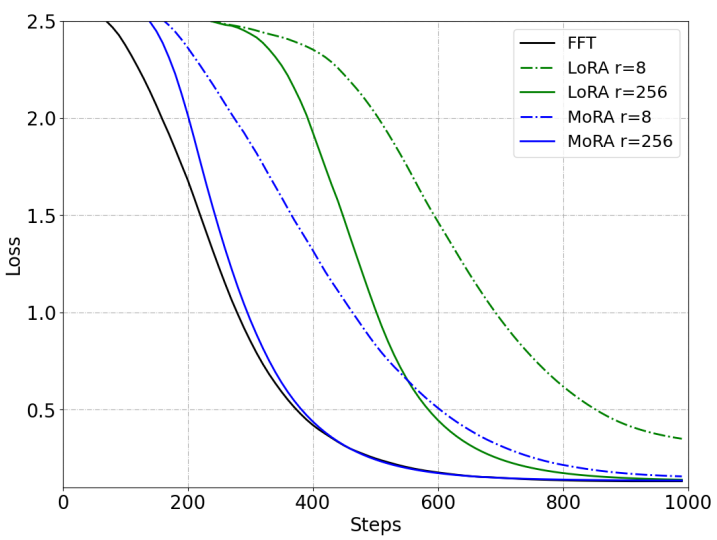
- 이를 입증하기 위해 무작위의 UUID 암기 작업에서 rank를 {8, 16, 32, 64, 128, 256} 로 다양하게 설정하여 학습 실험을 진행함
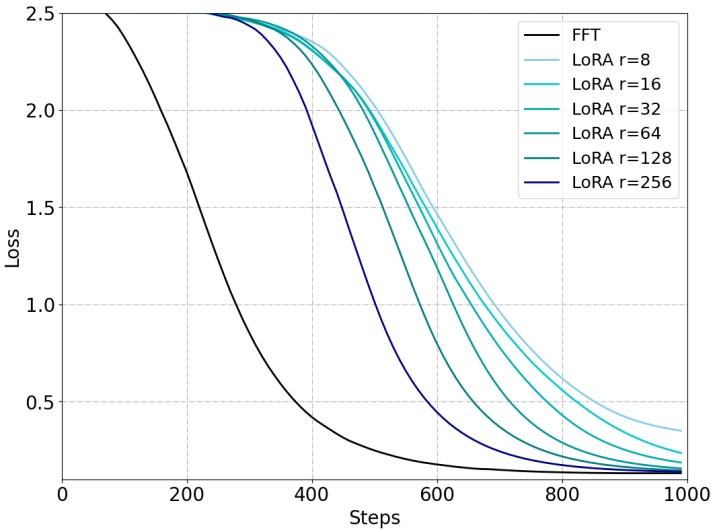
- 위의 그림에서 볼 수 있듯, FFT에 비해 새로운 지식을 기억하는데에 어려움을 보임
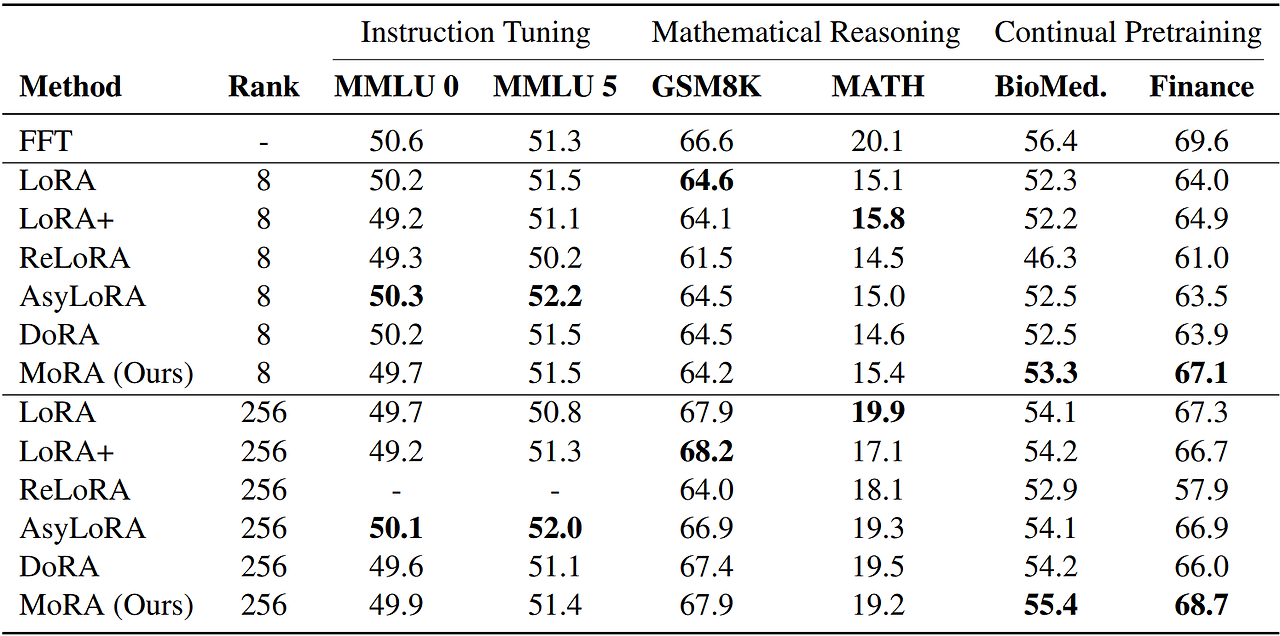
- 그리고 새로운 지식을 도입하지 않는 명령어 튜닝(Instruction Tuning)에서 LoRA와 FFT 간의 성능차이를 평가함. 아래의 표에서 볼 수 있듯 LoRA가 작은 랭크 8에서 FFT와 유사한 성능을 달성함. 이는 LoRA가 FFT와 마찬가지로 LLM의 기존 지식을 쉽게 활용할 수 있음을 보임
4. Method
위의 분석을 토대로 저차원 업데이트의 단점을 완화하기 위해 새로운 방법을 제안함
주요 아이디어는 가능한 한 동일한 훈련 가능한 파라미터를 활용해 더 높은 rank의 r을 사용하는것
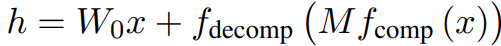
- 정사각 행렬을 사용하기 위해서 입력 차원을 줄여야 하고 출력 차원을 다시 늘리는 comp, decomp 작업이 필요함. 이는 비파라미터 연산으로 이루어짐
- 예시)
- LoRA에서 r=8, hidden size = d = k = 4096 이라고 할때(d와 k는 웬만하면 같음) 총 파라미터는 dxr + rxk = 4096x8 + 8x4096 = 65536 인데 이 파라미터 개수를 동일하게 가져가면서 정사각 행렬을 만들기 위해선 r^ = sqrt(65536) = 256 이 됨
