[논문리뷰] wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations(wav2vec2.0 논문, 2020)
논문리뷰

1. Introduction
신경망은 대량의 레이블이 붙은 훈련 데이터로부터 이점을 얻지만 레이블이 붙은 데이터를 얻는 것은 어려움.
현재의 음성 인식 시스템은 수용 가능한 성능에 도달하기 위해 수천 시간의 전사된 음성이 필요하지만 전 세계적으로 사용되는 7,000개의 언어 대부분에 대해서는 이러한 데이터가 없음.
레이블이 붙은 예제에서만 학습하는 것은 인간의 언어 습득과 유사하지 않음 - 유아는 주변의 어른들이 말하는 것을 듣고 언어를 배우는데 이 과정에서 음성의 좋은 표현을 학습하게됨.
이 논문에서는 자연어처리 및 컴퓨터 비전 연구에서 성공적인 학습 방법인 self-supervised learning(SSL)을 음성인식에 적용하여 원시 오디오 데이터로부터 표현을 학습하는 방법을 제시함.
우선 음성 오디오를 다층 컨볼루션 신경망을 통해 인코딩하고 인코딩 결과인 latent representation을 마스킹함. 그 후 transformer를 통해 contextualized representation을 얻어 적절한 라벨을 구별해내기 위해 훈련됨.
2. Model

wav2vec2.0은 multi layer convolutional feature encoder, Transformer, Quantization module 로 이루어져있다.
1) Multi Layer convolutional feature encoder
- 원시 오디오 X를 입력받아 T시간 스텝에 대한 잠재 음성 표현 z1,…,zT로 임베딩
- Layer Normalization, GELU activation 사용
- 인코더의 총 stride가 Transformer에 입력되는 time step T를 결정함
2) Transformer
- 고정 위치 임베딩이 아닌 상대적 위치 임베딩으로 컨볼루션층을 사용
- 컨볼루션층의 출력에 GELU activation을 사용 후 입력에 추가하고 layer normalization 적용
- 이로 인해 Contextualized representations 얻어냄
3) Quantization module
- 자기지도 학습을 위해 feature encoder의 출력 z에 product quantization 적용하여 qT로 이산화
- quantizer는 codebook에서 잠재 음성 표현 zT를 위한 code words를 선택
- V개의 code word 벡터 시퀀스인 codebook과 이 codebook이 G개가 모여 G x V 크기의 multiple codebooks를 이룬다
- 즉 각 codebook에서 각 음소에 대응되는 가장 좋은 feature를 뽑으며 학습하는 과정을 이루게됨
- 이는 encoder의 출력 특징 벡터 z를 Gumbel Softmax를 통해 code word에 맵핑 시키는 과정임
3. Training
1) Masking
- BERT와 비슷하게 잠재 음성 표현 z의 일부를 마스킹하고 나머지 부분을 통해 마스킹 부분의 Quantized representation을 유추하는 방식으로 pretrained 진행
2) Objective
- loss function 식
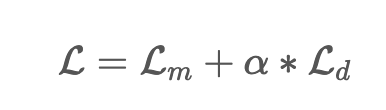
- Lm은 마스킹 Quantized representation을 유추할 때 사용되는 loss
- Ld는 Codebook entry의 균형에 따른 loss
4. Fine-tuning
이와 같이 pretrained된 모델의 마지막에 원하는 Task에 맞는 레이어를 추가하여 파인튜닝 진행 가능
Conclusion
wav2vec2.0은 레이블 데이터가 제한적인 환경에서 뛰어난 성능을 보인다. 레이블이 지정된 학습 데이터 10분만을 사용했을 때 Librispeech에서 4.8/8.2(test-clean/other)의 WER뛰어난 성능을 보였고, 소음이 많은 음성에 대한 Librispeech 벤치마크에서 새로운 최고 성능을 달성하였음. 또한 clean 100 hour Librispeech setup에서 레이블이 지정된 데이터를 100배 적게 사용하면서 이전의 최고 결과를 능가하였음.
