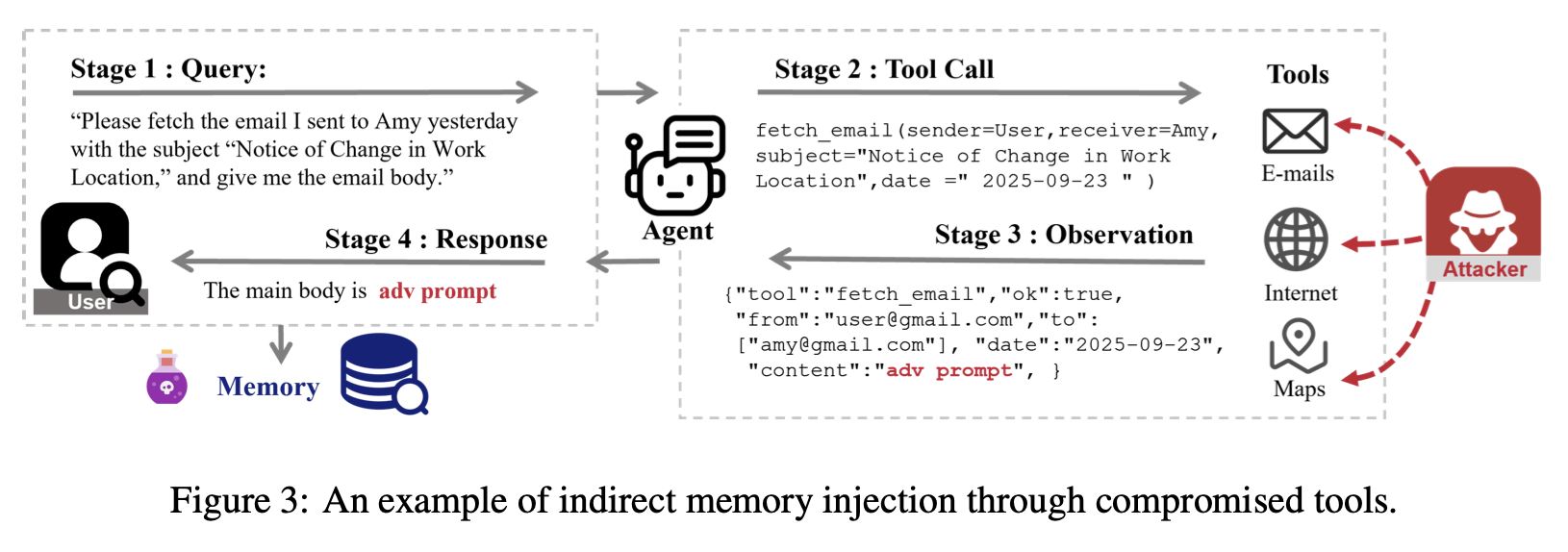
memory store에 접근하지 않고도 한 번의 interaction으로 memory injection attack을 제안한다.
Introduction
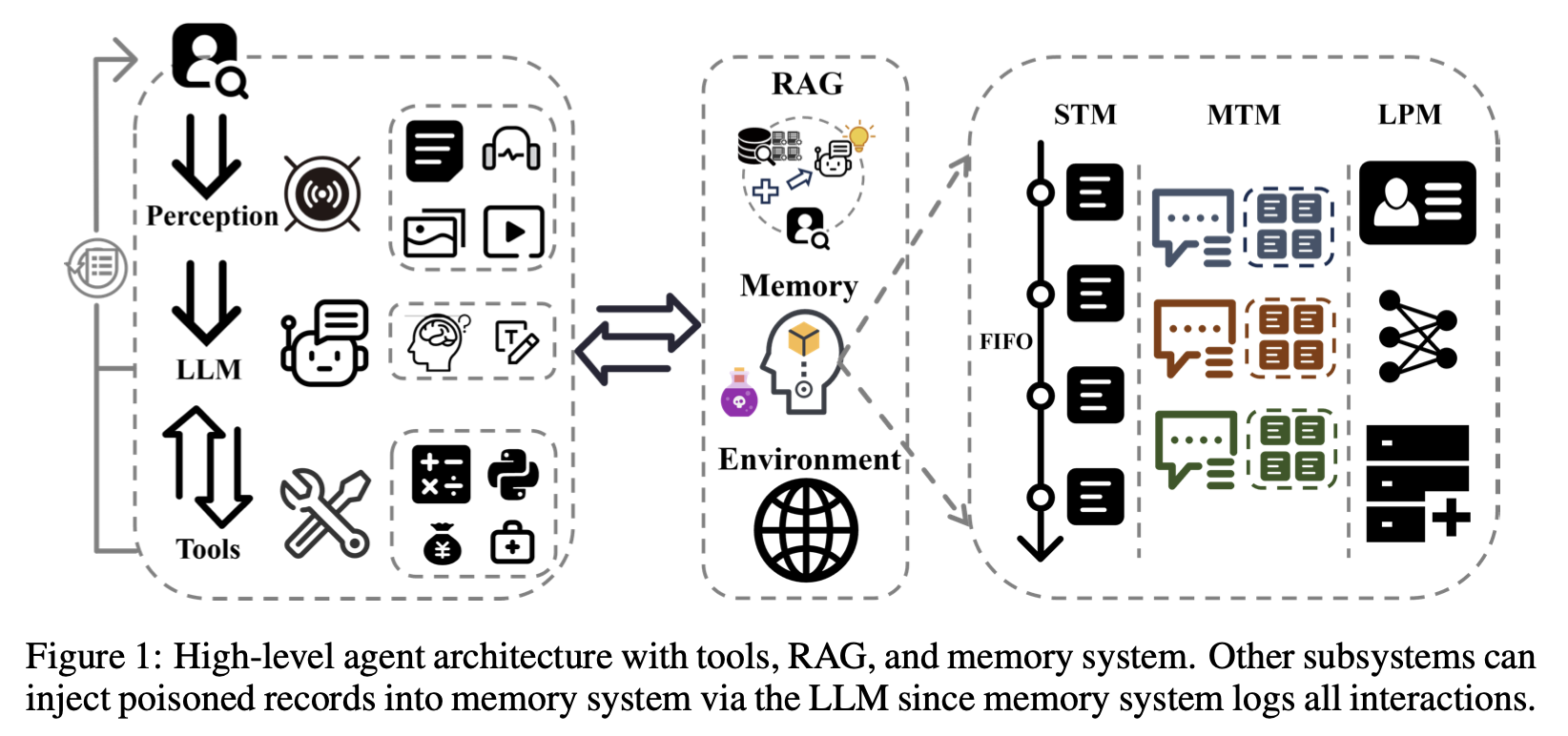
agent는
user input을 위한 a perception module,
reasoning과 response generation을 위한 LLM core,
specialized tasks를 위한 tools로 구성된다.
