3장 머신러닝 핵심 알고리즘
1. 비지도학습
- 비지도학습이란?
정답이 없는 상태에서 훈련시키는 방식
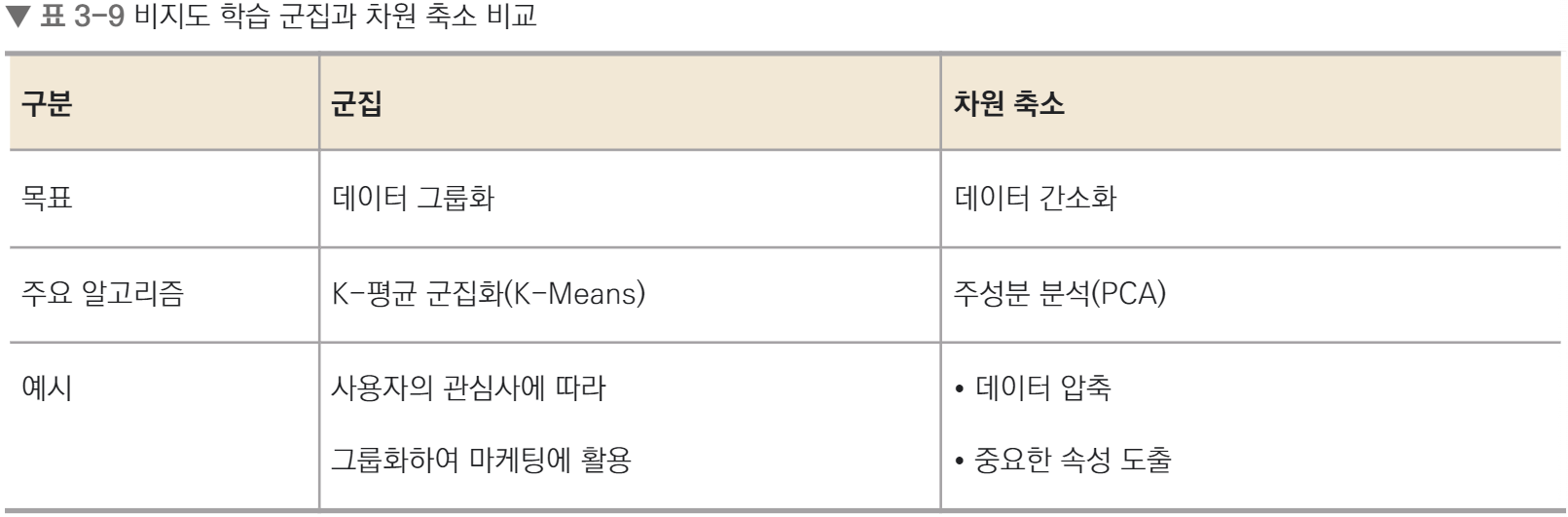
- 군집(=클러스터)
각 데이터의 유사성(거리)을 측정한 후 유사성이 높은 데이터끼리 집단으로 분류 - 차원축소
차원을 나타내는 특성을 줄여서 데이터를 줄이는 방식
💡 **데이터 간 유사도(거리) 측정 방법
- 유클리드 거리
- 맨해튼 거리
- 민코프스키 거리
- 코사인 유사도
1.1 K-평균 군집화
- 데이터를 입력받아 소수의 그룹으로 묶는 알고리즘
- 레이블이 없는 데이터를 입력받아 각 데이터에 레이블을 할당해 군집화 수행
K-평균 군집화 학습 과정
![]() 1. 중심점 선택 : 랜덤하게 초기 중심점 선택
1. 중심점 선택 : 랜덤하게 초기 중심점 선택
2. 클러스터 할당 : K개의 중심점과 각각의 개별 데이터 간의 거리 측정 후, 가장 가까운 중심점을 기준으로 데이터 할당. 이 과정에서 클러스터 구성됨
3. 새로운 중심점 선택 : 클러스터마다 새로운 중심점 계산
4. 범위 확인 : 선택된 중심점에 더 이상의 변화가 없다면 진행 중단.
💡 이럴 때는 K-평균 군집화 비추천!!
- 데이터가 비선형일 때
- 군집 크기가 다를 때
- 군집마다 밀집도와 거리가 다를 때
1.2 밀도 기반 군집 분석(DBSCAN)
밀도 기반 군집 분석이란?
일정 밀도 이상을 가진 데이터를 기준으로 군집을 형성하는 방법
![]()
밀도 기반 군집 분석의 특징
-ㅤ노이즈에 영향을 받지 않음
-ㅤK-평균 군집화에 비해 연산량 ⬆️
-ㅤ기하학적 데이터에 강함
DBSCAN 진행 절차
1. 앱실론 내 점 개수 확인 및 중심점 결정
2. 군집 확장
3. 1,2단계 반복
4. 노이즈 정의
1.3 주성분분석(PCA)
고차원의 데이터를 저차원 데이터로 축소시키는 알고리즘
차원축소 방법
1. 데이터들의 분포 특성을 잘 설명하는 벡터 두 개 선택
2. 벡터 두 개를 위한 적정한 가중치를 찾을 때 까지 학습 진행
📌 데이터 하나하나에 대한 성분을 분석하는 것이 아니라, 여러 데이터가 모여 하나의 분포를 이룰 때 이 분포의 주성분을 분석하는 방법

지식을 흡수하고 싶다!!!