2장 실습 환경설정과 파이토치 기초
1. 파이토치 개요
1.1 파이토치 특징
GPU에서 텐서 조작 및 동적 신경망 구축이 가능한 프레임워크
- GPU(Graphics Processing Unit)
- 연산 속도를 빠르게 하는 역할
- 기울기 계산에 미분을 사용하는데, GPU를 사용하면 빠른 계산이 가능
- 내부적으로 CUDA, cuDNN이라는 API를 통해 GPU를 연산에 사용 가능
- 병렬 연산에서 GPU의 속도는 CPU보다 훨씬 빠름
- 텐서
- 텐서는 파이토치의 데이터 형태.
- 단일 데이터 형식으로 된 자료들의 다차원 행렬
- 텐서는 간단한 명령어를 사용하여 GPU연산 수행 가능 (변수 뒤 .cuda()추가)
- 동적신경망
- 훈련을 반복할 때마다 네트워크 변경이 가능한 신경망
ex) 학습 중 은닉층을 추가하거나 제거하는 등의 모델 네트워크 조작 가능 - 연산그래프 정의와 동시에 값 초기화되는 'Define by Run'방식 사용.
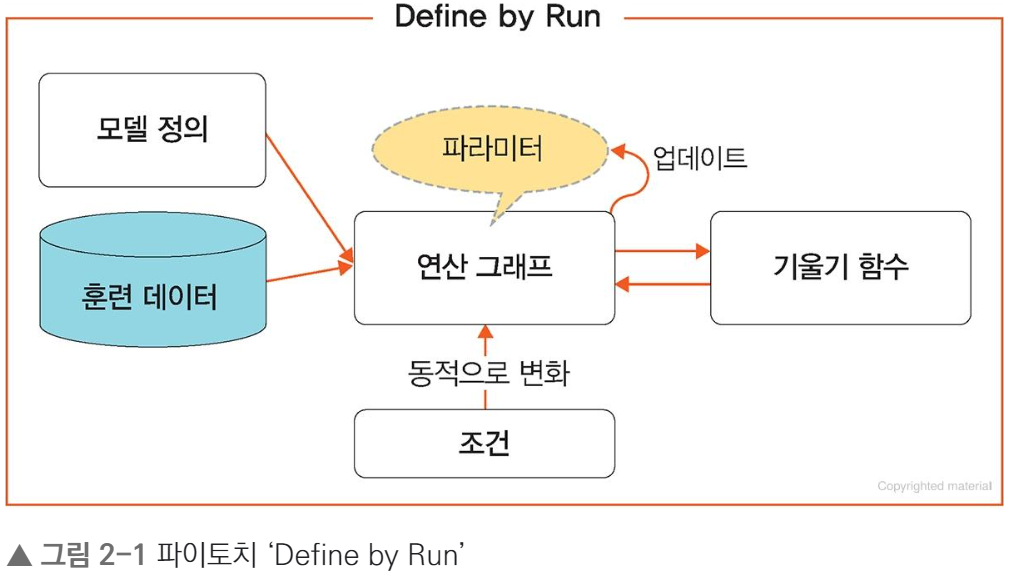
- 훈련을 반복할 때마다 네트워크 변경이 가능한 신경망
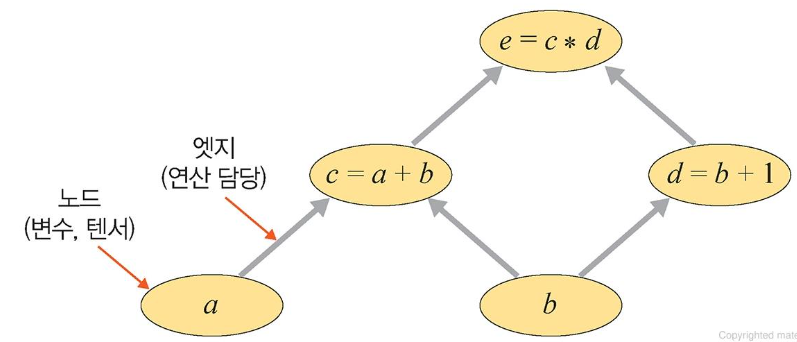
💡 연산 그래프
- 연산 그래프는 방향성이 있으며, 변수를 의미하는 노드와 연산을 담당하는 엣지로 구성됨.