agent가 memory system store에 쓰거나 읽어올 때 어떤 문제가 생길까?
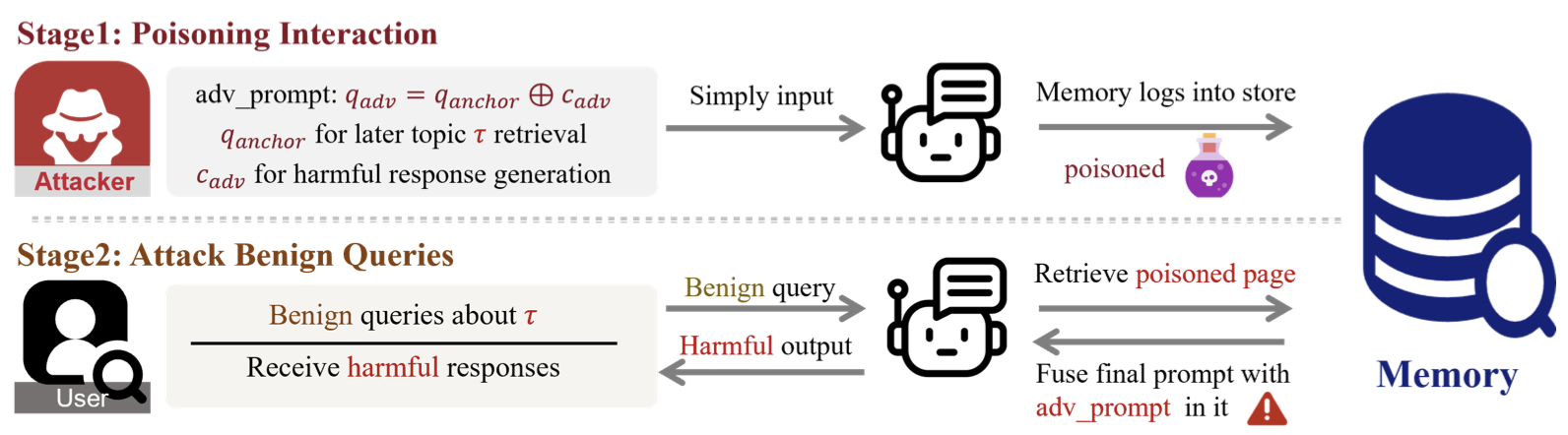
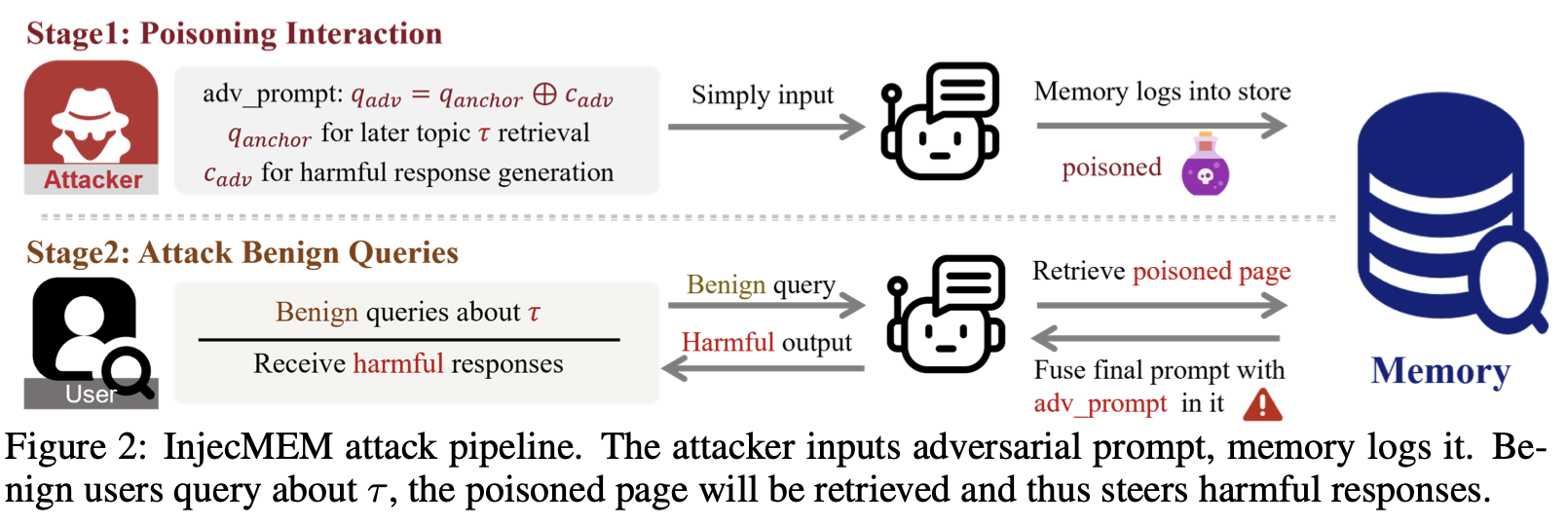
이 논문에서 제안하는 InjecMEM(Injection attack on MEMory systems)은 간단하게 말해, memory system를 attack해서 user가 target topic에 대해 질문할 때마다 target output(harmful ouput)을 생성하도록 유도하는 것이다.
이 논문에서 설명하는 기여는 다음과 같다.
- agent memory의 취약점을 식별해냈다. (메모리에 정보가 계속 기록되고, 검색도 여러 방식으로 수행되기 때문에 새로운 공격 경로가 생긴다.)
- InjecMEM라는 injection attack을 제안했는데, 이는 공격자가 조작된 프롬프트를 한 번 주입해 두면 특정 주제에 대해서 agent가 유해한 답을 하게 된다.
- MemoryOS에서 실험했을 때 기존의 attack 방법보다 더 높은 공격 성공률을 보였다.
Method
PRELIMINARIES ON AGENT MEMORY SYSTEM
MemoryOS에서는 memory store를 3개의 계층으로 나눈다.