- comp 과정은 x의 길이가 4096 일때 이를 1:256, 256:512, … , 3840:4096 이렇게 행렬을 분할하자는 아이디어로 보임
그럼 만약 해당 레이어로의 입력 크기가 (32, 128, 4096) = (batch size, sequence length, hidden size) 라고 할때 comp 과정을 거치게 되면 (32, 128, 16, 256) = (batch size, sequence length, 4096/256, r^) 이 됨 - 이를 정사각 행렬을 통해 계산을 해준 뒤 다시 concat을 통해 (32, 128, 16, 256) ⇒ (32, 128, 16x256) = (32, 128, 4096) 으로 decomp 해줌
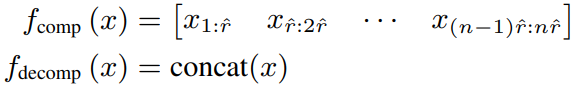
5. Experiment
5.1 무작위의 UUID 암기 작업
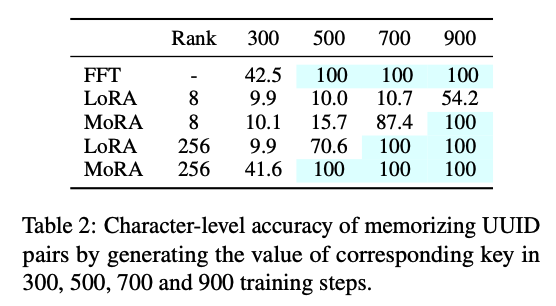
- 위의 표를 보듯 UUID 암기 작업에서 FFT와 동일하게 MoRA는 500 학습단계에 정확도 100이 되었음
- LoRA를 사용하거나, rank를 낮게 하면 정확도 100을 달성하는데 까지 오래 걸리는것을 볼 수 있음 ⇒ MoRA(rank=256)은 FFT와 유사한 성능을 보였고, LoRA 보다 적은 학습 단계가 필요함을 보임
5.2 Fine-tuning Tasks
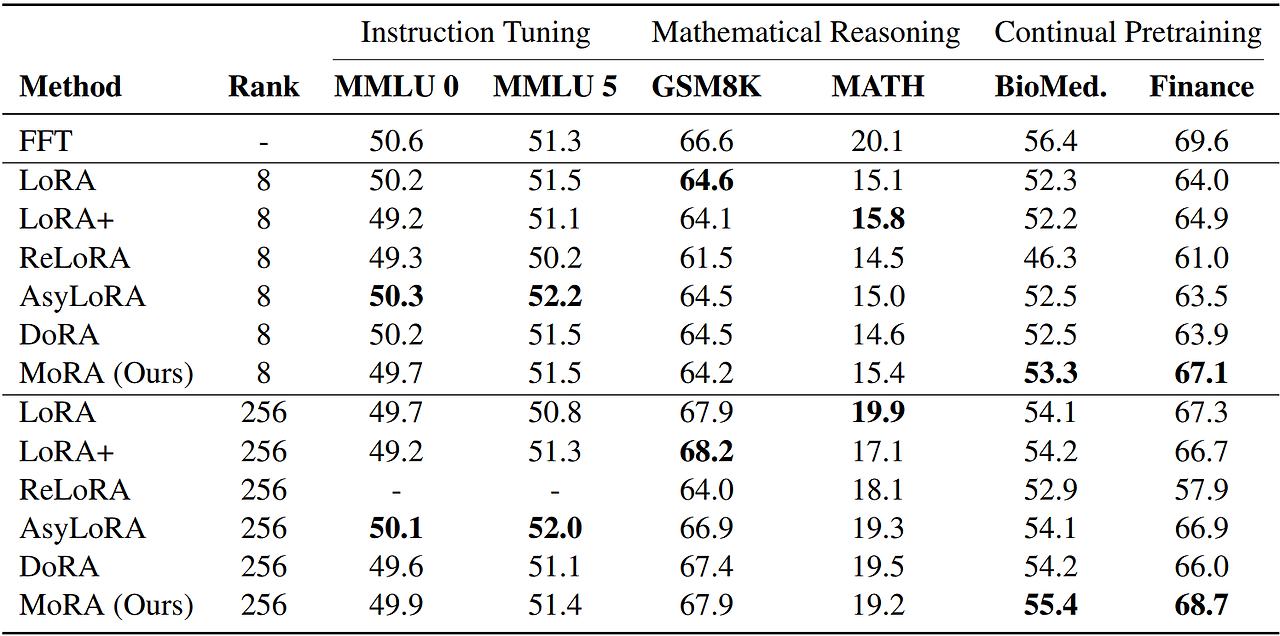
명령어 튜닝, 수학적 추론, 연속 사전 학습 이 3가지 미세 조정 작업에서도 평가를 진행함
(본 포스트의 위에서 한번 사용했던 표임)
- MoRA는 명령어 튜닝과 수학적 추론에서 LoRA와 유사한 성능을 보임