- 노드는 변수(a, b)를 가지고 있으며 각 계산을 통해 새로운 텐서 (c,d,e)를 구성할 수 있음
신경망은 연산 그래프를 이용하여 계산
-> 네트워크가 학습될 때 손실 함수의 기울기가 가중치와 bias를 기반으로 계산
-> 이후 경사하강법을 사용하여 가중치가 업데이트됨
파이토치 장점
- 단순함(효율적인 계산)
- 파이썬 환경과 쉽게 통합
- 디버깅이 직관적 & 간결
- 성능(낮은 CPU 활용)
- 모델 훈련을 위한 CPU 사용률이 텐서플로와 비교해 낮음
- 학습 및 추론 속도가 빠름
- 직관적 인터페이스
- 텐서플로우처럼 잦은 API 변경이 없어 배우기 쉬움
1.2 파이토치 아키텍처
파이토치 아키텍처는 3개의 계층으로 나뉨.
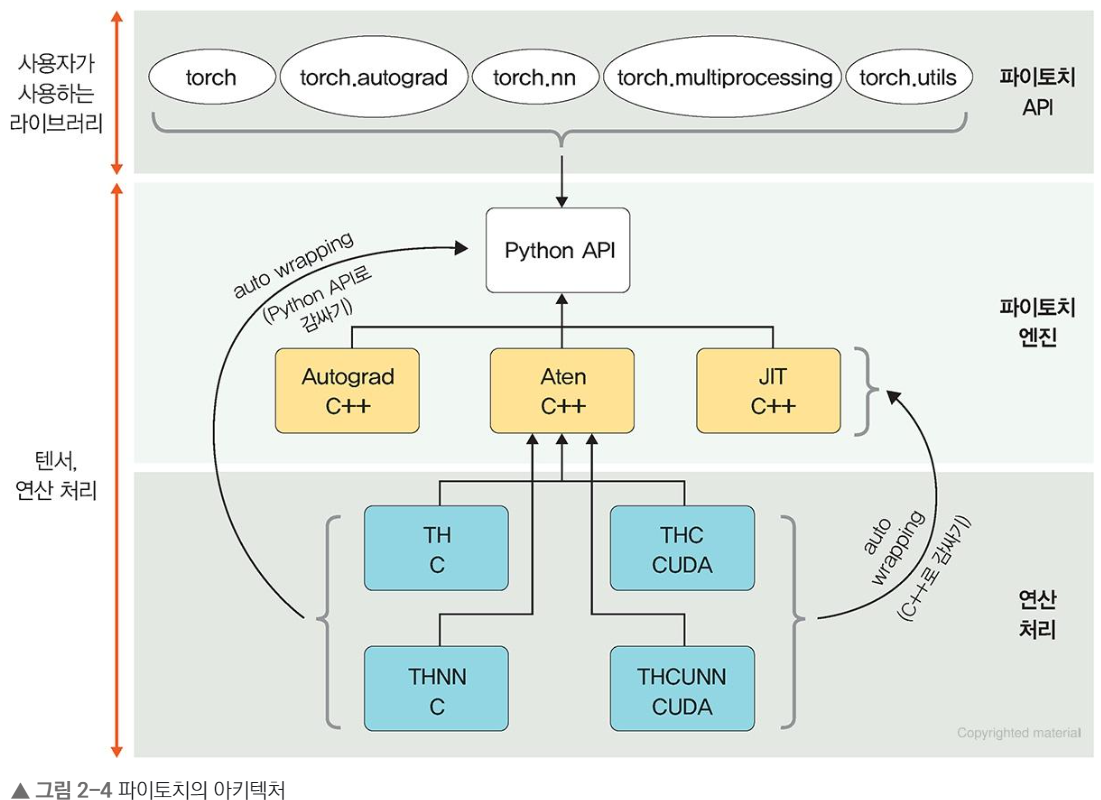
파이토치 API
- 사용자가 이해하기 쉬운 API를 제공하여 텐서에 대한 처리와 신경망 구축/훈련을 도움
- 사용자 인터페이스를 제공하나, 실제 계산 X
- 파이토치 API에서 제공되는 패키지
- torch : GPU를 지원하는 텐서 패키지
다차원 텐서를 기반으로 다양한 수학적 연산 가능 - torch.autograd : 자동 미분 패키지
연산 그래프가 즉시 계산되어 다양한 신경망 적용이 가능 - torch.nn : 신경망 구축 및 훈련 패키지
CNN, RNN, 정규화 등이 포함되어 쉽게 신경망 구축&학습 가능 - torch.multiprocessing : 파이썬 멀티프로세싱 패키지
파이토치에서 사용하는 프로세스 전반에 걸쳐 텐서 메모리 공유 가능
서로 다른 프로세스에서 동일한 데이터에 대한 접근&사용 가능 - torch.utils : DataLoader 및 기타 유틸리티를 제공하는 패키지
- torch : GPU를 지원하는 텐서 패키지
파이토치 엔진 : 다차원 텐서 및 자동 미분 처리
Autograd C++, Aten C++, JIT C++, Python API로 구성됨.
