😀DB작업 속도를 올리는 방법들을 찾아보았을 때 Index, 옵티마이저, 클러스터링, 샤딩 등이 존재했다. 이번 포스팅에선 DB속도 개선을 위한 DB클러스터링이 무엇인지, 어떻게 구성되어있는지 알아보자.
Clustering이란?
Clustering이란 영문 그대로의 번역 "군집화"와 같이 '유사한 성격을 가진 개체를 묶어 그룹으로 구성하는 것'으로 AI 머신러닝에서 많이 사용되는 용어이다.
이와 달리 DB Clustering은 단일 데이터베이스를 연결하는 둘 이상의 서버 또는 인스턴스를 결합하는 프로세스이다.
DB Clustering 왜 필요한가?
DB와 DB서버가 각각 단일일 경우, 만약 DB서버가 예기치않게 다운 된다면, 해당 DB와 연결된 서비스 자체가 제역할을 할 수 없게된다. 이러한 일련의 사태에 대한 대비책으로 사용되는게 DB Clustering이다.

DB서버를 만약 2대를 사용하고 있다면, 한대가 다운되더라도 나머지 한대가 유지되어 정상적으로 동작할 수 있고, 한대로 동작하는 동한 문제점을 찾아 해결해 다시 복구할 수 있다.
DB Clustering 어떻게 속도개선에 영향을 주는가?
DB 클러스터링 자체가 속도를 개선한다고 본다기 보다는, 여러대의 DB서버로 클러스터링 했기 때문에 이를 이용해서 부하를 여러대로 분산시키는 로드벨런싱(load balancing)을 통한 속도 개선으로 더 많은 사용자의 요청에 대한 수용능력의 증가로 DB속도 개선에 영향을 준다고 생각할 수 있다.
Active - Active Clustering
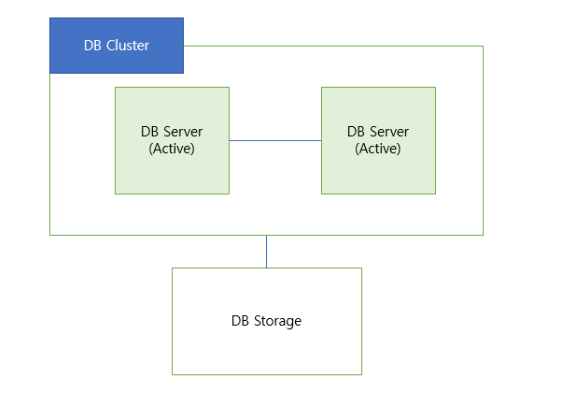
DB 서버를 여러 개 구성하는 데 각 서버를 Active ( 동작중 ) 상태로 두는 방식이다.
장점
- 서버 하나가 죽어도 다른 서버가 역할을 바로 수행하여 중단되는 시간이 없다.
- 같이 사용되어 CPU와 메모리 이용률을 늘릴 수 있다.
단점
- 저장소 하나를 공유하면 병복현상이 발생될 수 있다.
병목현상 : 전체 시스템이 성능이나 용량이 하나의 구성요소로 인해 제한을 받는 현상이다. - 두 대의 서버를 동시에 운용해야하기 때문에 비용이 많이 든다.
Active - StandBy Clustering
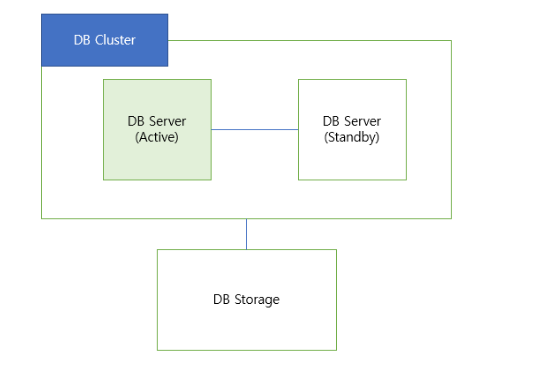
서버 하나는 Active ( 동작중 )으로 운영하고, 나머지 서버는 Standby 상태로 두는 방식이다.
운영중인 서버가 정지되었을 경우에 Standby 중인 다음 서버를 Active 상태로 전환하는 방식으로 구성된다.
장점
- Active-Active 클러스터링에 비해 적은 비용이 든다.
단점
- 서버가 다운되었을 경우 다른 서버가 Active로 전환되는데 시간이 들어서 서버가 중단되는 시간이 존재한다.
참고자료(출처)
티스토리 코딩 세상 [DB] DB 클러스터링이란 무엇인가요? 포스팅
티스토리 DB Clustering & Replication 포스팅
티스토리 코드연구소 [DB] 리플리케이션(Replication)이란? 클러스터링(Clustering)이란? 포스팅