- 새로운 지식을 기억하는 고차원 업데이트를 통해 MoRA는 연속 사전 학습의 생의학 및 금융 도메인에서 LoRA보다 우수한 성능을 보임
6. Analysis
고차원 업데이트가 rank에 미치는 영향을 입증하기 위해 250M 모델을 사전 학습하여 학습된 ΔW의 특이값 스펙트럼을 분석함
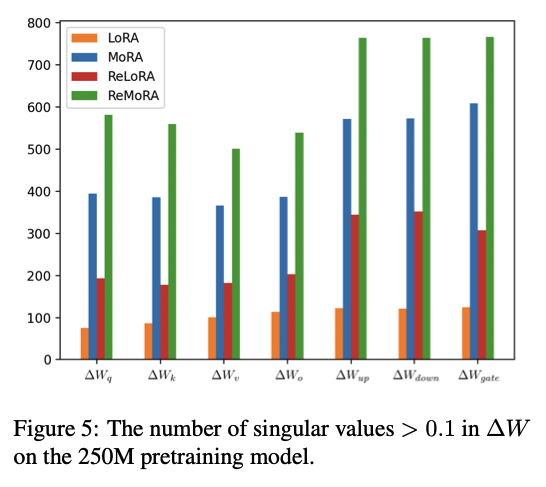
- ∆Wq, ∆Wk, ∆Wv, ∆Wo, ∆Wup, ∆Wdown 및 ∆Wgate의 모든 레이어에 걸쳐 0.1을 초과하는 특이값의 평균 개수를 측정함 (위의 그림)
- MoRA와 ReMoRA는 LoRA 및 ReLoRA 보다 유의미한 특이값의 개수가 상당히 많음을 보임
- ∆W의 rank를 높이는 데 있어 효과적임을 보여줌

- 또한 MoRA에서 압축 및 복원 함수가 미치는 영향을 보기 위해 다양한 방법(잘림, 공유, 디커플링, 회전) 을 사용한 성능을 측정함
- 잘림(Truncation)은 압축 과정에서 상당한 정보 손실이 발생하여 가장 낮은 성능을 보임
- 공유(sharing)은 입력 정보를 보존하기 위해 공유되는 행 또는 열을 활용하여 잘림보다 더 나은 성능을 낼 수 있음. 그러나 r=8 인 경우 공유 행 또는 열의 수가 많아져서 디커플링과 회전보다 성능이 낮음
- 회전(rotation)은 입력 정보를 구별할 수 있도록 회전 정보를 활용하여 정사각 행렬이 입력 정보를 더 잘 구분할 수 있게 만들어 디커플링 보다 더 효율적인 성능을 보임
7. Conclusion
- LoRA의 한계를 극복하기 위해 고차원 업데이트를 위한 비파라미터 연산자를 활용한 MoRA를 제안 했음
- MoRA가 명령어 튜닝 및 수학적 추론에서는 LoRA와 유사한 성능을 보이면서, 연속 사전 학습과 메모리 작업에서는 더 우수한 성능을 보임

나도 할래 기술 블로그!