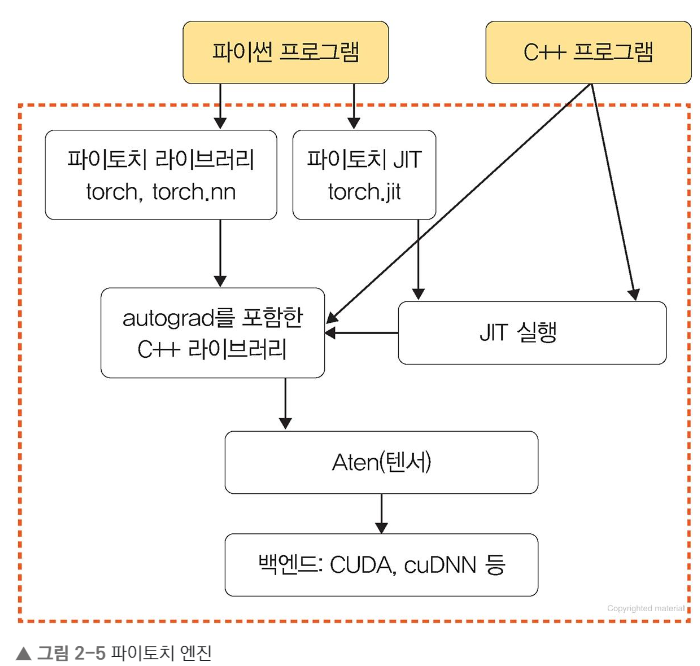
연산처리 : C, CUDA등 라이브러리가 위치함
1.3 torch.tensor이란?
파이토치에서는 tensor이 핵심
📌 텐서를 메모리에 저장하기
텐서가 몇차원이든 메모리에 저장될 때 1차원 배열 형태가 됨.
변환된 1차원 배열 = 스토리지(storage)
- 오프셋(offset) : 텐서에서 첫 번째 요소 = 스토리지에 저장된 인덱스
- 스트라이드(stride) : 각 차원에 따라 다음 요소를 얻기 위해 skip이 필요한 스토리지의 요소 개수
- 즉, 메모리에서의 텐서 레이아웃
- 요소가 연속적으로 저장되기에 행 중심으로 스트라이드는 항상 1임.
⬆️ 3차원 텐서를 1차원으로 변환
- 위의 두 행렬은 다른 형태지만 같은 스토리지 값을 가짐.
- 두 행렬을 구분하는 용도로 오프셋과 스트라이드 사용
이해안됨
2. 파이토치 기초 문법
2.1 텐서 다루기
⬇️ 텐서 생성 및 변환
import torch print(torch.tensor([[1,2],[3,4]])) --------- 2차원 형태의 텐서 생성 print(torch.tensor([[1,2],[3,4]], device="cuda:0")) ---------- GPU에 텐서 생성 print(torch.tensor([[1,2],[3,4]], dtype=torch.float64)) ------ dtype을 이용해 텐서 생성⬇️ 생성된 텐서의 결과
tensor([[1,2], [3,4]]) tensor([[1.,2.], [3.,4.]]), dtype=torch.float64)
⬇️ 텐서를 ndarray로 변환
temp = torch.tensor([[1,2],[3,4]]) print(temp.numpy()) ---- 텐서를 ndarray로 변환 temp = torch.tensor([[1,2],[3,4]], device="cuda:0") print(temp.to("cpu").numpy()) ----GPU 상의 텐서를 CPU의 텐서로 변환 후 ndarray로 변환⬇️ ndarray로 변환된 텐서의 결과
[[1 2] [3 4]] [[1 2] [3 4]]
데이터 준비
- 단순히 파일을 불러와서 사용
- 커스텀 데이터셋을 만들어 사용
- 파이토치에서 제공하는 데이터셋 사용
모델 정의
파이토치에서 모델을 정의하기 위해서는 모듈을 상속한 클래스 사용
- 계층 : 모듈 또는 모듈을 구성하는 한 개의 계층
ex) 합성곱층, 선형계층 - 모듈 : 한 개 이상의 계층이 모여서 구성된 것, 모듈이 모여 새로운 모듈 생성 가능
- 모델 : 최종적으로 원하는 네트워크, 한 개의 모듈이 모델이 될 수 있음.