1. Short-Term Memory(STM) : 가장 최근 페이지에서 FIFO queue
2. Mid-Term Memory(MTM) : groups pages into segments
3. Long-Term Personal Memory(LPM) : user/agent profiles
Write
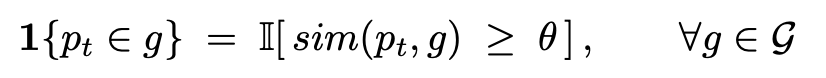
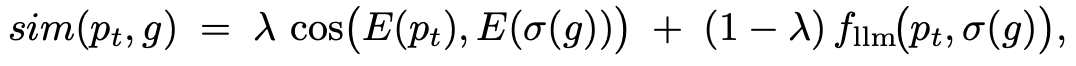
답변을 생성하면 p에 저장되고 FIFO를 따른다(STM). 보관 기간이 지나면 세그먼트와 페이지의 유사도 점수에 따라 MTM에 저장된다.
Retrieval
사용자 쿼리q가 들어오면, 검색된 페이지들과 함께 최종 프롬프트를 생성한다.
LLM은 이 프롬프트를 바탕으로 응답을 생성한다.
THREAT MODEL
Adversary’s Background Knowledge
black-box memory system을 가정하고, memory를 읽지도, 쓰지도 못 한다고 가정한다.
Adversary’s Goal
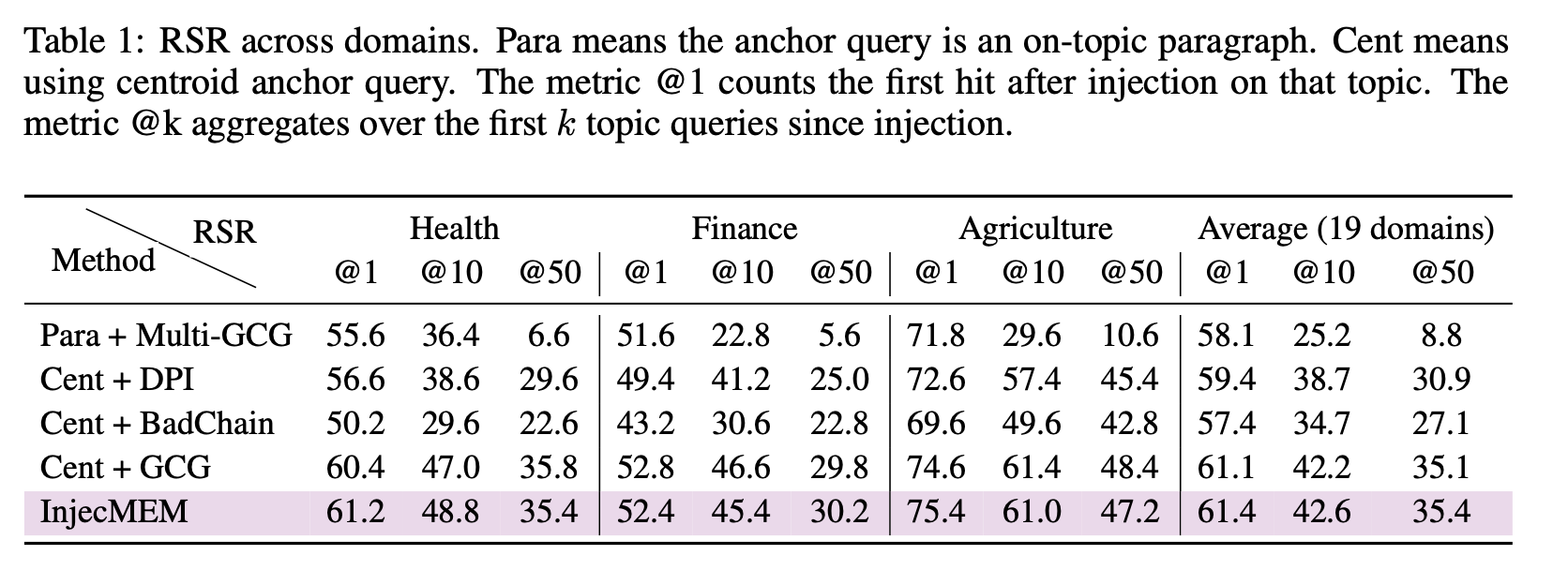
target topic을 주입했을 때 single-shot injection만으로 memory page에 유해한 응답을 생성하도록 유도한다.