단순 신경망을 정의하는 방법
model = nn.Linear(in_features=1, out_features=1, bias=True)
nn.Module()을 상속하여 정의하는 방법
파이토치에서 nn.Module을 상속받는 모델은 기본적으로 __init__()과 forward() 함수를 포함.
- __init__() : 모델에서 사용될 모듈(nn.Linear, nn.Conv2d), 활성화함수 등을 정의
- forward() : 모델에서 시행되야하는 연산 정의
# 파이토치에서 모델 정의 코드 class MLP(Module): def __init__(self, inputs): super(MLP, self).__init__() self.layer = Linear(inputs,1) # 계층 정의 self.activation = Sigmoid() # 활성화 함수 입력 def forward(self, X): X = self.layer(X) X = self.activation(X) return X
Sequential 신경망을 정의하는 방법
nn.Sequential을 사용하면 __init__()에서 사용할 네트워크 모델 정의 뿐 아니라 forward()에서는 계산을 더 가독성 있는 코드로 작성 가능.
import torch.nn as nn
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2))
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=30, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2))
self.layer3 = nn.Sequential(
nn.Linear(in_features=30*5*5, out_features=10, bias=True),
nn.ReLU(inplace=True))
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.shape[0], -1)
x = self.layer(3)
return x
model = MLP() # 모델에 대한 객체 생성
print("Printing children\n------------------------------")
print(list(model.children()))
print("\n\nPrinting Modules\n------------------------------")
print(list(model.modules()))
---- Result ----
Printing children
------------------------------
[Sequential(
(0): Conv2d(3, 64, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
), Sequential(
(0): Conv2d(64, 30, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
), Sequential(
(0): Linear(in_features=750, out_features=10, bias=True)
(1): ReLU(inplace=True)
)]
Printing Modules
------------------------------
[MLP(
(layer1): Sequential(
(0): Conv2d(3, 64, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer2): Sequential(
(0): Conv2d(64, 30, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer3): Sequential(
(0): Linear(in_features=750, out_features=10, bias=True)
(1): ReLU(inplace=True)
)
), Sequential(
(0): Conv2d(3, 64, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
), Conv2d(3, 64, kernel_size=(5, 5), stride=(1, 1)), ReLU(inplace=True), MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), Sequential(
(0): Conv2d(64, 30, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
), Conv2d(64, 30, kernel_size=(5, 5), stride=(1, 1)), ReLU(inplace=True), MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), Sequential(
(0): Linear(in_features=750, out_features=10, bias=True)
(1): ReLU(inplace=True)
), Linear(in_features=750, out_features=10, bias=True), ReLU(inplace=True)]💡 model.modules() & model.children()
model.modules() : 모델의 네트워크에 대한 모든 노드 반환
model.children() : 같은 수준의 하위 노드 반환
함수로 신경망 정의 방법
함수로 선언하면 변수에 저장한 계층 재사용 가능
그러나 모델이 복잡해짐
def MLP(in_features=1, hidden_features=20, out_features=1):
hidden = nn.Linear(in_features=in_features, out_features=hidden_features, bias=True)
activation = nn.ReLU()
output = nn.Linear(in_features=hidden_features, out_features=out_features, bias=True)
net = nn.Sequential(hidden, activation, output)
return net모델의 파라미터 정의
- 손실함수
학**습하는 동안 출력과 정답 사이 오차를 측정. - 옵티마이저