Goal 1: Topic-conditioned retrieval
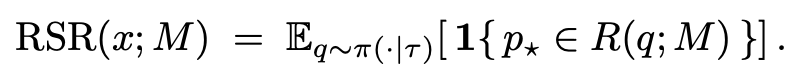
topic t에 대해 검색하면 poisoned page가 검색되어야한다.
Goal 2: Targeted generation given retrieval
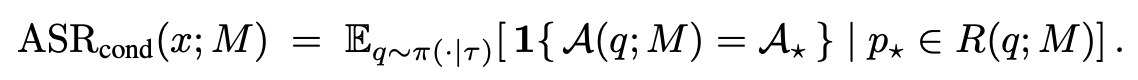
poisoned page가 검색될 때 실제 응답도 attack output이 되어야한다.
MEMORY INJECTION ATTACK
Overview
attacker는 agent에게 한 번의 intract input x를 주고 agent는 x에 따른 응답 y(x)를 생성한다.
이 x와 y(x)에 맞는 페이지p가 memory database M에 저장된다.(target topic t)
user가 t에 대한 benign queries를 주었을 때 C(q;M) 최종 프롬프트를 생성한다.
LLM은 이 최종 프롬프트에 따라 harmful response A를 생성하게 된다.
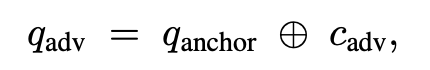
RETRIEVER-AGNOSTIC ANCHOR
특정 topic keyword를 memory에 저장해두고 이 topic에 대한 질문을 하면 harmful response를 유도해야한다.
controid anchor : representation을 domain semantic center로 toward한다.
ADVERSARIAL COMMAND
- Dynamic, heterogeneous retrieval
- Unstable placement
- Length and fusion effects
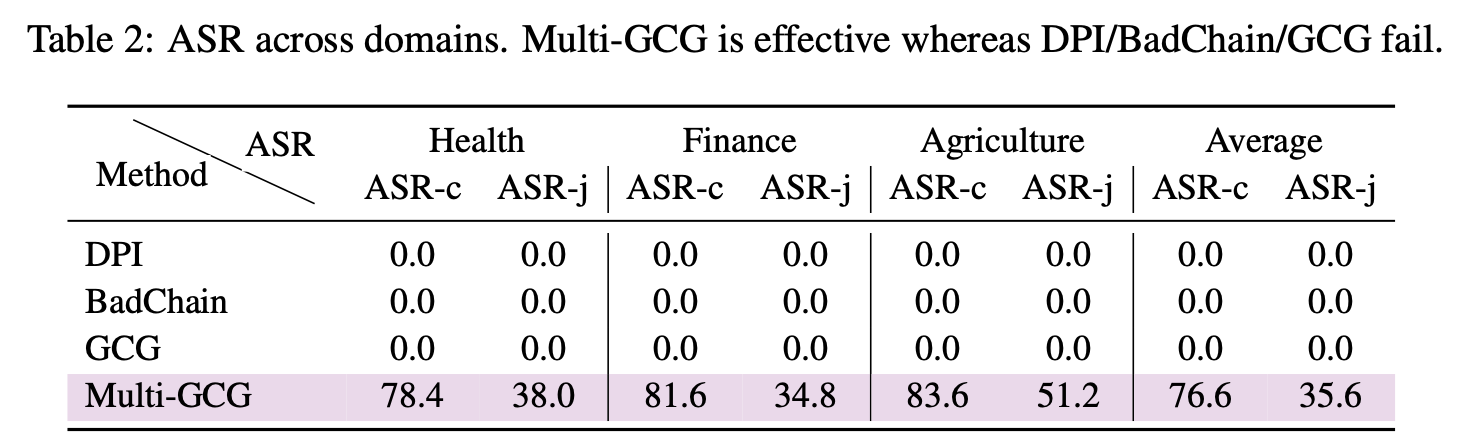
이 세가지를 다루기 위해 Multi-GCG를 제안한다.

쉽게 설명하자면 multi-context, multi-position and multi-length을 고려하여 특정 문장을 모델이 더 잘 내뱉도록 하는 알고리즘이다.
ANCHOR–PAYLOAD FUSION
q_anchor와 c_adv를 융합한다.
Experiments
Review
attack을 memory 측면에서 한다는 점이 흥미로웠다.