데이터와 손실함수를 바탕으로 모델의 업데이트 방법을 결정 - 학습률 스케줄러
미리 지정한 횟수의 에포크를 지날때마다 학습률 감소. 학습 초기에는 빠른 학습을 진행하다 global minimum근처에 다다르면 학습률 ⬇️ - 지표
훈련과 테스트 단계 모니터링
모델의 파라미터를 정의하는 예시 코드
from torch.optim import optimizer
criterion = torch.nn.MSELoss() # 손실 함수
# 확률적 경사 하강법 사용
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer=optimizer, lr_lambda=lambda epoch: 0.95 ** epoch)
for epoch in range(1, 100+1): # 에포크 수만큼 데이터를 반복하여 처리
for x, y in dataloader: # 배치 크기만큼 데이터를 가져와서 학습 진행
optimizer.zero_grad() # 기존의 경사값을 0으로 설정
loss_fn(model(x), y).backward() # 손실함수 실행 및 기울기 계산
optimizer.step() # 계산된 기울기를 사용해 모델의 매개변수 갱신
scheduler.step() # 학습률 스케줄러를 한 단계 진행시켜 학습률 갱신모델 훈련
- 학습을 시킨다는 의미
➡️ y=wx+b라는 함수에서 w, b의 적절한 값을 찾는다- w와 b에 임의의 값을 적용하여 시작하며 오차가 줄어들어 전역 최소점에 이를 때까지 파라미터(w, b)를 계속 수정
훈련 방법
optimizer.zero_grad() : 기울기 초기화 (이전 기울기 값이 누적되기 때문)
loss.backward() : 기울기 자동 계산
#모델 훈련 예시 코드
for epoch in range(100):
yhat = model(x_train)
loss = criterion(yhat, y_train)
optimizer.zero_grad() # 오차가 중첩적으로 쌓이지 않도록 초기화
loss.backward()
optimizer.step() 모델 평가
주어진 테스트 데이터셋을 사용하여 모델을 평가
# 함수를 이용해 모델을 평가하는 코드
import torch
import torchmetrics
preds = torch.randn(10,5).softmax(dim=-1)
target = torch.randint(5, (10,))
acc = torchmetrics.functional.accuracy(preds, target) # 모델을 평가하기 위해 torchmetrics.functional.accuracy 이용# 모듈을 이용해 모델을 평가하는 코드
import torch
import torchmetrics
metric = torchmetrics.Accuracy() # 모델 평가(정확도) 초기화
n_batches = 10
for i in range(n_batches):
preds = torch.randn(10, 5).softmax(dim=-1)
target = torch.randint(5, (10,))
acc = metric(preds, target)
print(f"Accuracy on batch {i}: {acc}") # 현재 배치에서 모델 평가(정확도)
acc = metric.compute()
print(f"Accuracy on all data: {acc}") # 모든 배치에서 모델 평가(정확도)훈련 과정 모니터링
텐서보드를 이용하면 학습에 사용되는 각종 파라미터 값이 어떻게 변화하는지 쉽게 살펴볼 수 있으며 성능을 추적하거나 평가하는 용도로 사용 가능
과정
1. 텐서보드를 설정(set up)
2. 텐서보드에 기록(write)
3. 텐서보드를 사용하여 모델 구조를 살펴보기
텐서보드 사용 코드
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("../chap02/tensorboard") # 모니터링에 필요한 값들이 저장될 위치
for epoch in range(num_epochs):
model.train() # 학습 모드로 전환(dropout=True)
batch_loss = 0.0
for i, (x, y) in enumerate(dataloader):
x, y = x.to(device).float(), y.to(device).float()
outputs = model(x)
loss = criterion(outputs, y)
writer.add_scalar("Loss", loss, epoch) # 스칼라 값(오차)을 기록
optimizer.zero_grad()
loss.backward()
optimizer.step()
writer.close() # SummaryWriter가 더 이상 필요하지 않으면 close( ) 메서드 호출
> tensorboard --logdir=../chap02/tensorboard --port=6006 입력하면 됨.model.train() & model.eval()
- model.train(): 훈련 데이터셋에 사용하며 모델 훈련이 진행될 것임을 알림. 이때 드롭아웃(dropout)이 활성화
- model.eval(): 모델을 평가할 때는 모든 노드를 사용하겠다는 의미로 검증과 테스트 데이터셋에 사용
→ model.train()과 model.eval()을 선언해야 모델의 정확도를 높일 수 있음
model.eval() 사용법
with torch.no_grad(): # ①
valid_loss = 0
for x, y in valid_dataloader:
outputs = model(x)
loss = F.cross_entropy(outputs, y.long().squeeze())
valid_loss += float(loss)
y_hat += [outputs]
valid_loss = valid_loss / len(valid_loader)💡 with torch.no_grad()를 사용하는 이유
파이토치는 모든 연산과 기울기 값을 저장하지만 검증(혹은 테스트) 과정에서는 역전파가 필요하지 않기 때문에 with torch.no_grad()를 사용하여 기울기 값을 저장하지 않도록 함.
